RAG+AI工作流+Agent:LLM框架该如何选择
引言
在当今人工智能飞速发展的时代,大型语言模型(LLM)已经成为自然语言处理领域的核心技术,广泛应用于智能客服、内容创作、智能翻译等众多场景。而检索增强生成(RAG)技术与AI工作流、Agent的结合,更是为LLM的应用带来了新的突破和发展。然而,面对市场上琳琅满目的LLM框架,如MaxKB、Dify、FastGPT、RagFlow、Anything - LLM等,开发者往往陷入选择困境。本文将深入剖析这些框架的特点、优势与不足,为大家在框架选择上提供全面的参考。
各框架详细介绍与分析
MaxKB:企业知识管理的得力助手
技术框架和原理
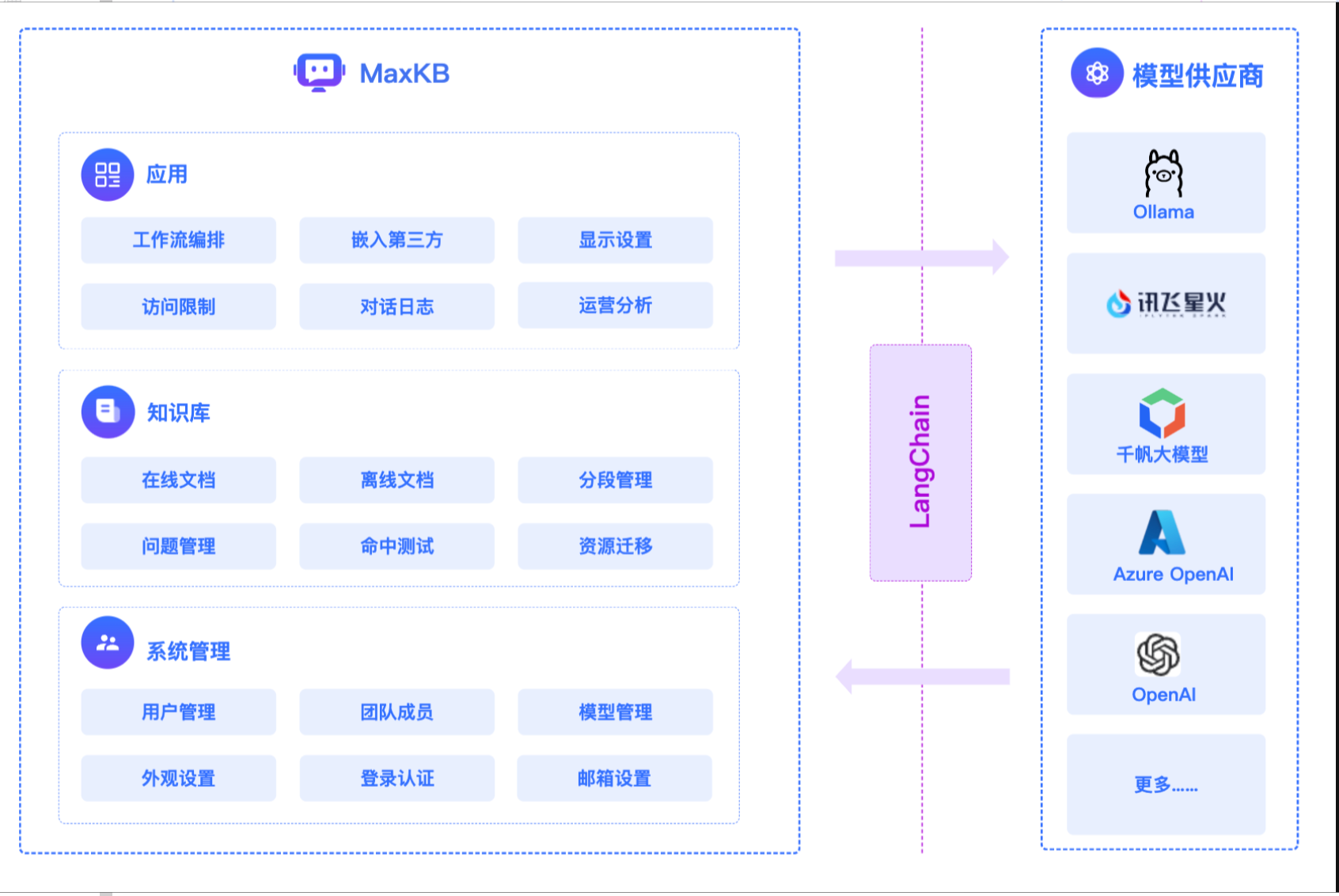
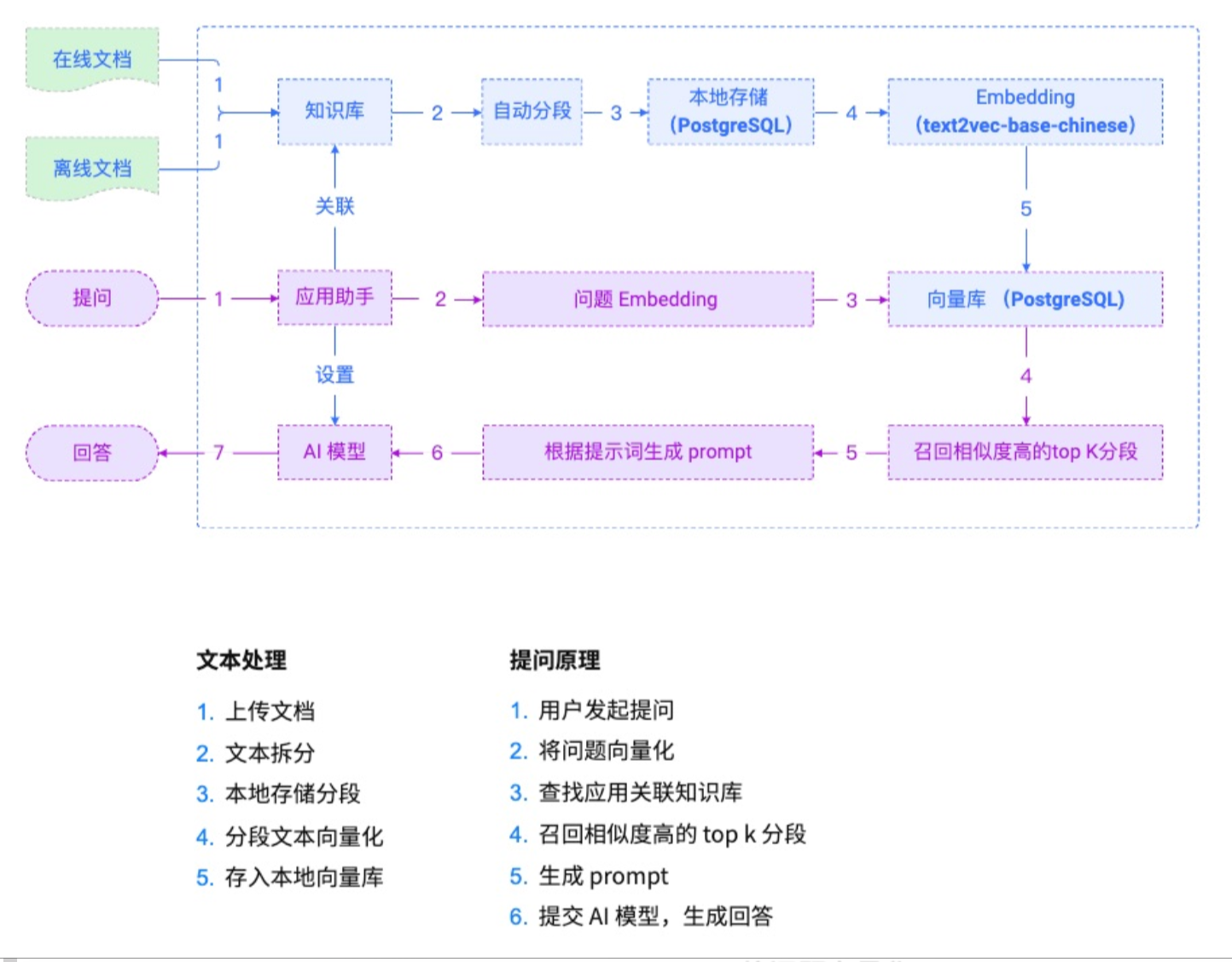
功能特点
MaxKB是一款基于LLM大语言模型的开源知识库问答系统。它开箱即用,支持直接上传文档、自动爬取在线文档,并且能对文本进行自动拆分、向量化以及RAG处理,为用户带来出色的智能问答交互体验。它还支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力。此外,MaxKB内置强大的工作流引擎,具备灵活编排的特性,支持编排AI工作流程,满足复杂业务场景下的需求。同时,它秉持模型中立原则,支持对接各种大语言模型,无论是本地私有大模型、国内公共大模型还是国外公共大模型,用户可根据自身需求和场景灵活选择。
应用场景
在企业内部知识库场景中,MaxKB表现出色。员工通过自然语言提问,MaxKB能迅速定位相关文档并给出准确答案,大幅提升了企业内部知识获取的效率。在客户服务场景,MaxKB同样发挥重要作用,能快速响应客户问题,准确解答,有效减轻了客服人员的工作负担,同时提高了客户满意度。
优势与局限
优势在于智能问答交互体验好,能有效减少大模型幻觉,提供准确的答案;多模型支持让用户在不同场景下都能选择最适配的模型,提升应用效果;工作流引擎的灵活编排使得它可以应对复杂业务逻辑。不过,在处理极其复杂、专业领域的深度知识时,可能由于知识库的覆盖范围或模型理解能力,答案的准确性和深度会有所欠缺。并且,在与部分复杂架构的第三方系统集成时,可能会遇到兼容性问题,需要额外的技术调试。
Dify:快速搭建生成式AI应用的利器
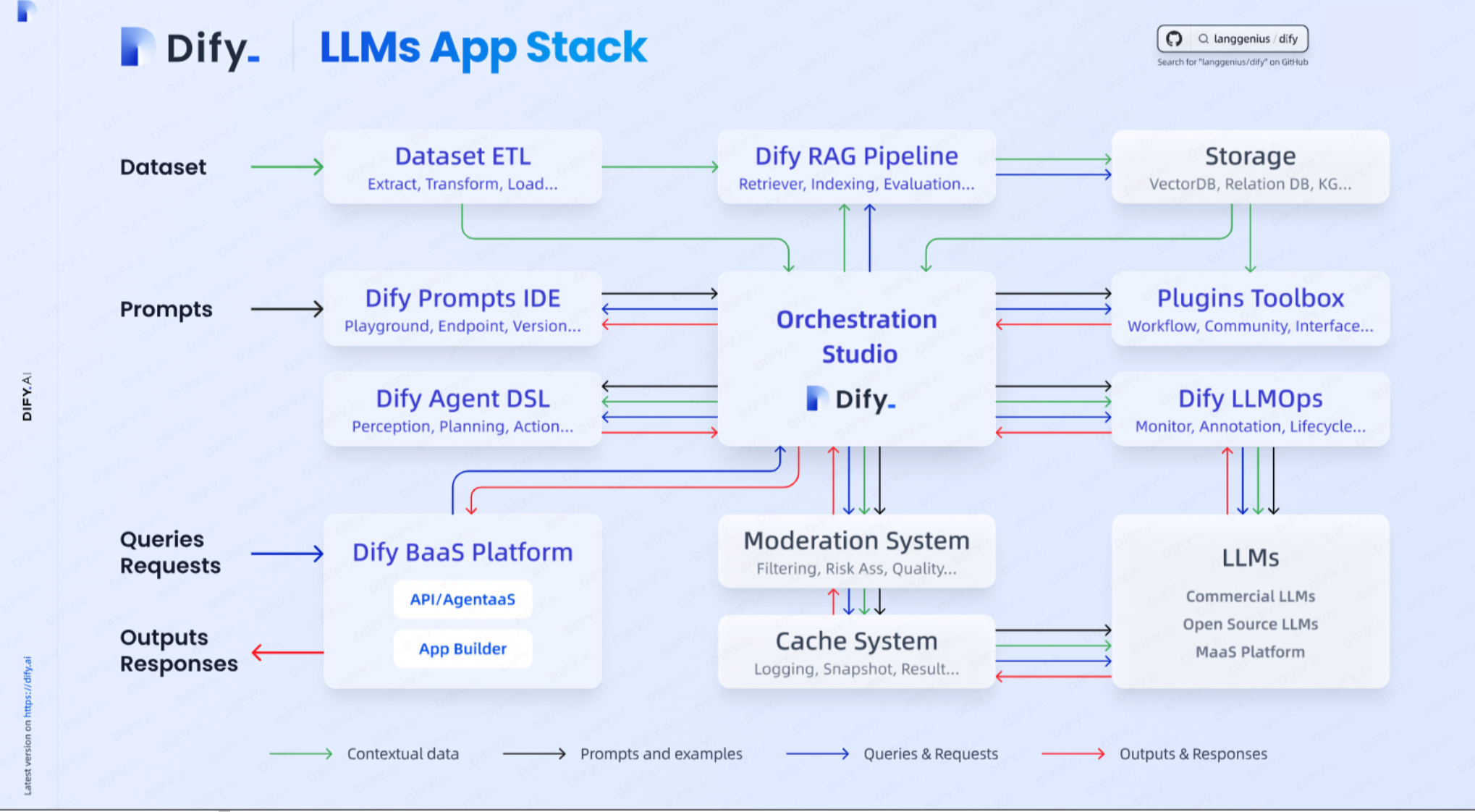
系统框架
功能特点
Dify是一款融合了后端即服务(Backend as Service)和LLMOps理念的开源大语言模型(LLM)应用开发平台,能让开发者快速搭建生产级的生成式AI应用。其工作流功能十分强大,用户可在其提供的画布上快速构建可执行自动化任务的AI应用。在模型支持方面,Dify表现全面,支持大多数市面上流行的AI模型。它还提供了直观简洁的界面,其中的Prompt IDE用于编写提示、比较模型性能以及向基于聊天的应用程序添加文本转语音等附加功能。另外,Dify具备RAG功能,涵盖从文档中摄取到的需要检索的所有内容,支持上传PDF、PPT和其他常见文档格式。
应用场景
在客户服务场景,Dify可构建智能客服机器人,24小时在线回答客户问题,大大提高了客户服务效率,降低了人力成本。在内容生成领域,新媒体运营人员可以借助Dify快速生成文章大纲、内容摘要甚至完整的文章,极大提高了内容创作的效率和质量。在任务自动化方面,企业的办公流程中,如数据整理、报告生成等重复性任务,都可以通过Dify进行自动化设置,解放人力。
优势与局限
优势显著,其低代码/无代码开发特性,通过可视化的方式允许开发者轻松定义Prompt、上下文和插件等,无需深入底层技术细节,降低了开发门槛,使更多人能够参与到AI应用开发中。Dify的模块化设计,每个模块都有清晰的功能和接口,开发者可以根据需求选择性地使用这些模块来构建自己的AI应用,提高了开发的灵活性和效率。其丰富的功能组件,如AI工作流、RAG管道、Agent、模型管理等,为开发者提供了从原型到生产的全方位支持。不过,它的性能高度依赖于底层的大语言模型,如果模型本身在某些任务上的表现有限,Dify也难以完全弥补。对于非常复杂或高度专业化的任务,Dify的提示工程和少样本学习可能无法完全满足需求,或许需要结合微调模型等其他技术。另外,使用大语言模型通常需要支付API调用费用,尤其是在高频调用或大规模部署时,成本可能较高,这对一些预算有限的开发者或企业来说,是需要考虑的因素。
FastGPT:专注知识库问答的高效框架
功能特点
FastGPT是一个基于LLM大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。在数据处理方面,它提供手动输入、直接分段、LLM自动处理和CSV等多种数据导入途径,兼顾精确和快速训练场景。FastGPT具备强大的工作流编排能力,基于Flow模块,用户可以设计更加复杂的问答流程。
应用场景
可作为智能客服系统,与用户进行自然流畅的对话交流,提升客户满意度和客服效率。在内容创作领域,能为创作者提供灵感和辅助,提高创作效率和质量。在学术研究方面,通过定制化训练,可成为学术研究的得力助手,帮助研究人员快速获取相关文献和信息。在教育培训领域,能辅助教师备课、答疑,为学生提供个性化的学习辅导。
优势与局限
优势在于高效的文档解析和检索能力,适合需要高精度知识库检索和复杂工作流编排的企业。然而,FastGPT的部署相对复杂,资源消耗较大。并且,其灵活性较低,深度定制需代码介入;处理复杂任务时成功率受限。
RagFlow:深度文档理解的高精度引擎
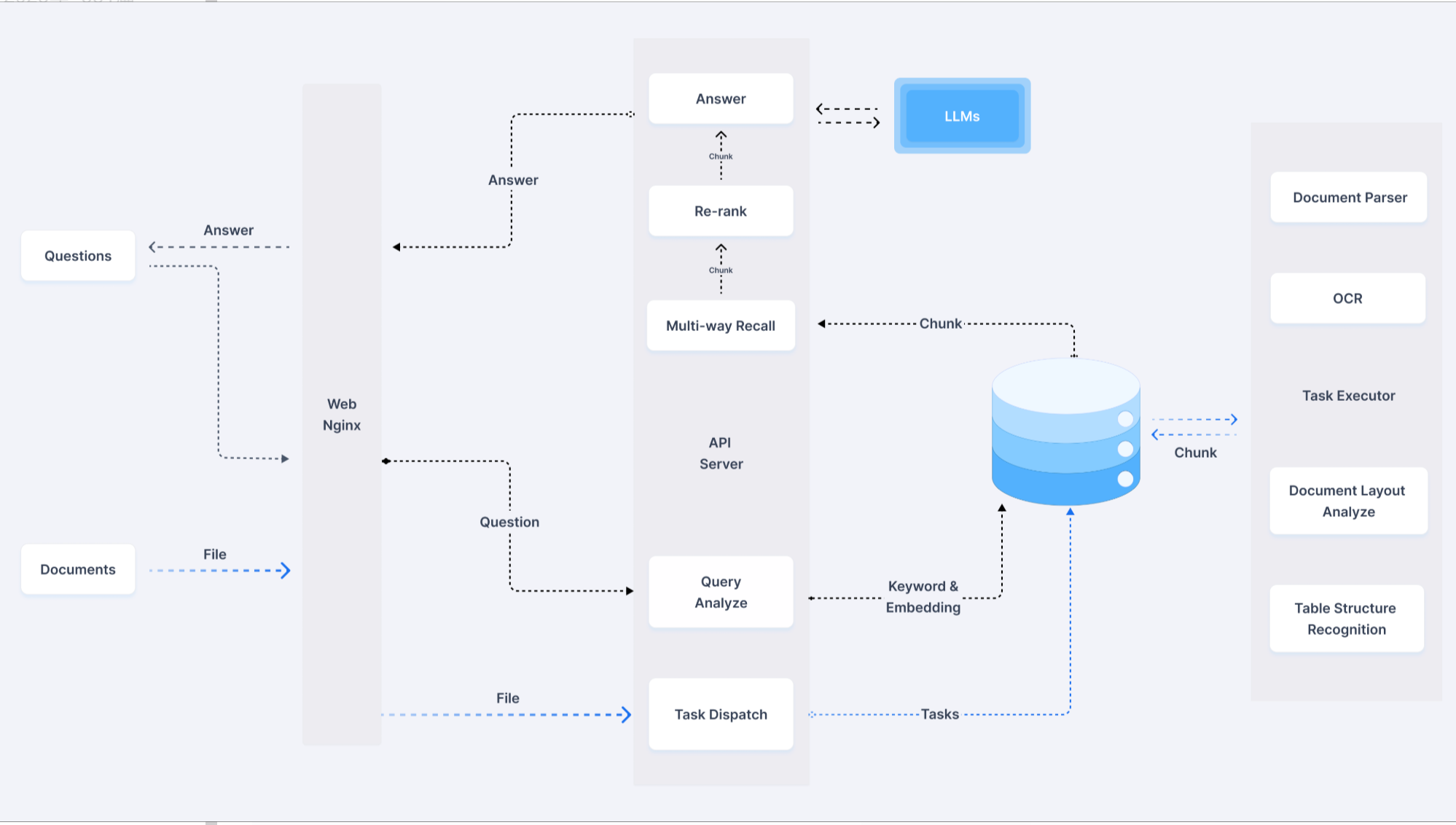
系统架构
功能特点
RAGFlow是一个基于对文档深入理解的开源RAG(检索增强生成)引擎。它支持多文档类型(PDF/Word/Markdown)和多语言处理,提供灵活的参数配置(如切块大小、检索阈值),适配主流LLM(如ChatGPT、LLaMA)和开源检索库。其核心在于能够让用户创建自有知识库,根据设定的参数对知识库中的文件进行切块处理,用户向大模型提问时,RAGFlow先查找自有知识库中的切块内容,接着把查找到的知识库数据输入到对话大模型中再生成答案输出。
应用场景
适合需要深度文档问答的场景,如法律文书审查、学术论文库的知识检索、医疗报告分析等。在这些场景中,RAGFlow能够处理复杂的文档结构,准确提取关键信息,为用户提供高精度的答案。
优势与局限
优势在于深度文档处理能力强,内置DeepDoc引擎,支持图片(OCR提取文本)、PDF、Excel和网页的智能解析,能处理多列PDF和嵌套表格,近期版本还新增多模态LLM支持。高精度检索,提供可视化分块和引用追踪,参数调整丰富,确保结果相关性。开源自托管,免费部署,数据隐私有保障,支持GPU加速,问答流程支持动态检索和模板定制。缺点是上手门槛较高,需Docker和依赖管理,配置复杂,对非技术用户不够友好。生态较小,社区和插件支持不如一些大型框架,扩展功能需自行开发。资源需求高,处理大文档需GPU支持,硬件要求较高。
Anything - LLM:隐私优先的本地知识库问答系统
功能特点
Anything - LLM是一款全栈AI应用程序,其核心定位是搭建本地文档与人工智能模型之间的桥梁,旨在解决企业级知识管理、数据安全与模型定制化的需求。该工具通过检索增强生成(RAG)技术,将用户上传的文档、网页、音视频等内容转化为结构化知识库,并结合本地运行的大语言模型(LLM),实现基于私有数据的智能问答、信息检索和自动化任务处理。它支持多模型兼容性,可解析多种文档类型,提供多用户协作与权限管理,有灵活的部署方式,并且是开发者友好型设计。
应用场景
适用于高隐私行业,如医疗机构病历分析、金融机构内部风控文档处理。在这些场景中,数据的隐私和安全至关重要,Anything - LLM的本地化部署和多用户权限管理能够满足这些需求。也适用于科研场景,如实验室敏感研究数据管理,科研人员可以在本地安全地使用和管理数据。
优势与局限
优势在于数据完全私有、支持本地模型,能解决通用大模型的“幻觉”问题,同时满足企业对数据隐私和定制化的需求。提供了一套低成本、高灵活性的解决方案,尤其适合需要深度融合私有数据的场景。不足在于部分用户反馈,在复杂问题或长文本场景下,AI的回答准确性有待提升,需优化文本召回和排序算法。此外,初次配置需一定学习成本,尤其是向量数据库的选择与调优。
各框架对比总结
| 框架名称 | 核心定位 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| MaxKB | 企业级知识库问答系统 | 权限体系完善、多模型灵活切换、开源免费;智能问答体验好,工作流编排灵活 | 部署需一定技术基础,本地模型需自备GPU资源;处理复杂专业知识准确性和深度可能不足,与部分第三方系统集成有兼容性问题 | 企业内外部知识库、客服系统,安全敏感场景如金融、政务领域的私有化部署需求 |
| Dify | 低代码AI应用开发平台 | 低代码高效开发、扩展性强、多模态支持;可视化工作流设计,多模型支持,实时监控 | 复杂场景需编写自定义代码,部分高级功能需付费;性能依赖底层模型,复杂任务提示工程和少样本学习可能不足,API调用成本较高 | 快速原型开发,企业自动化,如初创团队构建智能客服、营销文案生成工具,与内部系统集成实现工单自动分类、报告生成 |
| FastGPT | 快速构建GPT应用的轻量化工具 | 部署简单、成本低、社区活跃;一键部署,提示词优化,知识库同步,成本控制 | 依赖OpenAI接口,国内使用需代理;功能扩展性较弱,处理复杂任务成功率受限 | 中小企业FAQ系统,个性化助手,如电商商品咨询、教育机构课程问答,基于私有数据定制个人学习/办公助手 |
| RagFlow | 基于RAG的非结构化文档处理工具 | 文档解析能力强、检索效率高;深度文档处理,高精度检索,开源自托管 | 数据需上传云端,隐私性受限;按文档量计费,成本不可控;上手门槛高,生态小,资源需求高 | 企业文档管理,自动化审核,如法律合同分析、学术论文库、医疗报告归档,金融领域的合规性检查、发票信息提取 |
| Anything - LLM | 私有化部署的LLM知识库解决方案 | 全本地部署、数据隐私保障;多模型支持,文档管理与知识库构建功能强,多用户协作与权限管理 | 部署复杂,需专业运维;本地模型性能弱于云端大模型;复杂问题回答准确性有待提升,初次配置学习成本高 | 高隐私需求场景,如医疗机构病历分析、金融机构内部风控文档处理,科研场景实验室敏感研究数据管理 |
选择建议
根据团队技术能力选择
- 技术能力较弱的团队:Dify和FastGPT是不错的选择。Dify的低代码/无代码开发特性,让非技术人员也能轻松参与到AI应用开发中,通过可视化界面即可完成大部分操作。FastGPT部署简单,提供Docker - Compose脚本,5分钟内即可完成部署,对技术要求较低。
- 技术能力较强的团队:MaxKB、RagFlow和Anything - LLM更适合。MaxKB虽然部署需要一定技术基础,但它的多模型支持和灵活的工作流编排,能满足复杂业务场景的需求。RagFlow虽然上手门槛高,但对于有技术实力的团队来说,其深度文档处理和高精度检索能力能在专业领域发挥巨大优势。Anything - LLM的本地部署和多用户权限管理需要专业运维,但能保障数据的高度隐私和安全。
根据应用场景选择
- 企业知识管理场景:MaxKB是首选,它能快速构建企业内部知识库,支持多种数据格式导入,并且具备完善的权限管理体系,能有效提高企业内部知识获取的效率。
- 快速原型开发场景:Dify最为合适,其可视化工作流设计和丰富的模板,能让团队在短时间内搭建出智能客服、内容生成等应用的原型。
- 知识库问答场景:FastGPT专注于知识库问答,能提供详细准确的回答,并且支持多轮对话和上下文关联,适合构建FAQ问答机器人等。
- 复杂文档处理场景:RagFlow的文档解析能力强,能处理PDF、表格、图表等复杂格式的文档,适合法律、医疗、制造业等需要深度文档理解的行业。
- 高隐私需求场景:Anything - LLM的本地化部署和多用户权限管理,能确保数据的隐私和安全,适合金融、医疗等对数据隐私要求极高的行业。
结论
在选择RAG + AI工作流 + Agent的LLM框架时,没有绝对的最佳选择,需要根据团队的技术能力、项目的预算、应用场景等多方面因素进行综合考虑。每个框架都有其独特的优势和局限性,开发者应根据自身的实际需求,权衡各框架的优缺点,选择最适合自己的框架,以实现项目的高效开发和应用。希望本文的分析和建议能为大家在框架选择上提供有益的参考。