《Python星球日记》 第92天:AI模型部署工程化基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、引言
- 二、模型部署工具
- 1. Flask部署工具
- 2. FastAPI部署工具
- 3. Docker容器化部署(一次构建,随处运行)
- 三、RESTful API 设计
- 1. 什么是 RESTful API
- 2. API 接口设计原则
- 3. API 文档编写
- 四、实战练习:模型部署为 RESTful API
- 1. 准备简单模型
- 2. 使用 FastAPI 构建 API
- 3. 容器化部署
- 五、总结与展望
- 1. 今日要点回顾
- 2. 进阶学习方向
- 3. 实践建议
- 参考资料
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第91天:端到端 LLM 应用(综合项目:医疗文档助手)
欢迎回到Python星球🪐日记!今天是我们旅程的第92天。
昨天我们学习了LLM实战应用,今天我们将探索AI工程中的重要环节:模型部署。将训练好的模型投入实际使用,是AI项目落地的关键步骤。本文将带你了解常用的部署工具、API设计原则,并通过代码实践将简单模型部署为可用的服务。
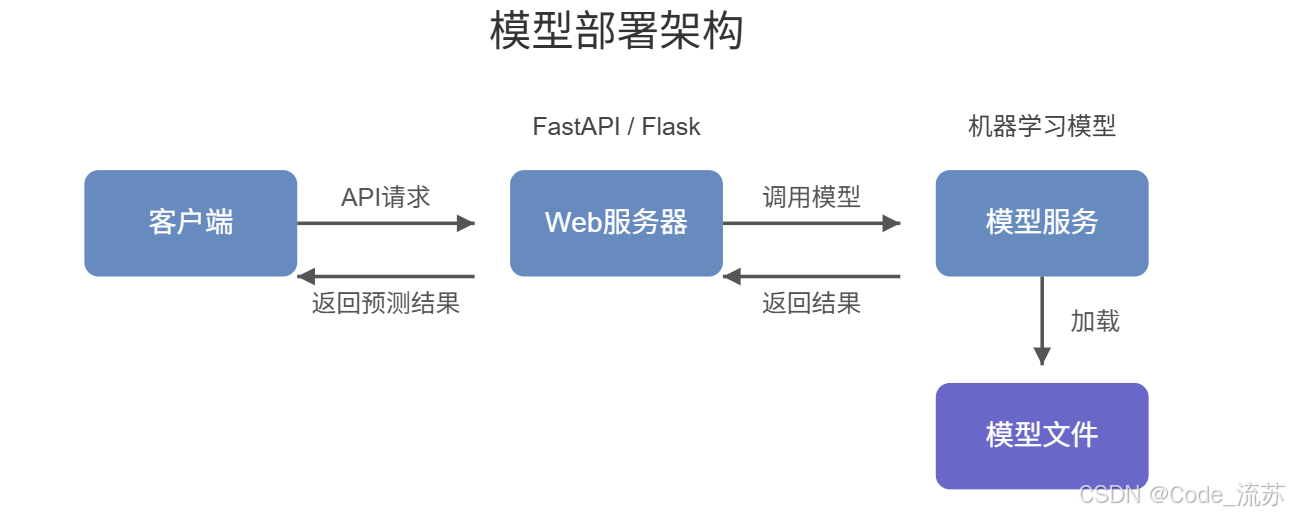
一、引言
当我们完成了模型的训练和评估后,模型部署是将AI能力真正实现商业价值的关键环节。就像建造一座房子,模型训练是打地基和建造框架,而部署则是让这座房子真正可以住人并发挥作用。今天,我们将学习如何将训练好的AI模型"搬上舞台",让它为用户提供实际服务。
在前面的课程中,我们已经掌握了从机器学习到深度学习,再到大语言模型的各种技术。现在,我们需要解决的问题是:如何让这些模型走出实验室,变成可以随时调用的服务?这正是今天我们要探讨的内容。
二、模型部署工具
将AI模型部署为可用服务,需要依靠一些专业工具。这些工具各有特色,适合不同的应用场景。
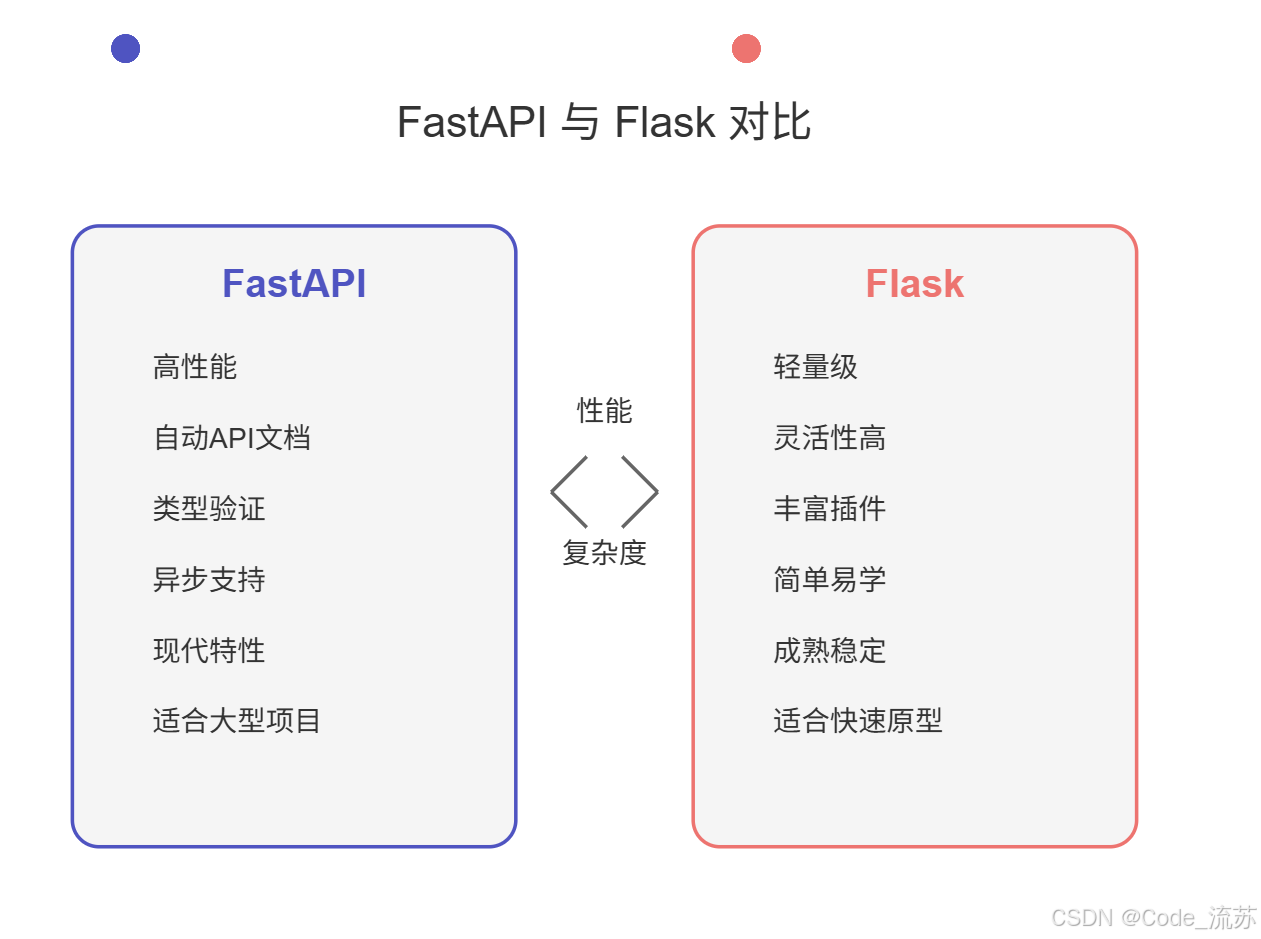
1. Flask部署工具
Flask我们在之前有专门的文章介绍,在此再简单回顾一下,Flask是Python中最轻量级的Web框架之一,非常适合快速搭建API服务。
Flask特点:
- 轻量级,易于学习和使用
- 灵活性高,可根据需求自由扩展
- 丰富的插件生态系统
- 适合小型到中型项目的原型开发
下面是使用Flask部署模型的基本代码结构:
from flask import Flask, request, jsonify
import joblib# 初始化Flask应用
app = Flask(__name__)# 加载预训练模型
model = joblib.load('model.pkl')# 定义API端点
@app.route('/predict', methods=['POST'])
def predict():# 获取输入数据data = request.json# 使用模型进行预测prediction = model.predict([data['features']])# 返回预测结果return jsonify({'prediction': prediction.tolist()})if __name__ == '__main__':app.run(debug=True, host='0.0.0.0', port=5000)
2. FastAPI部署工具
FastAPI是近年来迅速崛起的现代Web框架,专为API开发而设计,性能出色。
FastAPI特点:
- 高性能,接近原生性能
- 自动生成交互式API文档
- 内置数据验证功能
- 支持异步编程
- 现代化的类型提示系统
下面是使用FastAPI部署模型的示例代码:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import joblib
import uvicorn
import numpy as np# 定义输入数据模型
class InputData(BaseModel):features: list# 初始化FastAPI应用
app = FastAPI(title="模型预测API")# 加载预训练模型
model = joblib.load('model.pkl')# 定义API端点
@app.post("/predict")
async def predict(data: InputData):try:# 使用模型进行预测prediction = model.predict([data.features])return {"prediction": prediction.tolist()}except Exception as e:raise HTTPException(status_code=500, detail=str(e))if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000)
FastAPI vs Flask:
3. Docker容器化部署(一次构建,随处运行)
Docker是一种容器化技术,可以将应用及其依赖打包成一个独立的容器,确保在任何环境中都能一致运行。
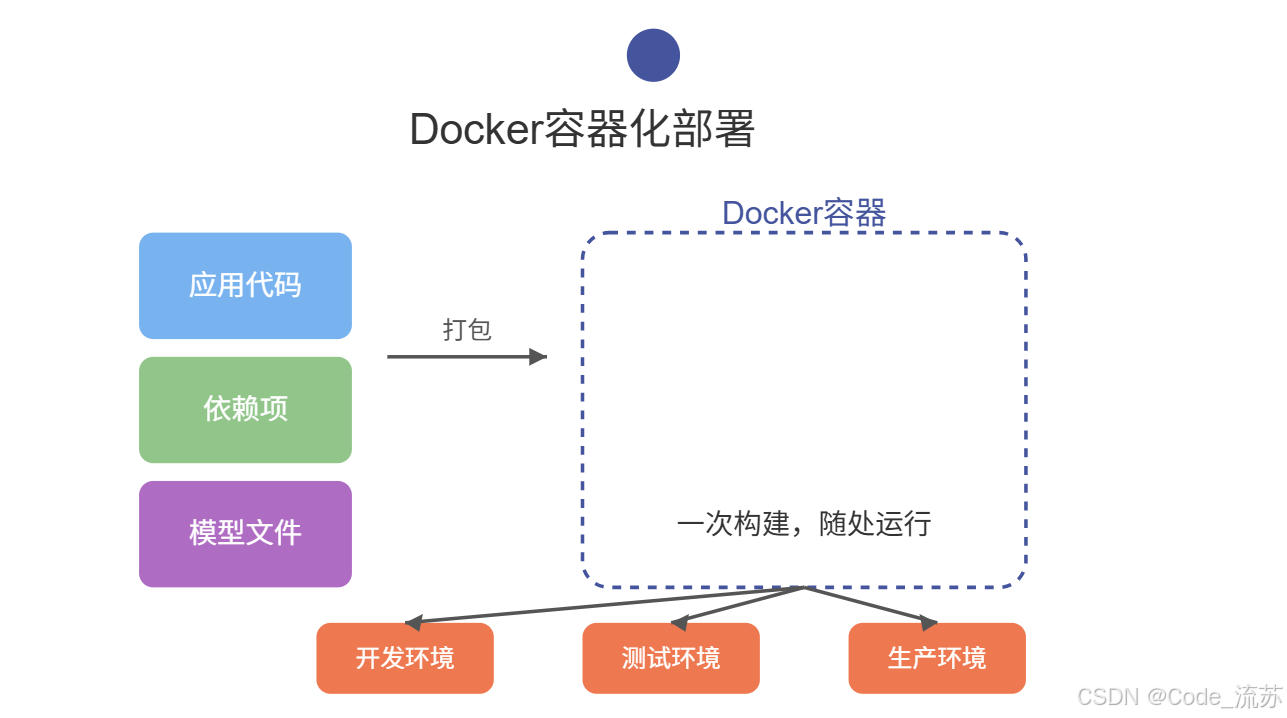
Docker优势:
- 环境一致性,解决"在我的机器上可以运行"的问题
- 资源隔离,避免依赖冲突
- 快速部署和扩展
- 版本控制和回滚方便
创建一个简单的Dockerfile来容器化我们的模型服务:
# 使用Python官方镜像作为基础镜像
FROM python:3.9-slim# 设置工作目录
WORKDIR /app# 复制依赖文件
COPY requirements.txt .# 安装依赖
RUN pip install -r requirements.txt# 复制应用代码和模型
COPY app.py .
COPY model.pkl .# 暴露端口
EXPOSE 5000# 运行应用
CMD ["python", "app.py"]
构建和运行Docker容器的命令:
# 构建Docker镜像
docker build -t ai-model-api .# 运行容器
docker run -p 5000:5000 ai-model-api
三、RESTful API 设计
1. 什么是 RESTful API
RESTful API(Representational State Transfer API)是一种遵循REST架构风格的应用程序接口。它使用HTTP请求执行CRUD(创建、读取、更新、删除)操作,是目前最流行的API设计风格。
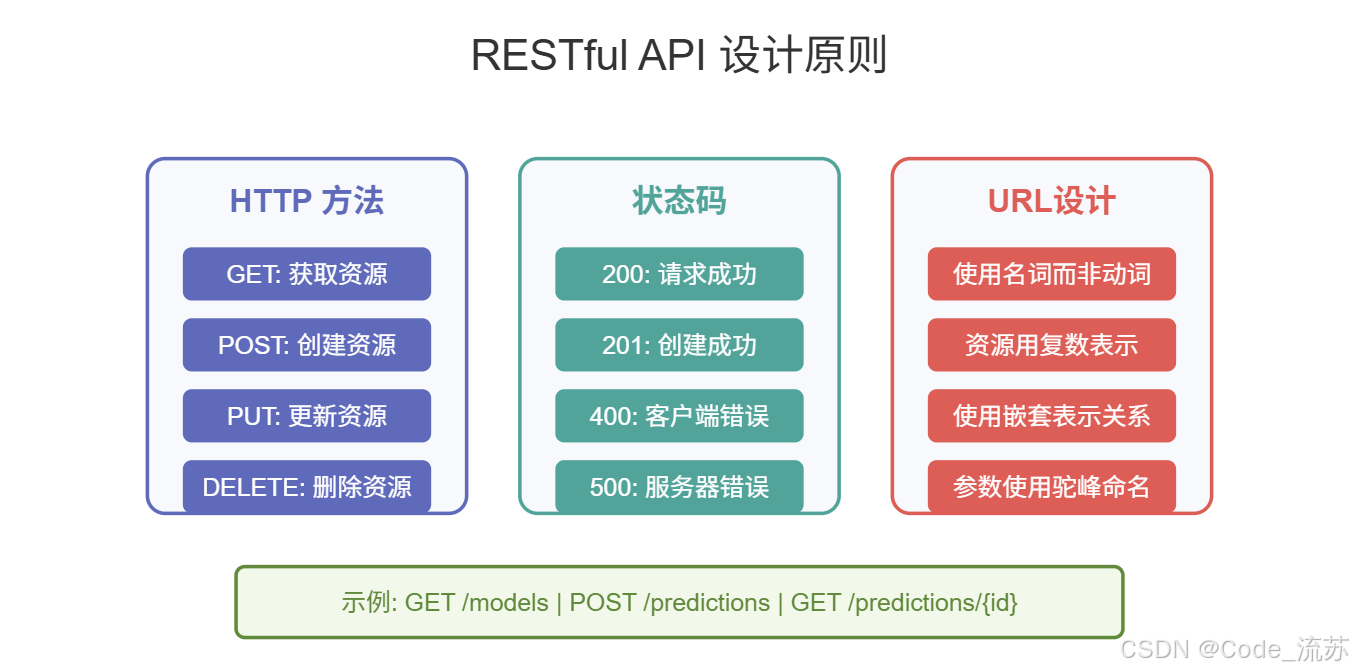
REST的核心理念是将所有内容视为资源,通过标准的HTTP方法来操作这些资源:
GET:获取资源POST:创建新资源PUT/PATCH:更新资源DELETE:删除资源
在AI模型部署中,我们通常将模型的预测功能作为一个资源,通过API接口提供服务。
2. API 接口设计原则
设计良好的API可以大大提高开发效率和用户体验。以下是一些关键原则:
1) 使用合适的HTTP方法
GET /models # 获取所有模型列表
POST /predictions # 创建新的预测请求
GET /predictions/{id} # 获取特定预测结果
2) 统一的URL结构
- 使用名词而非动词
- 使用复数表示资源集合
- 使用嵌套表示资源关系
3) 状态码使用规范
200 OK:请求成功201 Created:资源创建成功400 Bad Request:客户端错误404 Not Found:资源不存在500 Internal Server Error:服务器错误
4) 返回数据格式一致
{"status": "success","data": {"prediction": [0.87, 0.13],"class": "正常"},"message": "预测完成"
}
5) 错误处理清晰明确
{"status": "error","code": "INVALID_INPUT","message": "输入特征格式不正确","details": {"expected": "数组","received": "字符串"}
}
3. API 文档编写
良好的API文档是开发者上手使用API的关键。使用Swagger/OpenAPI等工具自动生成交互式文档是当前的最佳实践。
FastAPI内置了Swagger UI支持,只需少量代码配置:
# app.py
from fastapi import FastAPIapp = FastAPI(title="预测模型API",description="使用机器学习模型进行预测的API接口",version="1.0.0"
)# 端点实现...# 访问 http://localhost:8000/docs 查看自动生成的交互式文档
一个完善的API文档应包含:
| 文档内容 | 说明 |
|---|---|
| 接口概述 | 简要描述API的功能和用途 |
| 请求方法 | GET, POST, PUT, DELETE等 |
| 请求URL | 完整的端点URL |
| 请求参数 | 包括路径参数、查询参数、请求体等 |
| 响应格式 | 成功响应的数据结构 |
| 错误代码 | 可能的错误情况及对应代码 |
| 示例代码 | 不同编程语言的调用示例 |
四、实战练习:模型部署为 RESTful API
现在,让我们将一个简单的机器学习模型部署为可访问的RESTful API服务。我们将使用之前学过的鸢尾花分类模型作为示例。
1. 准备简单模型
首先,我们训练一个简单的分类模型并保存:
# 导入必要的库
import numpy as np
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import joblib# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)# 评估模型
accuracy = model.score(X_test, y_test)
print(f"模型准确率: {accuracy:.4f}")# 保存模型
joblib.dump(model, 'iris_model.pkl')
print("模型已保存至 iris_model.pkl")
2. 使用 FastAPI 构建 API
接下来,我们使用FastAPI创建一个REST API来提供预测服务:
# 导入必要的库
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import joblib
import uvicorn
import numpy as np# 定义输入数据模型
class IrisFeatures(BaseModel):sepal_length: floatsepal_width: floatpetal_length: floatpetal_width: float# 定义响应数据模型
class PredictionResponse(BaseModel):species_id: intspecies_name: strprobability: float# 初始化FastAPI应用
app = FastAPI(title="鸢尾花分类API",description="使用随机森林模型对鸢尾花进行分类",version="1.0.0"
)# 加载预训练模型
try:model = joblib.load('iris_model.pkl')species_names = ['setosa', 'versicolor', 'virginica']
except Exception as e:print(f"模型加载失败: {str(e)}")model = None@app.get("/")
async def root():return {"message": "欢迎使用鸢尾花分类API"}@app.post("/predict", response_model=PredictionResponse)
async def predict(features: IrisFeatures):if model is None:raise HTTPException(status_code=500, detail="模型未正确加载")try:# 转换输入特征为模型所需格式feature_array = np.array([[features.sepal_length,features.sepal_width,features.petal_length,features.petal_width]])# 获取预测结果和概率prediction = model.predict(feature_array)[0]probabilities = model.predict_proba(feature_array)[0]# 返回预测结果return {"species_id": int(prediction),"species_name": species_names[prediction],"probability": float(probabilities[prediction])}except Exception as e:raise HTTPException(status_code=500, detail=str(e))if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000)
3. 容器化部署
最后,我们将API服务容器化,便于部署和管理:
- 创建
requirements.txt文件,列出所有依赖:
fastapi==0.95.0
uvicorn==0.21.1
scikit-learn==1.2.2
joblib==1.2.0
numpy==1.24.2
pydantic==1.10.7
- 创建
Dockerfile:
# 使用Python官方镜像作为基础镜像
FROM python:3.9-slim# 设置工作目录
WORKDIR /app# 复制项目文件
COPY requirements.txt .
COPY app.py .
COPY iris_model.pkl .# 安装依赖
RUN pip install --no-cache-dir -r requirements.txt# 暴露端口
EXPOSE 8000# 启动应用
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
- 构建和运行Docker容器:
# 构建Docker镜像
docker build -t iris-classifier-api .# 运行容器
docker run -d -p 8000:8000 --name iris-api iris-classifier-api
- 测试API:
import requests# API地址
url = "http://localhost:8000/predict"# 测试数据(典型的Iris-setosa特征)
data = {"sepal_length": 5.1,"sepal_width": 3.5,"petal_length": 1.4,"petal_width": 0.2
}# 发送POST请求
response = requests.post(url, json=data)# 打印响应
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.json()}")
五、总结与展望
1. 今日要点回顾
在本篇文章中,我们深入探讨了AI模型部署的基础知识和实践方法。我们学习了三种主要的部署工具:Flask、FastAPI和Docker,每种工具都有其特定的应用场景和优势。
通过了解RESTful API设计的原则,我们掌握了如何构建规范、易用的接口。这些原则包括使用合适的HTTP方法、统一的URL结构、规范的状态码使用以及一致的返回数据格式。良好的API设计是模型服务成功的关键因素之一。
在实战部分,我们完整地实现了将一个鸢尾花分类模型部署为API服务的全流程,从模型训练、保存,到API构建,再到容器化部署。这个过程涵盖了生产环境中模型部署的核心步骤。
2. 进阶学习方向
随着你对模型部署基础的掌握,以下是一些值得深入探索的进阶主题:
- 模型监控与更新:如何监控已部署模型的性能,并实现模型的无缝更新
- 负载均衡与扩展:使用Kubernetes等工具实现服务的自动扩展
- 模型优化:模型量化、剪枝、知识蒸馏等技术,使模型更轻量化
- 边缘设备部署:将模型部署到移动设备、IoT设备等资源受限的环境
- MLOps:机器学习运维,实现模型开发到部署的全自动化流程
3. 实践建议
模型部署是一项需要不断实践的技能。建议你尝试:
- 将自己之前训练的模型(如第43-82天中的项目)部署为API服务
- 探索不同框架(TensorFlow Serving、PyTorch Serve等)的部署方案
- 实践云服务(AWS SageMaker、Azure ML、Google AI Platform)上的模型部署
- 参与开源项目,了解大型AI系统的部署架构
AI模型的真正价值在于它能解决实际问题并为用户提供服务。通过掌握模型部署的技能,你已经向成为一名全面的AI工程师迈出了重要一步!
参考资料
- Flask官方文档:https://flask.palletsprojects.com/
- FastAPI官方文档:https://fastapi.tiangolo.com/
- Docker官方文档:https://docs.docker.com/
- RESTful API设计最佳实践:https://restfulapi.net/
- scikit-learn模型持久化:https://scikit-learn.org/stable/model_persistence.html
你掌握了模型部署的基础知识了吗?欢迎在评论区分享你的实践经验和疑问!
祝你学习愉快,勇敢的Python星球探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!