【漫话机器学习系列】268. K 折交叉验证(K-Fold Cross-Validation)
图解 K 折交叉验证(K-Fold Cross-Validation)| 原理 + 数学公式 + 实践应用
原图作者:Chris Albon,手绘风格清晰易懂,本文基于其图解做详细扩展,适用于机器学习、深度学习初学者及进阶者参考学习。
一、什么是 K 折交叉验证?
K 折交叉验证(K-Fold Cross-Validation)是一种评估机器学习模型性能的重采样方法。它通过将原始训练数据划分为 K 个相等的子集(fold),反复训练和验证模型,从而更稳定、更可靠地评估模型在未知数据上的泛化能力。
为什么要使用交叉验证?
-
减少模型评估的方差,提高模型评估的鲁棒性;
-
更加充分地利用数据(相较于单一的训练/验证集划分);
-
适用于模型选择、参数调优等任务中的性能对比。
二、K 折交叉验证的流程详解
以 K=5 为例:
-
将数据集划分为 5 个等份;
-
每次使用其中 1 份作为验证集,剩下 4 份作为训练集;
-
训练模型并计算验证误差(Loss);
-
重复上述过程 5 次(每份数据都做一次验证集);
-
对 5 次的验证误差取平均,作为最终评估指标。
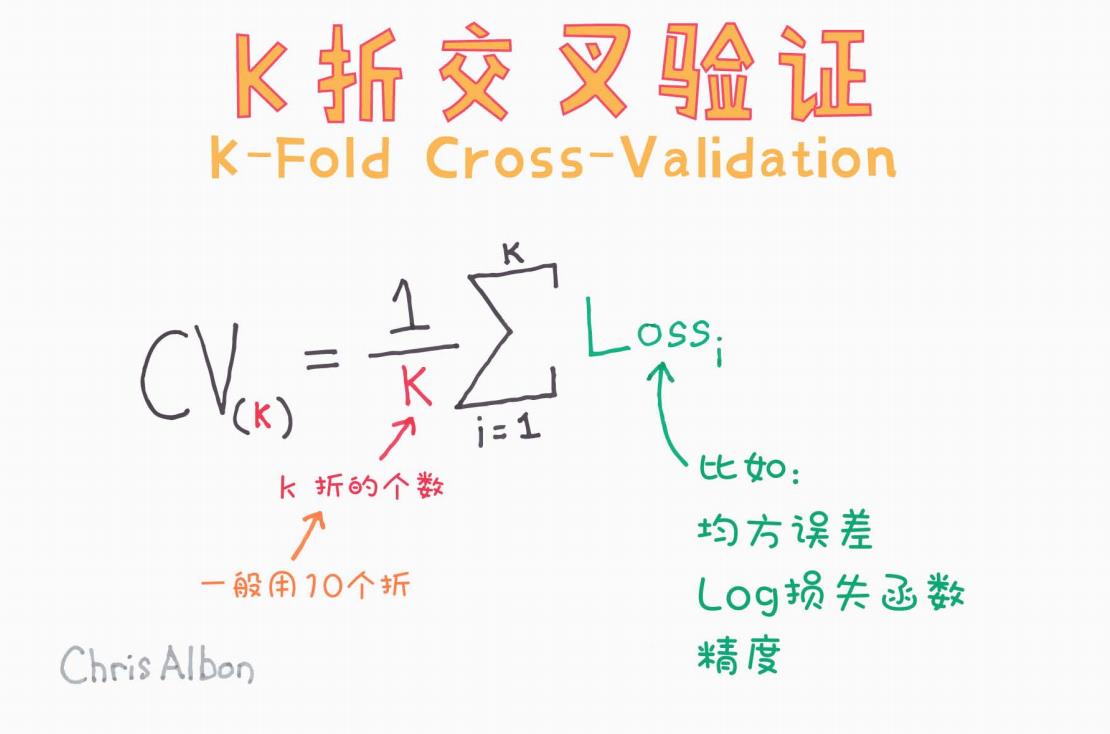
图示公式说明:
图片中给出的是 K 折交叉验证的数学公式:
解释如下:
-
K:表示将数据集划分为的折数,常用 10 折(10-Fold);
-
:第 i 折验证集上的损失值(例如均方误差);
-
:K 折交叉验证的平均损失值。
三、如何选择 K 值?
-
10 折交叉验证(K=10):实践中最常见,兼顾了训练充分与验证稳定;
-
5 折交叉验证(K=5):当数据量不大时也较常用;
-
Leave-One-Out(K = N):每次只留一条数据作为验证,计算开销大,但评估极为稳定。
一般推荐使用 10-Fold,因为它在偏差与方差之间取得了较好的平衡。
四、Loss(损失函数)可以是什么?
在不同的任务场景下,损失函数(Loss)可以有多种选择,图片中也列举了常见的三种:
-
均方误差(MSE):用于回归问题,惩罚偏差较大的预测值;
-
对数损失函数(Log Loss):用于二分类或多分类,衡量概率预测的准确度;
-
精度(Accuracy):用于分类问题,衡量预测正确的比例。
你可以根据实际任务选择合适的评估指标。
五、代码实现(以 scikit-learn 为例)
下面是一个使用 scikit-learn 实现 K 折交叉验证的简单示例:
from sklearn.model_selection import KFold, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import numpy as np# 加载数据集
X, y = load_iris(return_X_y=True)# 定义模型
model = LogisticRegression(max_iter=200)# 定义 KFold(10折)
kf = KFold(n_splits=10, shuffle=True, random_state=42)# 执行交叉验证
scores = cross_val_score(model, X, y, cv=kf, scoring='accuracy')# 输出结果
print("每折的准确率:", scores)
print("平均准确率:", np.mean(scores))
六、K 折交叉验证的优缺点
优点:
-
能较全面地使用全部数据;
-
结果更加稳定;
-
减少对特定训练/验证集划分的依赖。
缺点:
-
计算成本高(尤其是深度学习模型);
-
当数据分布不均或有时间依赖(时序数据)时需小心使用。
七、总结
K 折交叉验证是机器学习中不可或缺的模型评估工具。理解其原理、数学表达与实践意义,有助于你更科学地开发、调优和比较模型表现。
小贴士:
-
想要快速上手:推荐使用
scikit-learn中的cross_val_score; -
想控制更细粒度:可以自定义训练/验证流程配合
KFold; -
如果使用时间序列:考虑
TimeSeriesSplit等变种交叉验证方法。
💬 如果你觉得这篇图解和讲解对你有帮助,欢迎点赞 👍、收藏 ⭐、评论 📩 支持一下!