【Fine-Tuning】大模型微调高阶技术点概要
关于大模型微调的核心问题及其详细解答,涵盖核心数学原理和工业实践细节。不掌握或者理解这些高阶技术点,就无法深入调试或者测试微调完成的大模型,无法更好的衡量效果。

高级数学原理类
1. 问:微调中的 Catastrophic Forgetting 是什么?如何缓解?
答:Catastrophic Forgetting 是指模型在新任务训练中忘记预训练知识的现象。
缓解方法包括:
-
- 弹性权重整合(EWC): 通过正则化约束关键参数的变化,增加惩罚项 L=Ltask+λ∑iFi(θi−θi∗)2 ,其中 Fi 是 Fisher 信息矩阵。
- 渐进解冻(Progressive Freezing): 从顶层开始解冻逐层参数。
- 多任务学习(Multi-Task Learning): 同时训练多任务损失函数 L=∑twtLt 。
2. 问:如何从优化理论角度解释微调过程中常见的梯度爆炸和消失现象?
答:梯度爆炸与消失由链式求导导致梯度幅值在深层传播时呈指数增长或衰减: ∂θ=∏i=1n∂zi∂zi−1。
缓解方法:
-
- 梯度裁剪(Gradient Clipping): 限制梯度范数 ||g||≤τ 。
- 激活函数选择: 使用 ReLU 减少梯度消失,LayerNorm 稳定梯度传播。
优化与技术细节类
3. 问:什么是微调中的学习率调度器(Learning Rate Scheduler)?有哪些常见策略? 答:学习率调度器控制学习率动态变化以优化训练:
-
- 线性衰减:ηt=η0(1−tT) 。
- 余弦退火(Cosine Annealing):ηt=ηmin+ηmax−ηmin2(1+cos(tTπ)) 。
- Warmup: 初始阶段学习率缓慢增长,减小训练不稳定性。
4. 问:什么是基于梯度的参数剪枝技术?如何在微调中应用? 答:基于梯度的剪枝通过计算梯度敏感度筛选不重要参数:
-
- 方法: 对参数 θi\theta_i 的重要性评估 Si=∂L∂θi⋅θi 。
- 应用: 剪枝后重新训练微调模型,提高计算效率。
数据与实验设计类
5. 问:如何设计一个对抗样本增强的数据微调流程?
答:对抗样本增强通过生成对抗性输入扩展数据集:
-
- 生成方法: 添加微扰 x′=x+ϵ⋅sign(∇xL(x,y)) 。
- 流程: 对抗样本和原始样本联合训练,提升鲁棒性。
6. 问:如何量化数据集不平衡对微调效果的影响?
答:
- 影响分析: 数据分布不均导致模型偏向多数类。
- 量化指标: Gini 系数或 Shannon 熵衡量数据不平衡性。
- 缓解方法: 采样技术(过采样/欠采样)或类别加权损失。
架构与算法类
7. 问:微调中 LayerNorm 的作用是什么?其数学公式是什么?
答:LayerNorm 正则化隐藏层输出以提高训练稳定性:
x^i=xi−μσ2+ϵ, μ=1H∑i=1Hxi , σ2=1H∑i=1H(xi−μ)2 。
8. 问:为什么微调中需要残差连接(Residual Connection)?
答:残差连接通过跳过非线性变换缓解梯度消失
hl=f(hl−1)+hl−1 。
它使优化更易于收敛,尤其在深层网络中。
工业实践类
9.问:如何在微调中实现模型量化以减少推理成本?
答:模型量化将权重和激活从 32 位浮点数压缩为 8 位整型:
-
- 静态量化: 量化后固定比例。
- 动态量化: 运行时动态调整比例。
10. 问:如何评估微调模型的公平性?
答:通过检测不同子群体的性能差异:
-
- 指标: Demographic Parity、Equal Opportunity。
- 缓解: 数据重采样或任务损失加权。
前沿技术与发展方向类
11. 问:在微调中,LoRA 是如何实现矩阵分解的?公式是什么?
答:LoRA 用低秩分解替代全矩阵更新:
ΔW=ABT, A∈Rd×r , B∈Rd×r ,其中 r≪dr≪d 。
12. 问:微调中的 RLHF(人类反馈强化学习)过程是什么?
答:使用奖励模型优化生成文本:
-
- 流程: 使用 PPO 优化策略 πθ 来最大化奖励 R(x)。
- 公式:L=Ex∼πθ[R(x)]。
实验方法与实践难点类
13. 问:微调中如何选择最佳超参数?
答:通过网格搜索、随机搜索或贝叶斯优化选择学习率、批量大小等超参数。
14. 问:如何验证微调后模型对未知任务的迁移能力?
答:使用 zero-shot 评估任务性能,验证模型的泛化能力。
15. 问:如何设计实验分析微调的边际效益?
答:逐步增加训练数据量,绘制性能增长曲线(log-log scale)。
应用与趋势探索类
16. 问:如何在联邦学习场景中实现微调?
答:通过联合优化本地损失和全局一致性:
L=∑knkNLk+λD(Wk,Wglobal) 。
17. 问:指令微调(Instruction Fine-Tuning)与传统微调的区别是什么?
答:指令微调通过多任务指令数据扩展模型泛化能力,而传统微调针对单一任务优化。
18. 问:多模态微调的关键技术是什么?
答:设计共享表示层,将图像、文本等模态投影到同一特征空间。
19. 问:微调中如何避免隐私泄露?
答:通过差分隐私保护训练数据,添加噪声确保 ϵ−DP 。
20. 问:未来微调技术可能与哪些领域深度结合?
答:结合生成对抗网络(GANs)、强化学习和因果推断,提升模型泛化和解释能力。
扩充常用的10个问题
10个大语言模型微调的高阶问答题,涵盖理论、技术和实践,带有详细解答,供大家深入学习和评估之用。
1. 微调中的 Dropout 如何缓解过拟合?它的作用机制是什么?
答:Dropout 是一种随机正则化技术,在训练时通过随机丢弃神经元及其连接来降低过拟合的风险。具体机制如下:
- 作用机制:
- 随机丢弃: 在每次训练迭代中,按照一定概率 pp,随机将某些神经元的输出设为 0。公式为:
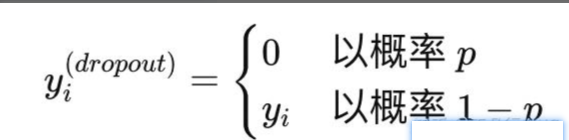
- 降低相互依赖: 通过减少神经元之间的协同适应(co-adaptation),促使模型学习更加鲁棒的特征表示。
- 推断时缩放: 在测试阶段,所有神经元保持激活状态,但其输出按 (1−p)(1-p) 缩放以平衡训练阶段的激活。
- 优点: Dropout 不仅降低了过拟合,还提升了泛化能力,尤其是在深层模型中。
2. 微调中 Batch Normalization 如何加速收敛?与 LayerNorm 有何区别?
答:Batch Normalization(BN)通过对每个 mini-batch 的激活值进行归一化来稳定训练过程,加速收敛:
- 数学公式:
对输入特征 xx 归一化:
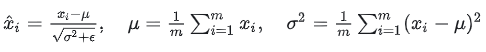
- 并通过可训练参数 γ,β 恢复尺度:
yi=γx^i+β - 作用:
- 减少梯度消失和爆炸的风险。
- 允许更高的学习率,提高收敛速度。
- 与 LayerNorm 的区别:
- BN 在 mini-batch 内归一化,适合大批量训练;LayerNorm 在单个样本的特征维度上归一化,适合小批量或自回归任务。
3. 为什么微调时常采用混合精度训练?它有哪些技术细节?
答:
混合精度训练结合 16 位(FP16)和 32 位(FP32)浮点运算,降低显存使用的同时提升计算效率。
- 技术细节:
- FP16 应用: 权重、激活值使用 FP16 表示以节省显存。
- FP32 应用: 梯度累积和损失计算使用 FP32,避免数值下溢和梯度不稳定。
- 动态损失缩放: 通过动态调整缩放因子(loss scaling)避免 FP16 下的梯度溢出或下溢。公式为:
![]()
- 优势: 提高计算速度 1.5-2 倍,同时减少显存占用。
4. 微调中的 Early Stopping 如何优化模型性能?有哪些风险?
答:
Early Stopping 是在验证集性能不再提高时提前终止训练的技术,避免过拟合。
- 实现方法:
- 定义监控指标(如验证损失或 F1 分数)。
- 设置耐心值(patience):若指标在若干轮内无提升,停止训练。
- 优点:
- 减少训练时间。
- 避免模型对训练数据的过拟合。
- 风险:
- 可能导致欠拟合,特别是在验证集波动较大时。
- 耐心值设置不当可能错过模型的潜在提升。
5. 在大模型微调中,如何设计高效的多任务学习流程?
答:
多任务学习(MTL)通过共享模型参数同时学习多个任务,提升任务间的协同效果。
- 设计要点:
- 共享与特定层: 共享底层参数,同时为特定任务设计单独的顶层。
- 多任务损失函数: 联合优化多个任务损失: LMTL=∑i=1nwiLi 其中 w_i 是任务权重,可动态调整。
- 权重平衡: 使用自适应加权方法(如动态不确定性加权)自动分配任务权重。
6. 如何基于因果推断的视角改进微调方法?
答:
微调过程中,因果推断可用于揭示数据与模型预测间的因果关系。
- 方法:
- 建立因果图(Causal Graph):描述特征、目标变量及其因果关系。
- 使用因果推断方法,如偏差校正或逆概率加权(IPW)。
- 校正潜在混淆变量对训练数据的影响,增强模型的泛化能力。
7. 微调中的 Adapter 模块是什么?如何工作?
答:Adapter 模块是参数高效微调的一种方法,通过插入小型瓶颈层调整模型输出。

- 优势:
- 不改变预训练权重。
- 存储需求低,适合多任务场景。
8. 如何设计微调实验来分析模型对噪声的鲁棒性?
答:通过添加不同类型的噪声评估模型鲁棒性:
- 添加噪声: 对输入或标签引入高斯噪声、对抗性扰动或错标。
- 评估指标: 使用准确率下降或 KL 散度量化模型性能变化。
- 实验变量: 比较不同微调方法(如全参数、LoRA)的鲁棒性差异。
9. 在微调中如何处理低资源任务?
答:通过数据扩展和高效优化提升低资源任务的性能:
- 数据扩展: 使用数据增强、合成或翻译扩展小规模数据集。
- 预训练迁移: 从相关领域模型迁移特征。
- 技术优化: 使用 LoRA、Adapter 等减少对大规模数据的依赖。
10. 如何设计模型以实现持续学习的微调?
答:持续学习(Continual Learning)旨在学习新任务时保留旧任务性能:
- 基于记忆的方法: 使用回放机制存储历史数据或梯度信息。
- 正则化方法: EWC、MAS 等通过正则化保护关键参数。
- 模块化设计: 不同任务使用独立模块,同时共享底层特征。