【DeepSeek论文精读】11. 洞察 DeepSeek-V3:扩展挑战和对 AI 架构硬件的思考
欢迎关注[【AIGC论文精读】](https://blog.csdn.net/youcans/category_12321605.html)原创作品
【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1
【DeepSeek论文精读】7. DeepSeek 的发展历程与关键技术
【DeepSeek论文精读】11. 洞察 DeepSeek-V3:扩展挑战和对 AI 架构硬件的思考
【DeepSeek论文精读】11. 洞察 DeepSeek-V3:扩展挑战和对 AI 架构硬件的思考
- 0. 论文简介与摘要
- 0.1 论文简介
- 0.2 论文概览
- 0.3 摘要
- 1. 引言
- 1.1 背景
- 1.2 目标
- 1.3 本文结构
- 2. DeepSeek模型的设计原则
- 2.1 内存效率
- 2.1.1 低精度模型
- 2.1.2 MLA压缩KV缓存
- 2.1.3 资源高效技术的未来方向
- 2.2 MoE模型的成本效益
- 2.2.1 降低训练的计算需求
- 2.2.2 本地部署优势
- 2.3 推理加速
- 2.3.1 通信与计算重叠
- 2.3.2 推理速度极限
- 2.3.3 多令牌预测
- 2.3.4 推理模型的测试时扩展
- 2.4 技术验证方法
- 3 低精度驱动设计
- 3.1 FP8混合精度训练
- 3.1.1 局限性
- 3.1.2 建议
- 3.2 LogFMT:通信压缩
- 3.2.1 局限性
- 3.2.2 建议
- 4. 互连驱动设计
- 4.1 当前硬件架构
- 4.2 硬件感知并行策略
- 4.3 模型协同设计:节点受限路由
- 4.4 纵向与横向扩展融合
- 4.4.1 现有实现局限
- 4.4.2 改进建议
- 4.5 带宽争用与延迟
- 4.5.1 现存问题
- 4.5.2 优化方向
- 5. 大规模网络驱动设计
- 5.1 网络协同设计:多平面胖树
- 5.1.1 多平面胖树网络优势
- 5.1.2 性能分析
- 5.2 低延迟网络
- 5.2.1 IB与RoCE对比
- 5.2.2 RoCE改进建议
- 5.2.3 InfiniBand GPUDirect异步(IBGDA)
- 6. 未来硬件架构设计的讨论和洞见
- 6.1 鲁棒性挑战
- 6.1.1 现存问题
- 6.1.2 高级错误检测和更正建议
- 6.2 CPU瓶颈与互连
- 6.3 智能网络演进方向
- 6.4 内存语义通信与顺序问题
- 6.5 网内计算与压缩
- 6.6 内存中心创新
- 6.6.1 内存带宽局限
- 6.6.2 发展方向
- 7. 结论
- 参考文献
0. 论文简介与摘要
0.1 论文简介
2025年 5月,DeepSeek AI 公开了将于 ISCA’25 发表的论文 Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures(洞察 DeepSeek-V3:扩展挑战和对 AI 架构硬件的思考)。梁文锋也是本文的署名作者。
本文深入分析了DeepSeek-V3/R1模型架构及其AI基础设施,重点阐述了多项关键创新:提升内存效率的多头潜在注意力(MLA)、优化计算-通信权衡的混合专家(MoE)架构、释放硬件全部潜力的FP8混合精度训练,以及最小化集群级网络开销的多平面网络拓扑。
论文标题:Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
发布时间:2025年5月 [2405.09343]
论文地址:arxiv-DeepSeek-V3
发表于:Proceedings of the 52nd Annual International Symposium on Computer Architecture; June 21–25, 2025; Tokyo, Japan
引用格式:Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Huazuo Gao, Jiashi Li, Liyue Zhang, Panpan Huang, Shangyan Zhou, Shirong Ma, Wenfeng Liang, Ying He, Yuqing Wang, Yuxuan Liu, Y.X. Wei . 2025. Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA https://doi.org/10.1145/3695053.3731412

0.2 论文概览
研究背景:
论文指出当前大模型(如OpenAI o1/o3、DeepSeek-R1、Claude-3.7等)的发展凸显了提升推理效率的必要性,尤其是在长上下文处理与深度推理场景下,这对计算资源提出了更高需求。
核心内容:
- 模型设计原则:
- 内存效率优化:通过改进注意力机制等设计降低内存占用。
- 低精度训练:提出FP8混合精度训练方案,并针对现有硬件局限性给出改进建议(如减少特定操作的计算复杂度)。
- 硬件协同设计:
- 互联驱动设计:强调通过 Scale-Up 与 Scale-Out 网络融合优化带宽利用率,减少EP all-to-all通信的操作开销。
关键技术与创新:
- 采用混合专家(MoE)架构和多平面网络(Multi-Plane Network),结合FP8混合精度训练提升计算效率。
- 提出硬件与算法的协同设计思路,以应对大模型推理中的算力瓶颈。
0.3 摘要
大型语言模型(LLM)的快速扩展揭示了当前硬件架构的关键局限性,包括内存容量、计算效率和互连带宽的约束。
基于2,048块NVIDIA H800 GPU训练的DeepSeek-V3证明了硬件感知的模型协同设计如何有效应对这些挑战,从而实现高性价比的大规模训练与推理。
本文深入分析了DeepSeek-V3/R1模型架构及其AI基础设施,重点阐述了多项关键创新:提升内存效率的多头潜在注意力(MLA)、优化计算-通信权衡的混合专家(MoE)架构、释放硬件全部潜力的FP8混合精度训练,以及最小化集群级网络开销的多平面网络拓扑。
基于DeepSeek-V3开发过程中遇到的硬件瓶颈,我们与学界和业界同行展开更广泛的讨论,探讨未来硬件的潜在发展方向,包括精确低精度计算单元、纵向扩展与横向扩展的融合,以及低延迟通信架构的创新。这些见解强调了硬件与模型协同设计在满足AI工作负载日益增长需求中的关键作用,为下一代AI系统创新提供了实用蓝图。
关键词:大语言模型,混合专家,深度学习,FP8混合精度训练,多平面网络,协同设计
1. 引言
1.1 背景
近年来,大型语言模型(LLM)在模型设计、计算能力和数据可用性的迭代进步推动下快速发展。2024年,GPT4o(OpenAI, 2024a)、LLaMa-3(AI@Meta, 2024a)、Claude 3.5 Sonnet(Anthropic, 2024)、Grok-2(xAI, 2024a)、Qwen2.5(Yang et al., 2024)、Gemini-2(Google, 2024)以及我们的DeepSeek-V3(DeepSeek-AI, 2024d)等突破性模型展现了显著进展,进一步缩小了与通用人工智能(AGI)的差距。正如《缩放法则》(Kaplan et al., 2020)所示,增加模型规模、训练数据和计算资源可显著提升模型性能,凸显了规模扩展在推动AI能力中的关键作用。总体而言,这些进展开启了一个新时代,其中扩大模型规模与计算能力被视为解锁更高智能水平的关键。
近期,OpenAI的o1/o3系列模型(OpenAI, 2024b, 2025)、DeepSeek-R1(DeepSeek-AI, 2025a)、Claude-3.7 Sonnet(Anthropic, 2025)、Gemini 2.5 Pro(Google, 2025)、Seed1.5-Thinking(Seed, 2025)和Qwen3(Team, 2025)等推理模型不仅展示了大尺度架构的优势,还凸显了提升推理效率的必要性,尤其是在处理更长上下文和实现更深层次推理方面。这些进步对计算资源提出了日益增长的需求,要求推理更快、更高效。
为应对这些挑战,阿里巴巴、字节跳动、谷歌、xAI和Meta等行业领导者部署了庞大的训练集群(Jouppi et al., 2023; Mudigere et al., 2023; Gangidi et al., 2024; Jiang et al., 2024; Qian et al., 2024; xAI, 2024b),配备数万甚至数十万GPU或TPU。尽管此类超大规模基础设施支持了尖端模型的开发,但其高昂成本对小型研究团队和组织构成了显著壁垒。尽管如此,DeepSeek(DeepSeek-AI, 2024b, c, d, a, 2025a)和Mistral(Jiang et al., 2023; Mistral, 2024)等开源初创公司仍致力于开发前沿模型。其中,DeepSeek尤其证明了软硬件协同设计能够实现大模型的高性价比训练,为小型团队创造了公平竞争环境。
基于这一传统,DeepSeek-V3(DeepSeek-AI, 2024d)代表了高性价比训练的新里程碑。仅使用2,048块NVIDIA H800 GPU,DeepSeek-V3便实现了顶尖性能。这一成就与通过实用、可扩展方案推动AI发展的承诺一致,此前Fire-Flyer AI-HPC(An et al., 2024)的高性价比架构已印证这一点。DeepSeek-V3的实践与洞见展示了如何最大限度利用现有硬件资源,为更广泛的AI和HPC社区提供了宝贵经验。
1.2 目标
本文并非重申DeepSeek-V3的详细架构与算法细节(其技术报告已全面记录,见DeepSeek-AI, 2024d),而是从硬件架构与模型设计的双重视角出发,探讨二者如何协同实现高性价比的大规模训练与推理。通过分析这种协同效应,我们旨在为高效扩展LLM提供可行见解,同时不牺牲性能或可及性。
具体而言,本文聚焦于:
- 硬件驱动的模型设计:
分析FP8低精度计算、纵向/横向扩展网络特性等硬件特性如何影响DeepSeek-V3的架构选择。 - 硬件与模型的相互依赖:
研究硬件能力如何塑造模型创新,以及LLM不断演进的需求如何推动下一代硬件的需求。 - 硬件发展的未来方向:
从DeepSeek-V3中提炼可行洞见,指导未来硬件与模型架构的协同设计,为可扩展、高性价比的AI系统铺路。
1.3 本文结构
本文余下部分安排如下:
- 第2章 探讨DeepSeek-V3模型架构的设计原则,重点介绍多头潜在注意力(MLA)、混合专家(MoE)优化和多令牌预测模块等关键创新;
- 第3章 阐述模型架构如何实现低精度计算与通信;
- 第4章 涵盖纵向扩展互连优化,讨论纵向/横向扩展的融合,并分析硬件特性如何影响并行性与专家选择策略;
- 第5章 聚焦横向扩展网络优化,包括多平面网络协同设计与低延迟互连。除第3~5章提及的当前局限与未来建议外,
- 第6章 进一步提炼DeepSeek-V3的关键洞见,并指明未来硬件与模型协同设计的方向。
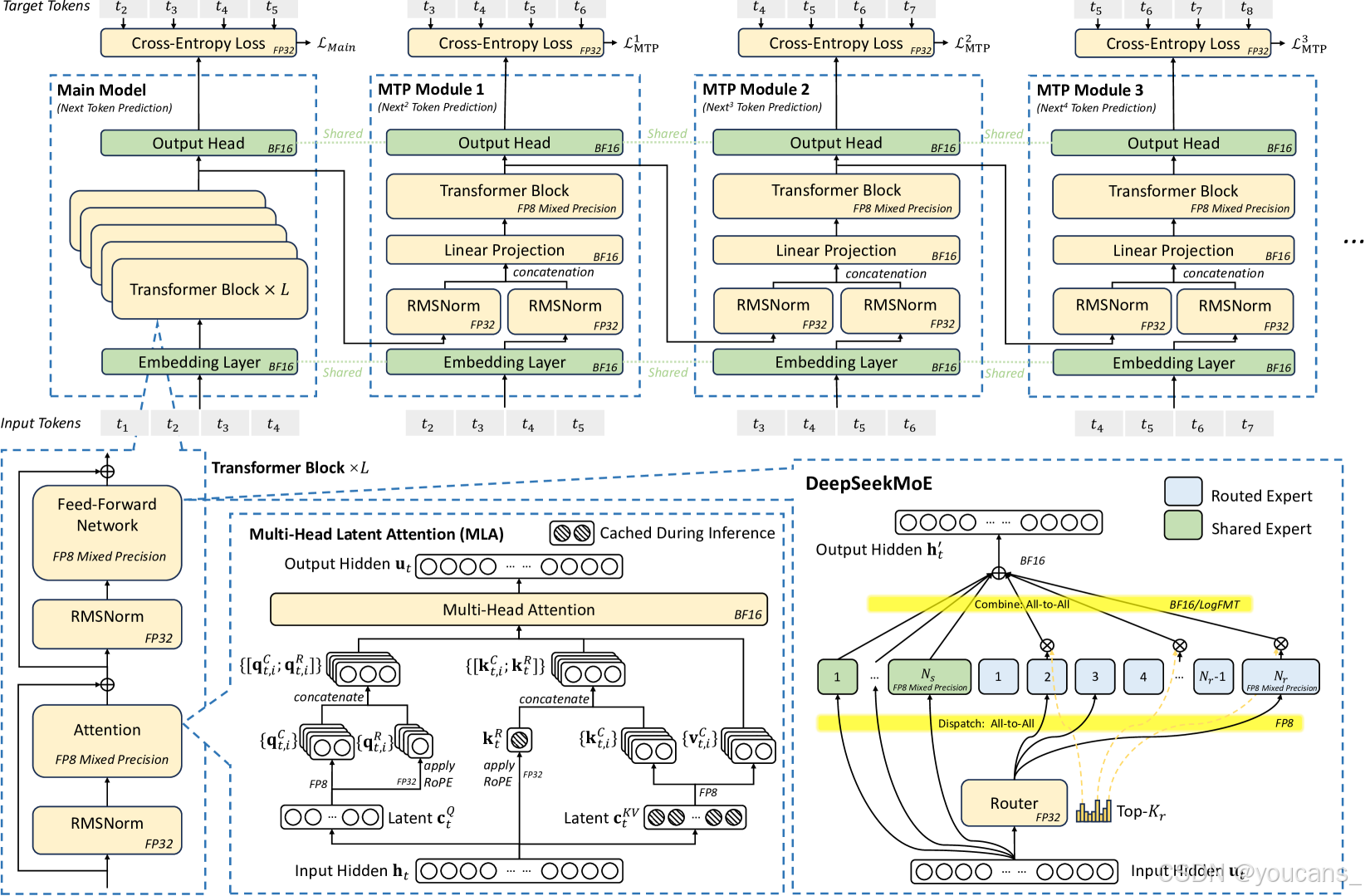
图 1:DeepSeek-V3 的基本架构。
基于 DeepSeek-V2 的 MLA 和 DeepSeekMoE 构建,引入了多标记预测模块和 FP8 混合精度训练,以提高推理和训练效率。该图显示了架构不同部分用于计算的精度。所有组件都采用 BF16 的输入和输出。
2. DeepSeek模型的设计原则
DeepSeek-V3的开发体现了硬件感知的大语言模型扩展方法,每个设计决策都与硬件约束精准对齐,以优化性能和成本效益。
如图1所示,DeepSeek-V3采用了已在DeepSeek-V2[25]中验证有效的DeepSeekMoE[27]和多头潜在注意力(MLA)[25]架构。
- DeepSeekMoE释放了混合专家架构的潜力,而MLA通过压缩键值(KV)缓存大幅降低内存消耗。
- DeepSeek-V3引入FP8混合精度训练,在保持模型质量的同时显著降低计算成本。
- 为提升推理速度,模型基于多令牌预测模块实现推测式解码,使生成速度显著提升。
- 在基础设施层面,我们采用多平面双层胖树网络替代传统三层拓扑,降低集群组网成本。
这些创新共同应对大模型扩展的三大核心挑战——内存效率、成本效益和推理速度,下文将详细阐述。
2.1 内存效率
大语言模型通常需要大量内存资源,其需求年增长率超1000%,而HBM等高速内存容量年增速不足50%[35]。虽然多节点并行是解决内存限制的可行方案,但从源头优化内存使用仍是关键策略。
2.1.1 低精度模型
相比BF16权重模型,FP8将内存消耗减半,有效缓解AI内存墙问题。第3章将详细讨论低精度驱动设计。
2.1.2 MLA压缩KV缓存
多轮对话场景中,历史上下文的KV缓存会持续增长。传统方法需为每个注意力头存储独立的KV对,导致内存占用随序列长度线性增加。我们采用多头潜在注意力(MLA)[25],通过投影矩阵将所有注意力头的KV表示压缩为联合训练的潜在向量。推理时仅需缓存潜在向量,较传统方法显著节省内存。

其他KV压缩方法包括:
- 共享KV(GQA/MQA):多个头共享一组 KV 对,而不是为每个注意力头维护单独的 KV 对,从而显着压缩了 KV 存储。代表性方法包括 GQA [5] 和 MQA [70]。
- 滑动窗口KV:对于长序列,缓存中仅保留 KV 对的滑动窗口,丢弃窗口外的结果。虽然这减少了存储,但它损害了长上下文推理。代表性方法包括 Longformer [11] 和相关架构。
- 量化压缩:KV 对使用低位表示 [40, 44, 52] 进行存储,进一步减少内存使用。量化可实现显著的压缩,同时对模型性能的影响最小。
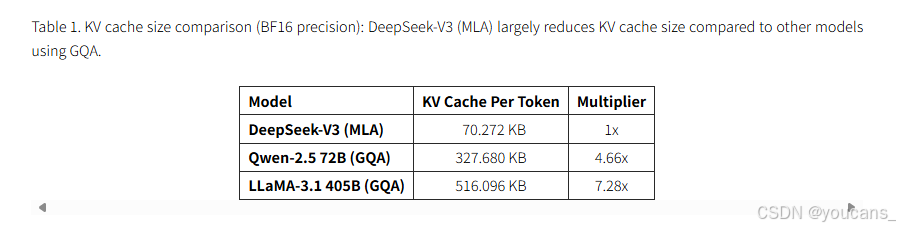
如表1所示,DeepSeek-V3每令牌仅需70KB KV缓存,远低于LLaMA-3.1 405B(516KB)和Qwen-2.5 72B(327KB)。
表 1 比较了 DeepSeek-V3 、 Qwen-2.5 72B [75] 和 LLaMA-3.1 405B [4] 之间每个令牌的 KV 缓存内存使用情况。通过采用 MLA,DeepSeek-V3 显著减少了 KV 缓存大小,每个令牌只需要 70 KB,大大小于 LLaMA-3.1 405B 的 516 KB 和 Qwen-2.5 72B 的 327 KB。与基于 GQA 的方法相比,这种减少突出了 MLA 在压缩 KV 表示方面的效率。实现如此显著的内存消耗降低的能力使 DeepSeekV3 特别适合涉及长上下文处理和资源受限环境的场景,从而实现更具可扩展性和成本效益的推理。
2.1.3 资源高效技术的未来方向
虽然减小 KV 缓存的大小是提高内存效率的一种很有前途的方法,但基于 Transformer 的自回归解码固有的二次复杂度仍然是一个艰巨的挑战,尤其是对于极长的上下文。最近的研究工作,如 Mamba-2 [21] 和 Lightning Attention[63],研究了为平衡计算成本和模型性能提供新可能性的线性时间替代方案。此外,诸如稀疏注意力[76]等方法,试图压缩和稀疏激活注意力键和值,代表了克服与注意力相关的计算挑战的另一种尝试。我们期待与更广泛的社区合作,在这一领域取得突破。
2.2 MoE模型的成本效益
对于稀疏计算,我们开发了 DeepSeekMoE,这是一种高级专家混合 (MoE) 架构,如图 1 的右下角所示。MoE 模型的优势在于两个方面。
2.2.1 降低训练的计算需求
MoE 架构的主要优势在于它能够显著降低训练成本。
通过选择性地仅激活专家参数的子集,MoE 模型允许总参数数量急剧增加,同时保持计算要求适中。例如,DeepSeek-V2 具有 236B 参数,但每个令牌只激活了 21B 参数。同样,DeepSeek-V3 扩展到 671B 参数(几乎是 V2 的三倍),同时将每个令牌的激活率保持在仅 37B。相比之下,Qwen2.5-72B 和 LLaMa3.1-405B 等密集模型要求所有参数在训练期间都处于活动状态。
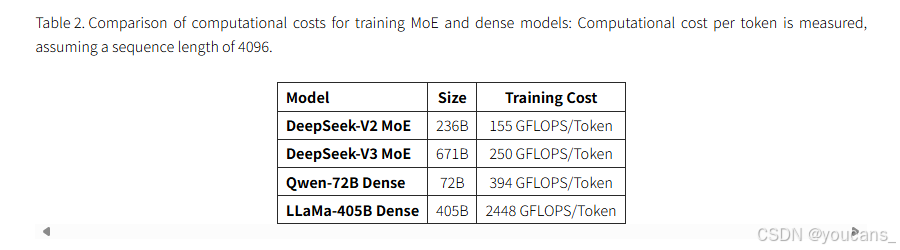
如表 2 所示,DeepSeekV3 的总计算成本约为每个令牌 250 GFLOPS,而 72B 密集模型需要 394 GFLOPS,405B 密集模型需要 2448 GFLOPS。这表明 MoE 模型实现了与密集模型相当甚至更好的性能,同时消耗的计算资源减少了一个数量级。
2.2.2 本地部署优势
个人使用和本地部署的优势。
在未来,个性化 LLM 代理 [53] 变得无处不在,MoE 模型在单一请求场景中提供了独特的优势。由于每个请求仅激活一个参数子集,因此内存和计算需求大大减少。例如,DeepSeek-V2(236B 参数)在推理过程中仅激活 21B 参数。这使得配备 AI SoC 芯片 [6, 10, 58] 的 PC 能够实现每秒近 20 个令牌 (TPS),甚至是该速度的两倍,这对于个人使用来说绰绰有余。相比之下,具有相似功能(例如 70B 参数)的密集模型在类似硬件上通常只能达到个位数的 TPS。
值得注意的是,越来越流行的 KTransformers [39] 推理引擎允许完整的 DeepSeek-V3 模型在配备消费类 GPU 的低成本服务器上运行(成本约为 10,000 美元),同时仍能实现近 20 TPS。这种效率使 MoE 架构适用于硬件资源通常有限的本地部署和单用户场景。通过最大限度地减少内存和计算开销,MoE 模型可以提供高质量的推理性能,而无需昂贵的基础设施。
2.3 推理加速
2.3.1 通信与计算重叠
通过双微批次流水线设计[31,78],我们将MLA与MoE计算解耦为两个阶段,使all-to-all通信与计算完全重叠。生产环境中还采用预填充/解码分离架构[80],根据任务特性分配专家并行组规模以最大化系统吞吐。
推理速度包括系统范围的最大吞吐量和单次请求延迟。为了最大限度地提高吞吐量,我们的模型从一开始就被构建为利用双微批处理重叠 [31, 78],有意将通信延迟与计算重叠。正如我们的在线推理系统所展示的,并得到开源分析数据 [31] 的支持,我们将 MLA 和 MoE 的计算解耦为两个不同的阶段。当一个微批处理执行一部分 MLA 或 MoE 计算时,另一个微批处理同时执行相应的调度通信。相反,在第二个微批处理的计算阶段,第一个微批处理将执行组合通信步骤。这种流水线方法实现了全对全通信与正在进行的计算的无缝重叠,确保 GPU 始终保持充分利用。此外,在生产中,我们采用预填充和解码解聚架构 [80],将大批量预填充和延迟敏感的解码请求分配给不同的专家并行组大小。此策略最终可在实际服务条件下最大限度地提高系统吞吐量。
2.3.2 推理速度极限
在配备400Gbps InfiniBand的系统中,DeepSeek-V3的理论TPOT上限为14.76ms(67TPS)。若采用GB200 NVL72(900GB/s单向带宽),理论极限可提升至0.82ms(1200TPS),凸显高带宽互连的革命性潜力。
本节重点介绍 LLM 服务的解码输出速度,通常以每个输出令牌的时间 (TPOT) 来衡量。TPOT 是用户体验的关键指标,它也直接影响 OpenAI 的 o1/o3 和 DeepSeek-R1 等推理模型的响应能力,这些模型依靠推理长度来增强其智能。对于 MoE 模型,实现高推理速度依赖于跨计算设备高效部署专家参数。为了实现尽可能快的推理速度,理想情况下,每个设备都应该为单个 EA 执行计算(或者如有必要,多个设备应协同计算单个 EA)。但是,Expert Parallelism (EP) 需要将令牌路由到适当的设备,这涉及跨网络的多对多通信。因此,MoE 推理速度的上限由互连带宽决定。考虑这样一个系统:每个设备都保存一个 EA 的参数,一次处理大约 32 个令牌。此令牌计数在计算内存比率和通信延迟之间取得平衡。此令牌计数可确保每个设备在专家并行期间处理相等的批量大小,从而可以轻松计算通信时间。对于与 CX7 400Gbps InfiniBand (IB) NIC 互连的系统,EP 中两次全对全通信所需的时间计算如下:
C o m m . T i m e = ( 1 B y t e + 2 B y t e s ) × 32 × 9 × 7 K / 50 G B / s = 120.96 μ s Comm. Time = (1Byte + 2Bytes) × 32 × 9 × 7K/50GB/s = 120.96μs Comm.Time=(1Byte+2Bytes)×32×9×7K/50GB/s=120.96μs
这里,dispatch 使用 FP8(1 字节),而 combine 使用 BF16(2 字节),每个令牌的隐藏大小约为 7K。因子 9 表示每个令牌都转移到 8 个路由专家和 1 个共享专家。如 Section 2.3.1 中所述,最大化吞吐量需要使用双微批处理重叠。在这种策略中,我们的理论最佳情况分析假设计算开销最小,因此性能上限由通信延迟决定。但是,在实际推理工作负载中,请求上下文通常要长得多,并且 MLA 计算通常主导执行时间。因此,该分析代表了双微批次重叠下的理想化情景。在此假设下,每层的总时间可以表示为:
T o t a l T i m e P e r L a y e r = 2 × 120.96 μ s = 241.92 μ s Total Time Per Layer = 2 × 120.96μs = 241.92μs TotalTimePerLayer=2×120.96μs=241.92μs
在 DeepSeek-V3 中有 61 层,总推理时间为:
T o t a l I n f e r e n c e T i m e = 61 × 241.92 μ s = 14.76 m s Total Inference Time = 61 × 241.92μs = 14.76ms TotalInferenceTime=61×241.92μs=14.76ms
因此,该系统的理论上限约为 14.76 毫秒 TPOT,相当于每秒 67 个令牌。但是,在实践中,通信开销、延迟、带宽利用率不完整和计算效率低下等因素会减少这个数字。
相比之下,如果使用 GB200 NVL72 等高带宽互连(72 个 GPU 上的 900GB/s 单向带宽),则每个 EP 步骤的通信时间将下降到:
C o m m . T i m e = ( 1 B y t e + 2 B y t e s ) × 32 × 9 × 7 K / 900 G B / s = 6.72 μ s Comm. Time = (1Byte + 2Bytes) × 32 × 9 × 7K/900GB/s = 6.72μs Comm.Time=(1Byte+2Bytes)×32×9×7K/900GB/s=6.72μs
假设计算时间等于通信时间,这会显著减少总推理时间,从而实现超过 0.82 毫秒 TPOT 的理论上限,大约每秒 1200 个令牌。虽然这个数字是纯粹的理论,尚未得到实证验证,但它生动地说明了高带宽纵向扩展网络在加速大规模模型推理方面的变革潜力。
虽然 MoE 模型表现出良好的可扩展性,但仅通过增加硬件资源来实现高推理速度的成本高昂。因此,软件和算法也必须有助于提高推理效率。
2.3.3 多令牌预测
如图1顶部所示,MTP模块通过轻量级层预测后续令牌,实现80%-90%的第二令牌接受率,使生成速度提升1.8倍。该方法还通过增大推理批次提升硬件利用率。
受 Gloeckle 等人 [36] 的启发,DeepSeek-V3 引入了多标记预测 (MTP) 框架,该框架可同时增强模型性能并提高推理速度。在推理过程中,传统的自回归模型在解码步骤中生成一个标记,从而导致顺序瓶颈。MTP 使模型能够以较低的成本生成额外的候选令牌并并行验证它们,从而缓解了这个问题,类似于以前基于自起草的推测解码方法 [14, 48]。该框架在不影响准确性的情况下显著加快了推理速度。
如图 1 的顶部所示,每个 MTP 模块都使用一个比完整模型轻量级得多的单层来预测额外的令牌,从而支持多个候选令牌的并行验证。虽然这种方法对吞吐量略有影响,但显著改善了端到端的生成延迟。实际实践数据表明,MTP 模块预测第二个后续令牌的接受率为 80% 到 90%,与没有 MTP 模块的场景相比,生成的 TPS 提高了 1.8 倍。
此外,通过预测每步多个令牌,MTP 增加了推理批量大小,这对于提高 EP 计算强度和硬件利用率至关重要。这种算法创新对于 DeepSeek-V3 中快速且经济高效的推理至关重要。
2.3.4 推理模型的测试时扩展
OpenAI o1/o3系列[60,61]和DeepSeek-R1[28]等推理模型通过动态调整计算资源,在数学推理等任务中取得突破。强化学习工作流(如PPO[67])对高吞吐的需求,使得推理加速成为关键研究方向。
以 OpenAI 的 o1/o3 系列 [60, 61] 为例,LLM 中的测试时间缩放通过在推理过程中动态调整计算资源,实现了数学推理、编程和一般推理的重大进步。随后的模型——包括 DeepSeek-R1 [28]、Claude-3.7 Sonnet [9]、Gemini 2.5 Pro [38]、Seed1.5-Thinking [68] 和 Qwen3 [71]——都采用了类似的策略,并在这些任务中取得了显著的改进。
对于这些推理模型,高 token 输出速度至关重要。在强化学习 (RL) 工作流程中,例如 PPO [67]、DPO [64] 和 GRPO [69],快速生成大量样本的必要性使推理吞吐量成为一个关键的瓶颈。同样,较长的推理序列会增加用户的等待时间,从而降低此类模型的实际可用性。因此,通过协同硬件和软件创新来优化推理速度对于提高推理模型的效率是必不可少的。然而,加速推理和加速 RL 训练的有效策略仍然是活跃的研究领域,如第 2.1.3 节所述。我们鼓励更广泛的社区合作探索和开发新颖的解决方案,以应对这些持续的挑战。
2.4 技术验证方法
每种加速技术都经过严格的实证验证,以评估其精度影响,包括 MLA、FP8 混合精度计算和网络共同设计的 MoE 门路由。
鉴于在全尺寸模型上穷举消融的成本高昂,我们采用了分层且资源高效的验证管道。每种技术首先在小规模模型上进行广泛验证,然后进行最少的大规模调整,最后集成到一个全面的训练运行中。
例如,在最终集成之前,我们首先对 16B 和 230B DeepSeek-V2 模型进行了细粒度的 FP8 训练消融研究。在这些受控设置下,与 BF16 相比,相对精度损失保持在 0.25% 以下,这归因于我们使用了高精度累积和细粒度量化策略。
3 低精度驱动设计
3.1 FP8混合精度训练
GPTQ[32]和AWQ[51]等量化技术已广泛用于将位宽降至8位、4位甚至更低,显著减少内存需求。但这些技术主要应用于推理阶段以节省内存,而非训练阶段。NVIDIA Transformer Engine虽早已支持FP8混合精度训练,但在DeepSeek-V3之前尚未有开源大模型采用FP8训练。通过基础设施与算法团队的深度协作及大量实验创新,我们开发了支持MoE模型的FP8训练框架。图1展示了训练流程中采用FP8精度前向与反向过程的计算组件。我们应用细粒度量化策略:对激活值采用1x128分块量化,对模型权重采用128x128分块量化。FP8框架的更多技术细节记录于DeepSeek-V3技术报告[26],细粒度FP8 GEMM实现已通过DeepGEMM[77]开源。
3.1.1 局限性
尽管FP8具有加速训练的潜力,仍需解决以下硬件限制以充分发挥其效能:
-
FP8累加精度:
Tensor Core中FP8采用受限累加精度,影响大模型训练稳定性(尤其在NVIDIA Hopper GPU上)。基于最大指数右移对齐32个尾数乘积后,Tensor Core仅保留最高13位小数位进行加法运算,超范围位直接截断。加法结果累积至FP22寄存器(1符号位+8指数位+13尾数位)。 -
细粒度量化挑战:
分块量化导致部分结果从Tensor Core传输至CUDA Core进行缩放因子乘法的反量化开销过大。频繁数据移动会降低计算效率并增加硬件利用复杂度。
3.1.2 建议
针对现有硬件局限,我们对未来设计提出以下建议:
-
提升累加精度:
硬件应提高累加寄存器精度至合适值(如FP32),或支持可配置累加精度,以适应不同模型训练/推理的精度-性能权衡需求。 -
原生细粒度量化支持:
硬件应原生支持细粒度量化,使Tensor Core可直接接收缩放因子并执行分组缩放矩阵乘。如此整个部分和累加与反量化可在Tensor Core内部完成,避免频繁数据移动。NVIDIA Blackwell对微缩放数据格式[66]的支持即为该方向的工业级实践范例。
3.2 LogFMT:通信压缩
当前DeepSeek-V3架构中,我们对网络通信采用低精度压缩。在专家并行(EP)阶段,令牌分发使用细粒度FP8量化,通信量较BF16减少50%。虽然组合阶段因精度要求仍采用BF16,但我们正积极测试FP8、自定义格式(如E5M6)及FP8-BF16混合方案。
除传统浮点格式外,我们还尝试了对数浮点格式 $(LogFMT-nBit)¥,其中n为总位数(首位为符号位S)。通过将激活值从线性空间映射至对数空间,其分布更趋均匀。具体实现中,对1x128元素块取绝对值并计算对数后,确定最小值min与最大值max。最小值编码为S.00···01,最大值编码为S.11···11,步长 S t e p = ( m a x − m i n ) / ( 2 ( n − 1 ) − 2 ) Step=(max-min)/(2^{(n-1)}-2) Step=(max−min)/(2(n−1)−2)。零值特例编码为S.00···00,其余值四舍五入至最近的 K × S t e p K×Step K×Step 整数倍。解码过程通过符号位与 e x p ( m i n + S t e p × ( K − 1 ) ) exp^{(min+Step×(K-1))} exp(min+Step×(K−1))组合实现。该格式支持动态表示范围,较静态浮点格式能覆盖更大范围或提供更高精度。
通过本地计算 min 和 Step,此数据类型支持不同块的动态表示范围,与静态浮点格式相比,涵盖更大的范围或提供更高的精度。此外,我们发现在原始 Linear 空间而不是 Log 空间中四舍五入对于无偏激活量化很重要。我们还将 min 限制为大于 max − log(232),这意味着 max 表示范围类似于 E5,一个具有 5 个指数的浮点。我们通过量化残差分支的输出来模拟 MoE 模型中的组合阶段,在具有大约 70 亿个参数的密集语言模型上验证我们的 LogFMT-nBit。当设置 n = 8 时,与 FP8 共享相同的位,LogFMT-8Bit 显示出优越的图 2:H800 节点互连。 与 E4M3 或 E5M2 相比的训练准确性。将 n 增加到 10 位后,我们发现它类似于 BF16 组合级。
3.2.1 局限性
使用 LogFMT 的最初目的是将其应用于传输期间的激活或接近激活函数,因为它在相同的位宽下提供比 FP8 更高的精度。但是,后续计算需要重新转换为 BF16 或 FP8 以适应 Hopper GPU 张量核心的数据类型。由于用于 log/exp作的 GPU 带宽不足以及编码/解码期间的寄存器压力过大,如果编码/解码作与多对多通信融合,开销可能会很大 (50%∼100%)。因此,尽管实验结果验证了这种格式的有效性,但我们最终没有采用它。
3.2.2 建议
未来硬件可提供面向FP8或自定义格式的原生编解码单元,以降低带宽需求并优化通信流水线。这种优化对MoE训练等带宽敏感任务尤为重要。
4. 互连驱动设计
4.1 当前硬件架构
我们采用的NVIDIA H800 GPU SXM架构(如图2所示)基于Hopper架构,与H100 GPU类似,但为符合监管要求降低了FP64计算性能和NVLink带宽。具体而言,H800 SXM节点的NVLink带宽从900GB/s降至400GB/s。这种节点内纵向扩展带宽的大幅削减对高性能工作负载构成挑战。为弥补此缺陷,每个节点配备八张400G Infiniband(IB)CX7网卡,通过增强横向扩展能力缓解带宽不足问题。
为应对这些硬件限制,DeepSeek-V3模型融入多项与硬件特性匹配的设计考量。
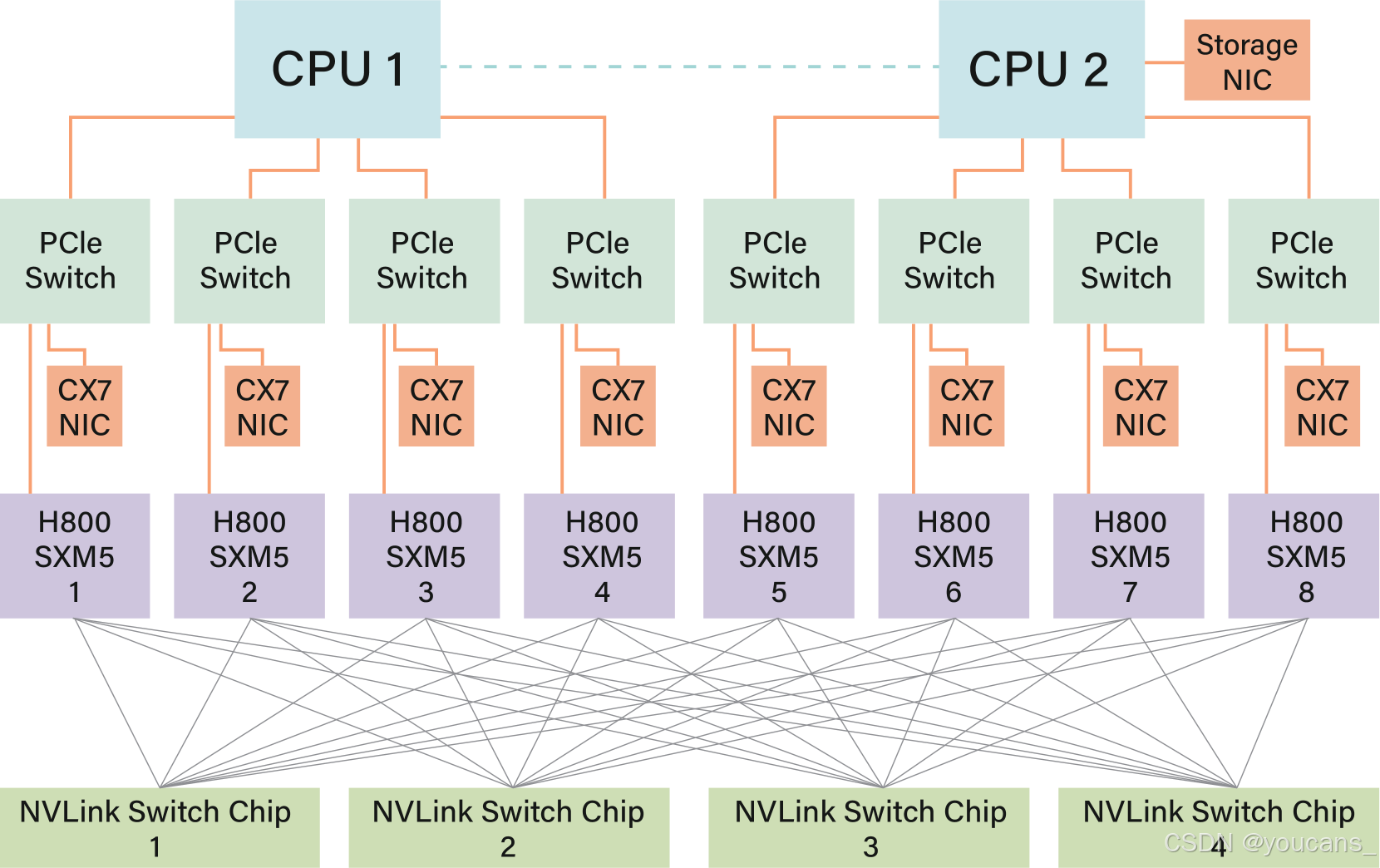
图 2:H800 节点互连。
4.2 硬件感知并行策略
为适应H800架构约束,我们采用以下并行策略优化DeepSeek-V3性能:
-
规避张量并行(TP):
训练阶段因NVLink带宽限制回避TP,但推理阶段仍可选择性采用以降低延迟 -
增强流水线并行(PP):
采用DualPipe(DeepSeek-AI, 2025b)重叠注意力计算与MoE通信,减少流水线气泡并平衡GPU内存使用 -
加速专家并行(EP):
借助8张400Gbps IB网卡实现超40GB/s的全对全通信,开源实现DeepEP(Zhao et al., 2025b)提供高效专家并行支持
值得注意的是,我们的 all-to-all EP 实现 DeepEP [78] 是开源的,实现了高效的专家并行性,如以下小节所述。
4.3 模型协同设计:节点受限路由
H800架构中纵向(节点内)与横向(节点间)通信带宽比约为4:1(NVLink实际带宽160GB/s vs 单IB网卡有效带宽40GB/s)。具体来说,NVLink 提供 200GB/s 的带宽(其中实际可以达到约 160GB/s),而每个 400Gbps 的 IB NIC 仅提供 50GB/s 的带宽(我们考虑到小消息大小和延迟的影响,使用 40GB/s 作为有效带宽)。为了平衡和充分利用更高的节点内带宽,模型架构与硬件共同设计,特别是在 TopK 专家选择策略中。
以8节点(64GPU)部署256名路由专家(每GPU4专家)为例。如果其 8 个目标专家分布在所有 8 个节点上,则通过 IB 的通信时间为 8t,其中 t 表示通过 IB 发送一个代币的时间。但是,通过利用更高的 NVLink 带宽,路由到同一节点的令牌可以通过 IB 发送一次,然后通过 NVLink 转发到其他节点内 GPU 。NVLink 转发支持 IB 流量的重复数据删除。当给定代币的目标专家分布在 M 个节点上时,去重后的 IB 通信成本将降低到 Mt (M < 8)。
由于 IB 流量仅依赖于 M,因此 DeepSeek-V3 为 TopK 专家选择策略引入了 Node-Limited Routing。具体来说,我们将 256 名路由专家分为 8 个组,每组 32 名专家,并将每个组部署在单个节点上。在此部署之上,我们在算法上确保每个令牌将被路由到最多 4 个节点。这种方法缓解了 IB 通信的瓶颈,提高了训练期间的有效通信带宽。
4.4 纵向与横向扩展融合
4.4.1 现有实现局限
节点受限路由策略虽降低带宽需求,但因NVLink与IB带宽差异导致通信流水线内核实现复杂化。训练中H800 GPU需分配多达20个流式多处理器(SM)处理通信任务(如填充QP/WQE、NVLink数据转发),挤占计算资源。在线推理场景为规避SM争用,我们完全通过NIC RDMA执行EP全对全通信,凸显RDMA异步通信优势。
虽然 NodeLimited 路由策略降低了通信带宽要求,但由于节点内 (NVLink) 和节点间 (IB) 互连之间的带宽差异,它使通信管道内核实现复杂化。在实践中,GPU 流式多处理器 (SM) 线程用于网络消息处理(例如,填充 QP 和 WQE)和通过 NVLink 进行数据转发,消耗计算资源。例如,在训练期间,H800 GPU 上多达 20 个 SMs 被分配给与通信相关的作,从而留给实际计算的资源较少。为了最大限度地提高在线推理的吞吐量,我们完全通过 NIC RDMA 执行 EP 全对全通信,避免了 SM 资源争用并提高计算效率。这凸显了 RDMA 的异步通信模型在重叠计算和通信方面的优势。
以下是 SM 当前在 EP 通信期间执行的关键任务,特别是对于 combine 阶段的 reduce作和数据类型转换。将这些任务卸载到专用通信硬件可以释放 SM 用于计算内核,从而显著提高整体效率:
- 转发数据:聚合发往 IB 和 NVLink 域之间同一节点内多个 GPU 的 IB 流量。
- 数据传输:在 RDMA 缓冲区 (已注册的 GPU 内存区域) 和输入/输出缓冲区之间移动数据。
- 减少操作:执行 EP all-to-all 组合通信所需的 reduce作。
- 管理内存布局:处理跨 IB 和 NVLink 域的分块数据传输的精细内存布局。• 数据类型转换:在所有通信之前和之后转换数据类型。
4.4.2 改进建议
为了解决这些低效率问题,我们强烈建议未来的硬件应将节点内(纵向扩展)和节点间(横向扩展)通信集成到一个统一的框架中。通过整合专用协处理器来管理网络流量以及 NVLink 和 IB 域之间的无缝转发,此类设计可以降低软件复杂性并最大限度地提高带宽利用率。例如,DeepSeek-V3 中采用的节点限制路由策略可以通过对动态流量重复数据删除的硬件支持进一步优化。
-
统一网络适配器:
设计连接到统一纵向扩展和横向扩展网络的 NIC(网络接口卡)或 I/O 芯片。这些适配器还应支持基本的交换机功能,例如将数据包从横向扩展网络转发到纵向扩展网络中的特定 GPU。这可以通过使用具有基于策略的路由的单个 LID(本地标识符)或 IP 地址来实现。 -
专用通信协处理器:
引入专用协处理器或可编程组件(如 I/O 芯片)来处理网络流量。此组件将卸载 GPU SM 的数据包处理,从而防止性能下降。此外,它还应包括硬件加速的内存复制功能,以实现高效的缓冲区管理。 -
灵活广播/归约机制:
硬件应支持跨纵向扩展和横向扩展网络的灵活转发、广播(EP分发)与归约(EP组合)操作,这反映了我们当前基于 GPU SM 的实现。这不仅可以提高有效带宽,还可以降低特定于网络的作的计算复杂性。 -
硬件同步原语:
提供精细的硬件同步指令,以处理硬件级别的内存一致性问题或无序数据包到达。这将消除对基于软件的同步机制(如 RDMA 完成事件)的需求,这些机制会带来额外的延迟并增加编程复杂性。具有 acquire/release 机制的内存语义通信是一种很有前途的实现。
通过实施这些建议,未来的硬件设计可以显著提高大规模分布式 AI 系统的效率,同时简化软件开发。
4.5 带宽争用与延迟
4.5.1 现存问题
当前硬件缺乏NVLink/PCIe带宽动态分配能力。例如推理时KV缓存从CPU内存传输至GPU可能占满PCIe带宽,若同时进行EP通信将导致性能下降与延迟尖峰。
4.5.2 优化方向
-
动态流量优先级:
硬件应支持根据流量类型对流量进行动态优先级排序。例如,应为与 EP、TP 和 KV 缓存传输相关的流量分配不同的优先级,以最大限度地提高互连效率。对于 PCIe,将 traffic class (TC) 公开给用户级编程就足够了。 -
I/O芯片集成:
将 NIC 直接集成到 I/O 芯片中,并将它们连接到同一封装中的计算芯片,而不是通过传统的 PCIe,将大大减少通信延迟并缓解 PCIe 带宽争用。 -
CPU-GPU专用互连:
为了进一步优化节点内通信,CPU 和 GPU 应使用 NVLink 或类似的专用高带宽结构互连,而不是仅仅依赖 PCIe。与将 NIC 集成到 I / O 芯片中带来的好处类似,这种方法可以显著改善训练和推理期间在 GPU 和 CPU 内存之间卸载参数或 KV 缓存等场景。
5. 大规模网络驱动设计
5.1 网络协同设计:多平面胖树
在DeepSeek-V3 训练中,我们部署了如图3所示的多平面胖树(MPFT)横向扩展网络。每个节点配备8块GPU与8张IB网卡,每对GPU-网卡分配至独立网络平面。另设400Gbps以太网RoCE网卡连接专用存储平面以访问3FS(DeepSeek-AI, 2025c)分布式文件系统。横向网络采用64端口400G IB交换机,理论上支持16,384 GPU规模的两层拓扑,但因政策限制最终仅部署两千余GPU。
受限于当前IB ConnectX-7技术,实际MPFT网络未完全实现理想架构——如图4 所示,理想情况下每张网卡应具备多物理端口并支持端口聚合,使单个队列对(QP)能跨端口分发数据包,这要求网卡原生支持乱序报文重组。InfiniBand ConnectX-8已原生支持四平面架构,未来网卡应全面增强多平面能力以支撑超大规模AI集群。
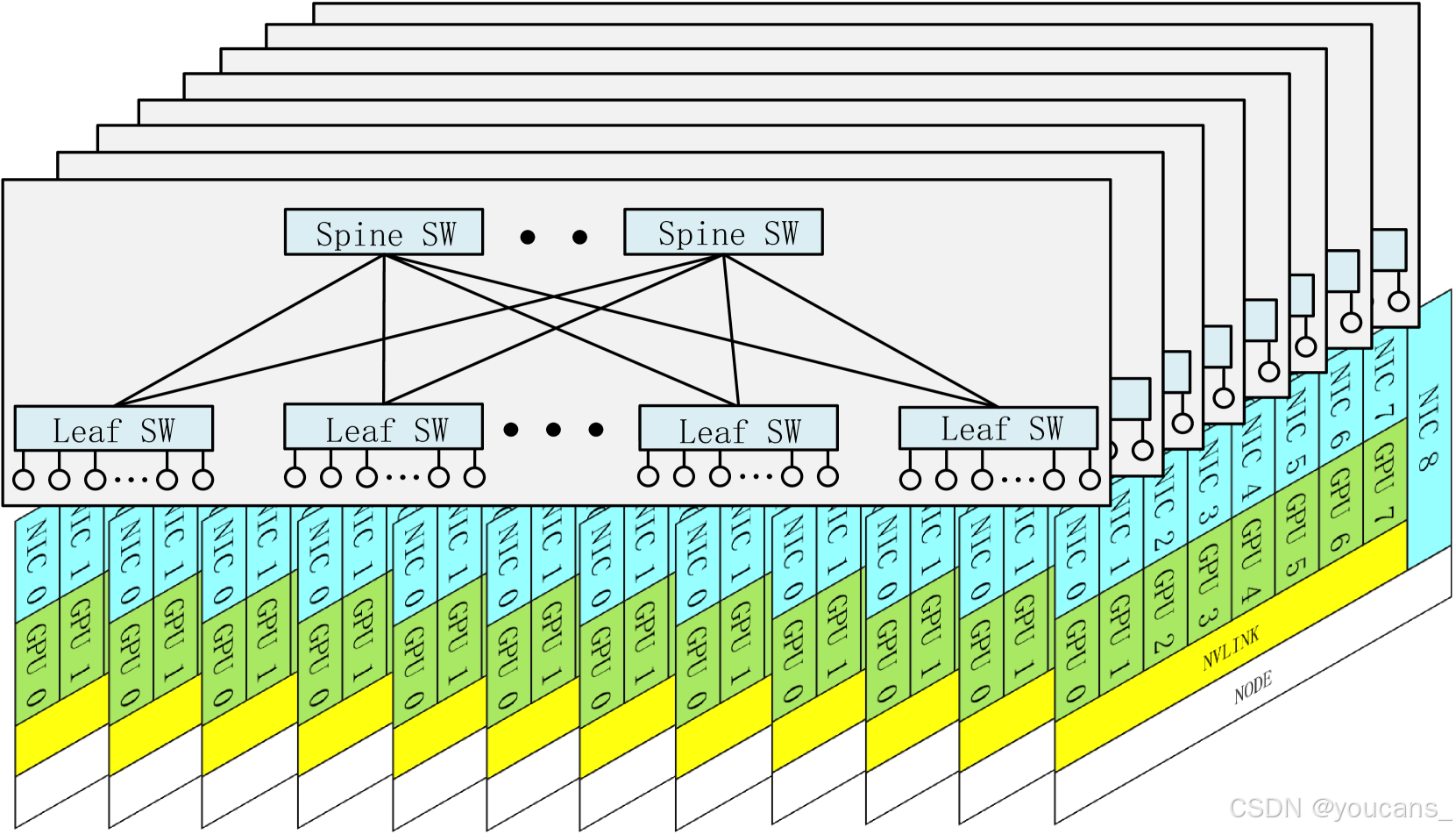
图 3 :八平面两层胖树横向扩展网络:每个 GPU 和 IB NIC 对属于一个网络平面。跨平面流量必须使用另一个 NIC 和 PCIe 或 NVLink 进行节点内转发。
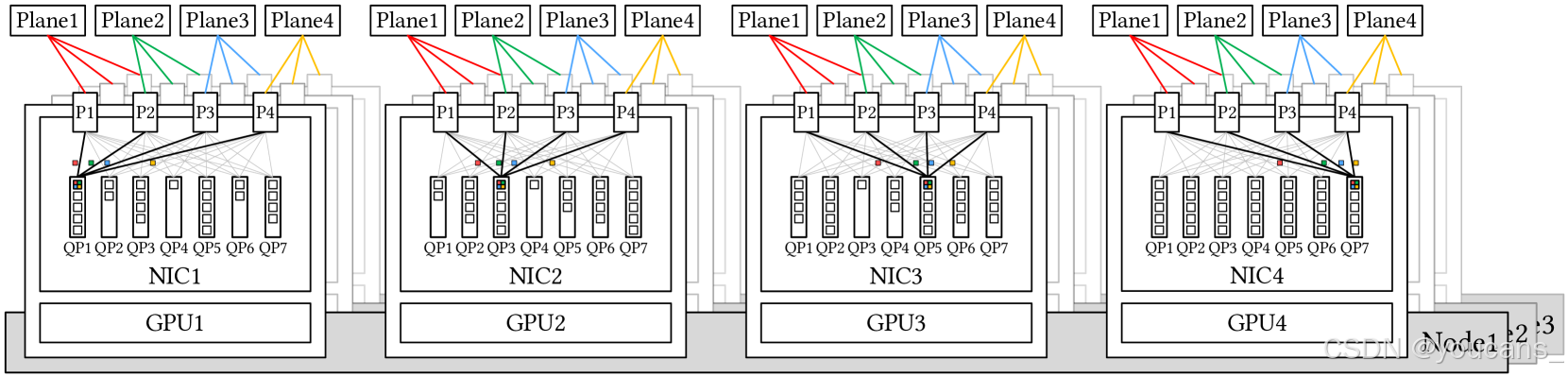
图 4:理想的多平面网络:
每个 NIC 都配备了多个物理端口,每个端口都连接到不同的网络平面。单个队列对 (QP) 可以同时利用所有可用端口来传输和接收数据包,这需要对 NIC 中的无序放置提供本机支持。
5.1.1 多平面胖树网络优势
-
多轨胖树(MRFT)子集:
MPFT属于MRFT特例,可直接复用NVIDIA与NCCL对多轨网络的优化成果,NCCL PXN技术(Mandakolathur and Jeaugey, 2022)有效解决平面间隔离通信问题 -
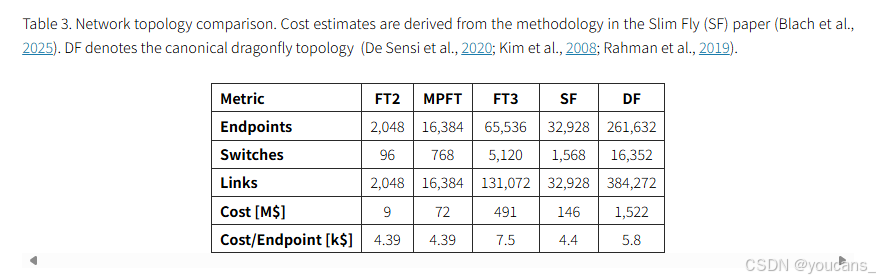
成本效益:
如表3所示,MPFT在16K端点规模下较三层胖树(FT3)显著降低成本,单端点成本甚至优于经济型Slim Fly(SF)拓扑(Blach et al., 2025) -
流量隔离:
平面间故障互不影响,提升整体稳定性 -
低延迟:
实验证明两层拓扑延迟低于三层架构,特别适合MoE训练等时敏场景 -
高容错:
如图4所示,多端口网卡提供冗余上行链路,单端口故障可快速透明恢复
注:当前400G NDR InfiniBand需通过节点内转发实现跨平面通信,引入额外延迟。若未来硬件实现4.4节所述的纵向-横向网络融合,可显著降低此类延迟。
5.1.2 性能分析
为验证MPFT有效性,我们在集群中对比MPFT与单平面多轨胖树(MRFT)性能:
- All-to-All 通信与EP场景:图5 显示MPFT全对全性能与MRFT相当,归功于NCCL PXN机制通过NVLink优化流量转发。图6 的16GPU全对全测试中两者延迟差异可忽略。图7展示训练场景下EP通信带宽稳定超40GB/s。
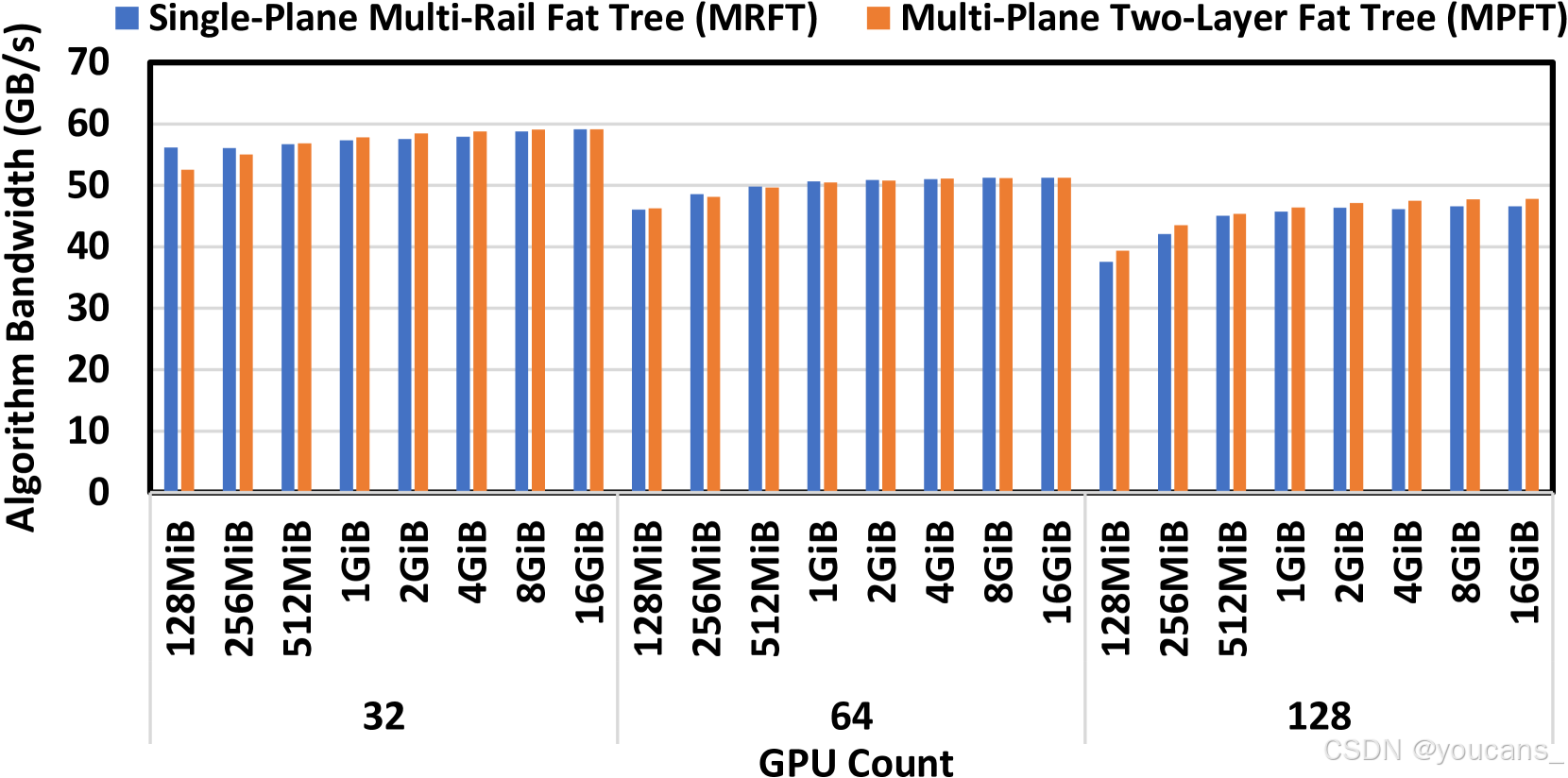
图 5 :MRFT 和 MPFT 网络的 NCCL 全对全性能,从 32 到 128 个 GPU 。
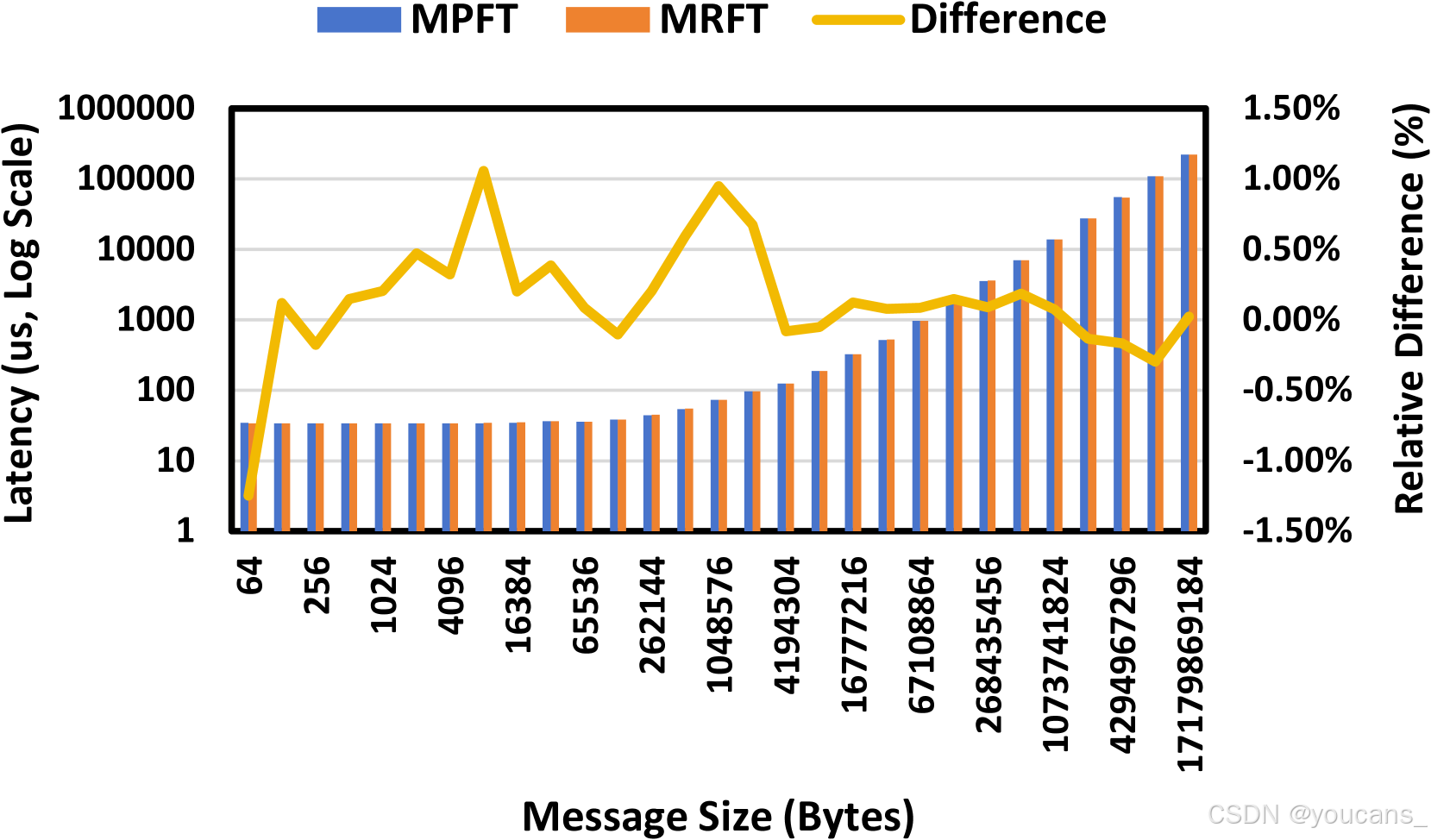
图 6:在不同消息大小下,NCCL all-to-all 测试中 MPFT 和 MRFT 网络之间的延迟比较,表明它们的性能几乎相同。
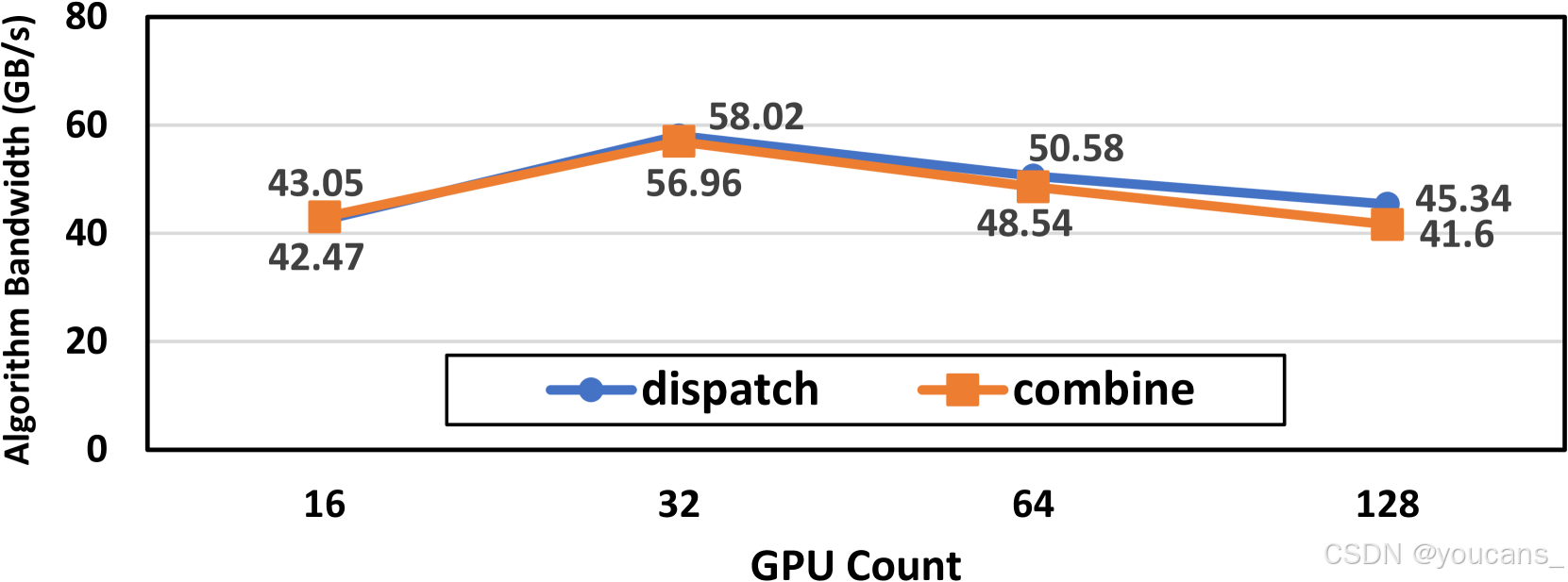
图 7 : MPFT 上的 DeepEP 性能:
EP 调度和组合内核使用多对多在 16 到 128 个 GPU 之间进行通信。每个 GPU 处理 4096 个令牌。观察到的吞吐量几乎使 400Gps NIC 带宽饱和。
- DeepSeek-V3 模型的训练吞吐量:
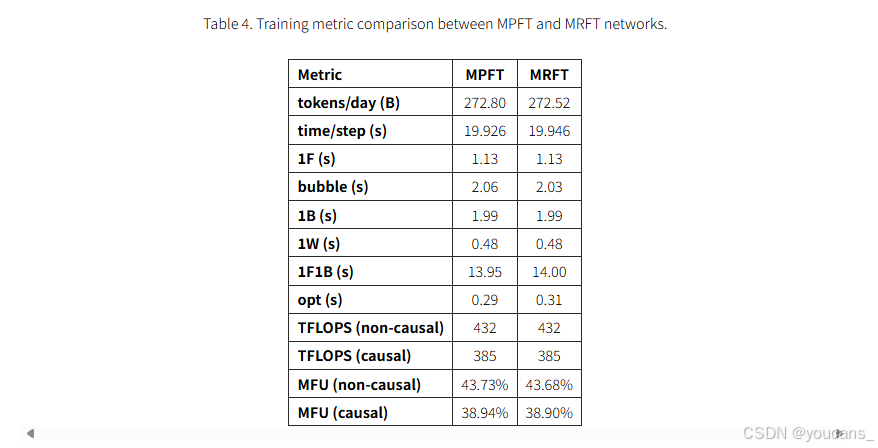
我们还在表 4 中比较了 DeepSeek-V3 模型在 MPFT 和 MRFT 之间的训练指标。
MFU (Model Flops Utilization) 是根据 BF16 峰值性能计算的。因果 MFU 只考虑了注意力矩阵下三角形的翻牌(与 FlashAttention[19, 20] 一致),而非因果 MFU 包括整个注意力矩阵的翻牌(与 Megatron [47] 一致)。1F、1B 和 1W 分别表示前进时间、输入后退时间和重量后退时间。在 2048 个 GPU 上训练 V3 模型时,MPFT 的性能与 MRFT 的性能几乎相同,观察到的差异属于正常波动和测量误差。
5.2 低延迟网络
在我们的模型推理中,大规模 EP 严重依赖于多对多通信,这对带宽和延迟都非常敏感。考虑第 2.3.2 节中讨论的典型场景,网络带宽为 50GB/s,理想情况下数据传输大约需要 120 μs。因此,微秒级的固有网络延迟会严重影响系统性能,使其影响不可忽略。
5.2.1 IB与RoCE对比
如表5 所示,IB凭借更低延迟成为分布式训练/推理首选,但存在两大局限:
扩展性:单IB交换机仅支持64端口,而RoCE交换机通常支持128端口
-
成本:
IB 硬件比 RoCE 解决方案贵得多,这限制了它的广泛采用。 -
可扩展性:
IB 交换机通常仅支持每台交换机 64 个端口,而 RoCE 交换机通常支持 128 个端口。这限制了基于 IB 的集群的可扩展性,尤其是对于大规模部署。

5.2.2 RoCE改进建议
虽然 RoCE 有可能成为 IB 的经济高效的替代方案,但其当前在延迟和可扩展性方面的限制使其无法完全满足大规模 AI 系统的需求。下面,我们概述了改进 RoCE 的具体建议:
-
专用低延迟RoCE交换机:
建议以太网厂商剥离冗余功能专为RDMA优化,Slingshot架构(De Sensi et al., 2020)与Broadcom(2025)的AI转发头(AIFH)技术已证明可行性。 -
优化路由策略:
如图8所示,RoCE默认ECMP路由在NCCL集合通信中易引发链路拥塞,而自适应路由(AR)(Geoffray and Hoefler, 2008)能通过动态多路径分发显著提升性能。 -
增强流量隔离与拥塞控制:
当前RoCE交换机优先级队列数不足,难以应对EP全对全与DP全规约的混合流量。建议采用虚拟输出队列(VOQ)隔离流,或部署RTTCC/PCC等先进拥塞控制机制。
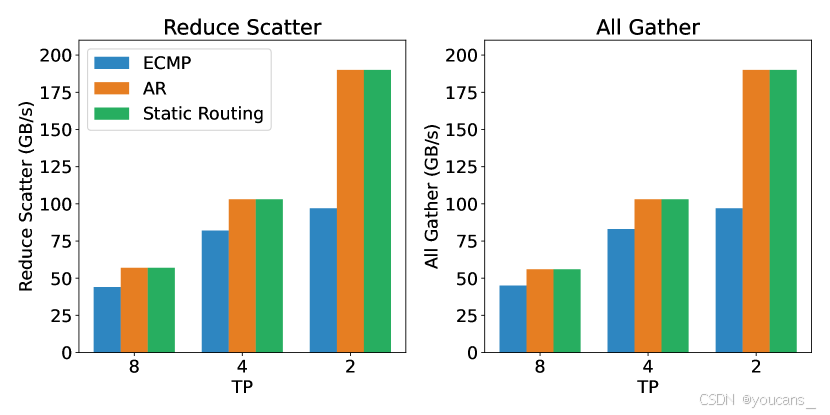
图 8:AllGather 和 ReduceScatter 通信原语在不同路由方法(ECMP、AR、静态路由)和 TP 维度下的 RoCE 网络带宽。
5.2.3 InfiniBand GPUDirect异步(IBGDA)
我们利用IBGDA(NVIDIA,2022;Agostini等人,2018)来减少网络通信中的延迟。
传统上,网络通信涉及创建CPU代理线程:一旦GPU准备好数据,它必须通知CPU代理,然后CPU代理填充工作请求(WR)的控制信息,并通过门铃机制向NIC发出信号以启动数据传输。此过程引入了额外的通信开销。
IBGDA 通过允许 GPU 直接填充 WR 内容并写入 RDMA 门铃 MMIO 地址来解决这个问题。通过在 GPU 中管理整个控制平面, IBGDA 消除了与 GPU-CPU 通信相关的大量延迟开销。而且,当发送大量小数据包时,控制平面处理器很容易成为瓶颈。由于 GPU 具有多个并行线程,因此发送者可以利用这些线程来分配工作负载,从而避免此类瓶颈。
我们的DeepEP(Zhao et al., 2025b)等实践已证明IBGDA可带来显著性能提升(Agostini et al., 2017),因此我们主张在 Accelerator 设备中广泛支持这些功能。
6. 未来硬件架构设计的讨论和洞见
在前面的部分的基础上,我们总结了关键的架构见解,并概述了针对大规模 AI 工作负载量身定制的硬件设计的未来方向。第 2.3.2 节强调了大规模扩展网络对加速模型推理的重要性。第 3 节讨论了对低精度计算和通信的高效支持的必要性。第 4 节探讨了纵向扩展和横向扩展架构的融合,以及一些建议的增强功能。第 5 节重点介绍了多平面网络拓扑,并确定了基于以太网的互连所需的关键改进。这些部分共同确定了具体应用程序上下文中的硬件限制,并提供了相应的建议。在此基础上,本节将讨论扩展到更广泛的考虑因素,并为未来的硬件架构设计提出了前瞻性的方向。
6.1 鲁棒性挑战
6.1.1 现存问题
-
互连故障:
高性能互连(例如 IB 和 NVLink)容易出现间歇性断开连接,这可能会中断节点到节点的通信。这在 EP 等通信密集型工作负载中尤其有害,即使是短暂的中断也可能导致性能显著下降或作业失败。 -
单点硬件故障:
节点崩溃、GPU 故障或 ECC(纠错码)内存错误可能会损害长时间运行的训练作业,通常需要代价高昂的重启。在大规模部署中,此类故障的影响会升级,其中单点故障的可能性与系统大小成比例增加。 -
静默数据损坏:
ECC 机制未检测到的错误(例如多位内存翻转或计算不准确)会对模型质量构成重大风险。这些错误在长时间运行的任务中尤其阴险,因为它们可能会传播未检测到的 JSON 计算并破坏下游计算。当前的缓解策略依赖于应用程序级启发式方法,这不足以确保系统范围的稳健性。
6.1.2 高级错误检测和更正建议
为了降低与静默损坏相关的风险,硬件必须采用超越传统 ECC 的高级错误检测机制。
基于校验和的验证或硬件加速冗余检查等技术可以为大规模部署提供更高的可靠性。此外,硬件供应商应向最终用户提供全面的诊断工具包,使他们能够严格验证其系统的完整性,并主动识别任何潜在的静默数据损坏。当作为标准硬件包的一部分嵌入时,此类工具包可以提高透明度并在整个运营生命周期中实现持续验证,从而提高整体系统的可信度。
6.2 CPU瓶颈与互连
虽然加速器设计通常占据中心位置,但 CPU 对于协调计算、管理 I/O 和维持系统吞吐量仍然至关重要。然而,当前的架构面临几个关键瓶颈:
-
PCIe接口限制:
如4.5节所述,CPU-GPU间PCIe在参数/KV缓存传输时成为带宽瓶颈,尤其是在大规模参数、梯度或 KV 缓存传输期间。为了缓解这种情况,未来的系统应采用直接的 CPU-GPU 互连(例如 NVLink 或 Infinity Fabric),或者将 CPU 和 GPU 集成到纵向扩展域中,从而消除节点内瓶颈。 -
内存带宽需求:
除了 PCIe 限制之外,维持如此高的数据传输速率还需要极高的内存带宽。例如,饱和 160 个 PCIe 5.0 通道需要每个节点超过 640 GB/s,这意味着每个节点的内存带宽要求约为 1 TB/s,这对传统 DRAM 架构构成了重大挑战。 -
核心性能要求:
延迟敏感型任务(如内核启动和网络处理)需要较高的单核 CPU 性能,通常需要 4 GHz 以上的基本频率。此外,现代 AI 工作负载需要每个 GPU 有足够的 CPU 内核,以防止控制端瓶颈。对于基于 chiplet 的架构,需要额外的内核来支持缓存感知工作负载分区和隔离。
6.3 智能网络演进方向
为了满足延迟敏感型工作负载的需求,未来的互连必须优先考虑低延迟和智能网络:
-
共封装光学:硅光技术提升能效与带宽扩展性
结合硅光子学可实现可扩展的更高带宽可扩展性和更高的能效,这两者都对于大规模分布式系统至关重要。 -
无损网络:基于信用机制的流量控制需结合终端驱动拥塞控制算法
基于信用的流量控制 (CBFC) 机制可确保无损数据传输,但天真地触发流量控制可能会导致严重的队头阻塞。因此,必须部署先进的端点驱动型拥塞控制 (CC) 算法,以主动调节注射速率并避免病态的拥塞情况。 -
自适应路由:应标准化动态路由方案(如数据包喷洒)
正如第 5.2.2 节所强调的,未来的网络应该标准化采用动态路由方案,例如数据包喷洒和拥塞感知路径选择,这些方案可持续监控实时网络状况并智能地重新分配流量。这些自适应策略在缓解集体通信工作负载(包括全对全和减少分散作)期间的热点和瓶颈方面特别有效。 -
高效容错协议:链路层重试机制与选择性重传协议提升可靠性
通过部署自我修复协议、冗余端口和快速故障转移技术,可以显著提高对故障的稳健性。例如,链路层重试机制和选择性重传协议被证明对于在大型网络中扩展可靠性、最大限度地减少停机时间和确保在间歇性故障的情况下无缝运行是必不可少的。 -
动态资源管理:支持训练/推理流量隔离与带宽动态分配
为了有效地处理混合工作负载,未来的硬件应支持动态带宽分配和流量优先级。例如,推理任务应与统一集群中的训练流量隔离,以确保延迟敏感型应用程序的响应能力。
6.4 内存语义通信与顺序问题
现有跨节点内存语义通信受限于内存顺序约束:发送方必须显式内存屏障才能更新通知标志,引入额外RTT延迟。我们主张硬件原生支持内存语义通信的顺序保障,建议采用区域获取/释放(RAR)机制——接收方硬件通过位图跟踪RNR内存区域状态,将排序任务卸载至NIC/I/O芯片。该机制同样有利于RDMA原子操作等消息语义场景。
使用 load/store memory 语义的节点间通信是高效且对程序员友好的,但当前的实现受到内存排序挑战的阻碍。例如,写入数据后,发送方必须在更新标志之前发出显式内存屏障(栅栏)以通知接收方,从而确保数据一致性。这种严格的排序会带来额外的往返时间 (RTT) 延迟,并可能使发出线程停止,从而阻碍正在进行的存储并降低吞吐量。消息语义 RDMA 中也会出现类似的无序同步问题;例如,在 InfiniBand 或 NVIDIA BlueField-3 上进行常规 RDMA 写入后,使用数据包喷射执行 RDMA 原子添加作可能会导致额外的 RTT 延迟。
为了解决这些问题,我们提倡为内存语义通信提供内置排序保证的硬件支持。这种一致性应该在编程级别(例如,通过 acquire/release 语义)和接收器的硬件中强制执行,从而在不增加开销的情况下实现按顺序交付。
有几种可能的方法。例如,接收方可以缓冲原子消息并使用数据包序列号进行顺序处理。但是,获取/释放机制更优雅、更高效。我们建议使用一种简单的概念机制,即区域获取/释放 (RAR) 机制,其中接收器硬件维护位图以跟踪 RNR 内存区域的状态,并且获取/释放作的范围限定为 RAR 地址范围。凭借最小的位图开销,这实现了高效的、硬件强制的排序,消除了明确的发送方围栏,并将排序委托给硬件 — 最好是在 NIC 或 I/O 芯片上。重要的是,RAR 机制不仅有利于内存语义作,也有利于消息语义 RDMA 原语,从而扩大了其实际适用性。
6.5 网内计算与压缩
EP的两个关键的 All-to-All 阶段存在优化机遇:
-
分发阶段:硬件级协议实现自动包复制与多目标转发
分发阶段类似于小规模多播作,其中必须将单个消息转发到多个目标设备。支持自动数据包复制和转发到多个目的地的硬件级协议可以大大降低通信开销并提高效率。 -
组合阶段:支持灵活的小规模网内聚合
组合阶段作为小规模的缩减作,可以从网络内聚合技术中受益。
然而,由于 EP 联合收敛的缩减范围小且工作负载不平衡,以灵活的方式实现网络内聚合具有挑战性。此外,正如第 3.2 节所强调的,LogFMT 支持低精度令牌传输,对模型性能的影响最小。将 LogFMT 原生整合到网络硬件中,可以通过增加熵密度和减少带宽使用来进一步优化通信。硬件加速的压缩和解压缩将允许将 LogFMT 无缝集成到分布式系统中,从而提高整体吞吐量。
6.6 内存中心创新
6.6.1 内存带宽局限
模型大小的指数级增长超过了高带宽内存 (HBM) 技术的进步。这种差异造成了内存瓶颈,尤其是在像 Transformer 这样需要大量注意力的架构中。
6.6.2 发展方向
-
DRAM堆叠加速器:采用3D堆叠技术(如SeDRAM[Wang et al., 2023])实现超高带宽推理
利用先进的 3D 堆叠技术,DRAM 芯片可以垂直集成在逻辑芯片上,从而实现极高的内存带宽、超低延迟和实用的内存容量(尽管堆栈有限)。事实证明,这种架构范式对于 MoE 模型中的超快速推理非常有利,其中内存吞吐量是一个关键瓶颈。SeDRAM[72] 等架构体现了这种方法的潜力,为内存受限的工作负载提供前所未有的性能。 -
晶圆级系统(SoW):晶圆级集成[Lie, 2022]满足超大规模模型需求
晶圆级集成 [50] 可以最大限度地提高计算密度和内存带宽,满足超大规模模型的需求。
7. 结论
DeepSeek-V3 体现了硬件软件协同设计在提高大规模 AI 系统的可扩展性、效率和稳健性方面的变革潜力。
通过解决当前硬件架构的局限性并提出可行的建议,本文为下一代 AI 优化硬件提供了路线图。随着 AI 工作负载的复杂性和
规模不断增长,这些创新将至关重要,从而推动智能系统的未来发展。
参考文献
[1] Elena Agostini, Davide Rossetti, and Sreeram Potluri. 2017. Offloading Communication Control Logic in GPU Accelerated Applications. In 2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID). 248257. https://doi.org/10.1109/CCGRID.2017.29
[2] E. Agostini, D. Rossetti, and S. Potluri. 2018. GPUDirect Async: Exploring GPU synchronous communication techniques for InfiniBand clusters. J. Parallel and Distrib. Comput. 114 (2018), 28–45. https://doi.org/10.1016/j.jpdc.2017.12.007
[3] AI@Meta. 2024. Llama 3 Model Card. https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md
[4] AI@Meta. 2024. Llama 3.1 Model Card. https://github.com/meta-llama/llamamodels/blob/main/models/llama3_1/MODEL_CARD.md
[5] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint arXiv:2305.13245 (2023).
[6] AMD. 2025. AMD Ryzen AI Max+ PRO 395: Designed to power a new generation of compact Copilot+ PC workstations. https: //www.amd.com/en/products/processors/laptop/ryzen- pro/ai- max- pro300- series/amd- ryzen- ai- max- plus- pro- 395.html
[7] Wei An, Xiao Bi, Guanting Chen, Shanhuang Chen, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Wenjun Gao, Kang Guan, Jianzhong Guo, Yongqiang Guo, Zhe Fu, Ying He, Panpan Huang, Jiashi Li, Wenfeng Liang, Xiaodong Liu, Xin Liu, Yiyuan Liu, Yuxuan Liu, Shanghao Lu, Xuan Lu, Xiaotao Nie, Tian Pei, Junjie Qiu, Hui Qu, Zehui Ren, Zhangli Sha, Xuecheng Su, Xiaowen Sun, Yixuan Tan, Minghui Tang, Shiyu Wang, Yaohui Wang, Yongji Wang, Ziwei Xie, Yiliang Xiong, Yanhong Xu, Shengfeng Ye, Shuiping Yu, Yukun Zha, Liyue Zhang, Haowei Zhang, Mingchuan Zhang, Wentao Zhang, Yichao Zhang, Chenggang Zhao, Yao Zhao, Shangyan Zhou, Shunfeng Zhou, and Yuheng Zou. 2024. Fire-Flyer AIHPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning. In SC24: International Conference for High Performance Computing, Networking, Storage and Analysis. 1–23. https://doi.org/10.1109/SC41406.2024.00089
[8] Anthropic. 2024. Claude 3.5 Sonnet. https://www.anthropic.com/news/claude3- 5- sonnet
[9] Anthropic. 2025. Claude 3.7 Sonnet and Claude Code. https:// www.anthropic.com/news/claude- 3- 7- sonnet
[10] Apple. 2024. Apple introduces M4 Pro and M4 Max. https://www.apple.com/ newsroom/2024/10/apple- introduces- m4- pro- and- m4- max/
[11] Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The LongDocument Transformer. arXiv:2004.05150 (2020).
[12] Nils Blach, Maciej Besta, Daniele De Sensi, Jens Domke, Hussein Harake, Shigang Li, Patrick Iff, Marek Konieczny, Kartik Lakhotia, Ales Kubicek, Marcel Ferrari, Fabrizio Petrini, and Torsten Hoefler. 2025. A high-performance design, implementation, deployment, and evaluation of the slim fly network. In Proceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation (Santa Clara, CA, USA) (NSDI’24). USENIX Association, USA, Article 57, 20 pages.
[13] Broadcom. 2025. Scale Up Ethernet Framework. https://docs.broadcom.com/ doc/scale- up- ethernet- framework
[14] Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https: //openreview.net/forum?id=PEpbUobf Jv
[15] Shaoyuan Chen, Wencong Xiao, Yutong Lin, Mingxing Zhang, Yingdi Shan, Jinlei Jiang, Kang Chen, and Yongwei Wu. 2025. Efficient Heterogeneous Large Language Model Decoding with Model-Attention Disaggregation. arXiv:2405.01814
[cs.LG] https://arxiv.org/abs/2405.01814
[16] ULTRA ACCELERATOR LINK CONSORTIUM. 2025. Introducing UALink 200G 1.0 Specification. https://ualinkconsortium.org/wp-content/uploads/2025/04/ UALink- 1.0- White_Paper_FINAL.pdf
[17] Ultra Ethernet Consortium. 2023. Overview of and Motivation for the Forthcoming Ultra Ethernet Consortium Specification. https://ultraethernet.org/wpcontent/uploads/sites/20/2023/10/23.07.12- UEC- 1.0- Overview- FINAL- WI THLOGO.pdf
[18] Ultra Ethernet Consortium. 2024. UEC Progresses Towards v1.0 Set of Specifications. https://ultraethernet.org/uec-progresses-towards-v1-0-set-ofspecifications/
[19] Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.
[20] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In Advances in Neural Information Processing Systems.
[21] Tri Dao and Albert Gu. 2024. Transformers are SSMs: generalized models and efficient algorithms through structured state space duality. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24). JMLR.org, Article 399, 31 pages.
[22] Daniele De Sensi, Salvatore Di Girolamo, Kim H. McMahon, Duncan Roweth, and Torsten Hoefler. 2020. An In-Depth Analysis of the Slingshot Interconnect. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14. https://doi.org/10.1109/SC41405.2020.00039
[23] DeepSeek-AI. 2024. DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. CoRR abs/2406.11931 (2024). https://doi.org/ 10.48550/arXiv.2406.11931
[24] DeepSeek-AI. 2024. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. CoRR abs/2401.02954 (2024). https://doi.org/10.48550/ arXiv.2401.02954
[25] DeepSeek-AI. 2024. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-ofExperts Language Model. CoRR abs/2405.04434 (2024). https://doi.org/10.48550/ arXiv.2405.04434
[26] DeepSeek-AI. 2024. DeepSeek-V3 Technical Report. (2024). arXiv:2412.19437
[cs.CL] https://arxiv.org/abs/2412.19437
[27] DeepSeek-AI. 2024. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. CoRR abs/2401.06066 (2024). https: //doi.org/10.48550/arXiv.2401.06066
[28] DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948[cs.CL] https://arxiv.org/abs/ 2501.12948
[29] DeepSeek-AI. 2025. DualPipe: A bidirectional pipeline parallelism algorithm for computation-communication overlap in V3/R1 training. https://github.com/ deepseek- ai/dualpipe.
[30] DeepSeek-AI. 2025. Fire-Flyer File System. https://github.com/deepseek-ai/3FS
[31] DeepSeek-AI. 2025. Profiling Data in DeepSeek Infra. https://github.com/ deepseek- ai/profile- data?tab=readme- ov- file#inference
[32] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323 (2022).
[33] Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. 2024. RDMA over Ethernet for Distributed Training at Meta Scale. In Proceedings of the ACM SIGCOMM 2024 Conference (Sydney, NSW, Australia) (ACM SIGCOMM ’24). Association for Computing Machinery, New York, NY, USA, 57–70. https://doi.org/10.1145/3651890.3672233
[34] Patrick Geoffray and Torsten Hoefler. 2008. Adaptive Routing Strategies for Modern High Performance Networks. In 2008 16th IEEE Symposium on High Performance Interconnects. 165–172. https://doi.org/10.1109/HOTI.2008.21
[35] Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W. Mahoney, and Kurt Keutzer. 2024. AI and Memory Wall . IEEE Micro 44, 03 (May 2024), 33–39. https://doi.org/10.1109/MM.2024.3373763
[36] Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. 2024. Better & Faster Large Language Models via Multi-token Prediction. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https://openreview.net/ forum?id=pEWAcejiU2
[37] Google. 2024. Introducing Gemini 2.0: our new AI model for the agentic era. https://blog.google/technology/google-deepmind/google-gemini-aiupdate- december- 2024
[38] Google. 2025. Gemini 2.5: Our most intelligent AI model. https://blog.google/ technology/google- deepmind/gemini- model- thinking- updates- march- 2025/
[39] MADSys group and Approaching.AI. 2025. A Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations. https://github.com/kvcacheai/ktransformers
[40] Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. arXiv preprint arXiv:2401.18079 (2024).
[41] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7B. arXiv preprint arXiv:2310.06825 (2023).
[42] Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin Jin, and Xin Liu. 2024. MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs. http://arxiv.org/abs/2402.15627 arXiv:2402.15627 [cs].
[43] Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, Clifford Young, Xiang Zhou, Zongwei Zhou, and David A Patterson. 2023. TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings. In Proceedings of the 50th Annual International Symposium on Computer Architecture (Orlando, FL, USA) (ISCA ’23). Association for Computing Machinery, New York, NY, USA, Article 82, 14 pages. https://doi.org/10.1145/ 13 ISCA ’25, June 21–25, 2025, Tokyo, Japan DeepSeek-AI 3579371.3589350
[44] Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, and Tuo Zhao. 2024. GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM. arXiv:2403.05527 [cs.LG]
[45] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models. CoRR abs/2001.08361 (2020). arXiv:2001.08361 https://arxiv.org/abs/2001.08361
[46] John Kim, Wiliam J. Dally, Steve Scott, and Dennis Abts. 2008. TechnologyDriven, Highly-Scalable Dragonfly Topology. In 2008 International Symposium on Computer Architecture. 77–88. https://doi.org/10.1109/ISCA.2008.19
[47] Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. 2023. Reducing activation recomputation in large transformer models. Proceedings of Machine Learning and Systems 5 (2023).
[48] Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https://openreview.net/forum?id=1NdN7eXyb4
[49] Heng Liao, Bingyang Liu, Xianping Chen, Zhigang Guo, Chuanning Cheng, Jianbing Wang, Xiangyu Chen, Peng Dong, Rui Meng, Wenjie Liu, Zhe Zhou, Ziyang Zhang, Yuhang Gai, Cunle Qian, Yi Xiong, Zhongwu Cheng, Jing Xia, Yuli Ma, Xi Chen, Wenhua Du, Shizhong Xiao, Chungang Li, Yong Qin, Liudong Xiong, Zhou Yu, Lv Chen, Lei Chen, Buyun Wang, Pei Wu, Junen Gao, Xiaochu Li, Jian He, Shizhuan Yan, and Bill McColl. 2025. UB-Mesh: a Hierarchically Localized nD-FullMesh Datacenter Network Architecture. arXiv:2503.20377 [cs.AR] https: //arxiv.org/abs/2503.20377
[50] Sean Lie. 2022. Cerebras Architecture Deep Dive: First Look Inside the HW/SW Co-Design for Deep Learning : Cerebras Systems. In 2022 IEEE Hot Chips 34 Symposium (HCS). 1–34. https://doi.org/10.1109/HCS55958.2022.9895479
[51] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. In MLSys.
[52] Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache. arXiv preprint arXiv:2402.02750 (2024).
[53] Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. 2025. Large Language Model Agent: A Survey on Methodology, Applications and Challenges. arXiv preprint arXiv:2503.21460 (2025).
[54] Karthik Mandakolathur and Sylvain Jeaugey. 2022. Doubling all2all Performance with NVIDIA Collective Communication Library 2.12. https://developer.nvidia.com/blog/doubling- all2all- performance- withnvidia- collective- communication- library- 2- 12/
[55] Mistral. 2024. Cheaper, Better, Faster, Stronger: Continuing to push the frontier of AI and making it accessible to all. https://mistral.ai/news/mixtral-8x22b
[56] Dheevatsa Mudigere, Yuchen Hao, Jianyu Huang, Zhihao Jia, Andrew Tulloch, Srinivas Sridharan, Xing Liu, Mustafa Ozdal, Jade Nie, Jongsoo Park, Liang Luo, Jie Amy Yang, Leon Gao, Dmytro Ivchenko, Aarti Basant, Yuxi Hu, Jiyan Yang, Ehsan K. Ardestani, Xiaodong Wang, Rakesh Komuravelli, Ching-Hsiang Chu, Serhat Yilmaz, Huayu Li, Jiyuan Qian, Zhuobo Feng, Yinbin Ma, Junjie Yang, Ellie Wen, Hong Li, Lin Yang, Chonglin Sun, Whitney Zhao, Dimitry Melts, Krishna Dhulipala, K. R. Kishore, Tyler Graf, Assaf Eisenman, Kiran Kumar Matam, Adi Gangidi, Guoqiang Jerry Chen, Manoj Krishnan, Avinash Nayak, Krishnakumar Nair, Bharath Muthiah, Mahmoud khorashadi, Pallab Bhattacharya, Petr Lapukhov, Maxim Naumov, Ajit Mathews, Lin Qiao, Mikhail Smelyanskiy, Bill Jia, and Vijay Rao. 2023. Software-Hardware Co-design for Fast and Scalable Training of Deep Learning Recommendation Models. http://arxiv.org/abs/2104.05158 arXiv:2104.05158 [cs].
[57] NVIDIA. 2022. Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async. https://developer.nvidia.com/blog/improving- network- performance- ofhpc- systems- using- nvidia- magnum- io- nvshmem- and- gpudirect- async/
[58] NVIDIA. 2025. NVIDIA DGX Spark: A Grace Blackwell AI supercomputer on your desk. https://www.nvidia.com/en-us/products/workstations/dgx-spark/
[59] OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/
[60] OpenAI. 2024. Introducing OpenAI o1. https://openai.com/o1/
[61] OpenAI. 2025. Introducing OpenAI o3 and o4-mini. https://openai.com/index/ introducing- o3- and- o4- mini/.
[62] Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai. 2024. Alibaba HPN: A Data Center Network for Large Language Model Training. In Proceedings of the ACM SIGCOMM 2024 Conference (Sydney, NSW, Australia) (ACM SIGCOMM ’24). Association for Computing Machinery, New York, NY, USA, 691–706. https://doi.org/10.1145/3651890.3672265
[63] Zhen Qin, Weigao Sun, Dong Li, Xuyang Shen, Weixuan Sun, and Yiran Zhong. 2024. Various lengths, constant speed: efficient language modeling with lightning attention. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24). JMLR.org, Article 1688, 19 pages.
[64] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv:2305.18290 [cs.LG] https://arxiv.org/ abs/2305.18290
[65] Md Shafayat Rahman, Saptarshi Bhowmik, Yevgeniy Ryasnianskiy, Xin Yuan, and Michael Lang. 2019. Topology-custom UGAL routing on dragonfly. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (Denver, Colorado) (SC ’19). Association for Computing Machinery, New York, NY, USA, Article 17, 15 pages. https://doi.org/10.1145/ 3295500.3356208
[66] Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Summer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, Stosic Dusan, Venmugil Elango, Maximilian Golub, Alexander Heinecke, Phil James-Roxby, Dharmesh Jani, Gaurav Kolhe, Martin Langhammer, Ada Li, Levi Melnick, Maral Mesmakhosroshahi, Andres Rodriguez, Michael Schulte, Rasoul Shafipour, Lei Shao, Michael Siu, Pradeep Dubey, Paulius Micikevicius, Maxim Naumov, Colin Verrilli, Ralph Wittig, Doug Burger, and Eric Chung. 2023. Microscaling Data Formats for Deep Learning. arXiv:2310.10537 [cs.LG] https://arxiv.org/abs/2310.10537
[67] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs.LG] https://arxiv.org/abs/1707.06347
[68] ByteDance Seed. 2025. Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning. arXiv:2504.13914 [cs.CL] https://arxiv.org/abs/ 2504.13914
[69] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
[70] Noam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need. CoRR abs/1911.02150 (2019). http://arxiv.org/abs/1911.02150
[71] Qwen Team. 2025. Qwen3: Think Deeper, Act Faster. https://github.com/ QwenLM/Qwen3
[72] Song Wang, Bing Yu, Wenwu Xiao, Fujun Bai, Xiaodong Long, Liang Bai, Xuerong Jia, Fengguo Zuo, Jie Tan, Yixin Guo, Peng Sun, Jun Zhou, Qiong Zhan, Sheng Hu, Yu Zhou, Yi Kang, Qiwei Ren, and Xiping Jiang. 2023. A 135 GBps/Gbit 0.66 pJ/bit Stacked Embedded DRAM with Multilayer Arrays by Fine Pitch Hybrid Bonding and Mini-TSV. In 2023 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). 1–2. https://doi.org/10.23919/ VLSITechnologyandCir57934.2023.10185427
[73] xAI. 2024. Grok-2 Beta Release. https://x.ai/news/grok-2.
[74] xAI. 2024. Our Gigafactory of Compute:Colossus. https://x.ai/colossus.
[75] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi Tang, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. 2024. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115 (2024).
[76] Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. 2025. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. https: //arxiv.org/abs/2502.11089
[77] Chenggang Zhao, Liang Zhao, Jiashi Li, and Zhean Xu. 2025. DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling. https://github.com/ deepseek- ai/DeepGEMM.
[78] Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library. https://github.com/deepseek-ai/DeepEP.
[79] Size Zheng, Jin Fang, Xuegui Zheng, Qi Hou, Wenlei Bao, Ningxin Zheng, Ziheng Jiang, Dongyang Wang, Jianxi Ye, Haibin Lin, Li-Wen Chang, and Xin Liu. 2025. TileLink: Generating Efficient Compute-Communication Overlapping Kernels using Tile-Centric Primitives. arXiv:2503.20313 [cs.DC] https://arxiv.org/abs/ 2503.20313
[80] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 193–210. https://www.usenix.org/conference/osdi24/ presentation/zhong- yinmin
版权声明:
本文由 youcans@xidian 对论文 Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures 进行摘编和翻译,只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【DeepSeek论文精读】11. 洞察 DeepSeek-V3:扩展挑战和对 AI 架构硬件的思考
Copyright 2025 youcans, XIDIAN
Created:2025-05