Hive简介
目录
引入Hive
Hive定义
Hive架构
Hive查询执行流程
Hive查询示例
Hive与MySQL对比
引入Hive
在Hadoop诞生之前,关系型数据库(MySQL等)已经主导数据处理数十年,SQL作为操作数据库的标准语言,是所有数据从业者的必备技能。但后来随着数据量的指数级上升,传统关系型数据库逐渐力不从心。此时Hadoop崛起,成为处理大数据的核心技术。
但是,传统的Hadoop编程模式下,完成一个任务需要:
①编写MR程序:用Java或其他语言写一个Mapper类来提取和转换数据,再写一个Reducer类来进行聚合运算;
②打包项目:将代码和依赖打包成JAR文件;
③提交作业:通过命令将JAR包提交到Hadoop集群上运行;
④获取结果:从HDFS的输出目录中获取结果文件
这意味着:
- 之前熟悉用SQL来做数据处理的人无法直接操作Hadoop,语言的学习门槛高。即使有专业的开发人员,也要面临开发周期长、开发效率低的问题;
- 其次,Hadoop存储的海量数据中,很大一部分是结构化或半结构化数据,这些数据的分析逻辑与传统关系型数据库中的SQL操作完全一致。
既然如此,那为什么不能直接把SQL转换成MapReduce程序来处理数据呢?
Hive工具应运而生,它能够在保留Hadoop大规模数据处理能力的同时,让熟悉SQL的用户高效地分析大数据,彻底降低了大数据分析的门槛。
小tip:Hive同时也继承了Hadoop高延迟的特性,所以在后续持续优化延迟。
Hive定义
Hive是一款基于Hadoop的开源数据仓库工具,为熟悉SQL的用户提供了一种简单、高效的方式来处理和分析HDFS上存储的大规模结构化/半结构化数据。
Hive架构
客户端 (CLI/JDBC/ODBC)
↓
Hive Server2 (Thrift服务)
↓
Driver (驱动引擎)
↓
Compiler (编译器) → Metastore (元数据存储)
↓
Execution Engine (执行引擎)
↓
Hadoop Cluster (HDFS + MapReduce/Tez/Spark)
组件介绍:
客户端:用户与Hive交互的接口;
Hive Server2:提供Thrift接口,相当于“网关”,支持多客户端并发访问;
Driver:接收查询,管理整个查询执行的生命周期;
Compiler:解析、编译、优化HQL查询;
Metastore:存储表结构、分区等元数据;
Execution Engine:执行生成的执行计划;
Hadoop Cluster:Hive本身不存储数据、不执行计算,完全依赖Hadoop集群提供的底层能力
Hive查询执行流程
你的HQL查询
↓
HiveServer2接收
↓
Driver协调流程
↓
Compiler编译优化
├── 语法解析
├── 语义分析 (咨询Metastore)
├── 逻辑计划
├── 逻辑优化
└── 物理计划 (MapReduce/Tez/Spark)
↓
执行引擎执行
├── Map阶段:扫描过滤
├── Shuffle:数据重分布
└── Reduce阶段:聚合计算
↓
结果返回给客户端
Hive查询示例
查询示例:
SELECT department, AVG(salary) as avg_salary
FROM employees
WHERE salary > 5000
GROUP BY department
HAVING avg_salary > 8000;①客户端提交查询;
# 你在Hive CLI中输入SQL
hive> SELECT department, AVG(salary) as avg_salary > FROM employees > WHERE salary > 5000 > GROUP BY department > HAVING avg_salary > 8000;②Hive Server2接收HQL语句,进行身份验证和权限检查,创建会话准备处理查询;
③Driver驱动整个查询流程;
④Complier编译SQL(最关键的步骤):
- 语法解析:检查语法是否正确,并生成“抽象语法树”;
# Compiler分析SQL结构
解析结果 = {"查询类型": "SELECT","目标表": "employees", "过滤条件": "salary > 5000","分组字段": "department","聚合函数": "AVG(salary)","分组过滤": "avg_salary > 8000"
}- 语义分析:与Metastore交互,验证表、字段是否存在,检查数据类型是否匹配,询问数据存储位置;
# 咨询Metastore目录系统
咨询问题 = ["employees表存在吗?","有department和salary字段吗?", "salary是什么数据类型?","数据存储在HDFS的哪个位置?"
]# Metastore返回信息
表信息 = {"表名": "employees","位置": "hdfs://cluster/user/hive/warehouse/employees","字段": ["id:int", "name:string", "salary:float", "department:string"],"文件格式": "ORC","分区信息": "按部门分区"
}- 逻辑计划:将HQL转化为“逻辑操作树”,描述查询的执行步骤;
# 生成逻辑执行计划
逻辑计划 = ["1. 扫描employees表的所有数据","2. 过滤出salary > 5000的记录", "3. 按department分组","4. 计算每个组的AVG(salary)","5. 过滤出avg_salary > 8000的组","6. 输出department和avg_salary"
]- 逻辑优化:对逻辑计划进行优化。谓词下推:尽早过滤数据,减少后续处理、列裁剪:只读取需要的列,减少I/O等;
# 优化器改进计划
优化后的逻辑计划 = ["1. 扫描employees表时直接过滤salary > 5000", # 谓词下推"2. 只读取department和salary列", # 列裁剪"3. 按department分组","4. 计算AVG(salary)", "5. 过滤avg_salary > 8000","6. 输出结果"
]- 物理计划:将逻辑计划转换成物理执行计划,即Hive可以执行的步骤。对于MR来说,就是生成MR作业。
# 转换成具体的物理操作
物理计划 = {"执行引擎": "MapReduce","Map任务": ["读取HDFS上的ORC文件","过滤salary > 5000", "输出键值对: <department, salary>"],"Shuffle阶段": ["按department分区","排序和传输到对应的Reduce节点"],"Reduce任务": ["接收相同department的所有salary","计算平均工资AVG(salary)","过滤avg_salary > 8000","输出最终结果"]
}⑤执行引擎执行:根据物理计划生成具体的计算任务脚本,通过YARN向Hadoop集群申请资源,调度任务在集群的多个节点并执行;
#Map阶段
# 多个Map任务并行处理不同数据块
def map_task(数据块):for 每一行 in 数据块:if 行.salary > 5000: # 过滤emit(行.department, 行.salary) # 输出键值对# 输出:<"技术部", 6000>, <"销售部", 7000>, <"技术部", 8000>...#Shuffle阶段
# 数据重新分布和排序
shuffle过程 = {"目的": "把相同department的数据送到同一个Reduce任务","操作": ["按department的哈希值分区","在不同节点间传输数据", "按department排序"]
}#Recuce阶段
def reduce_task(department, 所有salary列表):总工资 = sum(所有salary列表)平均工资 = 总工资 / len(所有salary列表)if 平均工资 > 8000:emit(department, 平均工资) # 输出最终结果# 输出:<"技术部", 8500>, <"管理层", 12000>...⑥结果返回。
# 执行结果
最终结果 = [("技术部", 8500.0),("管理层", 12000.0)
]# 通过Execution Engine → Driver → HiveServer2 → 客户端展示给你#在Hive CLI中显示
+------------+-----------+
| department | avg_salary|
+------------+-----------+
| 技术部 | 8500.0 |
| 管理层 | 12000.0 |
+------------+-----------+Hive与MySQL对比
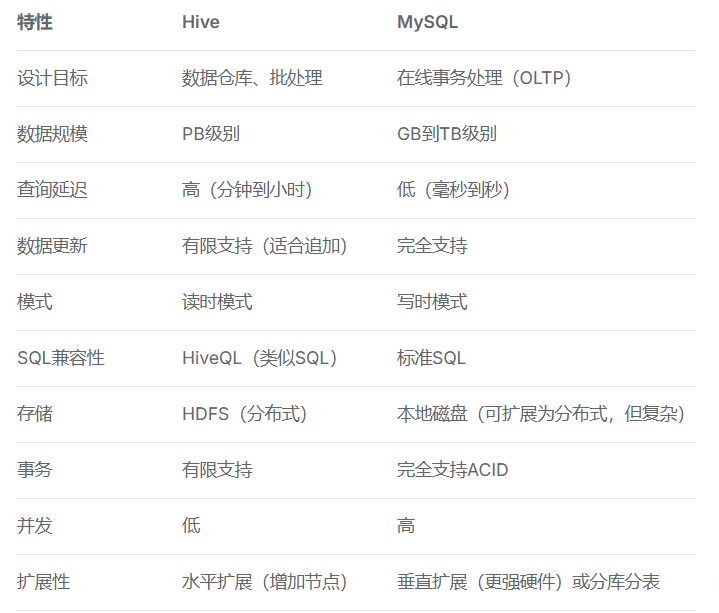
选择Hive:
- 数据量超过MySQL处理能力
- 主要是分析操作,不是事务操作
- 可以接受分钟级以上的延迟
- 需要处理半结构化数据
- 使用场景:数据仓库、离线分析
选择MySQL:
- 需要低延迟的实时查询
- 完整的事务支持
- 数据量在单机可处理范围
- 复杂的业务逻辑和约束
- 使用场景:业务系统、实时查询
两者配合使用:
MySQL (业务数据库)
↓ 数据同步
Hive (数据仓库)
↓ 分析处理
MySQL (报表数据库) ← BI工具