深度学习中常见损失函数激活函数
损失函数
一、分类任务损失函数

二、回归任务损失函数


三、生成对抗网络(GAN)损失函数
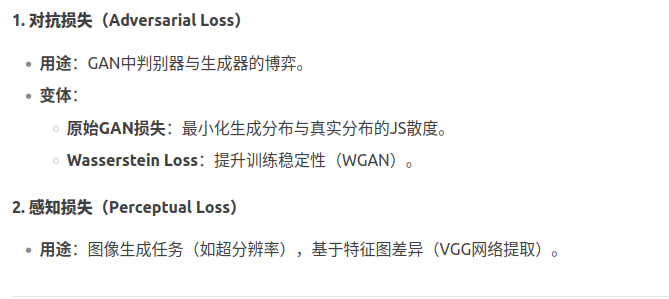
四、其他专用损失函数
 五、损失函数选择原则
五、损失函数选择原则
-
任务类型:分类用交叉熵,回归用MSE/MAE。
-
数据分布:类别不平衡时选择Focal Loss或Dice Loss。
-
鲁棒性需求:异常值多时选用Huber Loss。
-
模型结构:GAN需配合对抗损失,检测任务需IoU-aware损失(如DFL)。
激活函数
一、常见激活函数及特点


二、激活函数与损失函数的关联

三、激活函数与损失函数的协作方法

3. 任务驱动选择
| 任务类型 | 输出层激活函数 | 损失函数 |
|---|---|---|
| 单标签分类 | Softmax | Cross-Entropy Loss |
| 多标签分类 | Sigmoid | BCE Loss |
| 回归(无限制) | 无 | MSE / MAE Loss |
| 回归(非负输出) | ReLU | Huber Loss |
| 边界框回归(检测) | 无 | DFL + IoU Loss |
常见问题
Q1:为什么ReLU不用于输出层?
-
ReLU的输出无界(0~+∞),不适合概率或回归任务(需控制范围)。
Q2:如何选择隐藏层激活函数?
-
默认用ReLU(计算高效);遇死亡神经元问题换LeakyReLU/Swish。
Q3:激活函数和损失函数可以随意组合吗?
-
不能!需匹配任务需求(如Softmax配Cross-Entropy,Sigmoid配BCE)。