unordered_map/set常用接口及模拟实现
目录
unordered_map 和 unordered_set
1>参考文档
2>概念
3>unordered_set的使用差异
4>unordered_map的使用差异
5>unordered_multimap/unordered_multiset
6>哈希相关接口
哈希表实现
1>直接定址法
2>哈希冲突
3>负载因子
4>将关键字转为整数
5>哈希函数
a.除法散列法
b.乘法散列法
c.全域散列法
6>处理哈希冲突
a.开放定址法
①线性探测
②二次探测
③双重散列
b.代码实现
①哈希表结构
②扩容
③key不能取模问题
④完整代码
c.链地址法
①思路
②扩容
③完整代码
用哈希表封装 myunordered_map 和 myunordered_set
1>源码及框架分析
2>模拟实现
a.复用框架
b.iterator的实现
①核⼼源代码
②思路分析
c.map支持[]
d.代码实现
unorderedset.h
unorderedmap.h
HashTables.h
unordered_map 和 unordered_set
1>参考文档
<unordered_set> - C++ Reference
2>概念
• unordered_set 的声明如下,Key就是 unordered_set 底层关键字的类型
• unordered_set 默认要求Key⽀持转换为整形,如果不⽀持或者想按⾃⼰的需求⾛可以⾃⾏实现⽀持将Key转成整形的仿函数传给第⼆个模板参数
• unordered_set 默认要求Key⽀持⽐较相等,如果不⽀持或者想按⾃⼰的需求⾛可以⾃⾏实现⽀持将Key⽐较相等的仿函数传给第三个模板参数
• unordered_set 底层存储数据的内存是从空间配置器申请的,如果需要可以⾃⼰实现内存池,传给第四个参数
• ⼀般情况下,我们都不需要传后三个模板参数
• unordered_set 底层是⽤哈希桶实现,增删查平均效率是 O(1) ,迭代器遍历不再有序,为了跟 set 区分,所以取名 unordered_set
(我在前面的文章介绍了 set 容器的使⽤,set和unordered_set的功能⾼度相似,只是底层结构不同,有⼀些性能和使⽤的差异,这⾥我就介绍它们的差异部分)
template < class Key, //
unordered_set::key_type/value_typeclass Hash = hash<Key>, // unordered_set::hasherclass Pred = equal_to<Key>, // unordered_set::key_equalclass Alloc = allocator<Key> // unordered_set::allocator_type> class unordered_set;3>unordered_set的使用差异
• unordered_set 和 set 的第⼀个差异是对 key 的要求不同,set 要求 Key ⽀持⼩于⽐较,⽽ unordered_set 要求 Key ⽀持转成整形且⽀持等于⽐较,要理解 unordered_set 的这个两点要求得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求
• unordered_set 和 set 的第⼆个差异是迭代器的差异,set 的 iterator 是双向迭代器,unordered_set 是单向迭代器,其次 set 底层是红⿊树,红⿊树是⼆叉搜索树,⾛中序遍历是有序的,所以 set 迭代器遍历是有序+去重,⽽ unordered_set 底层是哈希表,迭代器遍历是⽆序+去重
• unordered_set 和 set 的第三个差异是性能的差异,整体⽽⾔⼤多数场景下, unordered_set 的增删查改更快⼀些,因为红⿊树增删查改效率是 O(logN) ,⽽哈希表增删查平均效率是 (1)
(大家可以复制下面这段代码跑一下,感受一下它们的性能差异)
#include<unordered_set>
#include<unordered_map>
#include<set>
#include<iostream>
#include<vector>
#include<ctime>
using namespace std;int test_set2()
{const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N⽐较⼤时,重复值⽐较多v.push_back(rand()+i); // 重复值相对少//v.push_back(i); // 没有重复,有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();us.reserve(N);for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;int m1 = 0;size_t begin3 = clock();for (auto e : v){auto ret = s.find(e);if (ret != s.end()){++m1;}}size_t end3 = clock();cout << "set find:" << end3 - begin3 << "->" << m1 << endl;int m2 = 0;size_t begin4 = clock();for (auto e : v){auto ret = us.find(e);if (ret != us.end()){++m2;}}size_t end4 = clock();cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;cout << "插⼊数据个数:" << s.size() << endl;cout << "插⼊数据个数:" << us.size() << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
}int main()
{test_set2();return 0;
}4>unordered_map的使用差异
• unordered_map 和 map 的第⼀个差异是对 key 的要求不同,map 要求 Key ⽀持⼩于⽐较,⽽ unordered_map 要求 Key ⽀持转成整形且⽀持等于⽐较,要理解 unordered_map 的这个两点要求得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求
• unordered_map 和 map 的第⼆个差异是迭代器的差异,map 的 iterator 是双向迭代器,unordered_map 是单向迭代器,其次 map 底层是红⿊树,红⿊树是⼆叉搜索树,⾛中序遍历是有序的,所以 map 迭代器遍历是 Key有序+去重。⽽unordered_map 底层是哈希表,迭代器遍历是 Key⽆序+去重
• unordered_map 和 map 的第三个差异是性能的差异,整体⽽⾔⼤多数场景下,unordered_map 的增删查改更快⼀些,因为红⿊树增删查改效率是 O(logN) ,⽽哈希表增删查平均效率是 O(1)
pair<iterator,bool> insert ( const value_type& val );
size_type erase ( const key_type& k );
iterator find ( const key_type& k );
mapped_type& operator[] ( const key_type& k );5>unordered_multimap/unordered_multiset
• unordered_multimap/unordered_multiset 跟 multimap/multiset 功能完全类似,⽀持Key冗余
• unordered_multimap/unordered_multiset 跟 multimap/multiset 的差异也是三个⽅⾯的差异,key 的要求的差异,iterator 及遍历顺序的差异,性能的差异
6>哈希相关接口
Buckets和Hash policy系列的接⼝分别是跟哈希桶和负载因⼦相关的接⼝,大家可以先看一下哈希表的底层再来看这个系列的接口,会理解的透彻一点
哈希表实现
概念:哈希(hash)⼜称散列,是⼀种组织数据的⽅式。从译名来看,有散乱排列的意思。本质就是通过哈希函数把关键字Key跟存储位置建⽴⼀个映射关系,查找时通过这个哈希函数计算出Key存储的位置,进⾏快速查找
1>直接定址法
当关键字的范围⽐较集中时,直接定址法就是⾮常简单⾼效的⽅法,⽐如⼀组关键字都在[0,99]之间,那么我们开⼀个100个数的数组,每个关键字的值直接就是存储位置的下标。再⽐如⼀组关键字值都在[a,z]的⼩写字⺟,那么我们开⼀个26个数的数组,每个关键字acsii码 - a的ascii码就是存储位置的下标。也就是说直接定址法本质就是⽤关键字计算出⼀个绝对位置或者相对位置
387. 字符串中的第一个唯一字符 - 力扣(LeetCode)
class Solution {
public:int firstUniqChar(string s) {// 每个字⺟的ascii码-'a'的ascii码作为下标映射到count数组,数组中存储出现的次数int count[26] = {0};// 统计次数for(auto ch : s){count[ch-'a']++;} for(size_t i = 0; i < s.size(); ++i){if(count[s[i]-'a'] == 1)return i;}return -1;}
};2>哈希冲突
直接定址法的缺点也⾮常明显,当关键字的范围⽐较分散时,就很浪费内存甚⾄内存不够⽤。假设我们只有数据范围是[0, 9999]的N个值,我们要映射到⼀个M个空间的数组中(⼀般情况下M >= N),那么就要借助哈希函数(hash function)hf,关键字key被放到数组的h(key)位置,这⾥要注意的是h(key)计算出的值必须在[0, M)之间
这⾥存在的⼀个问题就是,两个不同的key可能会映射到同⼀个位置去,这种问题我们叫做哈希冲突,或者哈希碰撞(实际场景中哈希冲突是不可避免的,但我们可以尽可能设计出好的哈希函数,减少冲突的次数
3>负载因子
假设哈希表中已经映射存储了N个值,哈希表的⼤⼩为M,那么负载因⼦有些地⽅也翻译为载荷因⼦/装载因⼦等(英⽂为load factor),负载因⼦越⼤,哈希冲突的概率越⾼,空间利⽤率越⾼;负载因⼦越⼩,哈希冲突的概率越低,空间利⽤率越低
4>将关键字转为整数
我们将关键字映射到数组中的位置,⼀般是整数好做映射计算,如果不是整数,我们要想办法转换成整数
5>哈希函数
⼀个好的哈希函数应该让N个关键字被等概率的均匀的散列分布到哈希表的M个空间中,但是实际中却很难做到,但是我们要尽量往这个⽅向去考量设计
a.除法散列法
• 除法散列法也叫做除留余数法,假设哈希表的⼤⼩为M,那么通过key除以M的余数作为映射位置的下标,也就是哈希函数为:h(key) = key % M
• 当使⽤除法散列法时,要尽量避免M为某些值,如2的幂,10的幂等。如果是 2^x,那么key % 2^x 本质相当于保留key的后X位,那么后x位相同的值,计算出的哈希值都是⼀样的,就冲突了(所以建议M取不太接近2的整数次幂的⼀个质数(素数) )
• 注意,要灵活运用,例如JAVA的 HashMap 采用除法散列法时就是2的整数次幂做哈希表的M,这样的话就不用取模,而可以直接位运算,且还提高了效率(当然,这里不是简单的位运算,大家感兴趣可以去了解一下)
b.乘法散列法
• 乘法散列法对哈希表⼤⼩M没有要求,他的⼤思路第⼀步:⽤关键字 K 乘上常数 A (0<A<1),并抽取出 kA 的⼩数部分。第⼆步:后再⽤M乘以kA 的⼩数部分,再向下取整

c.全域散列法
• 如果存在⼀个恶意的对⼿,他针对我们提供的散列函数,特意构造出⼀个发⽣严重冲突的数据集,⽐如,让所有关键字全部落⼊同⼀个位置中。这种情况是可以存在的,只要散列函数是公开且确定的,就可以实现此攻击。解决⽅法⾃然是⻅招拆招,给散列函数增加随机性,攻击者就⽆法找出确定可以导致最坏情况的数据,这种⽅法叫做全域散列

• 需要注意的是每次初始化哈希表时,随机选取全域散列函数组中的⼀个散列函数使⽤,后续增删查改都固定使⽤这个散列函数,否则每次哈希都是随机选⼀个散列函数,那么插⼊是⼀个散列函数,查找⼜是另⼀个散列函数,就会导致找不到插⼊的key了
(以上的方法都来自《算法导论》书籍,后面两种方法大家了解一下即可,我们主要还是用除法散列法,当然还有其它方法,大家感兴趣可以看看严蔚敏老师和吴伟民老师的数据结构等相关书籍)
6>处理哈希冲突
实践中哈希表⼀般还是选择除法散列法作为哈希函数,当然哈希表⽆论选择什么哈希函数也避免不了冲突,那么插⼊数据时,如何解决冲突呢?主要有两种⽅法,开放定址法和链地址法
a.开放定址法
在开放定址法中所有的元素都放到哈希表⾥,当⼀个关键字key⽤哈希函数计算出的位置冲突了,则按照某种规则找到⼀个没有存储数据的位置进⾏存储,开放定址法中负载因⼦⼀定是⼩于的。这⾥的规则有三种:线性探测、⼆次探测、双重探测
①线性探测
• 从发⽣冲突的位置开始,依次线性向后探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果⾛到哈希表尾,则回绕到哈希表头的位置

• 线性探测相对来说比较好实现,线性探测的问题假设,hash0位置连续冲突,hash0,hash1位置已经存储数据了,后续映射到hash0,hash1的值都会争夺hash2位置,这种现象叫做群集/堆积(二次探测可以⼀定程度改善这个问题)
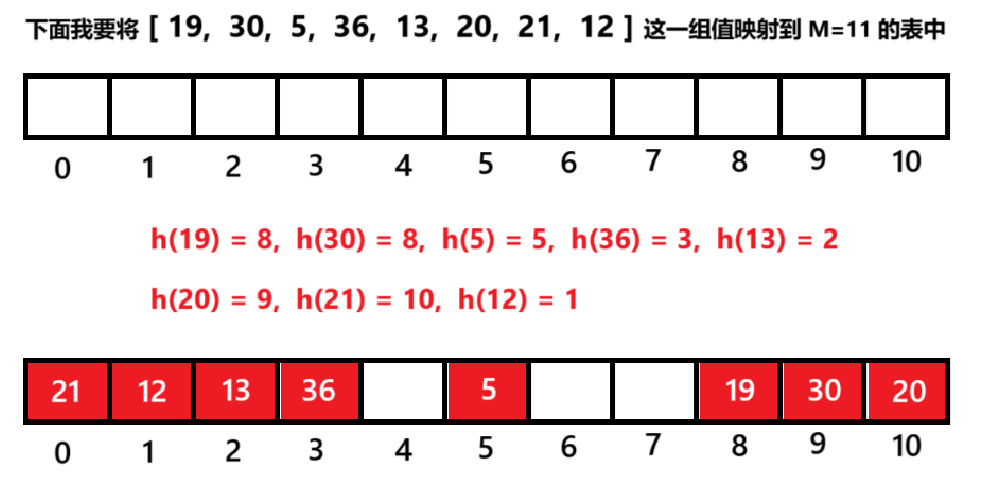
②二次探测
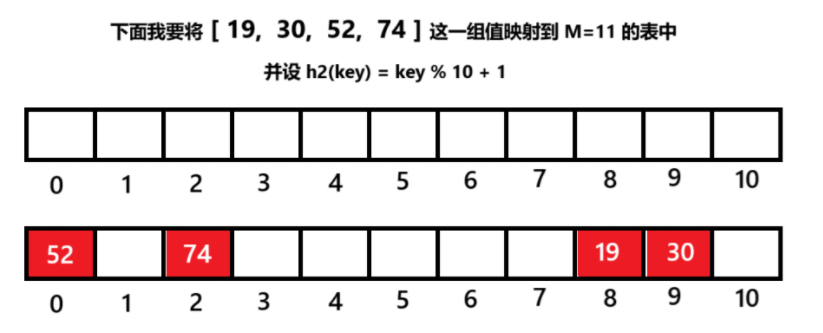
• 从发⽣冲突的位置开始,依次左右按⼆次⽅跳跃式探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果往右⾛到哈希表尾,则回绕到哈希表头的位置;如果往左⾛到哈希表头,则回绕到哈希表尾的位置

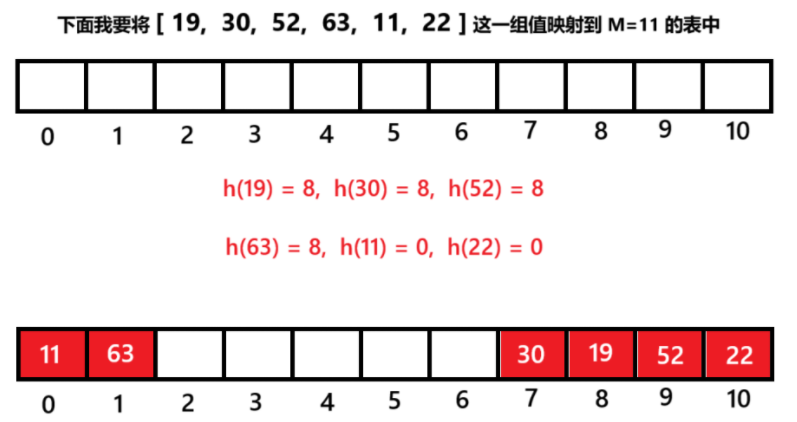
③双重散列
• 第⼀个哈希函数计算出的值发⽣冲突,使⽤第⼆个哈希函数计算出⼀个跟key相关的偏移量值,不断往后探测,直到寻找到下⼀个没有存储数据的位置为⽌

b.代码实现
开放定址法在实践中,不如下⾯介绍的链地址法,因为开放定址法解决冲突不管使⽤哪种⽅法,占⽤的都是哈希表中的空间,始终存在互相影响的问题,所以开放定址法,我们简单选择线性探测实现即可
①哈希表结构
enum State
{EXIST,EMPTY,DELETE
};template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;
};template<class K, class V>
class HashTable
{
private:vector<HashData<K, V> _tables;size_t n = 0;
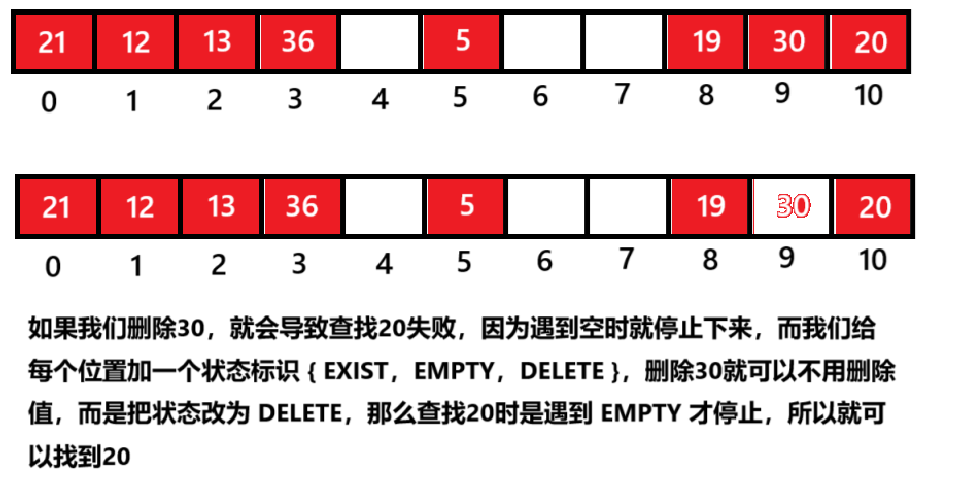
};要注意的是这⾥需要给每个存储值的位置加⼀个状态标识,否则删除⼀些值以后,会影响后⾯冲突的值的查找
②扩容
这⾥我们哈希表负载因⼦控制在0.7,当负载因⼦到0.7以后我们就需要扩容了,我们还是按照2倍扩容,但是同时我们要保持哈希表⼤⼩是⼀个质数,第⼀个是质数,2倍后就不是质数了,那该如何解决这个问题呢?
一种方案是 sgi 版本的哈希表使⽤的⽅法,给了⼀个近似2倍的质数表,每次去质数表获取扩容后的⼤⼩,还有一种就是上面介绍的JAVA HashMap使用2的整数幂
inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;__stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291
};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}③key不能取模问题
当 key 是 string/Date 等类型时,key 不能取模,那么我们需要给 HashTable 增加⼀个仿函数,这个仿函数⽀持把 key 转换成⼀个可以取模的整形,如果 key 可以转换为整形并且不容易冲突,那么这个仿函数就⽤默认参数即可,如果这个key 不能转换为整形,我们就需要⾃⼰实现⼀个仿函数传给这个参数,实现这个仿函数的要求就是尽量 key 的每值都参与到计算中,让不同的key转换出的整形值不同
(string 做哈希表的 key ⾮常常⻅,所以我们可以考虑把 string 特化⼀下)
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};// 特化
template<>
struct HashFunc<string>
{// 字符串转换成整形,可以把字符ascii码相加即可// 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的// 这⾥我们使⽤BKDR哈希的思路,⽤上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131等效果会⽐较好size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 131;hash += e;} return hash;}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{ public:private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数
};④完整代码
namespace open_address
{enum State{EXIST,EMPTY,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}HashTable(){_tables.resize(__stl_next_prime(1));}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 扩容if ((double)_n / (double)_tables.size() >= 0.7){// 获取素数表里面比当前表大的下一个素数size_t newsize = __stl_next_prime(_tables.size() + 1);HashTable<K, V, Hash> newHT;newHT._tables.resize(newsize);// 遍历旧表,将数据都映射到新表for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}_tables.swap(newHT._tables);}Hash hs;size_t hash0 = hs(kv.first) % _tables.size();size_t i = 1;size_t hashi = hash0;while (_tables[hashi]._state == EXIST){// 线性探测hashi = (hash0 + i) % _tables.size();++i;}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}HashData<K, V>* Find(const K& key){Hash hs;size_t hash0 = hs(key) % _tables.size();size_t i = 1;size_t hashi = hash0;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST &&_tables[hashi]._kv.first == key){return &_tables[hashi];}hashi = (hash0 + i) % _tables.size();++i;}return nullptr;}bool Erase(const K& key){// 伪删除 --> 就是不删除这个值,只是把这个值的标识状态改了,比如存在改为删除HashData<K, V>* del = Find(key);if (del == nullptr){return false;}else{del->_state = DELETE;--_n;return true;}}private:vector<HashData<K, V>> _tables;size_t _n = 0;};
}c.链地址法
①思路
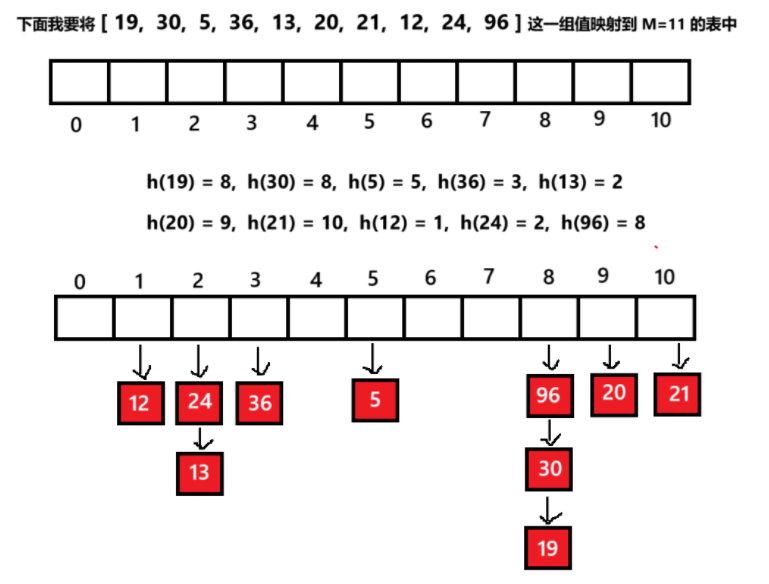
开放定址法中所有的元素都放到哈希表⾥,链地址法中所有的数据不再直接存储在哈希表中,哈希表中存储⼀个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据链接成⼀个链表,挂在哈希表这个位置下⾯,链地址法也叫做拉链法或者哈希桶
②扩容
开放定址法负载因⼦必须⼩于1,链地址法的负载因⼦就没有限制了,可以⼤于1。负载因⼦越⼤,哈希冲突的概率越⾼,空间利⽤率越⾼;负载因⼦越⼩,哈希冲突的概率越低,空间利⽤率越低;而 stl 中 unordered_xxx 的最⼤负载因⼦基本控制在1,⼤于1就扩容,我们下⾯实现也使⽤这个⽅式
如果极端场景下,某个桶特别⻓怎么办?其实我们可以考虑使⽤全域散列法,这样就不容易被针对了。而在JAVA HashMap中当桶的长度超过一定阈值时,就把链表转换成红黑树(这里我们就不实现的这么复杂,大家了解一下即可)
③完整代码
namespace hash_bucket
{template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}};template<class K, class V>class HashTable{typedef HashNode<K, V> Node;public:inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}HashTable(){_tables.resize(__stl_next_prime(1), nullptr);}// 哈希桶的销毁~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}// 插入值为data的元素,如果data存在则不插入bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因子到1就扩容if (_n == _tables.size()){size_t newsize = __stl_next_prime(_tables.size() + 1);vector<Node*> newtables(newsize, nullptr);// 遍历旧表,把旧表的节点挪动到新表for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// cur头插到新表size_t hashi = cur->_kv.first % newsize;cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}size_t hashi = kv.first % _tables.size();Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}// 在哈希桶中查找值为key的元素,存在返回true否则返回falseNode* Find(const K& key){size_t hashi = key % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}// 哈希桶中删除key的元素,删除成功返回true,否则返回falsebool Erase(const K& key){size_t hashi = key % _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key){if (prev == nullptr){// 头删_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;size_t _n = 0;};
}用哈希表封装 myunordered_map 和 myunordered_set
1>源码及框架分析
SGI-STL30版本源代码中没有 unordered_map 和 unordered_set,SGI-STL30版本是C++11之前的STL版本,这两个容器是C++11之后才更新的。但是SGI-STL30实现了哈希表,不过容器的名字是 hash_map 和 hash_set,它是作为⾮标准的容器出现的,⾮标准是指⾮C++标准规定必须实现的
下面是 hash_map 和 hash_set 的实现结构框架核⼼部分
// stl_hash_set
template <class Value, class HashFcn = hash<Value>,class EqualKey = equal_to<Value>,class Alloc = alloc>
class hash_set
{
private:typedef hashtable<Value, Value, HashFcn, identity<Value>,EqualKey, Alloc> ht;ht rep;public:typedef typename ht::key_type key_type;typedef typename ht::value_type value_type;typedef typename ht::hasher hasher;typedef typename ht::key_equal key_equal;typedef typename ht::const_iterator iterator;typedef typename ht::const_iterator const_iterator;hasher hash_funct() const { return rep.hash_funct(); }key_equal key_eq() const { return rep.key_eq(); }
}// stl_hash_map
template <class Key, class T, class HashFcn = hash<Key>,class EqualKey = equal_to<Key>,class Alloc = alloc>
class hash_map
{
private:typedef hashtable<pair<const Key, T>, Key, HashFcn,
select1st<pair<const Key, T> >, EqualKey, Alloc> ht;ht rep;public:typedef typename ht::key_type key_type;typedef T data_type;typedef T mapped_type;typedef typename ht::value_type value_type;typedef typename ht::hasher hasher;typedef typename ht::key_equal key_equal;typedef typename ht::iterator iterator;typedef typename ht::const_iterator const_iterator;
}// stl_hashtable.h
template <class Value, class Key, class HashFcn,class ExtractKey, class EqualKey,class Alloc>
class hashtable {
public:typedef Key key_type;typedef Value value_type;typedef HashFcn hasher;typedef EqualKey key_equal;private:hasher hash;key_equal equals;ExtractKey get_key;typedef __hashtable_node<Value> node;vector<node*,Alloc> buckets;size_type num_elements;public:typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> iterator;pair<iterator, bool> insert_unique(const value_type& obj);const_iterator find(const key_type& key) const;
};template <class Value>
struct __hashtable_node
{__hashtable_node* next;Value val;
};• 通过源码可以看到,结构上 hash_map 和 hash_set 跟 map 和 set 的完全类似,复⽤同⼀个 hashtable 实现 key 和 key/value 结构,hash_set 传给hash_table 的是两个key,hash_map 传给 hash_table 的是 pair<const key, value>
• 需要注意的是源码⾥⾯跟map/set源码类似,命名⻛格⽐较乱,下面我就根据自己的习惯来写
2>模拟实现
a.复用框架
• 参考源码框架,unordered_map 和 unordered_set 复⽤之前我们实现的哈希表,这里相比源码调整一下,key参数就⽤K,value参数就⽤V,哈希表中的数据类型,我们使⽤T
• unordered_map 和 unordered_set 的模拟实现类结构相对会复杂⼀点,但是⼤框架和思路是完全类似的。因为 HashTable 实现了泛型不知道T参数导致是K,还是pair<K, V>,那么 insert 内部进⾏插⼊时要⽤K对象转换成整形取模和K⽐较相等,因为 pair 的 value 不参与计算取模,且默认⽀持的是 key 和 value ⼀起⽐较相等,我们在任何时候只需要⽐较K对象,所以我们在unordered_map和unordered_set层分别实现⼀个MapKeyOfT和SetKeyOfT的仿函数传给HashTable的KeyOfT,然后HashTable中通过KeyOfT仿函数取出T类型对象中的K对象,再转换成整形取模和K⽐较相等
MyUnorderedSet.h
namespace tianci
{template<class K, class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:bool insert(const K& key){return _ht.Insert(key);}private:hash_bucket::HashTable<K, K, SetKeyOfT, Hash> _ht;};
}MyUnorderedMap.h
namespace tianci
{template<class K, class V, class Hash = HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:bool insert(const pair<K, V>& kv){return _ht.Insert(kv);}private:hash_bucket::HashTable<K, pair<K, V>, MapKeyOfT, Hash> _ht;};
}HashTable.h
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};namespace hash_bucket
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}};template<class K, class T, class KeyOfT, class Hash>class HashTable{typedef HashNode<T> Node;inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last? *(last - 1) : *pos;}public:HashTable(){_tables.resize(__stl_next_prime(_tables.size()), nullptr);}~HashTable(){// 依次把每个桶释放for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const T& data){KeyOfT kot;if (Find(kot(data)))return false;Hash hs;size_t hashi = hs(kot(data)) % _tables.size();// 负载因子==1扩容if (_n == _tables.size()){std::vector<Node*> newtables(__stl_next_prime(_tables.size()), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 旧表中结点,挪动新表重新映射的位置size_t hashi = hs(kot(cur->_data)) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}// 头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 表中存储数据个数};
}b.iterator的实现
①核⼼源代码
template <class Value, class Key, class HashFcn,class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>hashtable;typedef __hashtable_iterator<Value, Key, HashFcn,ExtractKey, EqualKey, Alloc>iterator;typedef __hashtable_const_iterator<Value, Key, HashFcn,ExtractKey, EqualKey, Alloc>const_iterator;typedef __hashtable_node<Value> node;typedef forward_iterator_tag iterator_category;typedef Value value_type;node* cur;hashtable* ht;__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}__hashtable_iterator() {}reference operator*() const { return cur->val; }
#ifndef __SGI_STL_NO_ARROW_OPERATORpointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */iterator& operator++();iterator operator++(int);bool operator==(const iterator& it) const { return cur == it.cur; }bool operator!=(const iterator& it) const { return cur != it.cur; }
};template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++()
{const node* old = cur;cur = cur->next;if (!cur) {size_type bucket = ht->bkt_num(old->val);while (!cur && ++bucket < ht->buckets.size())cur = ht->buckets[bucket];}return *this;
}②思路分析
• iterator实现的⼤框架跟list的iterator思路是⼀致的,⽤⼀个类型封装结点的指针,再通过重载运算符实现,迭代器像指针⼀样访问的⾏为,要注意的是哈希表的迭代器是单向迭代器
• 这⾥的难点是operator++的实现。iterator中有⼀个指向结点的指针,如果当前桶下⾯还有结点,则结点的指针指向下⼀个结点即可。如果当前桶⾛完了,则需要想办法计算找到下⼀个桶。这⾥的难点是反⽽是结构设计的问题,参考上⾯的源码,我们可以看到iterator中除了有结点的指针,还有哈希表对象的指针,这样当前桶⾛完了,要计算下⼀个桶就相对容易多了,⽤key值计算出当前桶位置,依次往后找下⼀个不为空的桶即可
• begin()返回第⼀个桶中第⼀个节点指针构造的迭代器,这⾥end()返回迭代器可以⽤空表⽰
• unordered_set 的 iterator 也不⽀持修改,我们把 unordered_set 的第⼆个模板参数改成 const K 即可, HashTable<K, const K, SetKeyOfT, Hash> _ht; unordered_map 的 iterator 不⽀持修改 key 但是可以修改 value,我们把unordered_map 的第⼆个模板参数 pair 的第⼀个参数改成 const K 即可, HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct __HTIterator
{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef __HTIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;Node* _node;const HT* _ht;__HTIterator(Node* node, const HT* ht):_node(node),_ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}{++hashi;}}if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}
};c.map支持[]
• unordered_map要⽀持[]主要需要修改 insert 返回值⽀持,修改 HashTable 中的 insert 返回值为 pair<Iterator, bool> Insert(const T& data)
d.代码实现
unorderedset.h
namespace tianci
{template<class K, class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}private:hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;};void Print(const unordered_set<int>& s){unordered_set<int>::const_iterator it = s.begin();while (it != s.end()){// *it += 1;cout << *it << " ";++it;}cout << endl;}void test_set1(){unordered_set<int> s;s.insert(1);s.insert(12);s.insert(54);s.insert(107);unordered_set<int>::iterator it = s.begin();while (it != s.end()){// *it += 1;cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;Print(s);}
}unorderedmap.h
namespace tianci
{template<class K, class V, class Hash = HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}private:hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};void Print(const unordered_map<string, string>& dict){unordered_map<string, string>::const_iterator it = dict.begin();while (it != dict.end()){//it->first += 'x';//it->second += 'x';cout << it->first << " " << it->second;++it;}cout << endl;}void test_map1(){unordered_map<string, string> dict;unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()){//it->first += 'x';it->second += 'x';cout << it->first << " " << it->second;++it;}cout << endl;string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };unordered_map<string, int> countMap;for (const auto& str : arr){countMap[str]++;}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;Print(dict);}
}HashTables.h
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}
};namespace hash_bucket
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};// 前置声明template<class K, class T, class KeyOfT, class Hash>class HashTable;template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>struct __HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef __HTIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;Node* _node;const HT* _ht;__HTIterator(Node* node, const HT* ht):_node(node),_ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}{++hashi;}}if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};template<class K, class T, class KeyOfT, class Hash>class HashTable{template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct __HTIterator;typedef HashNode<T> Node;public:typedef __HTIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;typedef __HTIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}HashTable(){_tables.resize(__stl_next_prime(1), nullptr);}// 哈希桶的销毁~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}Iterator Begin(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];if (cur){return Iterator(cur, this);}}return End();}Iterator End(){return Iterator(nullptr, this);}ConstIterator Begin()const{for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];if (cur){return ConstIterator(cur, this);}}return End();}ConstIterator End()const{return ConstIterator(nullptr, this);}// 插入值为data的元素,如果data存在则不插入pair<Iterator, bool> Insert(const T& data){KeyOfT kot;Hash hs;Iterator it = Find(kot(data));if (it != End())return { it, false };// 负载因子到1就扩容if (_n == _tables.size()){size_t newsize = __stl_next_prime(_tables.size() + 1);vector<Node*> newtables(newsize, nullptr);// 遍历旧表,把旧表的节点挪动到新表for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// cur头插到新表size_t hashi = hs(kot(cur->_data)) % newsize;cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}size_t hashi = hs(kot(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return { Iterator(newnode, this), true };}// 在哈希桶中查找值为key的元素,存在返回true否则返回falseIterator Find(const K& key){Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return Iterator(cur, this);}cur = cur->_next;}return End();}// 哈希桶中删除key的元素,删除成功返回true,否则返回falsebool Erase(const K& key){Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr;while (cur){if (kot(cur->_data) == key){if (prev == nullptr){// 头删_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;size_t _n = 0;};
}本篇文章到这里就结束啦,希望这些内容对大家有所帮助!
下篇文章见,希望大家多多来支持一下!
感谢大家的三连支持!