4.【Linux】Linux工具(2)
4.Linux工具
文章目录
- 4.Linux工具
- Linux项目自动化构建工具-make/Makefile
- 介绍
- 使用方法
- makefile文件内容
- 补充——文件的三个时间
- 总结
- 进度条
- linux中的git工具
- 调试器 - gdb/cgdb使用
- 基本指令
- 要点
- 总结
Linux项目自动化构建工具-make/Makefile
注意:这个工具并不需要理解得特别深入,因为现在企业中有其他工具来生成makefile。
介绍
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
使用方法
[lisihan@hcss-ecs-b735 lession7]$ touch makefile #新建makefile/Makefile文件
[lisihan@hcss-ecs-b735 lession7]$ vim makefile #vim打开写入
[lisihan@hcss-ecs-b735 lession7]$ cat makefile #makefile文件内容
code:code.cgcc -o code code.c[lisihan@hcss-ecs-b735 lession7]$ ls #当前路径文件
code.c makefile
[lisihan@hcss-ecs-b735 lession7]$ make #执行make命令
gcc -o code code.c
[lisihan@hcss-ecs-b735 lession7]$ ls
code code.c makefile #生成code可执行文件
[lisihan@hcss-ecs-b735 lession7]$ ./code #执行code
hello code
[lisihan@hcss-ecs-b735 lession7]$
makefile文件内容
-
主要书写方式
上面的代码中makefile文件主要包含两行内容:
[lisihan@hcss-ecs-b735 lession7]$ cat makefile #makefile文件内容
code:code.c #依赖关系gcc -o code code.c #依赖方式
书写要点:第二行依赖方法前面是一个tab键,不是两个空格也不是四个空格,tab和单纯的空格是不一样的
-
.PHONTY声明伪目标这个类似于C语言中的关键字,可以用于声明一个伪目标
[lisihan@hcss-ecs-b735 lession7]$ cat makefile #makefile文件内容 code:code.cgcc -o code code.c .PHONY:clean clean:rm -rf code [lisihan@hcss-ecs-b735 lession7]$ ls code code.c makefile [lisihan@hcss-ecs-b735 lession7]$ make clean rm -rf code [lisihan@hcss-ecs-b735 lession7]$ ls code.c makefile注意:
.、:,.PHONY:作用其实是让目标文件,对应的方法,总是被执行的,即使不使用.PHONY:我们也可以在make命令后面加上clear或其他依赖关系来指定要执行的以来方式的内容例如:
[lisihan@hcss-ecs-b735 lession7]$ cat makefile code:code.cgcc -o code code.c .PHONY:clean clean:rm -rf code [lisihan@hcss-ecs-b735 lession7]$ ls code.c makefile [lisihan@hcss-ecs-b735 lession7]$ make code #没有PHONY一样可以指定依赖关系执行 gcc -o code code.c [lisihan@hcss-ecs-b735 lession7]$ ls code code.c makefile -
@关闭命令回显。通常情况下当我们使用make指令之后往往会显示具体执行的依赖方式的内容,但我们可以在依赖方法的某一行指令前加上一个@来取消命令回显[lisihan@hcss-ecs-b735 lession7]$ cat makefile code:code.c@gcc -o code code.c #这行指令取消命令回显 .PHONY:clean clean:@rm -rf code #这行指令取消命令回显 [lisihan@hcss-ecs-b735 lession7]$ make code #执行之后没有命令回显 [lisihan@hcss-ecs-b735 lession7]$ make clean#执行之后没有命令回显 -
makefile文件,会被make从上到下开始扫描,第一个目标名,是缺省的,如果我们想执行其他组的依赖关系和依赖方法
make name,所以如果只是执行make命令不加其他,就只会执行第一个依赖关系对应的依赖方法 -
make makefile在执行gcc命令的时候,如果发生了语法错误,就会终止推导
补充——文件的三个时间
我们使用stat命令可以查看文件更详细的信息,其中会显示三个时间:Access(最近访问时间、不一定会每次更新)、Modify(文件内容修改时间)、Change(文件属性修改时间)
[lisihan@hcss-ecs-b735 lession7]$ stat makefile File: ‘makefile’Size: 69 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1713736 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ lisihan) Gid: ( 1000/ lisihan)
Access: 2025-05-14 21:11:43.010053287 +0800
Modify: 2025-05-14 21:11:32.225907865 +0800
Change: 2025-05-14 21:11:32.225907865 +0800Birth: -
gcc文件的编译时,如果原文件的M时间比已经编译之后的可执行程序的M时间要更新,就会重新编译,但反之就不会再次编译
-
make解释makefile的时候,是会自动推导的。一直推导,不执行依赖方法。直到推到导游依赖文件存在,然后在逆向地执行所有的依赖方法。这就像栈一样,先进后出
[lisihan@hcss-ecs-b735 lession7]$ cat makefile code:code.ocode code code.o code.o:code.sgcc -c code.s -o code.o code.s:code.igcc -S code.i -o code.s code.i:code.cgcc -E code.c -o code.i.PHONY:clean clean:@rm -rf code code.o code.i code.s [lisihan@hcss-ecs-b735 lession7]$ ls code.c makefile [lisihan@hcss-ecs-b735 lession7]$ make gcc -E code.c -o code.i gcc -S code.i -o code.s gcc -c code.s -o code.o gcc code.o -o code [lisihan@hcss-ecs-b735 lession7]$ ls code code.c code.i code.o code.s makefile [lisihan@hcss-ecs-b735 lession7]$ ./code hello code [lisihan@hcss-ecs-b735 lession7]$ make clean [lisihan@hcss-ecs-b735 lession7]$ ls code.c makefile -
make中的通配符
我们先来看下面这一段的代码:
code:code.cgcc code.c -o code %.o:%.cgcc -c $< .PHONY:clean clean:@rm -rf code code.o其中,
%为makefile语法中的通配符,%c表示当前目录下所有的.c文件,展开到依赖列表中。使用%.o: %.c表示所有.o文件依赖于对应的.c文件,而在下面gcc -c $<表示右侧的依赖文件,一个一个的交个gcc -c 选项,形成同名的.o文件我们再来看下面的一段代码:
[lisihan@hcss-ecs-b735 lession7]$ cat makefile bin=code src=code.c$(bin):$(src)gcc $^ -o $@ .PHONY:clean clean:@rm -rf code [lisihan@hcss-ecs-b735 lession7]$ make gcc code.c -o code这段代码中,我们把bin作为目标文件,src作为依赖文件列表(目前这个列表中只有一个文件),在
$(bin):$(src)依赖关系中,把所有依赖文件列表通过gcc -o 编译成 目标文件-
在makefile中如bin和src我们可以称为变量,makefile中的变量没有类型,可以直接进行赋值
-
引用变量名用
$(变量名) -
$@表示目标文件名,在代码中也就是$(bin) -
$<表示每一个文件依赖名 -
$^表示所有依赖文件列表
在一般情况写make和makefile只能编译一个目标文件,但我们可以用一个方法使make执行一次,编译出两个可执行文件。
如下面代码:
[lisihan@hcss-ecs-b735 lession7]$ cat makefile bin1=code src1=code.cbin2=porc src2=porc.cmakeall:$(bin1) $(bin2)$(bin1):$(src1)gcc $^ -o $@ $(bin2):$(src2)gcc $^ -o $@.PHONY:clean clean:@rm -rf $(bin1) $(bin2) [lisihan@hcss-ecs-b735 lession7]$ make gcc code.c -o code gcc porc.c -o porc [lisihan@hcss-ecs-b735 lession7]$ ls code code.c makefile porc porc.c [lisihan@hcss-ecs-b735 lession7]$ make clean [lisihan@hcss-ecs-b735 lession7]$ ls code.c makefile porc.cmakeall作为第一个依赖关系在使用make指令的时候执行,而它的依赖文件列表存在两个文件,如果这两个文件不存在,就会一直推导从而生成两个可执行文件
-
注意$>和$^的区别
总结
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么,
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“code”这个文件,并把这个文件作为最终的目标文件。
- 如果code文件不存在,或是code所依赖的后面的code.o文件的文件修改时间要比code这个文件新(可以用 测试),那么,他就会执行后面所定义的命令来生成code这个文件。
- 如果code所依赖的code.o文件不存在,那么make会在当前文件中找目标为code.o文件的依赖性,如果找到则再根据那一个规则生成hecodelo.o文件。(这有点像一个堆栈的过程)
- 当然,你的C文件和H文件是存在的啦,于是make会生成 code.o 文件,然后再用 code.o 文件声明make的终极任务,也就是执行文件code了。
- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
进度条
-
我们先回顾一下之前学的换行回车。‘\r’表示只回车,也就是将光标移动到这一行的开头。’\n’表示换行,就是将光标直接移动到下一行
-
linux系统中也有输出缓存区,我们可以用’\n’刷新输出缓存区,也可以用函数
fflush(stdout)刷新输出缓存
[lisihan@hcss-ecs-b735 lession7]$ cat makefile
bin1=process
src1=main.c
src2=process.c$(bin1):$(src1) $(src2)gcc $^ -o $@ .PHONY:clean
clean:@rm -rf $(bin1)
[lisihan@hcss-ecs-b735 lession7]$ cat main.c
#include <stdio.h>
#include "process.h"int main()
{printf("main ready\n");process(); printf("main complete\n");return 0;
}
[lisihan@hcss-ecs-b735 lession7]$ cat process.h
#include <stdio.h>void process();
[lisihan@hcss-ecs-b735 lession7]$ cat process.c
#include "process.h"
#include "unistd.h"
#include <string.h>void process()
{char arr[101] = {0};memset(arr, ' ', 100);printf("process ready\n");int i = 0;for(; i <= 100; i++){printf("[%s][%d%%]\r", arr, i);arr[i] = '#';fflush(stdout);sleep(1);}printf("\n");
}
上面的代码可以实现视觉上的进度条,但是进度条应该是要反应具体某一个任务完成的情况,比如说下载,下面通过模拟一个下载任务来实现进度条:
[lisihan@hcss-ecs-b735 lession8]$ cat main.c
#include <stdio.h>
#include "process.h"
#include <time.h>
#include <stdlib.h>float total = 1024.0f;
float speed = 0.5f;void download()
{float nowload = 0;while(nowload < total){nowload += (rand() % 10 + 1) * speed;//档位有10个,每个档位的下载速度是0.5的倍数if(nowload > total) nowload = total;progress(nowload, total);}
}int main()
{srand(time(NULL));printf("main ready...\n");progress_init();download();printf("\nmain complete...\n");return 0;
}
[lisihan@hcss-ecs-b735 lession8]$ cat process.h
#include <stdio.h>void progress_init();
void progress(float now, float tal);[lisihan@hcss-ecs-b735 lession8]$ cat process.c
#include "process.h"
#include "unistd.h"
#include <string.h>char arr[101] = {0};
int pos = 0;void progress_init()
{pos = 0;memset(arr, ' ', 100);printf("process_init ready\n");
}void progress(float now, float tal)
{int rate = now * 100 / tal;int i = pos;for(; i <= rate; i++){printf("[%s][%d%%][%.1f / %.1f]\r", arr, i, now, tal);arr[i] = '#';fflush(stdout);//刷新输出缓存usleep(20000);}pos = i;
}实际运行效果:
[lisihan@hcss-ecs-b735 lession8]$ ./process
main ready...
process_init ready
[####################################################################################################][100%][1024.0 / 1024.0]
main complete...
linux中的git工具
我们可以先简单了解一下git的作用:
Git 是一个分布式版本控制系统(DVCS),核心作用是帮助开发者高效管理代码(或其他文件)的版本变更历史,支持多人协作开发。
- 记录每次代码修改的细节(谁、何时、改了什么),可随时回退到历史版本。通过
commit保存版本快照,形成可追溯的时间线。 - 允许创建独立分支开发新功能,避免干扰主代码,完成后可合并回主线(
merge或rebase)。 - 支持多人并行修改同一项目,通过远程仓库(如 GitHub、GitLab)同步代码,解决冲突。
- 使用 SHA-1 哈希算法确保每次提交的唯一性,防止数据损坏或篡改。
centOS安转git:sudo yum install -y git
把linux服务器上的代码上传到gitee中与Windows中的操作基本相同,只是Windows中有图形化配置界面,linux中需要用命令行
git add [文件、目录]
git commit -m "[日志]"
git push
我们需要将远程仓库git clone到linux本地,再将我们需要上传的文件拷贝到这个目录下,之后在按照上面的git三板斧进行上传

git仓库要提交,必须保证本地仓库的内容和远端仓库内容一致!
调试器 - gdb/cgdb使用
基本指令
-
程序的发布⽅式有两种, relese模式和 debug模式, gcc/g++出来的⼆进制程序,默认是 relese模式。
-
要使⽤gdb调试,必须在源代码⽣成⼆进制程序的时候, 加上 选项,如果没有添加,程序⽆法被编译
例子:
[lisihan@hcss-ecs-b735 lession9]$ cat makefile
bin1 = code_relese
bin2 = code_debug
src = code.cmakeall:$(bin1) $(bin2)$(bin1):$(src)gcc -o $@ $^$(bin2):$(src)gcc -g -o $@ $^[lisihan@hcss-ecs-b735 lession9]$ ll
total 32
-rw-rw-r-- 1 lisihan lisihan 152 May 18 20:10 code.c
-rwxrwxr-x 1 lisihan lisihan 9400 May 18 20:10 code_debug
-rwxrwxr-x 1 lisihan lisihan 8360 May 18 20:10 code_relese
-rw-rw-r-- 1 lisihan lisihan 142 May 18 20:07 makefile
[lisihan@hcss-ecs-b735 lession9]$
我们可以看到,包含debug调试信息的可执行程序要大一些
在gdb中,我们可以用命令的方式来调试代码:
[lisihan@hcss-ecs-b735 lession9]$ gdb code_debug #执行gdb指令
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /home/lisihan/lession9/code_debug...done.
(gdb) l #显示代码,后面跟数字(行号)、文件函数名可以显示指定位置的代码
1 #include <stdio.h>
2
3 int main()
4 {
5 printf("code ready!\n");
6
7 int i = 0;
8 while(i <= 100000000)
9 i++;
10 printf("code finsh\n");
(gdb) #默认不会显示所有代码,继续按空格可以继续显示
11
12 return 0;
13 }
(gdb) b 4 #在第4行添加断点
Breakpoint 1 at 0x400535: file code.c, line 4.
(gdb) b 3 #在第3行添加断点
Note: breakpoint 1 also set at pc 0x400535.
Breakpoint 2 at 0x400535: file code.c, line 3.
(gdb) b 8 #在第8行添加断点
Breakpoint 3 at 0x400546: file code.c, line 8.
(gdb) info b #显示当前断点信息
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400535 in main at code.c:4
2 breakpoint keep y 0x0000000000400535 in main at code.c:3
3 breakpoint keep y 0x0000000000400546 in main at code.c:8
(gdb) d 1 #删除Num为1的断点(注意不是)
(gdb) info b
Num Type Disp Enb Address What
2 breakpoint keep y 0x0000000000400535 in main at code.c:3
3 breakpoint keep y 0x0000000000400546 in main at code.c:8
| 命令 | 作⽤ | 样例 |
|---|---|---|
| list/l | 显⽰源代码,从上次位置开始,每次列出10⾏ | list/l 10 |
| list/l 函数名 | 列出指定函数的源代码 | list/l main |
| list/l ⽂件名:⾏号 | 列出指定⽂件的源代码 | list/l mycmd.c:1 |
| r/run | 从程序开始连续执⾏ | run |
| n/next | 单步执⾏,不进⼊函数内部 | next |
| s/step | 单步执⾏,进⼊函数内部 | step |
| break/b [⽂件名:]⾏号 | 在指定⾏号设置断点 | break 10break test.c:10 |
| break/b 函数名 | 在函数开头设置断点 | break main |
| info break/b | 查看当前所有断点的信息 | info break |
| finish | 执⾏到当前函数返回,然后停⽌ | finish |
| print/p 表达式 | 打印表达式的值 | print start+end |
|---|---|---|
| p 变量 | 打印指定变量的值 | p x |
| set var 变量=值 | 修改变量的值 | set var i=10 |
| continue/c | 从当前位置开始连续执⾏程序 | continue |
| delete/d breakpoints | 删除所有断点 | delete breakpoints |
| delete/d breakpoints n | 删除序号为n的断点 | delete breakpoints 1 |
| disable breakpoints | 禁⽤所有断点 | disable breakpoints |
| enable breakpoints | 启⽤所有断点 | enable breakpoints |
| info/i breakpoints | 查看当前设置的断点列表 | info breakpoints |
| display 变量名 | 跟踪显⽰指定变量的值(每次停⽌时) | display x |
| undisplay 编号 | 取消对指定编号的变量的跟踪显⽰ | undisplay 1 |
| until X⾏号 | 执⾏到指定⾏号 | until 20 |
| backtrace/bt | 查看当前执⾏栈的各级函数调⽤及参数 | backtrace |
| info/i locals | 查看当前栈帧的局部变量值 | info locals |
| quit | 退出GDB调试器 | quit |
要点
-
在一个调试周期下,断点编号是递增的,删除的断点编号不会被重复利用
-
由于gdb调试代码难以可视化,所以我们可以用gdb的进阶版本cgdb,这个工具使用的指令与gdb是一致的但是可以实现代码调试的可视化,更加友好
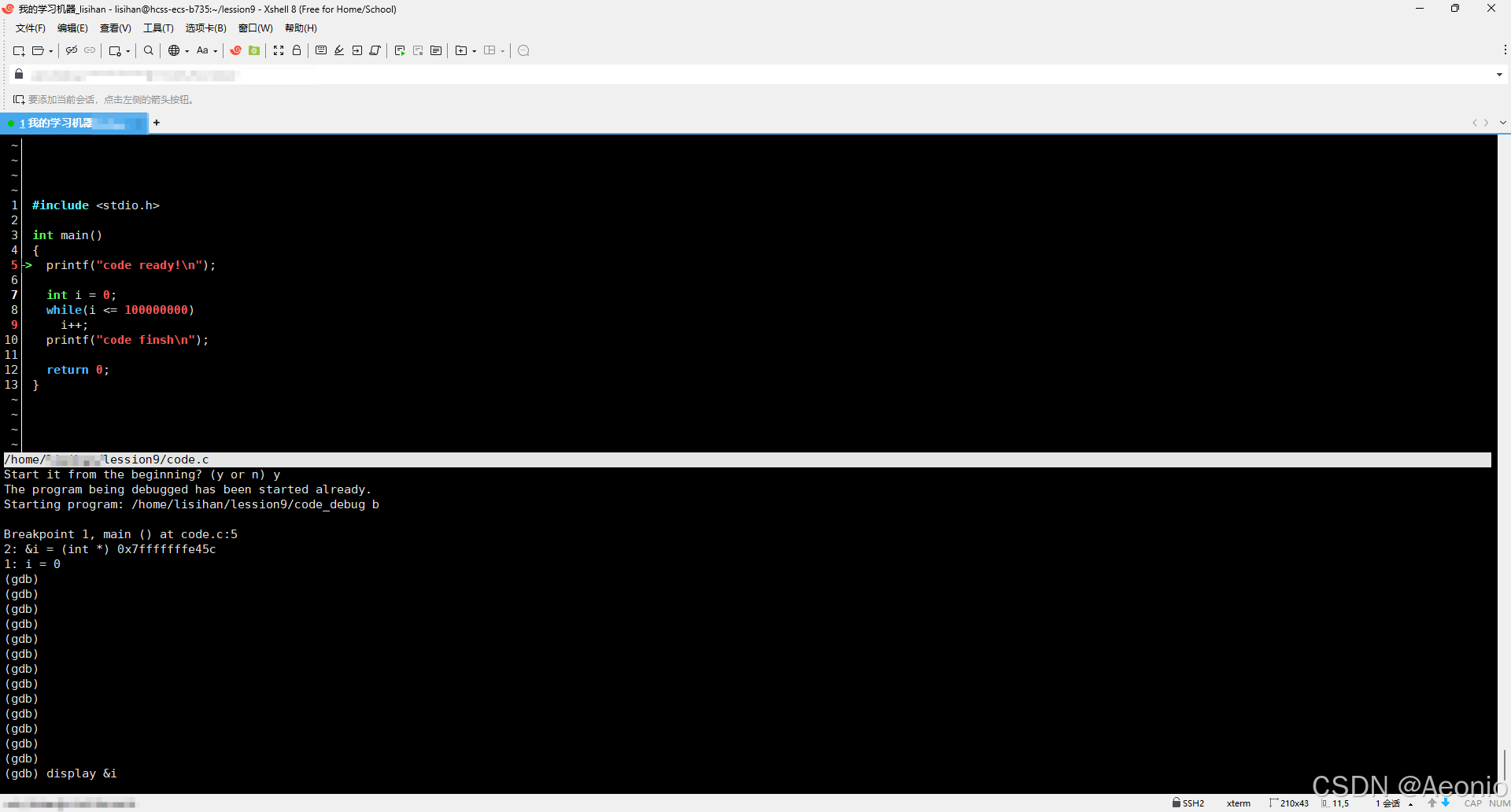
-
-
在使用gdb调试的时候我们可以用watch来执⾏时监视⼀个表达式(如变量)的值。如果监视的表达式在程序运⾏期间的值发⽣变化,GDB 会暂停程序的执⾏,并通知使⽤者
-
watch与前面的display有点类似,都是在调试过程中查看变量和表达式的值,但watch是在变量的值发生变化的时候才会显示,并且会显示变化之前和变化之后的值,而且实际上watch相当于是一个断点因此可以用去掉断点的方法
d [num]来取消watch,具体看一看下面的图片 -
如果你有⼀些变量不应该修改,但是你怀疑它修改导致了问题,你可以watch它,如果变化了,就会通知你
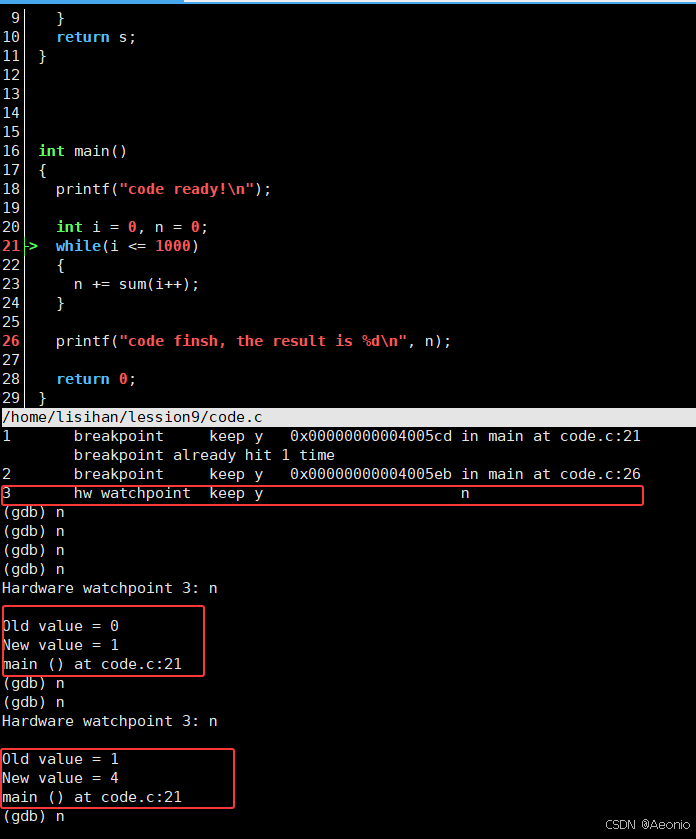
-
-
set var 可以在调试的时候直接修改变量的值,便于调试
-
条件断点
- 条件断点添加常⻅两种⽅式:1. 新增 2. 给已有断点追加
- 注意两者的语法有区别,不要写错了
- 新增:
b ⾏号/⽂件名:⾏号/函数名 if i == 30(条件) - 给已有断点追加:
condition 2 i==30, 其中2是已有断点编号,没有if
新增断点
(gdb) b 9 if i == 30 # 9是⾏号,表⽰新增断点的位置
Breakpoint 2 at 0x555555555186: file mycmd.c, line 9.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00005555555551c3 in main at mycmd.c:20 #断点1并不是条件断点
breakpoint already hit 1 time
2 breakpoint keep y 0x0000555555555186 in Sum at mycmd.c:9
stop only if i == 30 #这里是断点触发的条件,表示断点2是条件断点
(gdb) finish #再有条件断点的时候直接finish
Run till exit from #0 Sum (s=1, e=100) at mycmd.c:7
Breakpoint 2, Sum (s=1, e=100) at mycmd.c:9 #不会直接运行完整个函数,会在条件触发时直接停止
9 result += i;
1: i = 30
(gdb) finish #再次finish的时候,由于不满足条件,条件断点不会被触发,直接运行结束
Run till exit from #0 Sum (s=1, e=100) at mycmd.c:9
0x00005555555551d2 in main () at mycmd.c:20
20 int n = Sum(start, end);
Value returned is $1 = 5050
给已有断点追加 :
(gdb) condition 2 i==30 #给2号断点,新增条件i==30
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00005555555551c3 in main at mycmd.c:20
breakpoint already hit 1 time
2 breakpoint keep y 0x0000555555555186 in Sum at mycmd.c:9
stop only if i==30 #这里是断点触发的条件,表示断点2是条件断点
breakpoint already hit 2 times
总结
这份笔记主要介绍了Linux开发中的三个核心工具:make/Makefile、git以及gdb/cgdb调试器。make/Makefile用于项目自动化构建,通过定义依赖关系和编译规则实现“一键编译”,需注意格式细节(如Tab键)和伪目标(.PHONY)的声明,同时利用变量(如$@、$^)和通配符简化编写。git作为分布式版本控制系统,支持代码版本管理和协作开发,基本操作包括克隆仓库、提交三板斧(add、commit、push),需确保本地与远程仓库内容同步。gdb/cgdb是调试工具,需通过-g选项生成调试信息,支持断点设置、单步调试、变量监视(watch)和条件断点等操作,cgdb提供可视化界面提升调试效率。