Docker 核心原理详解:Namespaces 与 Cgroups 如何实现资源隔离与限制
#Docker疑难杂症解决指南#
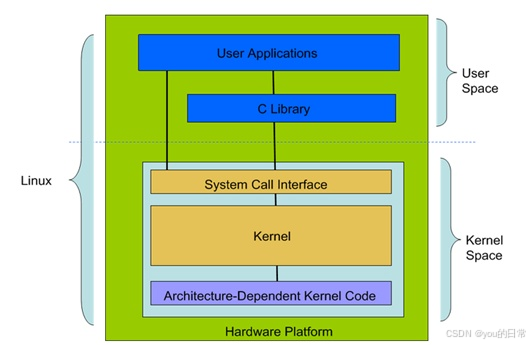
Docker 作为容器化技术的代名词,彻底改变了软件的开发、部署和管理方式。它凭借其轻量、快速、一致性强的特性,成为了现代云原生架构的基石。然而,Docker 容器的神奇之处并非“无中生有”,其背后是 Linux 内核的两大核心技术——Namespaces(命名空间) 和 Cgroups(控制组)。正是这两项技术,共同构筑了 Docker 容器的强大隔离性和资源限制能力。
本文将深入浅出地解析 Namespaces 和 Cgroups 的工作原理,揭示 Docker 容器是如何在共享宿主机内核的情况下,实现“看似独立”的运行环境,并对其资源进行精确控制的。
一、容器化技术与虚拟化的本质区别
在深入了解 Docker 的底层原理之前,我们有必要区分容器化与传统的虚拟化技术。
A. 虚拟机 (Virtual Machines)
- 概念: 虚拟机通过Hypervisor(管理程序)在物理硬件之上模拟出一个完整的计算机系统(包括CPU、内存、磁盘、网卡等),每个虚拟机都运行一个独立的客户操作系统(Guest OS)内核。
- 优点: 隔离性非常强,能够运行不同的操作系统,拥有完整的操作系统功能。
- 缺点: 资源开销大(每个VM都需要独立的OS内核和其运行所需的资源),启动速度慢。
B. 容器 (Containers)
- 概念: 容器是基于宿主机(Host OS)的操作系统内核运行的。它共享宿主机的内核,但在用户空间提供了进程级别的隔离。容器内部只包含应用程序及其运行所需的环境(库、运行时、配置文件等)。
- 优点: 轻量级、启动速度快(秒级甚至毫秒级),资源利用率高。
- 缺点: 隔离性相对VM稍弱(共享内核),无法运行不同于宿主机的操作系统。
容器化与虚拟化比较图 (概念示意)
- 虚拟机: 硬件 -> Hypervisor -> 客户操作系统A -> 应用A / 客户操作系统B -> 应用B
- 容器: 硬件 -> 宿主机操作系统内核 -> Docker Engine -> 容器A (应用A+依赖) / 容器B (应用B+依赖)
二、Namespaces:隔离的基石
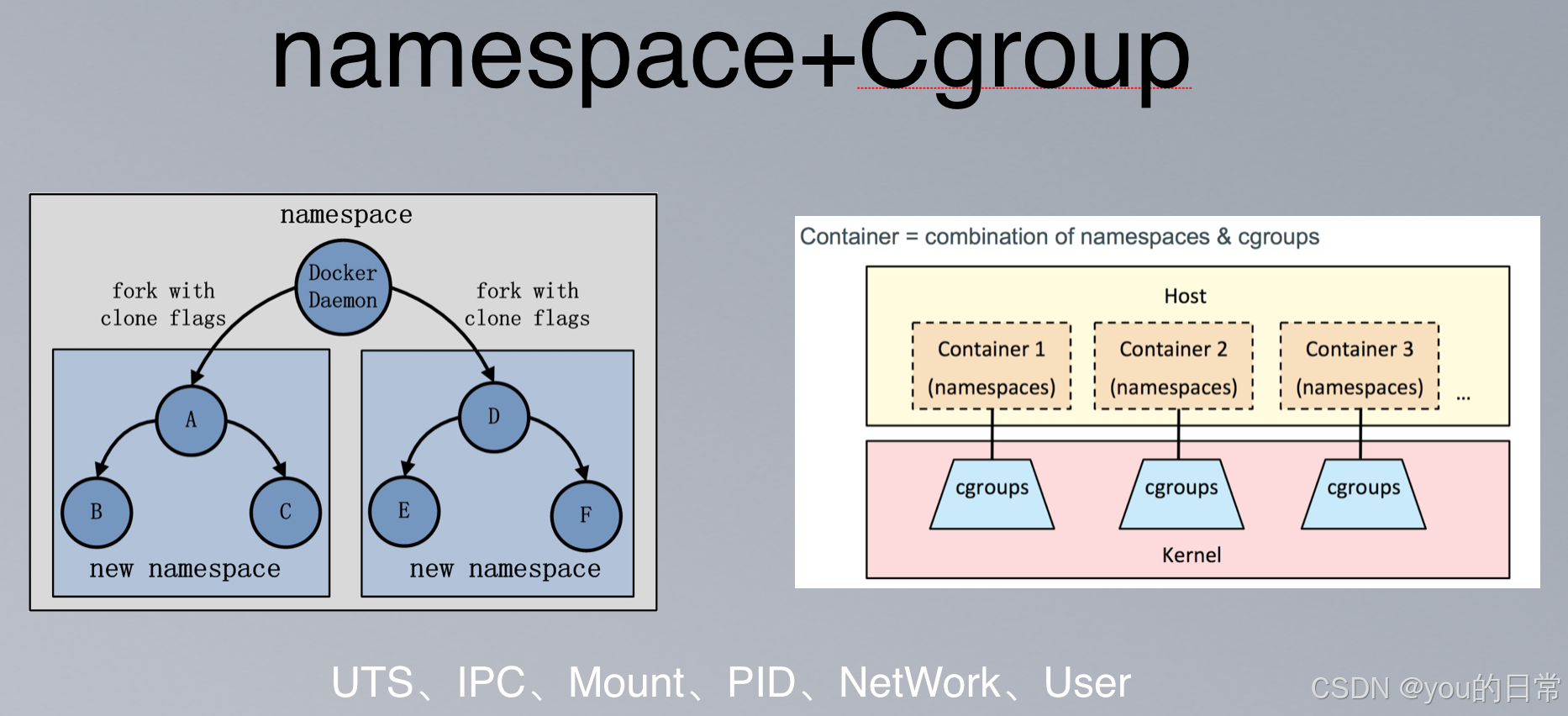
Namespaces 是 Linux 内核的一项功能,它能够将全局的系统资源进行分区,使得每个进程组(即一个 Namespace)只能看到和使用自己所属的资源视图,而不能看到或影响其他 Namespace 中的资源。通过 Namespaces,Docker 为每个容器创建了一个“看似独立”的运行环境。
A. 什么是 Namespaces?
Namespaces 的核心思想是隔离。它为不同进程提供独立的系统资源视图。例如,在一个 PID Namespace 中的进程,看到的进程 ID 空间是独立的,它只知道自己 Namespace 内的进程,并不知道其他 Namespace 中的进程。
B. 常见的 Namespaces 类型及作用
-
PID Namespace (进程 ID 命名空间):
- 作用: 隔离进程 ID 空间。每个 PID Namespace 都有自己独立的进程 ID 编号系统,即每个 Namespace 都有一个 PID 为 1 的进程(通常是容器的启动进程)。
- 表现: 容器内
ps -ef命令看到的 PID 与宿主机上的 PID 是不同的。容器内的 PID 1 是启动容器的应用程序,而不是宿主机的 init 进程。 - 示例:
# 在宿主机上创建一个新的 PID Namespace sudo unshare -p --fork bash# 进入新的 Bash Shell 后,查看当前进程的 PID # 注意:这里看到的 PID 是在新的 PID Namespace 中的 PID echo $$# 尝试查看所有进程,会发现进程列表非常简洁,且当前 Bash 的 PID 是 1 ps -ef
-
Mount Namespace (MNT Namespace / 挂载命名空间):
- 作用: 隔离文件系统挂载点。每个 MNT Namespace 都有自己独立的根文件系统视图和挂载点。
- 表现: 容器有自己的独立文件系统(通常是基于镜像层叠形成的),容器内的文件操作不会影响宿主机文件系统(除非通过卷挂载)。
- 示例:
# 在宿主机上创建一个新的 Mount Namespace sudo unshare -m --fork bash# 在新的 Bash Shell 中创建一个新的挂载点并挂载一个临时文件系统 mkdir /tmp/new_mount sudo mount -t tmpfs none /tmp/new_mount# 退出后,宿主机上不会看到 /tmp/new_mount 挂载点
-
Network Namespace (NET Namespace / 网络命名空间):
- 作用: 隔离网络设备、IP 地址、端口号、路由表、防火墙规则等。
- 表现: 每个容器拥有独立的网络栈,可以有自己的 IP 地址、虚拟网卡,端口映射只影响宿主机网络。
- 示例:
# 在宿主机上创建一个新的 Network Namespace sudo unshare -n --fork bash# 进入新的 Bash Shell 后,查看网络接口,会发现只有一个 lo(loopback)接口 ip addr # 可以手动配置新的网络接口和IP # sudo ip link set lo up # sudo ip addr add 127.0.0.1/8 dev lo
-
UTS Namespace (Unix Time-sharing System Namespace):
- 作用: 隔离主机名和域名。
- 表现: 容器可以拥有独立的主机名,不会影响宿主机的主机名。
- 示例:
# 在宿主机上创建一个新的 UTS Namespace sudo unshare -u --fork bash# 在新的 Bash Shell 中修改主机名 hostname new-container-host# 退出后,宿主机的主机名不受影响
-
User Namespace (USER Namespace / 用户命名空间):
- 作用: 隔离用户 ID 空间。允许容器内的
root用户映射到宿主机上的一个非root用户。 - 表现: 提高容器安全性,即使容器内的
root被攻破,也无法在宿主机上获得root权限。 - 注: User Namespace 的使用相对复杂,它增强了容器的安全性,但同时也带来了额外的配置和限制。
- 作用: 隔离用户 ID 空间。允许容器内的
-
IPC Namespace (Interprocess Communication Namespace):
- 作用: 隔离 System V IPC(如信号量、消息队列、共享内存)和 POSIX 消息队列。
- 表现: 容器内的进程无法直接看到或访问宿主机上的 IPC 资源,从而避免潜在的冲突和安全问题。
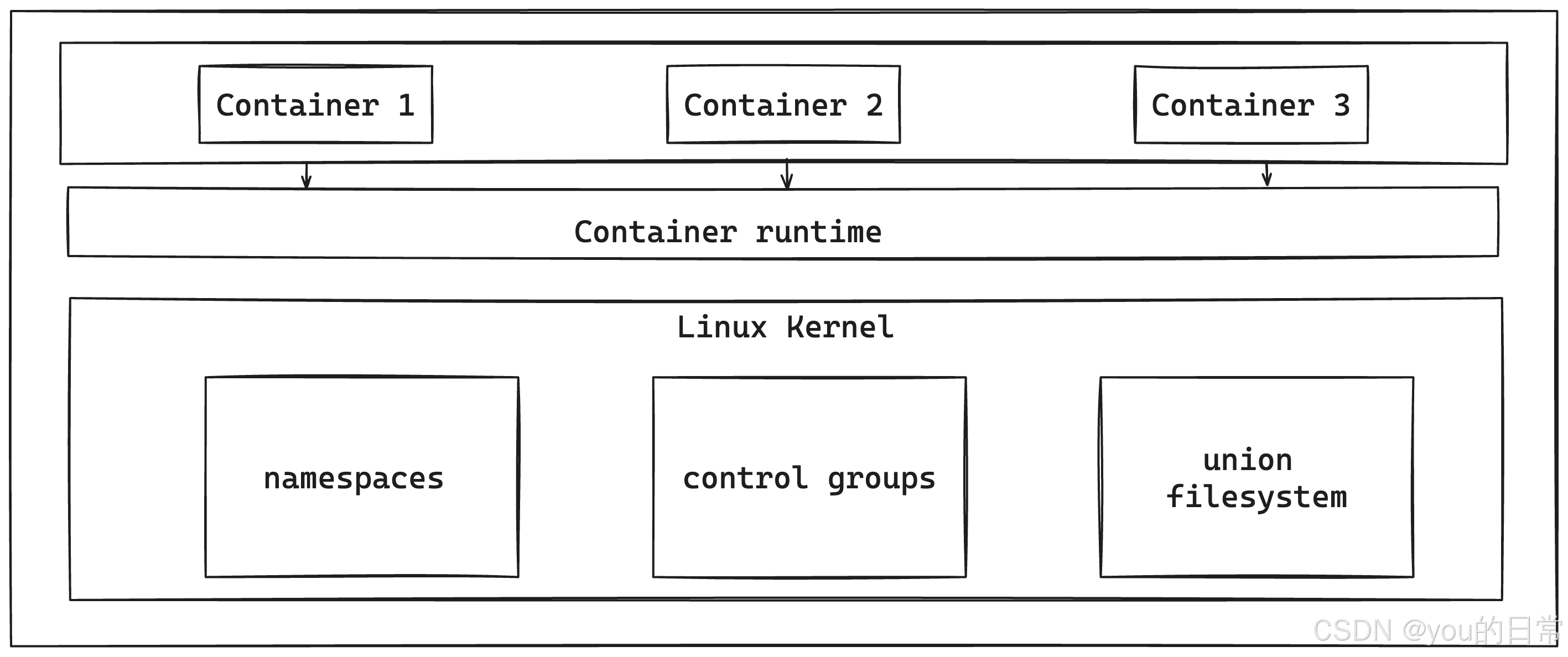
三、Cgroups (Control Groups):资源限制的守护者
Cgroups 是 Linux 内核的另一个强大功能,它负责对进程组的资源使用进行限制、审计和隔离。如果说 Namespaces 解决了“可见性”的问题(让容器看到一个独立的资源集合),那么 Cgroups 解决的就是“配额”的问题(限制容器能够使用多少资源)。
A. 什么是 Cgroups?
Cgroups 允许我们将一组进程组织起来,然后为这组进程设置各种资源使用的上限,例如 CPU 时间、内存用量、磁盘 I/O、网络带宽等。
B. Cgroups 的作用
- 资源限制 (Resource Limiting): 防止某个容器耗尽宿主机的所有资源。
- 优先级 (Prioritization): 为不同的容器分配不同的资源份额。
- 审计 (Accounting): 监控和报告进程组的资源使用情况。
- 控制 (Control): 暂停或恢复进程组的执行。
C. 常见的 Cgroups 子系统
Cgroups 提供了多个子系统,每个子系统控制一种特定的资源:
-
CPU 子系统:
- 限制容器能使用的 CPU 时间份额(
cpu.cfs_quota_us和cpu.cfs_period_us)。 - 设置 CPU 份额(
cpu.shares),决定当 CPU 资源紧张时,容器能获得多少 CPU 时间的比例。 - Docker 命令示例:
# 限制容器最多使用 0.5 个 CPU 核(即 50% 的 CPU) docker run -d --name my_cpu_limited_container --cpus 0.5 alpine sh -c "while true; do :; done"# 设置 CPU 份额为 512 (默认是 1024,即获得一半的 CPU 资源) docker run -d --name my_cpu_shares_container --cpu-shares 512 alpine sh -c "while true; do :; done"
- 限制容器能使用的 CPU 时间份额(
-
Memory 子系统:
- 限制容器可以使用的内存总量(
memory.limit_in_bytes)。 - 设置 OOM(Out Of Memory)行为,当容器内存超限时的处理方式。
- Docker 命令示例:
# 限制容器最多使用 100MB 内存 docker run -d --name my_mem_limited_container --memory 100m alpine sh -c "while true; do head /dev/zero; done"
- 限制容器可以使用的内存总量(
-
Blkio 子系统:
- 限制容器对块设备(如硬盘、SSD)的读写 I/O 速率。
-
Net_cls / Net_prio 子系统:
- 用于对容器的网络流量进行标记,以便通过流量控制工具(如
tc)进行管理和限制。
- 用于对容器的网络流量进行标记,以便通过流量控制工具(如
D. Cgroups 的工作原理
Cgroups 通过一个文件系统接口暴露给用户。在 Linux 系统中,你可以在 /sys/fs/cgroup 路径下看到各种 Cgroup 子系统对应的目录。每个子系统目录下都会有对应容器的目录,其中包含一系列配置文件,通过修改这些文件,可以控制容器的资源。
# 查看一个容器的 CPU Cgroup 配置 (假设容器 ID 为 <container_id>)
# 这表示在 100ms 的周期内,容器最多只能运行 50ms
sudo cat /sys/fs/cgroup/cpu/docker/<container_id>/cpu.cfs_quota_us
sudo cat /sys/fs/cgroup/cpu/docker/<container_id>/cpu.cfs_period_us# 查看容器的内存限制
sudo cat /sys/fs/cgroup/memory/docker/<container_id>/memory.limit_in_bytes# 查看一个进程所属的 Cgroup
# 替换 <process_id> 为容器内 PID 1 对应的宿主机 PID
sudo cat /proc/<process_id>/cgroup
四、Docker 如何整合 Namespaces 和 Cgroups
当您执行 docker run 命令时,Docker Daemon 会在底层协调 Namespaces 和 Cgroups,为您的容器构建一个隔离且受控的运行环境:
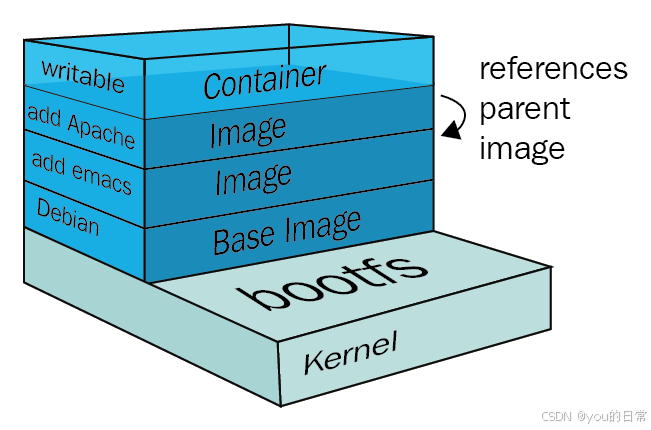
- 创建 Root Filesystem: Docker 会根据您指定的镜像,利用联合文件系统(Union File System)技术为容器创建一个独立的只读层和可写层,作为容器的根文件系统。
- Namespaces 创建: Docker 调用 Linux 内核的
clone()系统调用,并传入CLONE_NEWPID,CLONE_NEWNS,CLONE_NEWNET等标志位,为容器创建一套新的 PID、Mount、Network、UTS、IPC 命名空间。 - Cgroups 限制: Docker 将容器的第一个进程(通常是容器的入口点或
CMD指定的命令)放入预设的 Cgroup 中,并根据docker run命令中的--cpus,--memory等参数,在对应的 Cgroup 子系统目录中写入限制值。 - 进程启动: 在全新的命名空间和资源限制下,容器内的应用程序进程启动。
实际案例分析:
当我们执行以下 Docker 命令时:
docker run -d --name my_app_container --cpus 0.5 --memory 100m busybox sh -c "while true; do echo 'Hello Docker'; sleep 1; done"
--name my_app_container:为容器指定名称。--cpus 0.5:通过 Cgroups 的 CPU 子系统将容器的 CPU 使用率限制在 0.5 核。--memory 100m:通过 Cgroups 的 Memory 子系统将容器的内存使用限制在 100MB。- 当
busybox sh -c "while true; do echo 'Hello Docker'; sleep 1; done"这个命令在容器内启动时:- 它会在独立的 PID Namespace 中运行(在容器内看到它的 PID 可能是 1)。
- 它在独立的 Mount Namespace 中,其文件系统是 busybox 镜像的瘦身版。
- 它在独立的 Network Namespace 中,拥有自己的网络栈。
- 同时,这个进程会被放置到由 Docker 创建的 Cgroup 中,受到 CPU 0.5 核和内存 100MB 的限制。
五、总结与展望
Namespaces 和 Cgroups 是 Docker 容器化技术的核心支柱。Namespaces 提供了进程、文件系统、网络等资源的隔离性视图,让容器感觉像一个独立的操作系统;而 Cgroups 则提供了对 CPU、内存、I/O 等资源的限制和配额管理,确保容器不会过度消耗宿主机资源,从而保证了多租户环境下的稳定性和公平性。
理解这些底层原理,不仅能帮助我们更好地使用 Docker,进行问题排查和性能优化,还能加深对 Linux 操作系统本身进程管理和资源调度机制的理解。随着容器技术的不断发展,特别是围绕 OCI(Open Container Initiative)标准的演进,这些核心原理依然是容器生态系统不可动摇的基石。