Python中的组合数据类型
一、列表类型
列表是指一系列的按特定顺序排列的元素组成。使用[]定义列表,元素与元素之间使用英文的逗号分隔,列表中的元素可以是任意的数据类型。
#直接使用[]创建
lst=['hello','world',99.8,100]
print(lst)#可以使用内置的list()函数创建列表
lst2=list('helloworld')
lst3=list(range(1,10,2)) #从1开始,到10结束(不包含10),步长为2
print(lst2)
print(lst3)#列表中序列中的一种,对序列操作的运算符,操作符,函数均可以使用
print(lst+lst2+lst3) # 序列中的相加操作
print(lst*3) #相乘的操作
print(len(lst))
print(max(lst3))
print(min(lst3))
print(lst2.count('o')) # 统计o的个数
print(lst2.index('o')) #o在列表lst2中第一次出现的位置#列表的删除操作lst4=[10,20,30]
print(lst4)
# 删除列表
del lst4
#print(lst4)#NameError: name 'lst4' is not defined 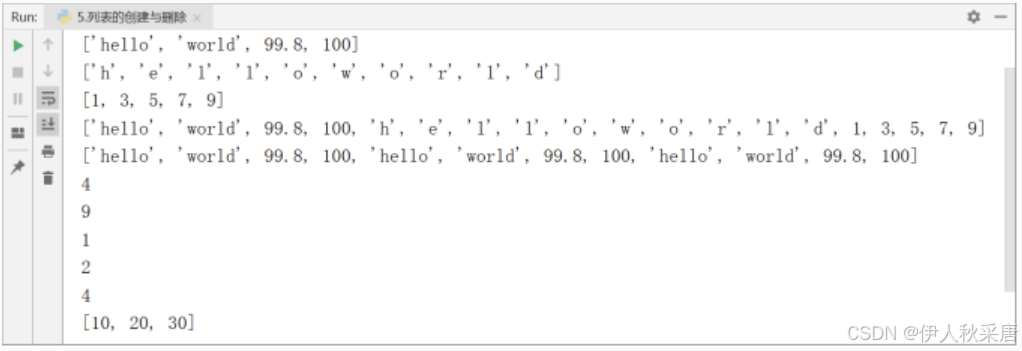
遍历列表
lst=['hello','world','python','php']
# 使用遍历循环for遍历列表元素
for item in lst:print(item)# 使用for循环,range()函数,len()函数,根据索引进行遍历
for i in range(len(lst)):print(i,'-->',lst[i])#使用for循环与enumerate()函数,进行遍历
for index,item in enumerate(lst): #默认序号从0开始print(index,item)for index,item in enumerate(lst,1): #序号从1开始print(index, item)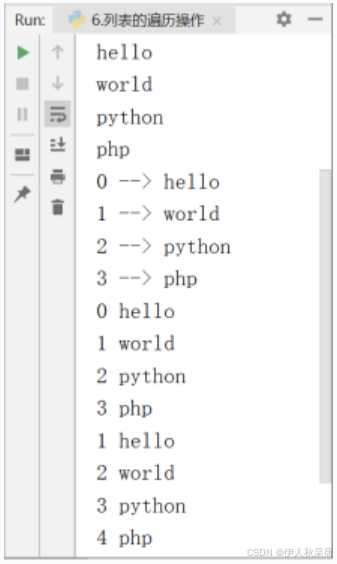
最后一个for循环for index,item in enumerate(lst,1)将序号设置为从1开始,但并没有改变索引,索引依然从0开始。
| 列表的方法 | 描述说明 |
| lst.append(x) | 在列表中第index位置增加一个元素 |
| lst.insert(index,x) | 在列表中第index位置增加一个元素 |
| lst.clear() | 清除列表lst中所有元素 |
| lst.pop(index) | 将列表lst中第index位置的元素取出,并从列表中将其删除 |
| lst.remove(x) | 将列表lst中出现的第一个元素x删除 |
| lst.reverse(x) | 将列表lst中的元素反转 |
| lst.copy() | 拷贝列表lst中的所有元素,生成一个新的列表 |
# coding:utf-8
lst=['hello','world','python']
print('原列表:',lst,id(lst))#新增元素的操作
lst.append('sql')
print('增加元素之后',lst,id(lst))#使用insert(index,x)在指定的位置上插入元素
lst.insert(1,100)
print(lst)#列表元素的删除操作
lst.remove('world')
print('删除元素之后的列表',lst,id(lst))#使用pop(index)根据索引移出元素,先将元素取出,再将元素删除
print(lst.pop(1))
print(lst)#清除列表中所有的元素clear()
#lst.clear()
#print(lst,id(lst))#列表反向
lst.reverse()
print(lst)#列表的拷贝,将产生一个新的列表对象
new_lst=lst.copy()
print(lst,id(lst))
print(new_lst,id(new_lst))#列表元素的修改
#根据索引进行修改元素
lst[1]='mysql'
print(lst)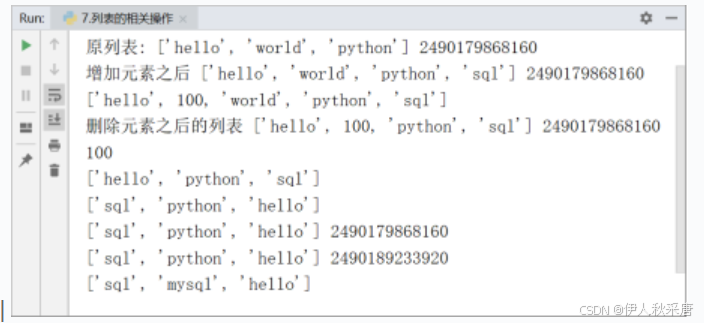
# coding:utf-8
lst=[4,56,3,78,40,56,89]
print('原列表:',lst)
#排序,默认是升序
lst.sort() # lst.sort(reverse=False)
print('升序:',lst)#排序,降序
lst.sort(reverse=True)
print('降序:',lst)print('------------------------')
lst2=['banana','apple','Cat','Orange']
print('原列表:',lst2)
#升序排序 ,先排大写,再排小写
lst2.sort()
print('升序:',lst2)#降序 先排小写,后排大写
lst2.sort(reverse=True)
print('降序:',lst2)#忽略大小写进行比较
lst2.sort(key=str.lower)
print(lst2)
# coding:utf-8
lst=[4,56,3,78,40,56,89]
print('原列表:',lst)
#排序
asc_lst=sorted(lst)
print('升序:',asc_lst)
print('原列表:',lst)#降序
desc_lst=sorted(lst,reverse=True)
print('降序:',desc_lst)
print('原列表:',lst)lst2=['banana','apple','Cat','Orange']
print('原列表:',lst2)#忽略大小写的排序
new_lst2=sorted(lst2,key=str.lower)
print('原列表:',lst2)
print('排序后的列表:',new_lst2)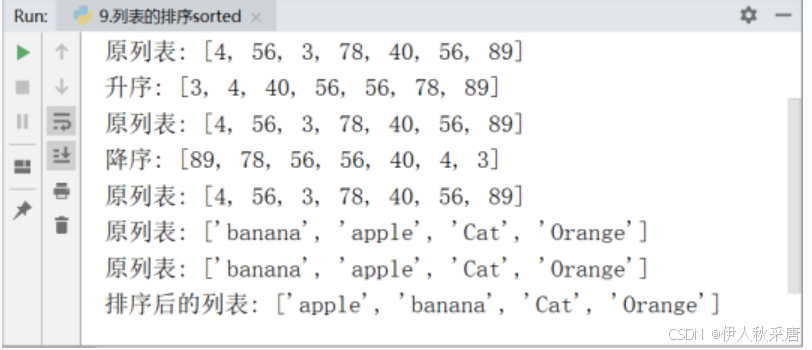
二维表
# coding:utf-8
# 创建二维列表
lst=[['城市','环比','同比'],['北京',102,103],['上海',104,504],['深圳',100,39]
]
print(lst)
#
for row in lst: #行for item in row:#列print(item,end='\t')print()#换行# 列表生成式生成一个四行五列的二维列表
lst2=[[j for j in range(5)] for i in range(4)]
print(lst2)
二、元组类型
元组是Python中的不可变数据类型,它没有增、删、改的一系统列操作方法,对于元组类型只可以使用索引获取元素和使用for循环遍历元素。
# coding:utf-8
# 直接使用()创建元组
t=('hello',[10,20,30],'python','world')
print(t)# 使用内置tuple()创建元组
t=tuple('helloworld')
print(t)t=tuple([10,20,30,40])
print(t)t=tuple(range(1,10))
print(t)# 元组的相关操作
print('10在元组中是否存在:',(10 in t))
print('10在元组中不存在:',(10 not in t))
print('max:',max(t))
print('min:',min(t))
print('len:',len(t))
print('t.index:',t.index(1))
print('t.count:',t.count(3))x=(10)
print(x,type(x))y=(10,) #元组中只有一个元素,逗号不能省
print(y,type(y))#元组的删除
del t
#print(t)三、字典类型
与列表和元组类型不同,字典类型是根据一个信息查找另一个信息的方式构成了“键值对”,它表示索引用的键和对应的值构成的成对关系。
典中没有整数索引的概念,要想检索字典中的元素只能通过键(key)
# coding:utf-8
# (1)直接使用{}创建
d={10:'cat',20:'dog',30:'pet',20:'zoo'} # key相同,值进行覆盖
print(d)#zip函数的使用
lst1=[10,20,30,40]
lst2=['cat','dog','car','zoo']
zipobj=zip(lst1,lst2) #映射函数的结果是一个zip对象
#print(zipobj)
#print(list(zipobj))
d=dict(zipobj)
print(d)#使用参数创建字典
d=dict(cat=10,dog=20) # 注意事项,参数相当于变量,变量的名字不加引号
print(d)t=(10,20,30) # 创建一个元组
print({t:10})#lst=[10,20,30] #TypeError: unhashable type: 'list'
#print({lst:10}) 因为列表是可变数据类型#字典属于序列类型
print('max:',max(d))
print('min:',min(d))
print('len:',len(d))#字典的删除
del d
print(d)字典的遍历
# coding:utf-8
d={'hello':10,'world':20,'python':30}
# 访问字典中的元素
# (1)使用[key]
print(d['hello'])
#(2)使用d.get(key)
print(d.get('hello'))#二者之间是有区别的,如果Key不存在时d[key]报错,而使用get(key)可以指定默认值
#print(d['java'])#KeyError: 'java'
print(d.get('java')) #None
print(d.get('java','不存在'))# 字典的遍历
for item in d.items():print(item) #key-value组成的一个元组#在使用for循环遍历时,分别获取key和value
for key,value in d.items():print(key, value)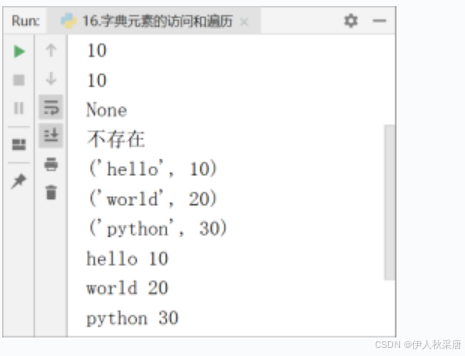
| 字典的方法 | 描述说明 |
| d.keys() | 获取所有的key数据 |
| d.values() | 获取所有的value数据 |
| d.pop(key,default) | key存在获取相应的value,同时删除key-value对,否则获取默认值 |
| d.popitem() | 随机从字典中取出一个key-value对,结果为元组类型,同时将该key-value从字典中删除 |
| d.clear() | 清空字典中所有的key-value对 |
# coding:utf-8
d={1001:'李梅',1002:'王华',1003:'张峰'}
print(d)
#向字典中添加数据
d[1004]='张丽丽' #直接使用赋值运算符=向字典中添加元素
print(d)#获取字典中所有的key
keys=d.keys() # d.keys()结果是dict_keys ,Python中的一种内部数据类型, 专用于表示字典的key
#如果希望更好的显示数据,可以使用list或者tuple转成相应的数据类型print(keys)
print(list(keys))
print(tuple(keys))#获取字典中所有的value
values=d.values()
print(values) #dict_values
print(list(values))
print(tuple(values))#字典遍历的时用到的一个方法items
items=d.items() #dict_items
print(items)
print(list(items))
print(tuple(items))lst=list(items) #将字典中的数据转成键-值对的形式,以元组的方式进行展示
print(lst)#直接可以使用dict函数将[(1001, '李梅'), (1002, '王华'), (1003, '张峰'), (1004, '张丽丽')]转成字典
d=dict(lst)
print(d)#使用pop函数
print(d.pop(1001))
print(d)
print(d.pop(1008,'不存在')) #如果Key不存在,结果输出默认值"不存在"#随机删除
print(d.popitem()) #先获取key-value对
print(d)#清空字典中所有的元素
d.clear()
print(d)#Python中一切皆对象,而每一个对象都一个布尔值
print(bool(d)) #空字典的bool值为False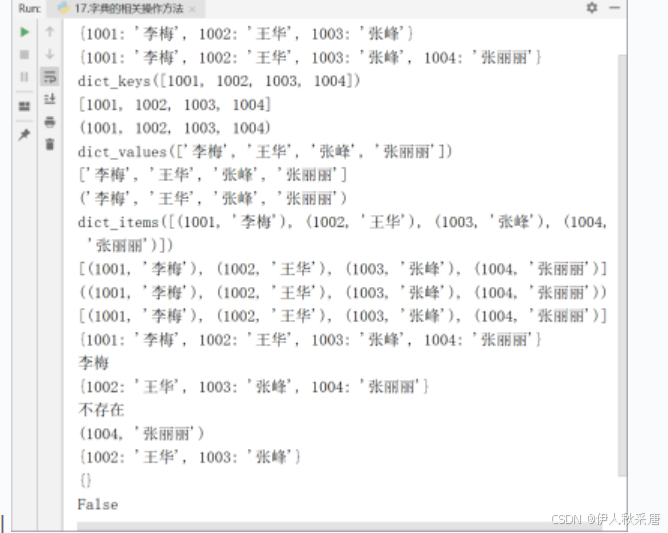
四、集合类型
Python中的集合与数学中集合的概念一致,是一个无序的不重复元素序列,所以集合中的元素要求唯一,由于集合的底层数据结构与字典中key的数据结构相同都是使用了Hash表,所以集合中只能存储不可变数据类型(字符串、整数、浮点数、元组)。在Python中字典使用{}定义,集合也使用{}定义,元素之间使用英文的逗号进行分隔。集合与列表、字典一样,都是Python中的可变数据类型。
# coding:utf-8
#使用{}直接创建集合
s={10,20,30,40}
print(s)
#s={[10,20],[30,40]}#TypeError: unhashable type: 'list'
#s={([10,20]),([20,30])}
print(s)s={} # 创建的是字典还是集合呢?
print(type(s)) #<class 'dict'>字典#如何创建空集合
s=set()
print(type(s),bool(s))# 第二种创建集合的方式set()
s=set('helloworld')
s2=set([10,20,30])
s3=set(range(1,10))
print(s)
print(s2)
print(s3)#集合属于序列中的一种
print('max:',max(s3))
print('min:',min(s3))
print('len:',len(s3))print('9在集合中是否存在?',(9 in s3))
print('9在集合中不存在?',(9 not in s3))#集合的删除
del s3
#print(s3) #NameError: name 's3' is not defined
