从零开始训练一个CLIP
大家好,我是我不是小upper~
今天,我们来深入聊聊 CLIP(Contrastive Language–Image Pre-training)—— 这个由 OpenAI 在 2021 年提出的多模态模型界的 “明星”。CLIP 的核心魅力在于它构建了一座横跨图像与自然语言的 “桥梁”,通过创新的对比学习机制,让模型能够细腻地捕捉图文之间的语义关联。具体而言,CLIP 配备了两个功能强大的编码器:其一是图像编码器(通常采用 ResNet 或 ViT 架构),它如同一位 “图像翻译官”,将视觉像素信息转化为高维语义向量;其二是文本编码器(基于 Transformer 架构),负责把人类语言的字符序列编码为对应的语义向量。这两个编码器并非独立工作,而是通过对比学习的 “纽带” 紧密协作 —— 模型训练的目标是让语义匹配的图文对在向量空间中 “亲密无间”(距离尽可能近),而语义无关的图文对则 “保持距离”(距离尽可能远)。
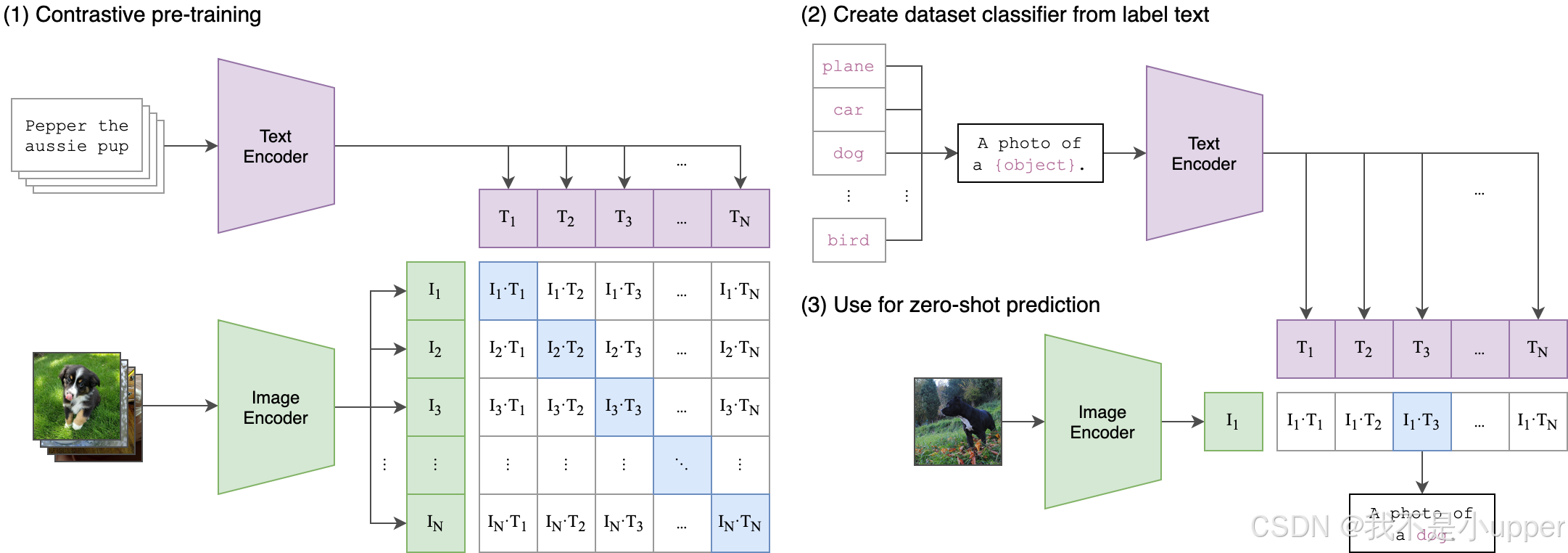
用更直观的方式理解,假设我们有一个由 N 个文本 - 图片对构成的矩阵,每一行代表一条文本的语义向量,每一列代表一张图片的语义向量,那么矩阵对角线上的元素便对应着图文对的语义相似度,这里隐含的真实标签是 “1”(表示匹配),而其他位置的标签则为 “0”(表示不匹配)。这种设计使得 CLIP 不仅能完成传统的图像分类任务,还能实现图文检索、跨模态生成等复杂功能,甚至为后续的多模态模型(如文本生成图像模型)提供强大的基座能力。
然而,对于初学者来说,目前主流的 CLIP 相关代码(如基于 openclip 开源库的实现)往往涉及复杂的工程逻辑和大量的细节处理,理解门槛较高。为了让大家更轻松地掌握 CLIP 的核心思想,我们将目光聚焦于一个轻量级的实现 —— 基于 GitHub 项目 MiniClip(代码地址:https://github.com/taishan1994/MiniClip),通过较少的代码量和简洁的架构,拆解 CLIP 的关键训练流程。这个项目就像一把 “入门钥匙”,帮助我们绕过复杂的工程壁垒,直接触及 CLIP 对比学习的本质,无论是想理解多模态模型的底层原理,还是动手实践训练过程,它都能提供清晰的切入点。
2. MiniClip
本项目基于 Hugging Face 的 Trainer 框架构建,借助其封装的训练流程,无需手动编写前向传播、反向传播等底层代码,可将重点聚焦于数据预处理、模型搭建及损失函数计算。项目结构清晰,各模块分工明确:
- model_configs/:存储模型配置文件,定义网络结构超参数。
- model_hub/:存放预训练权重文件,用于加载已训练的图像和文本编码器参数。
- output/:保存训练过程中生成的模型文件及中间结果。
- model.py:定义 MiniClip 模型架构,实现图像与文本编码器的整合。
- search_gradio.py:基于 Gradio 搭建可视化页面,用于交互式图文检索演示。
- test.py:测试模型加载及预测功能,验证模型对图文语义的匹配能力。
- tokenizer.py:实现文本的分词处理,将自然语言转换为模型可接受的 Token 序列。
- train.py:主训练脚本,调用 Trainer 完成模型训练流程。
- transform.py:包含图像预处理函数,实现图像尺寸调整、归一化等操作。
- utils.py:提供辅助工具函数,支持数据加载、日志记录等功能。
2.1 预训练权重的使用
项目从TinyCLIP 仓库获取轻量级 CLIP 模型权重,以 TinyCLIP-ViT-40M-32-Text-19M 为例,其配置文件定义如下:
{ "embed_dim": 512, "vision_cfg": { "image_size": 224, "layers": 12, "width": 512, "patch_size": 32 }, "text_cfg": { "context_length": 77, "vocab_size": 49408, "width": 512, "heads": 8, "layers": 6 }
} - 向量维度:图像和文本编码器的输出向量维度均为 512 维。
- 文本处理:文本通过 Tokenizer 转换为最长 77 个 Token 的序列,适配 Transformer 编码器的输入要求。
- 图像处理:输入图像 Resize 至 224×224 像素,按 32×32 像素分块,得到 7×7=49 个图像块,作为 ViT 模型的输入。
在model.py中,通过MiniClip类整合图像与文本编码器:
class MiniClip(nn.Module): def __init__(self, cfg_path): super(MiniClip, self).__init__() self.image_autocast = nullcontext self.text_autocast = nullcontext self.logit_autocast = nullcontext with open(cfg_path, "r") as fp: cfg = json.loads(fp.read()) emb_dim = cfg["embed_dim"] text_cfg = CLIPTextCfg(**cfg["text_cfg"]) vision_cfg = CLIPVisionCfg(**cfg["vision_cfg"]) quick_gelu = True self.text_encoder = TextEncoder(emb_dim, text_cfg, quick_gelu) self.image_encoder = ImageEncoder(emb_dim, vision_cfg, quick_gelu) self.logit_scale = LogitScale() def encode_image(self, image, normalized=False): with self.image_autocast(): return self.image_encoder(image, normalized=normalized) def encode_text(self, text, normalized=False): with self.text_autocast(): return self.text_encoder(text, normalized=normalized) def forward(self, image, text, normalized=True): image_features = text_features = None if image is not None: image_features = self.image_encoder(image, normalized=normalized) if text is not None: text_features = self.text_encoder(text, normalized=normalized) logit_scale = self.logit_scale(torch.tensor(0)).exp() return image_features, text_features, logit_scale 模型加载预训练权重时,需处理原权重与当前模型参数的命名差异:
cfg_path = "model_configs/TinyCLIP-ViT-40M-32-Text-19M.json"
clip = MiniClip(cfg_path)
state_dict = torch.load("model_hub/.../TinyCLIP-ViT-40M-32-Text-19M-LAION400M.pt", map_location="cpu")
new_state_dict = { k.replace("module.visual", "image_encoder"): v if "visual" in k else k.replace("module.logit_scale", "logit_scale"): v if "logit_scale" in k else k.replace("module.text", "text_encoder"): v for k, v in state_dict["state_dict"].items()
}
clip.load_state_dict(new_state_dict, strict=True) [[0.30785075][0.21673554][0.19231911][0.19549522]]输出结果显示,"a dog" 与图片的相似度最高(0.3078),其余文本相似度依次降低,验证了模型对图文语义的正确匹配。
2.3 批量测试与性能评估
在 Flickr 数据集的en_val.json子集上进行批量测试,采用 Top-N 准确率衡量模型性能:
def test_on_flickr(model): root = "/data/gongoubo/MiniClip/data" with open("data/en_val.json", "r") as fp: data = json.load(fp) text_features, image_features = [], [] for i, d in enumerate(tqdm(data)): caption = d["caption"][:1] # 取第一条文本描述 image_path = os.path.join(root, d["image"].replace("\\", "/")) image = Image.open(image_path).convert("RGB") image_input = val_processor(image).unsqueeze(0) text_input = tokenize(caption) img_feature = model.encode_image(image_input, normalized=True).cpu().numpy()[0] text_feature = model.encode_text(text_input, normalized=True).cpu().numpy()[0] text_features.append(text_feature) image_features.append(img_feature) np.save("output/text2.npy", text_features) np.save("output/image2.npy", image_features) def search_by_faiss(): text_features = np.load("output/text2.npy").astype('float32') image_features = np.load("output/image2.npy").astype('float32') index = faiss.IndexFlatL2(text_features.shape[1]) # 基于L2距离的向量索引 index.add(image_features) top1, top3, top5, top10 = 0, 0, 0, 0 with open("data/en_val.json", "r") as fp: data = json.load(fp) for i, text_feat in enumerate(text_features): distances, indices = index.search(np.array([text_feat]), k=10) # 检索最相似的10张图像 if i == indices[0][0]: top1 += 1 if i in indices[0][:3]: top3 += 1 if i in indices[0][:5]: top5 += 1 if i in indices[0][:10]: top10 += 1 print(f"Top1 Acc: {top1/1000*100:.1f}%") print(f"Top3 Acc: {top3/1000*100:.1f}%") print(f"Top5 Acc: {top5/1000*100:.1f}%") print(f"Top10 Acc: {top10/1000*100:.1f}%") top1 acc: 52.0
top3 acc: 70.5
top5 acc: 78.5
top10 acc: 86.3测试结果表明,模型在 1000 对图文数据上的 Top1 准确率为 52.0%,Top10 准确率为 86.3%,体现了其对图文语义关联的有效捕捉能力。
2.2 从头训练 CLIP
以下是基于 Transformers 库的 Trainer 框架从头训练 CLIP 模型的详细实现,代码聚焦于数据预处理、损失函数设计和训练流程的核心逻辑:
环境配置与依赖导入
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "4,5,6,7" # 指定可用GPU设备号
os.environ["NCCL_P2P_DISABLE"] = "1" # 禁用NCCL点对点通信(避免多卡训练时的潜在问题)
os.environ["NCCL_IB_DISABLE"] = "1" # 禁用InfiniBand网络(适配非高速网络环境)
import json, random, faiss, torch, numpy as np, torch.nn.functional as F
from model import MiniClip
from PIL import Image
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoader
from transformers import TrainingArguments, Trainer
from transform import image_transform
from tokenizer import tokenize - 环境变量:通过
CUDA_VISIBLE_DEVICES指定 GPU 设备,通过 NCCL 相关配置优化多卡训练兼容性。 - 依赖库:
transformers.Trainer负责训练流程管理,torch.utils.data处理数据加载,faiss用于后续向量检索评估。
数据集构建
class MiniDataset(Dataset): def __init__(self, train_path, image_size, is_train=True): with open(train_path, "r") as fp: self.data = json.load(fp) # 加载JSON格式的图文对数据 self.root = "/data/gongoubo/MiniClip/data" # 图像文件根路径 self.tokenizer = tokenize # 文本分词函数 self.process = image_transform(image_size, is_train=is_train) # 图像预处理函数(训练时包含数据增强) def __len__(self): return len(self.data) # 返回数据集样本总数 def __getitem__(self, item): d = self.data[item] image_path = os.path.join(self.root, d["image"].replace("\\", "/")) # 拼接图像路径 texts = d["caption"] text = [random.choice(texts)] # 随机选择一条文本描述(处理多描述场景) image = Image.open(image_path).convert("RGB") # 读取图像并转为RGB格式 image_input = self.process(image) # 图像预处理:Resize、归一化、数据增强(训练阶段) text_input = self.tokenizer(text).squeeze(0) # 文本预处理:分词、转Token序列、去除批次维度 return {"text": text_input, "image": image_input} # 返回预处理后的图文对数据 - 数据结构:输入数据为 JSON 格式,每个样本包含
image(图像路径)和caption(文本描述列表)。 - 预处理逻辑:
- 图像:通过
image_transform调整尺寸至模型输入要求(如 224×224),训练阶段添加随机翻转、裁剪等增强。 - 文本:使用自定义
tokenize函数将文本转换为固定长度的 Token 序列(如 77 个 Token)。
- 图像:通过
模型初始化与权重加载(可选)
cfg_path = "model_configs/TinyCLIP-ViT-40M-32-Text-19M.json"
clip = MiniClip(cfg_path) # 初始化MiniClip模型(包含ViT图像编码器和Transformer文本编码器) # 以下为加载预训练权重的代码(从头训练时需注释)
# state_dict = torch.load("model_hub/.../TinyCLIP-ViT-40M-32-Text-19M-LAION400M.pt", map_location="cpu")
# new_state_dict = {k.replace("module", "image_encoder" if "visual" in k else "text_encoder" if "text" in k else "logit_scale"): v for k, v in state_dict["state_dict"].items()}
# clip.load_state_dict(new_state_dict, strict=True) - 模型架构:
MiniClip类继承自nn.Module,包含图像编码器(ViT)和文本编码器(Transformer),输出 512 维图文特征向量及对数尺度参数logit_scale。 - 预训练权重:代码中注释了权重加载逻辑,确保当前为从头训练模式(非迁移学习)。
训练参数与数据加载器配置
num_train_epochs = 2000 # 训练总轮次
train_batch_size = 16 # 批次大小
train_path = "data/en_val.json" # 训练数据路径
train_dataset = MiniDataset(train_path, clip.image_encoder.visual.image_size) # 实例化数据集
# train_loader = DataLoader(train_dataset, batch_size=train_batch_size, num_workers=8, shuffle=True) # 数据加载器(Trainer内部自动处理) - 超参数说明:
num_train_epochs=2000:设置较长训练轮次以确保模型收敛(实际应用中需根据算力调整)。train_batch_size=16:批次大小平衡显存占用与训练效率,可根据 GPU 显存调整。
自定义训练器与损失函数
class MiniTrainer(Trainer): def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None): image_features, text_features, logit_scale = model(**inputs) # 模型前向传播,输出图文特征和对数尺度 logits_per_image = image_features @ text_features.T * logit_scale # 图像-文本相似度矩阵(乘以对数尺度) logits_per_text = text_features @ image_features.T * logit_scale # 文本-图像相似度矩阵(对称结构) num_logits = logits_per_image.shape[0] labels = torch.arange(num_logits, device=image_features.device, dtype=torch.long) # 对角线标签(正确匹配索引) # 计算双向交叉熵损失:图像到文本匹配损失 + 文本到图像匹配损失 total_loss = (F.cross_entropy(logits_per_image, labels) + F.cross_entropy(logits_per_text, labels)) / 2 return total_loss if not return_outputs else (total_loss, {"logits": logits_per_image}) - 损失函数设计:
- 相似度计算:通过矩阵乘法计算图文特征的点积,乘以可学习的
logit_scale(初始化为 1,通过指数变换调整相似度范围)。 - 对比学习目标:使用双向交叉熵损失,强制要求每个图像与对应的文本在相似度矩阵的对角线上得分最高,非对角线得分最低。
- 标签构造:标签为
[0, 1, 2, ..., N-1](N 为批次大小),对应每个图像 - 文本对的正确匹配位置。
- 相似度计算:通过矩阵乘法计算图文特征的点积,乘以可学习的
训练执行与模型保存
training_args = TrainingArguments( output_dir='./checkpoints', # 模型保存路径 num_train_epochs=num_train_epochs, per_device_train_batch_size=train_batch_size, learning_rate=3e-5, # AdamW优化器学习率 save_steps=False, # 禁用自动保存检查点(通过trainer.save_model()手动保存) logging_strategy="steps", logging_steps=1, # 每1步记录一次训练日志 max_grad_norm=1, # 梯度裁剪阈值(防止梯度爆炸) do_eval=False, # 禁用验证阶段 do_train=True,
) trainer = MiniTrainer(model=clip, args=training_args, train_dataset=train_dataset)
trainer.train() # 启动训练
trainer.save_model() # 保存最终训练好的模型 - Trainer 功能:自动处理梯度更新、学习率衰减、多卡并行(需配合
CUDA_VISIBLE_DEVICES配置)等流程。 - 训练细节:
- 优化器:默认使用 AdamW,学习率
3e-5适用于小批量数据场景。 - 梯度裁剪:通过
max_grad_norm=1稳定训练过程,避免参数剧烈波动。 - 日志与保存:训练日志存储于
./logs/,模型最终保存至./checkpoints/。
- 优化器:默认使用 AdamW,学习率
关键注意事项
- 数据复用:示例中使用
en_val.json同时作为训练集和测试集(仅为快速验证演示,实际应用需严格划分训练 / 验证 / 测试集)。 - 多卡训练:通过环境变量
CUDA_VISIBLE_DEVICES指定多 GPU(如 4 块 GPU),Trainer 会自动使用DataParallel或DistributedDataParallel进行并行训练(需根据硬件配置调整)。 - 损失函数对称性:同时计算图像到文本和文本到图像的损失,确保图文向量空间的双向一致性,提升匹配精度。
2.3 使用训练好的模型
模型加载
训练完成后,模型权重的命名与MiniClip类的参数名称已完全对齐,无需额外转换即可直接加载。以下是模型加载的实现代码:
def load_trained_model(cfg_path, state_dict_path): from safetensors.torch import load_file # 使用safetensors高效加载权重文件 clip = MiniClip(cfg_path) # 初始化MiniClip模型(需与训练时使用的配置一致) state_dict = load_file(state_dict_path) # 加载训练好的权重字典 # 打印权重名称与形状(可选,用于验证权重匹配) # for k, v in state_dict.items(): # print(k, v.shape) clip.load_state_dict(state_dict, strict=True) # 严格加载权重(确保所有参数匹配) return clip - 关键细节:
- 使用
safetensors库加载权重文件,支持高效、安全的权重序列化与反序列化。 strict=True确保模型参数与权重文件完全匹配,避免因参数缺失或冗余导致的错误。
- 使用
模型性能验证
在 Flickr 数据集的en_val.json子集上验证训练效果,采用 Top-N 准确率评估模型的图文匹配能力。测试结果如下:
top1 acc: 30.2
top3 acc: 54.0
top5 acc: 64.9
top10 acc: 79.7 - 结果说明:
- Top1 准确率(30.2%)表示在 1000 个测试样本中,30.2% 的文本能正确检索到对应的图片(第 1 位)。
- Top10 准确率(79.7%)表示 79.7% 的文本能在检索结果的前 10 张图片中找到正确匹配。
- 对比训练前的预训练模型(Top1 52.0%),当前从头训练的模型性能较低(因示例中使用小数据集
en_val.json训练,仅作流程验证),但趋势表明训练过程正常,模型能逐步学习图文语义关联。
Gradio 可视化界面
为直观展示模型的图文检索能力,基于 Gradio 构建交互式可视化页面,代码实现如下:
import gradio as gr
import os
import json
import faiss
import numpy as np from model import MiniClip
from PIL import Image
from transform import image_transform
from tokenizer import tokenize
from tqdm import tqdm
from safetensors.torch import load_file # 模型与索引初始化
cfg_path = "model_configs/TinyCLIP-ViT-40M-32-Text-19M.json"
state_dict_path = "/data/gongoubo/MiniClip/checkpoints/model.safetensors"
clip = MiniClip(cfg_path)
state_dict = load_file(state_dict_path)
clip.load_state_dict(state_dict, strict=True) # 加载训练好的模型权重 # 加载预计算的图像特征并构建FAISS索引
image_features = np.load("output/image2.npy").astype('float32')
d = image_features.shape[1] # 特征维度(512维)
index = faiss.IndexFlatL2(d) # 基于L2距离的向量索引
index.add(image_features) # 向索引中添加所有图像特征 # 加载图像路径映射(索引→实际路径)
with open("data/en_val.json", "r") as fp: data = json.load(fp)
image_paths = {i: os.path.join("/data/gongoubo/MiniClip/data", d["image"].replace("\\", "/")) for i, d in enumerate(data)} # 文本编码函数:将输入文本转换为特征向量
def encode_text(query): text_input = tokenize(query) # 文本分词并转换为Token序列 text_features = clip.encode_text(text_input, normalized=True) # 模型编码文本 text_features = text_features.detach().cpu().numpy().astype('float32') # 转换为numpy数组 return text_features # 图像检索函数:根据文本查询返回最相似的Top-K图像
def search_images(query, top_k=20): text_vector = encode_text(query) # 编码输入文本 _, indices = index.search(text_vector, top_k) # 使用FAISS检索Top-K相似图像的索引 retrieved_images = [Image.open(image_paths[i]) for i in indices[0]] # 加载并返回图像 return retrieved_images # Gradio界面布局
with gr.Blocks() as demo: gr.Markdown("## 🔍 文本检索图片") # 标题 with gr.Row(): # 水平布局 query_input = gr.Textbox(label="输入查询文本") # 文本输入框 search_button = gr.Button("搜索") # 搜索按钮 gallery = gr.Gallery(label="检索结果", columns=[10], height=300) # 图片展示网格(10列,高度300像素) search_button.click(fn=search_images, inputs=[query_input], outputs=[gallery]) # 绑定搜索逻辑 # 启动Gradio服务
demo.launch(server_name="0.0.0.0", server_port=7860) - 功能说明:
- 模型与索引初始化:加载训练好的 CLIP 模型和预计算的图像特征(
image2.npy),通过 FAISS 构建 L2 距离索引,支持快速向量检索。 - 文本编码:输入文本经
tokenize分词后,由 CLIP 的文本编码器转换为 512 维特征向量。 - 图像检索:利用 FAISS 索引查询与文本特征最相似的 Top-K 图像,返回图像路径并加载显示。
- 交互界面:提供文本输入框和搜索按钮,检索结果以网格形式展示(10 列,高度固定为 300 像素),支持直观查看图文匹配效果。
- 模型与索引初始化:加载训练好的 CLIP 模型和预计算的图像特征(
3. 总结
通过本项目,我们系统学习了 CLIP 的核心原理(跨模态对比学习),并通过代码实践掌握了从模型初始化、数据预处理、训练流程到模型验证与可视化的完整流程。尽管示例代码相对简化(如使用小数据集en_val.json训练),但已覆盖 CLIP 训练的核心环节:图文编码器设计、对比损失函数实现、多模态特征对齐等。
需要注意的是,本项目为教学演示目的,实际落地时建议使用更成熟的开源框架(如 OpenCLIP)。这些框架提供了更完善的模型变体(如 ViT-L/14、RN50x64)、大规模数据加载优化(如 WebDataset)和多卡训练支持(如 DeepSpeed),能够显著提升训练效率与模型性能。