理想AI Talk第二季-重点信息总结
一、TL;DR
- 理想为什么要做自己的基模:座舱家庭等特殊VLM场景,deepseek/openai没有解决
- 理想的基模参数量:服务端-300B,VLencoder-32B/3.6B,日常工作使用-300B,VLA-4B
- 为什么自动驾驶可以达成:规则已知,类比机器人的自由度小,能够做的比人好
- VLA如何训练:基座模型pretrain、VLA后训练,强化学习训练,最后是agent
- 讲了很多公司的理念,我觉得挺好的,但是这部分就不在本文体现了
二、AI工具的三个分级
李想将AI分为3个阶段,分别是信息工具、辅助工具和生产工具,大多数人用来做信息工具使用,更进一步地,AI使用体验会变得更好,但此时他只是一个辅助工具,比如用来点外卖,但此时我们依旧在工作8小时,仍旧需要人的参与,最后如果变成生产工具,是否在产生有效的生产力,这也是用来衡量agent的做得好坏的标准

三、构建能力的3个过程
为了改变能力和提升能力:
- 这4个步骤是极简的人类最佳实践
- 理想在做VLA/李飞飞等在做研究都是这样

四、VLA为什么要做和怎么做
4.1 为什么要做
辅助驾驶需要把视觉和语料融合进去,openai/deepseek做好了Language,但是他们没有这些VL的数据,也没有这些场景和需求,因此也不会去解决这些问题,因此只能理想自己做
4.2 规模多大
理想同学用的是300B的模型,车端VLA是4B的模型,辅助驾驶的VL是32B/3.6B的模型。平产工作也是用的300B的模型
4.3 辅助驾驶的进化过程
第一阶段(rule):规则算法,整个模型规模只有几百万的参数量,因此加不同的规则,就像有轨电车
第二阶段((E2E+VLM):像人类的哺乳动物的智能运作的一种方式,动物园的猴子学习人类的各种行为去开车,但他对物理世界不理解,他对大部分的泛化性能是没问题的,但是特别复杂的场景搞不定
第三阶段(VLA):用3D视觉+2D视觉,有自己的Language和大脑去理解整个物理世界,具备自己的COT。真正的去执行这些理解

4.4 VLA如何训练

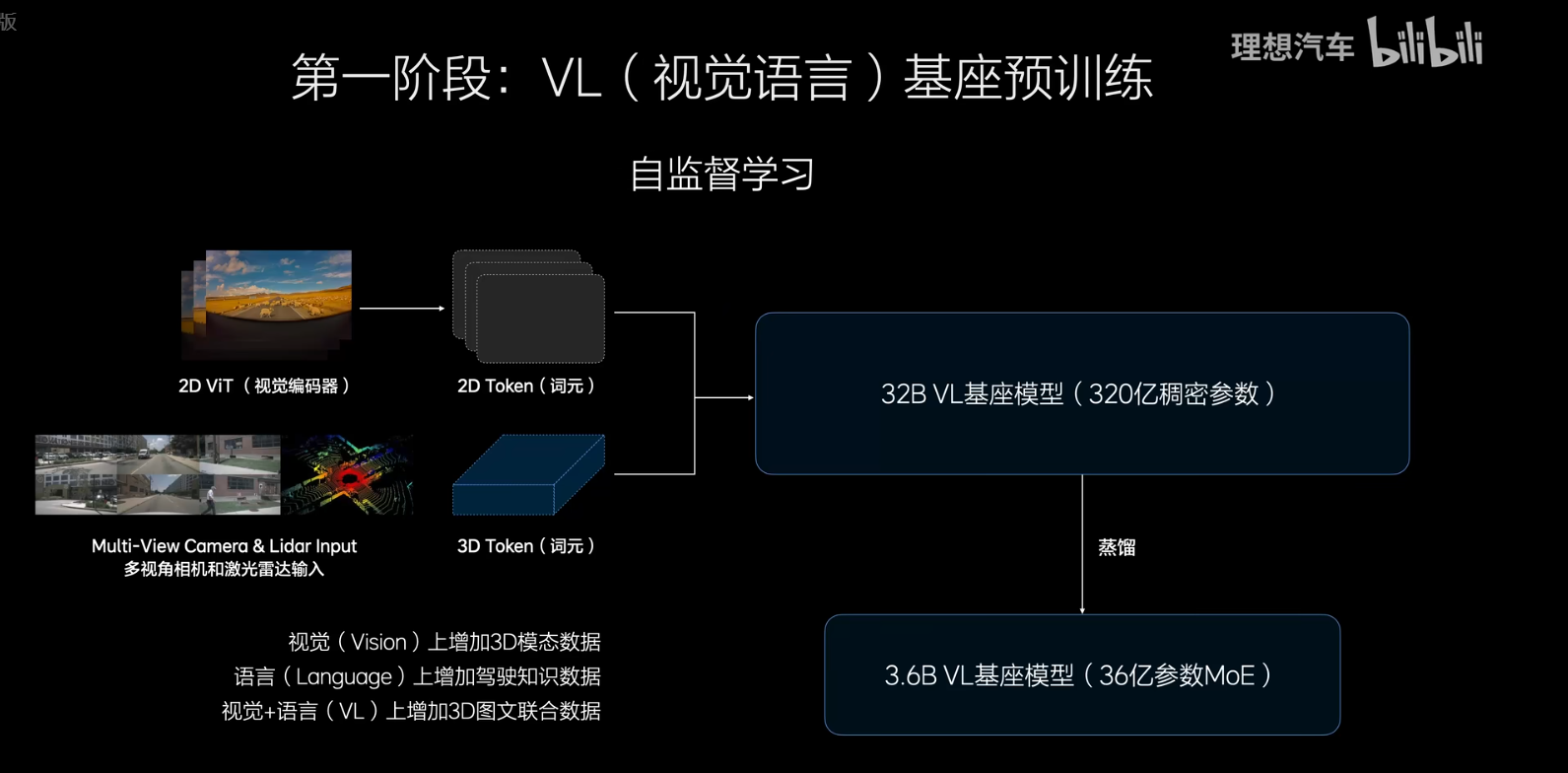
第一阶段:32B的基座VL 模型,与之前的差异是什么,需要放更多的视觉token,包括3Dtoken和更高清的2D token,放入驾驶的Language和视觉的联合语料,将对高精地图的理解也放进去,整体数据是vision的数据、Language的数据和VIsion/Language联合的数据,最后蒸馏下来的是3.6B的8个MOE车端模型
第二阶段是后训练,将其变为一个VLA模型,后训练仍然是一种强化学习,此时将模型规模扩展到4B左右,一方面是VLA,能够直接从inputt到输出,有着比较短的cot,另外做完action后,还会做一个4-8秒的diffusion轨迹和环境预测,特别像人去驾校学开车的过程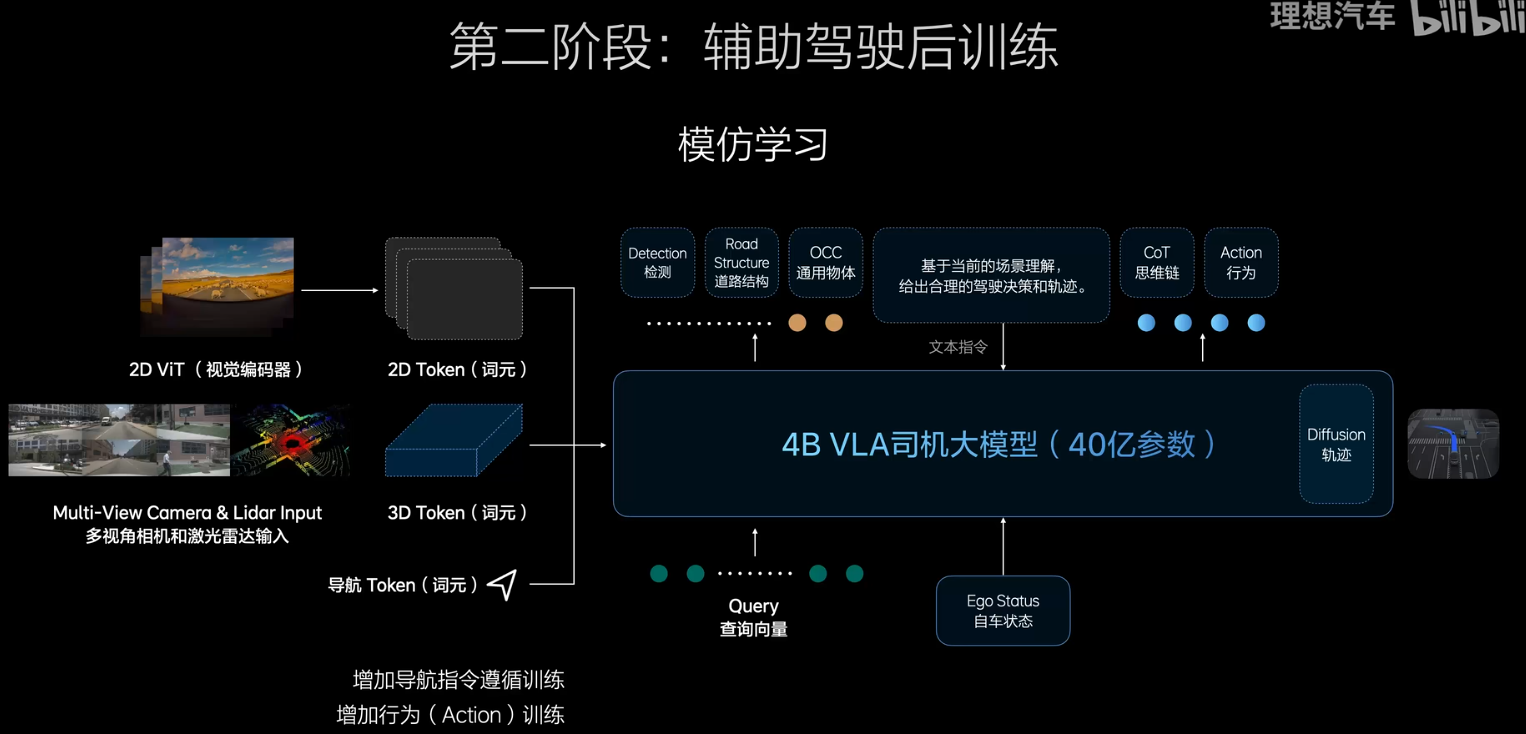
第三阶段:做强化训练,第一部分先做RLHF,带有人类反馈的强化学习,除了遵守交通规则以外,还需要增加大家的驾驶习惯,开的跟大家一样好,第二部分是纯粹的强化学习,拿着RL放在世界模型里面学习,目的就是比人开的更好,有3类的训练要求,G值判断舒适性的发聩、碰撞的反馈、交通事故的反馈,用这三个反馈来做强化学习
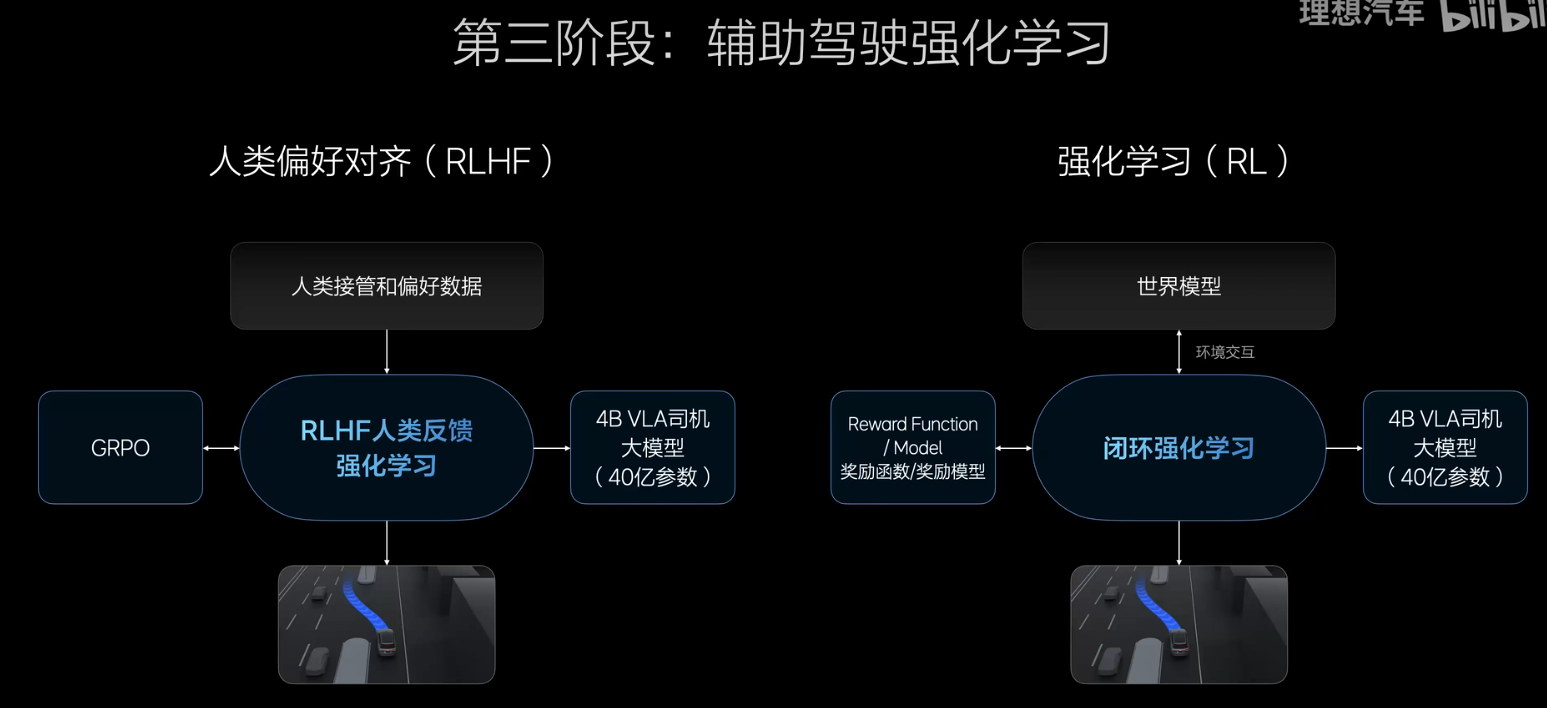
这三个要求完成以后,她就跟人类的驾驶习惯完全一样;像人类一样学习驾驶知识,这个是预训练,后训练相当于去驾校认真的学习开车,第三个环节相当于到社会上学开车和人类和社会环境做对齐。最后面, 人类通过自然语言的方式与VLA进行沟通,不再需要经过云端,如果是复杂的指令,则需要通过云端32B的模型先去 理解交通的一切,再交给VLA进行处理。他会像人类司机一样开车并且理解用户的问题,这个通过Agent来进行实现
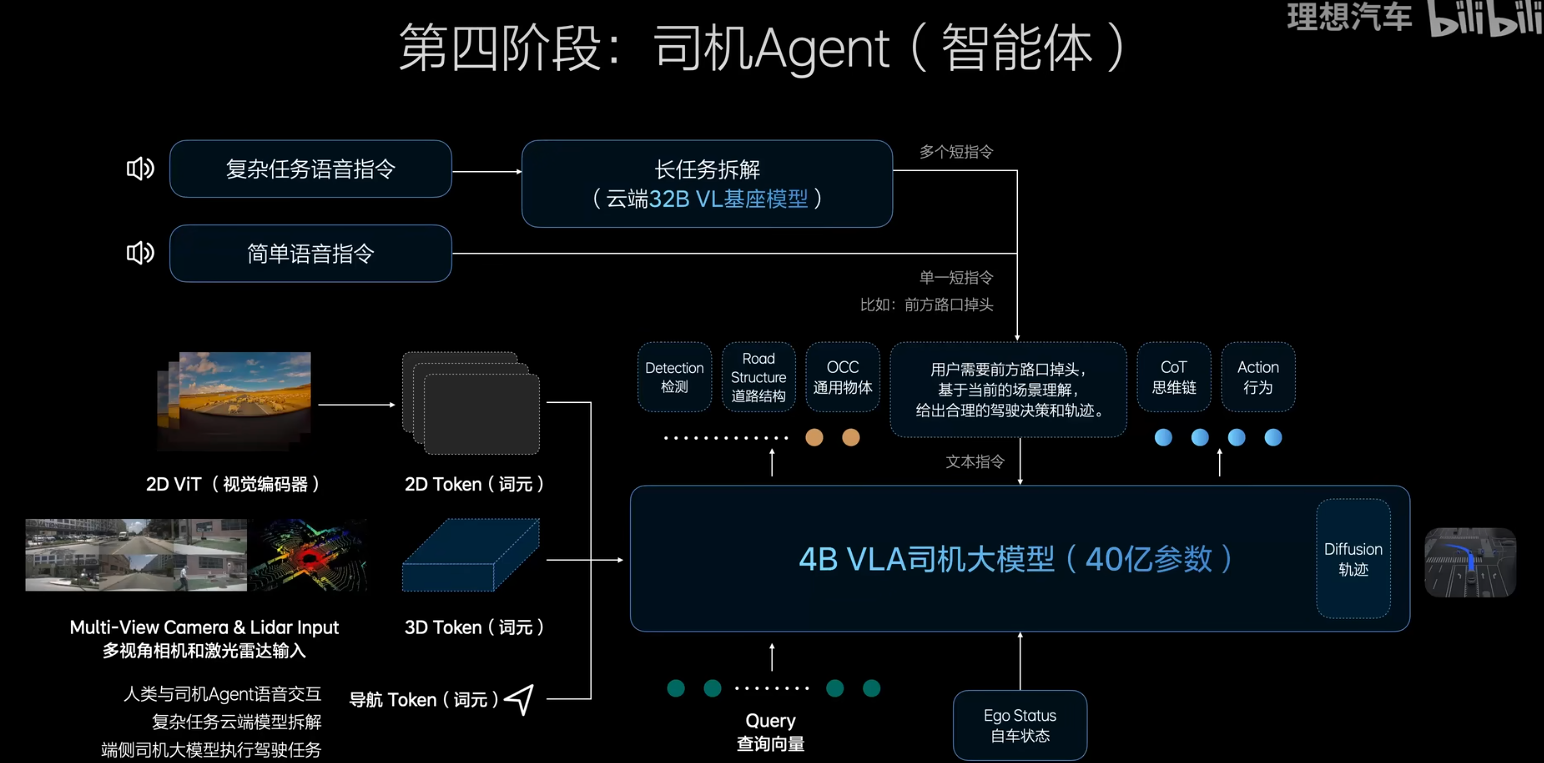
效果如下所示:
五、为什么辅助驾驶可以做成
5.1 做成的原因
第一、交通领域是最首先讲清楚规则的,虽然复杂但是具备确定性,一辆车上路后基本上路线是确定的
第二、是车的控制,其实只具备3个tof,左右、前后和轻微的旋转,机器人上来就40多个自由度,挑战更大
第三:我们进行模仿学习是比较方便的,还能做更好的强化学习,交通规则、是否碰撞、舒适性这些是能够被表达出来的,因此能够进行更好的强化学习
5.2 为什么是理想做成
什么难度大:数据获取难度最大,是vision和action,车上装门了传感器可以收集到世界数据,但是需要人来开车收集到action数据
为什么其他公司做不了:
其它车企没有建立预训练的基模能力、后训练和强化学习的能力,强化学习的体系建立如何和人类司机的方法对齐,这些能力的建设决定辅助驾驶能否做成、
5.3 如何保证辅助驾驶安全
对齐来解决与人类一致性的问题
模型能力越强,胡来的可能性就越大,一个公司也是这样的,公司做大以后,需要职业性来进行约束。只需要雇佣职业司机而非赛车手了
端到端的仿真和快速闭环问题的能力
模型是一个黑盒子,做了整个物理世界的仿真,2万公里的费用是17-20万左右,现在是4k,基本上都是fpu的渲染,解决问题的效率提升很多,相同的问题复现几乎没有可能,但是仿真世界再世界模型里面是可以做到的。3天可以解决一个cornercase
超级对其团队。来保证安全的驾驶,建了 100 多人的团队,就像给 AI 司机上 “职业素养课”,教它遵守交通规则,养成好的驾驶习惯 。
