Oracle 内存优化
Oracle 的内存可以按照共享和私有的角度分为系统全局区和进程全局区,也就是 SGA和 PGA(process global area or private global area)。对于 SGA 区域内的内存来说,是共享的全局的。在 UNIX 上,必须为 Oracle 设置共享内存段(可以是一个或者多个),因为 Oracle 在UNIX 上是多进程;而在 WINDOWS 上 Oracle 是单进程(多个线程),所以不用设置共享内存段。PGA 是属于进程(线程)私有的区域。在 Oracle 使用共享服务器模式下,PGA中的一部分,也就是 UGA 会被放入共享内存 large_pool_size 中。
对于 SGA 部分,通过查询语句可以看到,代码如下:
SQL> select * from v$sga;
执行后如图14-9所示。
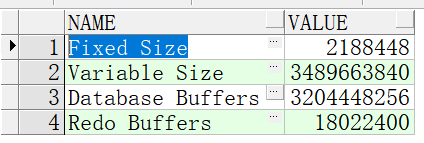
图14-9查询SGA使用情况
Fixed Size: Oracle 的不同平台和不同版本下可能不一样,但对于确定环境是一个固定的值,里面存储了 SGA 各部分组件的信息,可以看作引导建立 SGA 的区域。
Variable Size : 包含了 shared_pool_size、java_pool_size、large_pool_size 等内存设置。
Database Buffers : 指数据缓冲区。 在 9i 中 包 含 db_cache_size db_keep_cache_size、db_recycle_cache_size、db_nk_cache_size。
Redo Buffers : 指日志缓冲区,在这里说明一点的是,对于 v p a r a m e t e r 、 v parameter、v parameter、vsgastat、v s g a 查询值可能不一样。 v sga 查询值可能不一样。v sga查询值可能不一样。vparameter 里面的值,是指用户在初始化参数文件里面设置的值,v s g a s t a t 是 O r a c l e 实际分配的日志缓冲区大小 ( 因为缓冲区的分配值实际上是离散的,也不是以 b l o c k 为最小单位进行分配的 ) , v sgastat 是 Oracle 实际分配的日志缓冲区大小(因为缓冲区的分配值实际上是离散的,也不是以 block 为最小单位进行分配的), v sgastat是Oracle实际分配的日志缓冲区大小(因为缓冲区的分配值实际上是离散的,也不是以block为最小单位进行分配的),vsga 里面查询的值,是在 Oracle 分配了日志缓冲区后,为了保护日志缓冲区,设置了一些保护页,发现保护页大小大约是 11k(不同环境可能不一样)。
14.7.1SGA内参数及设置
(1)Log_buffer
对于日志缓冲区的大小设置,通常没有过多的建议,因为参考 LGWR 写的触发条件之后,发现通常超过 3M 意义不是很大。作为一个正式系统,可能考虑先设置这部分为 log_buffer=3到5M 大小,然后针对具体情况再调整。
log_buffer是Redo log的buffer。因此在这里必须要了解Redo Log的触发事件(LGWR)
当redo log buffer的容量达到1/3,设定的写redo log时间间隔到达,一般为3秒钟。
redo log buffer中重做日志容量到达1M,在DBWn将缓冲区中的数据写入到数据文件之前每一次提交事务。上面的结论可以换句话说:log_buffer中的内容满1/3,缓存刷新一次。最长间隔3秒钟,缓存刷新一次。log_buffer中的数据到达1M,缓存刷新一次。
每次提交一个事务,缓存刷新一次
(2)Large_pool_size
对于大缓冲池的设置,假如不使用 MTS,建议在 20-30M 足够了。这部分主要用来保存并行查询时候的一些信息,还有就是 RMAN 在备份的时候可能会使用到。
如果设置了MTS,则由于 UGA 部分要移入这里,则需要具体根据 server process 数量和相关会话内存参数的设置来综合考虑这部分大小的设置。
(3)Java_pool_size
假如数据库没有使用 JAVA,一般保留 10—20M 大小足够。事实上可以更少,甚至最少只需要 32k,但具体跟安装数据库的时候的组件相关。
(4)Shared_pool_size
Shared_pool_size的开销通常应该维持在300M 以内。除非系统使用了大量的存储过程、函数、包。比如 Oracle ERP 这样的应用,可能会达到 500M 甚至更高。于是假定一个 1G 内存的系统,可能考虑设置该参数为 100M,2G 的系统考虑设置为 150M,8G 的系统可以考虑设置为 200到300M。
(5)SGA_MAX_SIZE
SGA区包括了各种缓冲区和内存池,而大部分都可以通过特定的参数来指定他们的大小。但是作为一个昂贵的资源,一个系统的物理内存大小是有限。
尽管对于CPU的内存寻址来说,是无需关系实际的物理内存大小的(关于这一点,后面会做详细的介绍),但是过多的使用虚拟内存导致page in/out,
会大大影响系统的性能,甚至可能会导致系统crash。所以需要有一个参数来控制SGA使用虚拟内存的最大大小,这个参数就是SGA_MAX_SIZE。当实例启动后,各个内存区只分配实例所需要的最小大小,在随后的运行过程中,再根据需要扩展他们的大小,而他们的总和大小受到了SGA_MAX_SIZE的限制。
对于OLTP系统,内存大小见14-1表。
表14-1内存参数
系统内存 SGA_MAX_SIZE值
1G 400-500M
2G 1G
4G 2500M
8G 5G
(6)PRE_PAGE_SGA
Oracle实例启动时,会只载入各个内存区最小的大小。而其他SGA内存只作为虚拟内存分配,只有当进程touch到相应的页时,才会置换到物理内存中。但希望实例一启动后,所有SGA都分配到物理内存。这时就可以通过设置PRE_PAGE_SGA参数来达到目的了。这个参数的默认值为FALSE,即不将全部SGA置入物理内存中。当设置为TRUE时,实例启动会将全部SGA置入物理内存中。它可以使实例启动达到它的最大性能状态,但是,启动时间也会更长(因为为了使所有SGA都置入物理内存中,Oracle进程需要touch所有的SGA页)。
(7)LOCK_SGA
为了保证SGA都被锁定在物理内存中,而不必页入/页出,可以通过参数LOCK_SGA来控制。这个参数默认值为FALSE,当指定为TRUE时,可以将全部SGA都锁定在物理内存中。当然有些系统不支持内存锁定,这个参数也就无效了。
(8)SGA_TARGET
这里要介绍的时Oracle10g中引入的一个非常重要的参数。在10g之前,SGA的各个内存区的大小都需要通过各自的参数指定,并且都无法超过参数指定大小的值,尽管他们之和可能并没有达到SGA的最大限制。此外,一旦分配后,各个区的内存只能给本区使用,相互之间是不能共享的。
拿SGA中两个最重要的内存区Buffer Cache和Shared Pool来说,它们两个对实例的性能影响最大,但是就有这样的矛盾存在:在内存资源有限的情况下,某些时候数据被cache的需求非常大,了提高buffer hit,就需要增加Buffer Cache大小。但由于SGA有限,只能从其他区抢过来,增加Buffer Cache;而有时又有大块的PLSQL代码被解析驻入内存中,导致Shared Pool不足,甚至出现4031错误,又需要扩大Shared Pool,这时可能又需要人为干预,从Buffer Cache中将内存夺回来。 有了这个新的特性后,SGA中的这种内存矛盾就迎刃而解了。这一特性被称为自动共享内存管理。
而控制这一特性的,也就仅仅是这一个参数SGA_TARGE。设置这个参数后,就不需要为每个内存区来指定大小了。SGA_TARGET指定了SGA可以使用的最大内存大小,
而SGA中各个内存的大小由Oracle自行控制,不需要人为指定。Oracle可以随时调节各个区域的大小,使之达到系统性能最佳状态的个最合理大小,并且控制他们之和在SGA_TARGET指定的值之内。一旦给SGA_TARGET指定值后(默认为0,即没有启动ASMM),就自动启动了ASMM特性。
14.7.2ORALCE内存调整
当项目的生产环境出现性能问题,通过判断,对内存参数进行调整。
(1)检查Oracle实例的Library Cache命中率。标准:Library Cach一般是大于99%
检查方式,代码如下:
select 1-(sum(reloads)/sum(pins)) “Library cache Hit Ratio” from v$librarycache;
执行后如图14-10所示。

图14-10查询Library Cache命中率
处理措施:如果Library cache Hit Ratio的值低于99%,应调高shared_pool_size的大小。通过sqlplus连接数据库执行如下命令,调整shared_pool_size的大小,代码如下:
SQL>alter system flush shared_pool;
SQL>alter system set shared_pool_size=设定值 scope=spfile;
(2)检查Oracle实例的Data Buffer(数据缓冲区)命中率。
标准:一般是大于90%
检查方式,代码如下:
select 1 - (phy.value / (cur.value + con.value)) “HIT RATIO”
from v s y s s t a t c u r , v sysstat cur, v sysstatcur,vsysstat con, v$sysstat phy
where cur.name = ‘db block gets’
and con.name = ‘consistent gets’
and phy.name = ‘physical reads’
执行后如图14-11所示。
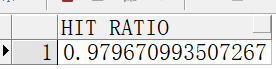
图14-11查看据缓冲区命中率
处理措施:如果HIT RATIO的值低于90%,应调高db_cache_size的大小。
调整db_cache_size的大小,代码如下:
SQL>alter system set db_cache_size=设定值 scope=spfile
(3)检查Oracle实例的Dictionary Cache命中率,一般是大于95%
检查方式,代码如下:
select 1 - (sum(getmisses) / sum(gets)) “Data Dictionary Hit Ratio”
from v r o w c a c h e ; 处理措施 : 如果 D a t a D i c t i o n a r y H i t R a t i o 的值低于 95 S Q L > a l t e r s y s t e m f l u s h s h a r e d p o o l ; S Q L > a l t e r s y s t e m s e t s h a r e d p o o l s i z e = 设定值 s c o p e = s p f i l e ; ( 4 ) 检查 O r a c l e 实例的 L o g B u f f e r 命中率,一般是小于 1 检查方式,代码如下: s e l e c t ( r e q . v a l u e ∗ 5000 ) / e n t r i e s . v a l u e " R a t i o " f r o m v rowcache; 处理措施:如果Data Dictionary Hit Ratio的值低于95%,应调高shared_pool_size的大小。通过sqlplus连接数据库执行如下命令,调整shared_pool_size大小代码如下: SQL>alter system flush shared_pool; SQL>alter system set shared_pool_size=设定值 scope=spfile; (4)检查Oracle实例的Log Buffer命中率,一般是小于1%。 检查方式,代码如下: select (req.value * 5000) / entries.value "Ratio" from v rowcache;处理措施:如果DataDictionaryHitRatio的值低于95SQL>altersystemflushsharedpool;SQL>altersystemsetsharedpoolsize=设定值scope=spfile;(4)检查Oracle实例的LogBuffer命中率,一般是小于1检查方式,代码如下:select(req.value∗5000)/entries.value"Ratio"fromvsysstat req, v s y s s t a t e n t r i e s w h e r e r e q . n a m e = ′ r e d o l o g s p a c e r e q u e s t s ′ a n d e n t r i e s . n a m e = ′ r e d o e n t r i e s ′ ; 处理措施 : 如果 R a t i o 高于 1 %,应调高 l o g b u f f e r 的大小。通过 s q l p l u s 连接数据库执行如下命令,调整 l o g b u f f e r 的大小代码如下: S Q L > a l t e r s y s t e m s e t l o g b u f f e r = 设定值 s c o p e = s p f i l e ; ( 5 ) 检查 u n d o r e t e n t i o n : : u n d o r e t e n t i o n 的值必须大于 m a x ( m a x q u e r y l e n ) 的值检查方式,代码如下: c o l u n d o r e t e n t i o n f o r m a t a 30 s e l e c t v a l u e " u n d o r e t e n t i o n " f r o m v sysstat entries where req.name = 'redo log space requests' and entries.name = 'redo entries'; 处理措施:如果Ratio高于1%,应调高log_buffer的大小。通过sqlplus连接数据库执行如下命令,调整log_buffer的大小代码如下: SQL>alter system set log_buffer=设定值 scope=spfile; (5)检查undo_retention::undo_retention 的值必须大于max(maxquerylen)的值 检查方式,代码如下: col undo_retention format a30 select value "undo_retention" from v sysstatentrieswherereq.name=′redologspacerequests′andentries.name=′redoentries′;处理措施:如果Ratio高于1%,应调高logbuffer的大小。通过sqlplus连接数据库执行如下命令,调整logbuffer的大小代码如下:SQL>altersystemsetlogbuffer=设定值scope=spfile;(5)检查undoretention::undoretention的值必须大于max(maxquerylen)的值检查方式,代码如下:colundoretentionformata30selectvalue"undoretention"fromvparameter where name=‘undo_retention’;
select max(maxquerylen) From v$undostat Where begin_time>sysdate-(1/4);
处理措施:如果不满足要求,需要调高undo_retention 的值。
调整undo_retention 的大小,代码如下:
SQL>alter system set undo_retention= 设定值 scope=spfile;
对于 Oracle 来说,存在着 32bit 与 64bit 的问题。这个问题影响到的主要是 SGA 的大小。在 32bit 的数据库下,通常 Oracle 只能使用不超过 1.7G 的内存,即使拥有12G 的内存,但是却只能使用 1.7G,这是一个莫大的遗憾。假如安装 64bit 的数据库,就可以使用很大的内存,几乎不可能达到上限。但是 64bit 的数据库必须安装在 64bit 的操作系统上。