【T2I】LoCo: Locally Constrained Training-Free Layout-to-Image Synthesis
page: 2311 无代码
LoCo
Abstract.
最近的文本到图像扩散模型在生成高质量图像方面达到了前所未有的水平。然而,它们对文本提示的完全依赖往往在图像组成的精确控制方面存在不足。在本文中,我们提出了LoCo,这是一种无需训练的布局到图像合成方法,擅长生成与文本提示和布局指令对齐的高质量图像。具体来说,我们引入了本地化注意约束(LAC),利用自注意力机制图中像素之间的语义亲和力来创建所需物体的精确表示,并有效地确保物体在指定区域的准确放置。我们进一步提出了填充令牌约束(PTC)来利用嵌入在先前被忽略的填充令牌中的语义信息,提高对象外观和布局指令之间的一致性。LoCo无缝集成到现有的文本到图像和布局到图像模型中,增强了它们在空间控制方面的性能,并解决了先前方法中观察到的语义故障。大量的实验展示了我们的方法的优越性,在多个基准测试中定性和定量地超越了现有的最先进的无需训练的图像布局方法。
Introduction
布局到图像合成(LIS)方法[1 X.: Spatext: Spatio-textual representation for controllable image
generation.,7 Layoutdiffuse: Adapting foundational diffusion models for layout-to-image generation.,10 Make-a-scene: Scene-based text-to-image generation with human priors.,18 Gligen:,19 : Image synthesis from layout with localityaware mask adaption,33 Learning layout and style reconfigurable gans for controllable image synthesis.,36 Object-centric image
generation from layouts.,45 Scenecomposer: Any-level semantic image synthesis. 46 Adding conditional control to text-to-image diffusion models.,47 Image generation from layout.]。这些方法允许用户使用各种形式的布局指令来指定对象的位置,例如,边界框、语义掩码或涂鸦。一般来说,这些布局到图像的方法可以分为两类:完全监督方法和无训练方法。
通过训练新的layout-to-image模型[38,45],或者使用辅助模块[18,24,39,46,48]增强现有的T2I模型以纳入布局指令,全监督的layout-to-image方法已经显示出显著的效果。不幸的是,这些方法需要大量成对的布局图像训练数据,这些数据既昂贵又难以获得。此外,模型的训练和微调都是计算密集型的。
相反,一项值得注意的研究[6 Training-free layout control with cross-attention guidance.,8 Zero-shot spatial layout conditioning for text-to-image diffusion models.,26 Grounded text-to-image synthesis with attention refocusing.,40 R&b: Region and boundary aware zero-shot grounded text-to-image generation.,41 Boxdiff]表明,可以通过不需要训练的方式实现布局到图像的合成。具体来说,他们通更新基于在每个时间步提取的交叉注意图的潜在特征来指导合成过程。然而,由于交叉注意图主要捕获对象的突出部分,它们作为所需对象的粗粒度和噪声表示。因此,直接使用交叉注意地图来指导合成过程只能提供有限的空间可控性。具体来说,合成的对象经常偏离它们的核心响应布局指令,导致不满意的结果。此外,这些方法还存在语义错误,如对象丢失或融合、属性绑定错误等。
为了解决这些问题,我们引入了LoCo,即局部约束扩散的缩写,这是一种新的无需训练的方法,旨在增强布局到图像的空间可控制性,并减轻以前方法面临的语义失败。具体来说,我们提出了两个新的约束,即局部注意约束(LLAC)和填充令牌约束(LPTC),以指导基于注意图的合成过程。
LLAC旨在确保所需对象的准确生成。与之前仅依赖粗粒度交叉注意图进行空间控制的方法不同,我们利用自注意力机制增强来获得所需对象的精确表示。因此,LLAC提供了更精确的空间控制,增强了交叉注意地图和布局指令之间的对齐,并纠正了语义错误。LPTC利用以前被忽略的填充标记所携带的语义信息,特别是文本嵌入中的文本起始标记([SoT])和文本结束标记([EoT])。这些标记与合成图像的布局具有重要的关联。通过利用这些信息,LPTC可以防止靠近位置的对象扩展到指定框之外,并增强对象外观和布局指令之间的一致性。
贡献:
- 我们介绍了LoCo,这是一种无需训练的布局到图像合成方法,擅长生成与文本提示和空间布局对齐的高质量图像。
- 我们提出了两个新的约束,LLAC和LPTC。前者提供了精确的空间控制,并改善了合成图像和布局指令之间的对齐。后者利用嵌入在先前被忽略的填充令牌中的语义信息,进一步增强了对象外观和布局指令之间的一致性。
- 我们进行了全面的实验,将我们的方法与现有的布局到图像合成文献中的方法进行了比较。结果表明,考虑到定量度量和定性评估,LoCo优于先前的最先进的方法。
Related Work
Text-to-image Diffusion models
Layout-to-image Synthesis
布局到图像合成(LIS)围绕生成符合提示和相应布局指令的图像展开,例如边界框或语义掩码。几种方法[1,18,21,37,38,42 - 46]建议使用成对的布局图像数据来训练新模型或对现有模型进行微调。例如,SceneComposer[45]使用图像和分割映射的成对数据集训练布局到图像的模型。同时,有几种方法[18,24,39,46,48]集成了用于布局控制的附加组件或适配器。虽然这些方法产生了值得注意的结果,但它们面临着训练数据收集的劳动密集型和耗时的挑战。此外,完全监督的管道需要额外的计算资源消耗和延长的推理时间。
另一系列方法[6,8,12,16,26,34,41]通过预训练模型的无训练方法解决了这个问题。Hertz等人[13]最初观察到生成图像的空间布局与交叉注意地图有着内在的联系。在此基础上,Directed Diffusion[23]和DenseDiffusion[16]在操纵交叉注意地图以使生成的图像与布局对齐方面处于领先地位。随后,BoxNet[37]提出了一种基于预测对象边界框的注意力掩码控制策略。一些同时进行的研究[11,12]也提出了各种调节交叉注意图的方法。令人遗憾的是,即使是最先进的无需训练的方法也无法精确控制空间,并且存在语义错误。
与我们的工作更接近的是,几种不需要训练的方法[6,8,40,41]基于交叉注意图设计能量函数来优化潜在特征,并鼓励期望的对象出现在指定区域。然而,我们的实验表明,这些方法缺乏精确的空间控制,因为它们完全依赖于在每个时间步提取的原始交叉注意地图,这些地图是所需对象的粗粒度和噪声表示。Attention-Refocusing[26]试图通过利用交叉注意和自注意地图分别进行空间控制来解决这一限制。然而,它只优化了注意图的最大值,导致生成结果不稳定,缺乏空间精度。相比之下,我们的LLAC基于精细的交叉注意图提供了准确的指导,这是对所需对象的更精确的表示。因此,LLAC增强了交叉注意图和布局指令之间的一致性,有效地解决了语义故障。Chen等人注意到一个反直觉的现象,即填充令牌,即文本开始令牌([SoT])和文本结束令牌([EoT]),固有地携带丰富的语义和布局信息。然而,这一观察结果尚未得到充分的探索和利用。我们的LPTC有效地利用嵌入在填充令牌中的信息,进一步增强了对象外观和布局指令之间的一致性。
Method
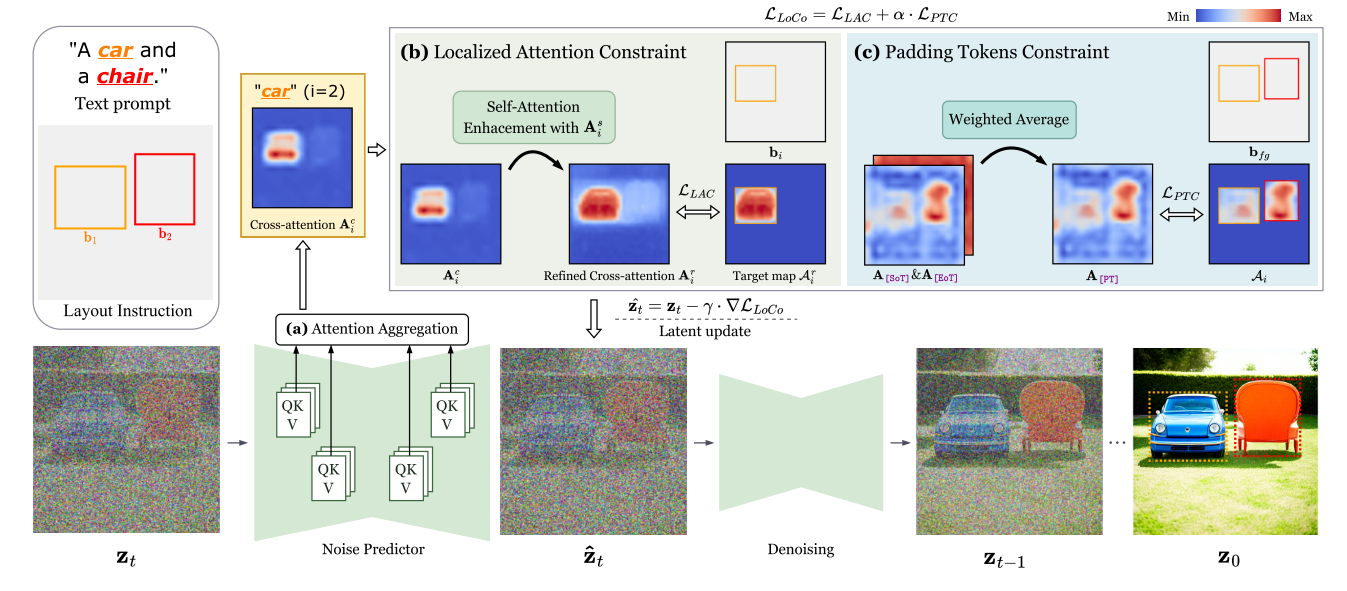
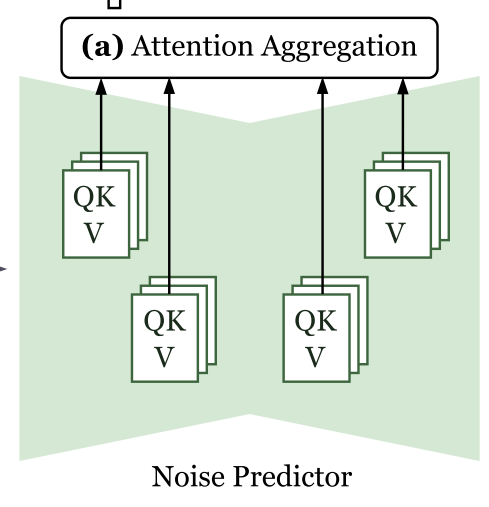
我们的方法基于从T2I扩散模型中提取的自注意力机制图和交叉注意图来指导合成过程。具体来说,LoCo包括三个步骤:(a)注意力聚合,(b)局部注意力约束和(c)填充令牌约束。我们将在以下部分中详细介绍这些步骤。
Preliminaries
Cross-attention maps.
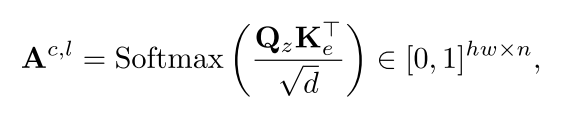 layer l, cross-attention maps
layer l, cross-attention maps
Self-attention maps.
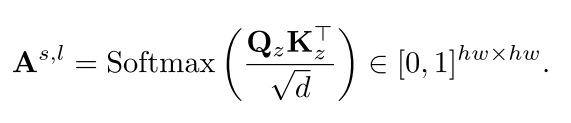
Problem setup. 为了清晰起见,我们考虑输入布局为k个边界框B = {b1,…, bk}和包含k个对应短语W = {w1, . . . ,wk}. bi表示用户提供的第i个对象的位置,wi描述了所需对象的详细信息。在应用所提出的约束之前,我们将每个边界框bi转换并调整大小为其相应的二进制掩码mask (bi)。
Attention Aggregation
在每个时间步长t,将潜在特征zt馈送到T2I模型的噪声预测器。如图图 (a)所示,我们分别对噪声预测器跨跨注意层和自注意力机制层的注意图进行聚合和平均,得到聚合关注Ac∈[0,1]hw×n, As∈[0,1]hw×hw:
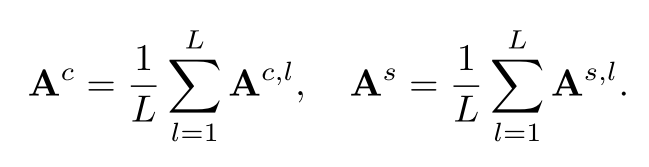
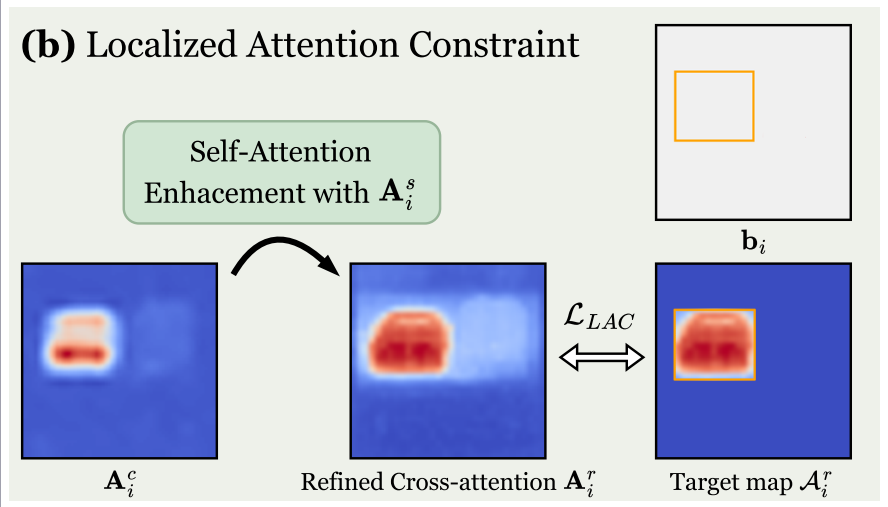
图2: LoCo概述。LoCo包括三个步骤:(a)注意力聚合,(b)局部注意力约束,(c)填充令牌约束。在时间步长为t时,我们通过噪声预测器传递潜在特征zt,提取交叉注意图Ac和自注意力机制图As。对于第i个目标,我们通过自注意力机制增强获得精细化的交叉注意图Ar i,以准确地表示目标的外观。建议的约束,即LLAC和LPTC,然后应用于鼓励注意图和布局指令之间的对齐。因此,用△LLoCo更新潜在特征zt,得到用于去噪的△zt。
Localized Attention Constraint (LLAC)
先前的研究[13,16,41]已经证明,交叉注意图中的高响应区域在感知上与解码图像中的合成物体对齐。然而,如图图 (a)所示,原始交叉注意Ac i只捕获了物体的显著部分,而忽略了非显著部分,例如边界区域。因此,它们是所需对象的粗粒度和噪声表示,不足以实现精确的空间控制。
最近关于生成合成数据集的研究[22,25]利用自关注来提高合成图像与相应分割掩码之间的一致性。受这些方法的启发,我们执行了自注意力机制增强(SAE),改进原始交叉注意Ac i∈[0,1]h×w,以便更准确地表示具有自注意力机制As∈[0,1]hw×hw的期望对象:
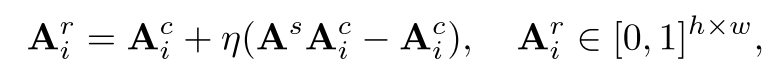
式中η控制自注意力机制的增强强度。直观上,该操作利用a中像素之间的两两语义亲和力,将交叉注意图扩展到具有高语义相似性的位置,并强化非显著区域(图 (a))。细化的交叉注意图Ar i作为第i个目标的形状和位置的改进描述。
随后,我们使用LLAC将Ar i与其关联的二进制掩码mask (bi)对齐(图 (b))。我们通过屏蔽掉目标区域以外的交叉注意地图元素来推导Ai:
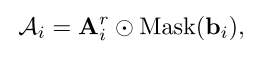
LLAC的公式为:
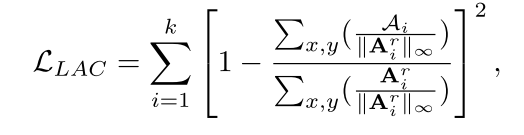
其中px,y表示我们累加交叉注意地图中每个空间条目的值。如图图所示,LLAC促使高值从当前高激活区域转移到相应的目标区域,引导第i个目标出现在指定位置。
与之前的方法[6,26,41]提出的能量函数不同,我们用∥ari∥∞对每个细化的交叉注意图ari进行了单独的归一化。这种归一化是至关重要的,因为尽管交叉注意图中的高响应区域在感知上与图像中合成对象的位置对齐,但这些区域的最大值在数值上很小(约0.1)并且波动。归一化将高响应区域与背景区区分开来,从而实现精确的空间控制并防止语义不一致。

Padding Tokens Constraint (LPTC)

LLAC有效地鼓励交叉关注集中在正确的区域。然而,当这些指定的区域靠近时,所需的对象有时会超出其相应的框,导致合成图像和布局指令之间的不对齐。
LLAC有效地鼓励交叉关注集中在正确的区域。然而,当这些指定的区域靠近时,所需的对象有时会超出其相应的框,导致合成图像和布局指令之间的不对齐。为了解决这个问题,我们引入了填充令牌约束(图 (c))。如图 (b)所示,[SoT]和[EoT]令牌的交叉关注包含有关图像布局的信息。[SoT]主要强调背景,[EoT]对前景的响应是互补的。我们在填充令牌中利用这些语义信息来防止对象移出目标区域。最初,我们为所有前景对象导出掩码bfg:
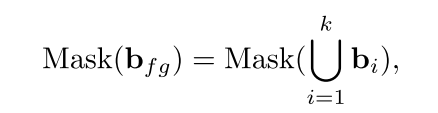
并获得APT,填充令牌的交叉关注。APT是归一化ASoT和归一化AEoT反演的加权平均值:
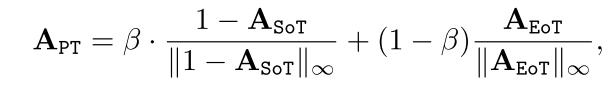
其中β作为加权因子。
随后,我们对LPTC的定义如下:
![]()
如图图所示,LPTC有助于惩罚参与背景区域的错误激活,有效地防止期望对象的错误扩展。

Latent Feature Update
在每个时间步t上,整体约束LLoCo是LLAC和LPTC的加权和,如下所示:
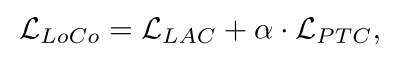
其中α是控制LPTC干预强度的因子。我们通过反向传播用L更新当前潜在特征zt,如下所示:
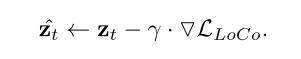
这里,γ是控制引导强度的比例因子。随后,z³被送到噪声预测器去噪。
在LLoCo的引导下,zt在每个时间步长逐渐调整,将高响应注意力区域对准指定的边界框。这个过程导致在用户提供的位置合成所需的对象。请参考实验部分了解更多细节。
Experiments
Experimental Setup
Datasets.我们在两个标准基准上进行了实验,HRSBench[2]和DrawBench[32]。hr - bench作为T2I模型的综合基准,提供了分为三个主要主题的各种提示:准确性,鲁棒性和泛化。由于我们的方法侧重于布局控制,因此我们从HRS中具体选择了与图像组成相对应的四个类别:空间关系、大小、颜色和对象计数。每个类别的提示数分别为1002/501/501/3000。
DrawBench数据集是对T2I模型进行细粒度分析的具有挑战性的基准。我们利用了对象计数和位置分类,包括39个提示。由于HRS和DrawBench都不包括布局说明,我们将Phung等人发布的公开可用布局纳入评估。为了进一步评估我们的方法以语义掩码的形式解释细粒度布局的能力,我们利用DenseDiffusion[16]提供的数据集,其中包括250个具有相应标签和标题的二进制掩码。为了评估LoCo在合成逼真图像方面的性能,我们从MS-COCO[20]数据集中随机选择100个样本,以及相应的标题和边界框,从而构建了一个COCO子集。
Evaluation Metrics. 我们遵循HRS的标准评估方案。具体来说,我们在所有合成图像上使用了预训练的UniDet[49],这是一种多数据集检测器。然后使用预测的边界框来验证调节布局是否正确接地。
对于空间构成,即空间关系、尺寸和颜色类别,生成精度作为评价指标。当所有检测到的对象(无论是空间关系、颜色还是大小)都准确时,合成图像就被视为正确的预测。对于对象计数,将生成图像中检测到的对象数量与文本提示中的基本事实进行比较,以衡量精度、召回率和F1分数。当生成的对象数量小于基本事实时,就会发生假阳性样本。相反,假阴性被计算为丢失的对象。
对于DenseDiffusion[16]数据集和策划的COCO子集,我们报告IoU和AP50来测量输入布局和合成图像的对齐。此外,我们使用CLIP评分来评估合成图像对文本条件的保真度。
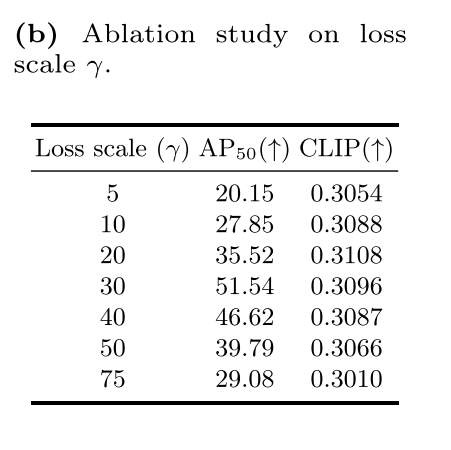
Implementation Details. 除非另有说明,否则我们使用官方的稳定扩散V-1.4[31]作为基本T2I综合模型。通过50步去噪,生成分辨率为512 × 512的合成图像。对于超参数,我们使用损失尺度因子γ = 30,自注意增强η = 0.3, α = 0.2, β = 0.8。采用无分类器制导[14],固定制导尺度为7.5。考虑到合成图像的布局通常是在推理的早期时间步骤中建立的,我们在最初的10个步骤中将制导与提出的约束相结合。在每个时间步长,方程(11)中的潜在更新迭代5次后去噪。
Qualitative Results
Visual variations.

Comparisons with prior methods.
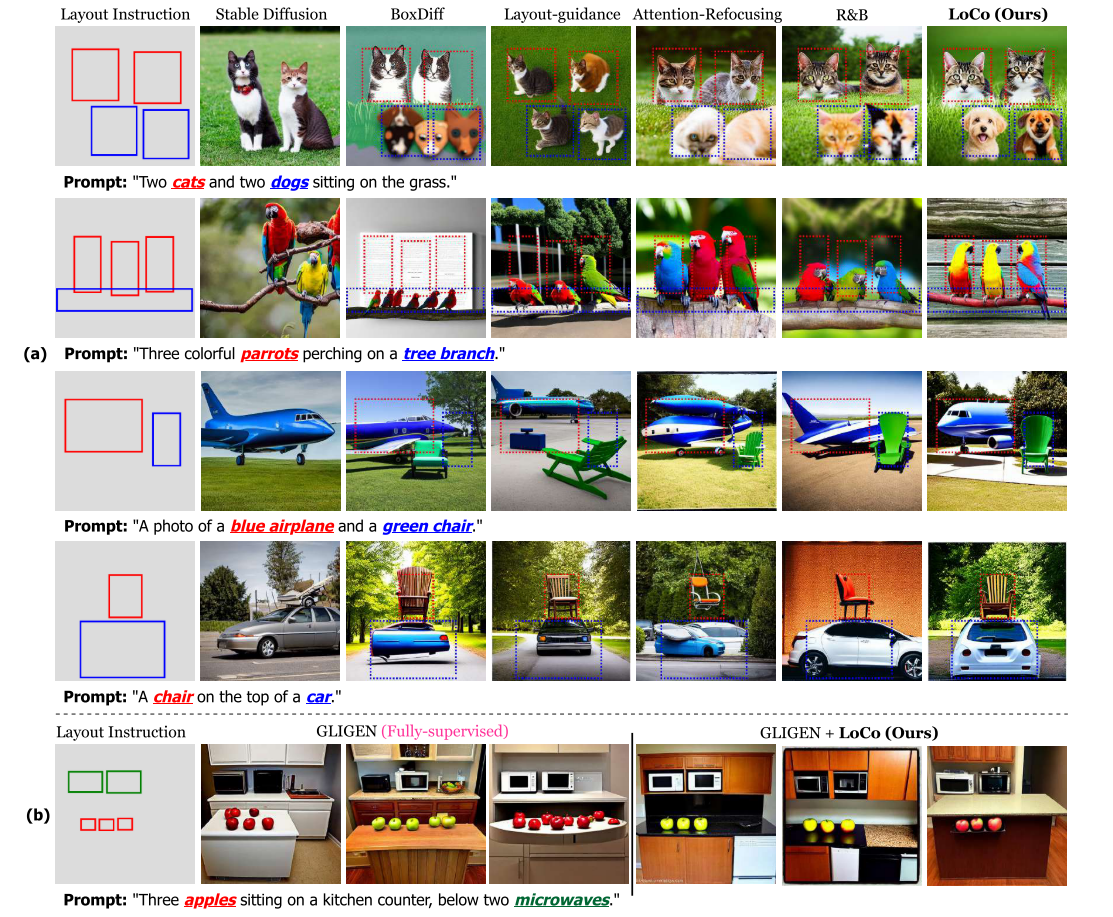
与先前方法的比较。图:(a)与以往方法的视觉对比。我们展示了LoCo和几种无需训练的图像布局方法之间的视觉比较。布局说明用虚线框标注在图像上。我们的结果忠实地遵循文本和布局条件,在空间控制和图像质量方面优于先前的方法。(b)全监督布局到图像方法的性能提升。LoCo显著提高了GLIGEN[18]在生成多个小目标方面的性能。请放大以便看得更清楚。
Quantitative Results
Box-level Layout Instruction. 我们将LoCo与基于Stable Diffusion V-1.4的各种无训练LIS方法进行了比较。

LoCo的集成也显著提升了GLIGEN[18]的性能,如表3所示。这强调了LoCo的多功能性,可作为全监督布局到图像方法的即插即用助推器。
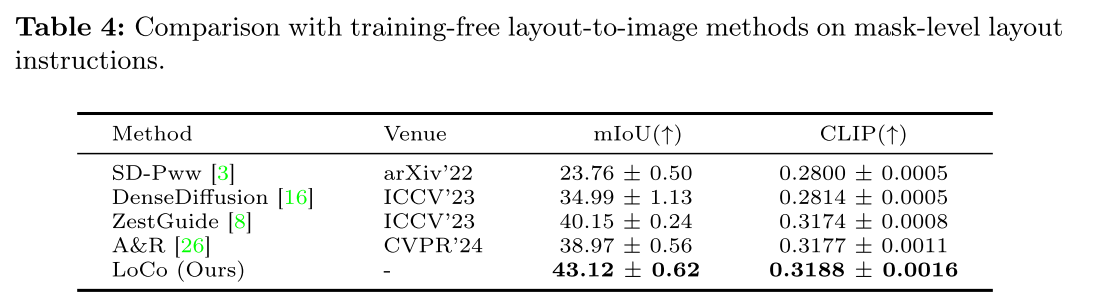
 Mask-level Layout Instruction. LoCo还可以平滑地扩展到各种形式的布局指令,例如语义掩码(表4,图6)。我们的方法以更高的mIoU和CLIP得分优于当前最先进的方法,表明LoCo在细粒度空间控制方面具有优势。
Mask-level Layout Instruction. LoCo还可以平滑地扩展到各种形式的布局指令,例如语义掩码(表4,图6)。我们的方法以更高的mIoU和CLIP得分优于当前最先进的方法,表明LoCo在细粒度空间控制方面具有优势。

Ablation Studies
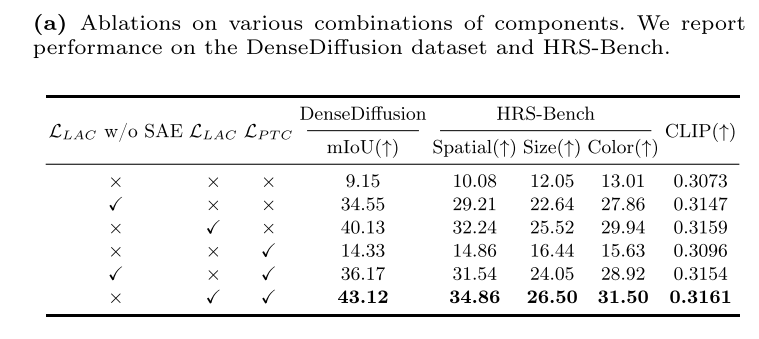
Ablation of Key Components. 我们在DenseDiffusion数据集和hr - bench上研究了方法中关键组件的有效性,如表5a所示。可视化结果如图所示。

Ablation on Loss Scale.