SuperYOLO:多模态遥感图像中的超分辨率辅助目标检测之论文阅读
摘要
在遥感影像(RSI)中,准确且及时地检测包含数十像素的多尺度小目标仍具有挑战性。现有大多数方法主要通过设计复杂的深度神经网络来学习目标与背景的区分特征,常导致计算量过大。本文提出一种兼顾检测精度与计算代价的快速准确的遥感目标检测方法,称为 SuperYOLO。该方法融合多模态数据,并通过借助超分辨率(SR)学习,在低分辨率(LR)输入下实现多尺度目标的高分辨率(HR)检测。首先,我们设计了对称紧凑的多模态融合(MF)模块,从多种数据中提取补充信息,以提升遥感图像中小目标的检测效果。其次,我们构建了简单灵活的超分支(SR branch),在训练阶段学习可区分小目标与广阔背景的高分辨率特征,进一步提高检测精度。另外,为避免增加推理阶段的计算开销,SR 分支仅在训练时使用,推理时予以丢弃,且因输入为低分辨率图像而减少网络整体计算量。实验结果表明,在常用的 VEDAI 遥感数据集上,SuperYOLO 在 mAP50 指标上达到了 75.09%,较 YOLOv5l、YOLOv5x 及专为遥感设计的 YOLOrs 等大型模型提高了超过 10%。同时,SuperYOLO 的参数量和 GFLOPs 分别约为 YOLOv5x 的 1/18 和 1/3.8。所提模型在精度–速度权衡方面优于现有最先进方法。代码将开源于:https://github.com/icey-zhang/SuperYOLO。
I. 引言
目标检测在计算机辅助诊断、无人驾驶等诸多领域具有重要作用。过去数十年间,基于深度神经网络(DNN)的多种优秀目标检测框架[1–5]相继被提出与优化,且在大规模自然图像数据集及其精确标注的推动下,检测精度显著提升[6–8]。
与自然场景相比,遥感影像(RSI)目标检测面临若干关键挑战:
标注样本数量较少,限制了 DNN 的训练效果;
RSI 中目标尺寸极小,仅占数十像素,相对于复杂广阔的背景极易被淹没[9,10];
目标尺度多样,不同类别间存在显著差异[11]。
如图 1(a)所示,汽车在广阔区域中非常微小;如图 1(b)所示,相较于房车(camping vehicle),汽车尺度更小且变化多端。
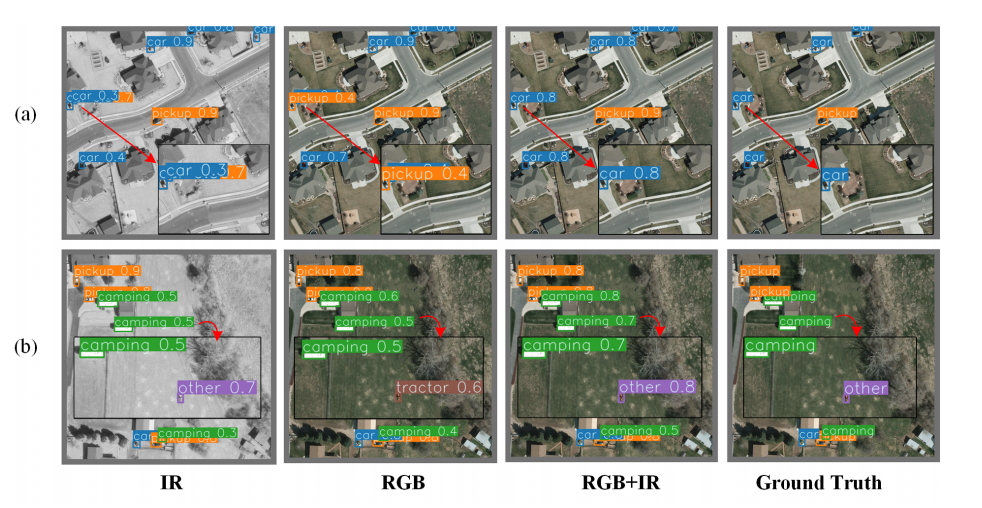
图1 RGB图像、IR图像和ground truth (GT)的视觉对比。红外图像为解决RGB检测中的难题提供了重要的补充信息。(a)中的物体在广阔的区域内相当小。在(b)中,物体有较大的变化,其中汽车的规模小于露营车的规模。RGB和IR模态的融合有效地提高了检测性能。
当前多数检测技术仅针对单一模态(如 RGB 或红外 IR)[12,13],难以利用不同模态间的互补信息提升地表目标识别能力[14]。随着成像技术发展,多模态遥感数据日益可得,为提高检测精度提供了契机。例如,将 RGB 与 IR 融合,可有效增强遥感小目标的可检测性。另一方面,某些模态分辨率偏低,需要通过超分辨率技术提升图像细节。近期超分辨率方法在遥感领域展现出巨大潜力[15–18],但基于 CNN 的高性能 SR 网络计算开销大,其在实时应用中的落地仍具挑战。
本研究旨在提出一款用于多模态遥感的实时高效目标检测框架,在保证高精度与高速推理的前提下,不增加额外计算负担。受轻量化实时神经网络的启发,我们以小型 YOLOv5s[19] 作为检测基线,其可降低部署成本并加速模型落地。考虑到小目标对高分辨率(HR)特征的需求,我们移除基线模型中的 Focus 模块,不仅有利于小而密集目标的定位,也提升了检测性能。我们提出如下关键技术:
像素级对称紧凑融合(MF)——在低计算代价下,高效地双向融合 RGB 与 IR 等多模态信息,相较于特征级融合进一步节省计算且不损失精度;
辅助超分辨率分支(SR branch)——在训练阶段引入 SR 任务,引导网络生成能区分小目标与背景的 HR 特征,有效减少背景误报;
无额外推理开销——SR 分支仅作为辅助任务,训练后舍弃,推理时保持低分辨率输入,实现 HR 空间信息提取而不增加计算;
优异的精度–速度权衡——SuperYOLO 在 VEDAI 数据集上显著超越现有实时及大型模型,提升超过 10% mAP50,且参数量和 FLOPs 大幅降低。
后续章节将依次介绍相关工作、方法细节、实验结果及分析。
A. 基于多模态数据的目标检测
近年来,多模态数据已在众多实际应用场景中得到广泛应用,包括视觉问答[20]、自动驾驶车辆[21]、显著性检测[22]以及遥感图像分类[23]。研究表明,将多模态数据的内部信息进行融合,能够有效传递互补特征,避免单一模态信息的遗漏。 在遥感影像(RSI)处理领域,来自不同传感器的多种模态(如红-绿-蓝(RGB)、合成孔径雷达(SAR)、激光雷达(LiDAR)、红外(IR)、全色(PAN)和多光谱(MS)影像)可相互补充,以提升各类任务的性能[24–26]。例如,附加的红外模态可捕获更长的热波段,在恶劣天气下提升检测能力[27]。Manish 等人[27]提出了一种多模态遥感影像实时目标检测框架,其扩展版本在中层融合阶段合并了多种模态数据。尽管多传感器融合如图 1所示能够提升检测性能,但其较低的检测精度和亟待提升的计算速度难以满足实时检测的需求。
融合方法主要分为三类:像素级融合、特征级融合和决策级融合[28]。决策级融合在最后阶段合并各分支检测结果,可能因对每个模态分支重复计算而消耗大量资源。在遥感领域,特征级融合被广泛采用:将多模态影像分别输入并行分支,提取各自特征后通过注意力机制或简单拼接等操作融合。但随着模态数增多,并行分支带来成倍的计算开销,不利于实时应用。
相比之下,像素级融合能够减少不必要的计算。本文中,我们的 SuperYOLO 在像素级对多模态进行融合,通过空间和通道域的高效操作挖掘不同模态间的内部互补信息,在大幅降低计算成本的同时提升检测精度。
B. 目标检测中的超分辨率
近期研究表明,多尺度特征学习[29,30]和基于上下文的检测[31]能够改善小目标检测性能,但这些方法往往侧重于多尺度信息的表示,而忽略了高分辨率上下文信息的保留。作为预处理手段,超分辨率(SR)已在多种目标检测任务中得到验证[32,33]。Shermeyer 等人[34]通过对不同分辨率的遥感影像进行检测实验,量化了 SR 对检测性能的影响。Courtrai 等人[35]基于生成对抗网络(GAN)生成高分辨率图像,并将其送入检测器以提升性能。Rabbi 等人[36]利用拉普拉斯算子提取输入图像的边缘,以加强高分辨率重建,从而改善目标定位与分类。Hong 等人[37]引入循环一致性 GAN 架构作为 SR 网络,并在 Faster R-CNN 中进行改进,用于检测由 SR 网络生成的增强图像中的车辆。这些工作表明,SR 结构能有效应对小目标检测难题,但由于输入图像分辨率增大,必然带来额外计算开销。
近期,Wang 等人[38]在语义分割任务中提出了一种 SR 模块,能够在低分辨率输入下保持高分辨率表示的同时减少计算量。受此启发,我们设计了一个辅助 SR 分支。与上述在网络初始阶段即进行 SR 的方法不同,本工作中的辅助 SR 模块在训练过程中引导检测主干学习高质量的高分辨率特征,不仅增强了小而密集目标的响应,也提升了空间域目标检测性能。更重要的是,该 SR 分支仅作为训练时的辅助任务,在推理阶段被移除,从而避免了任何额外计算。
III. 基线结构
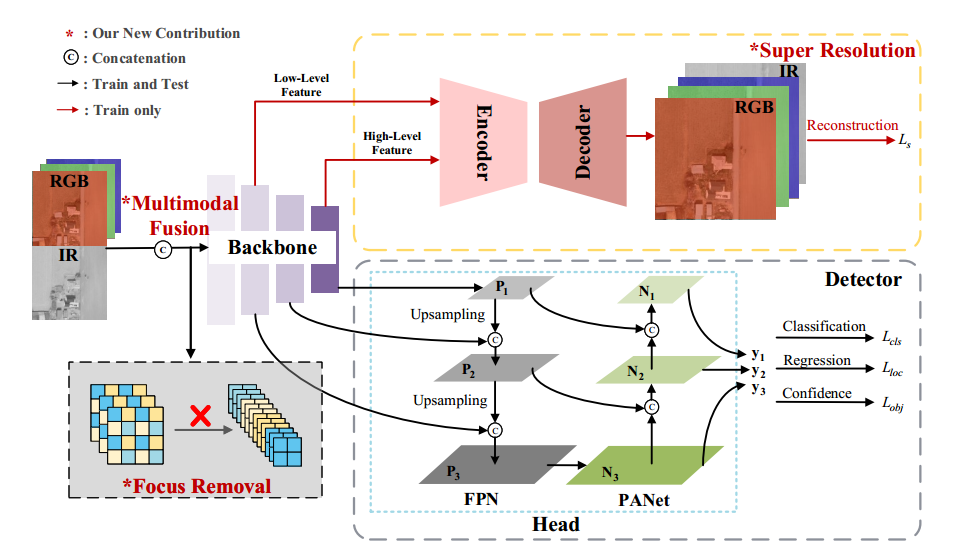
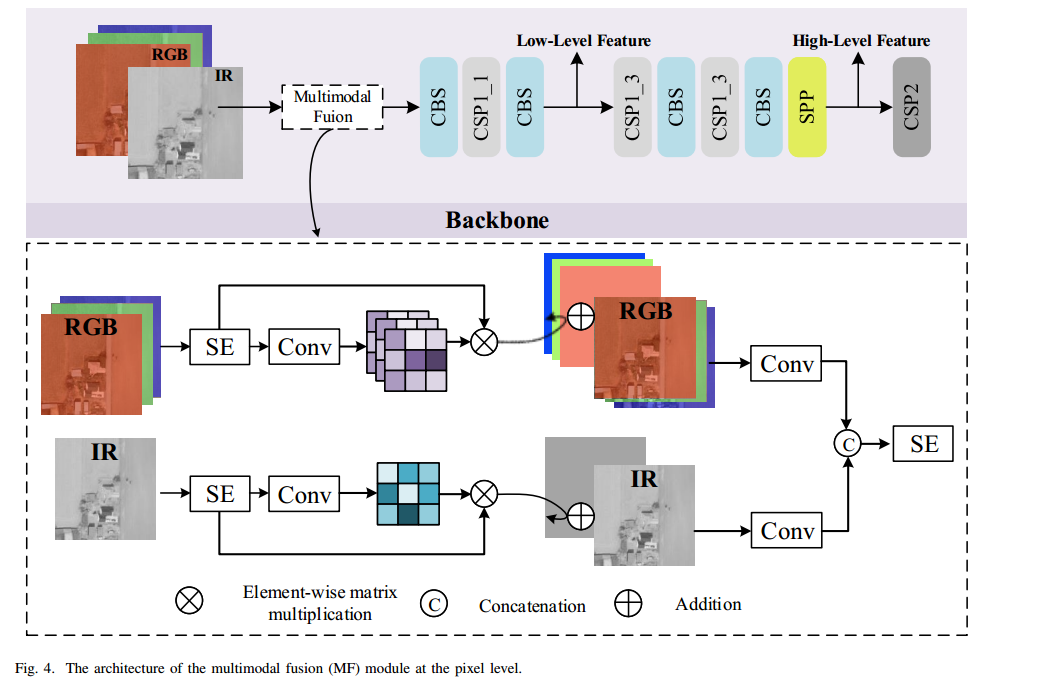
如图 2 所示,基线 YOLOv5 网络主要由两部分构成:Backbone(主干)和 Head(包括 Neck)。主干用于提取低层次的纹理特征和高层次的语义特征。随后,这些特征被送入 Head:先自上而下构建增强的特征金字塔,将强语义信息向下传递;再自下而上将局部纹理和模式特征的响应向上聚合。这样便通过多尺度特征融合,解决了目标尺度多样化的问题,提升了检测性能。
在图 3 中,Backbone 采用 CSPNet[39],由多个 CBS(Convolution‑BatchNorm‑SiLu)模块和 CSP(Cross Stage Partial)模块组成。CBS 包含卷积、批归一化及 SiLu 激活[40]三步操作。CSP 则将上一层的特征图复制为两份,分别通过 1×1 卷积将通道数减半以降低计算量。其中一份特征直接连接到该阶段末端,另一份送入若干 ResNet 或 CBS 块进行进一步处理,最后再在通道维度拼接并经过一个 CBS 块融合特征。SPP(Spatial Pyramid Pooling)模块[41]由多个不同核尺寸的并行最大池化层组成,用以提取多尺度深层特征。通过堆叠 CSP、CBS 和 SPP 结构,网络能够同时获得低级纹理和高级语义信息。
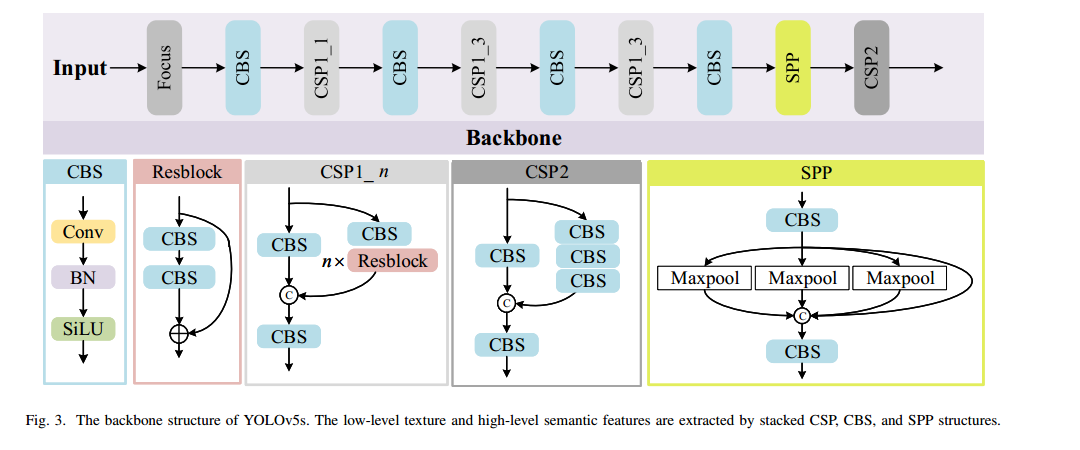
局限 1:YOLOv5 中引入了 Focus 模块以减少计算量。如图 2(左下)所示,该模块将输入按像素交错切分并隔行重排,最后在通道维度拼接,实现输入的下采样,从而加速训练与推理。但此操作在一定程度上牺牲了分辨率,容易对小目标检测精度造成影响。
局限 2:YOLO 主干通过多次步幅为 2 的深度卷积将特征图尺寸不断减半,因此多尺度检测所保留的特征图远小于原始输入图像。例如,输入尺寸为 608×608 时,最后三个检测层的特征图尺寸仅为 76×76、38×38 和 19×19。低分辨率特征可能导致部分小目标遗漏。
IV. SUPERYOLO 架构
如图 2 所示,SuperYOLO 在基线结构基础上引入三项改进:
移除 Focus 模块并替换为 MF 模块,避免因下采样重组而导致的分辨率和精度下降;
选择高效的像素级融合,在像素层面融合 RGB 与 IR 模态,提取互补信息;
训练阶段添加辅助 SR 模块,重建高分辨率图像以指导主干网络在空间维度学习并保留 HR 信息,推理阶段舍弃该分支以免增加计算开销。
A. 移除 Focus
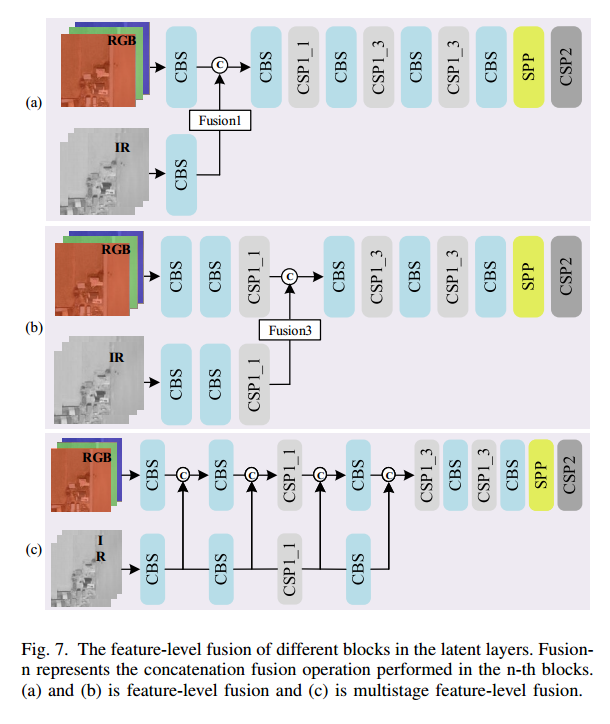
如第 III 节及图 2(左下)所示,YOLOv5 主干中的 Focus 模块通过空间域的间隔采样将输入图像切分重组,从而在通道维度拼接得到下采样图像。该操作虽能减少计算量并加速训练与推理,但会引起分辨率下降,导致小目标的空间信息丢失。鉴于小目标检测对高分辨率的依赖,我们舍弃 Focus,采用如图 4 所示的 MF 模块,以保持输入分辨率。
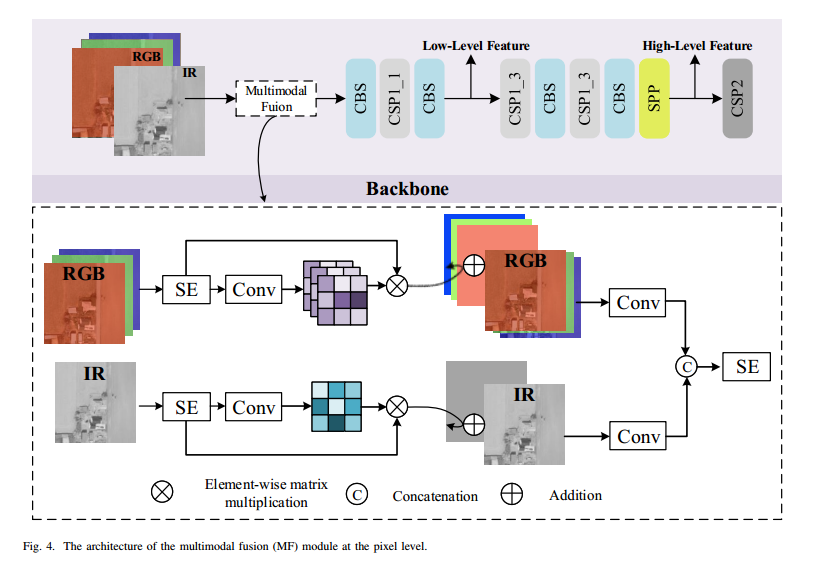
B. 多模态融合
利用更多信息有助于提升目标检测性能。多模态融合是将来自不同传感器的信息进行合并的有效途径。主流融合方法包括决策级、特征级和像素级融合。由于决策级融合需对各模态分支重复检测,计算开销过大,故不在 SuperYOLO 中采用。
我们提出一种像素级多模态融合(MF),以对称紧凑的方式双向提取不同模态的共享与特色信息。其流程如图 4 所示:
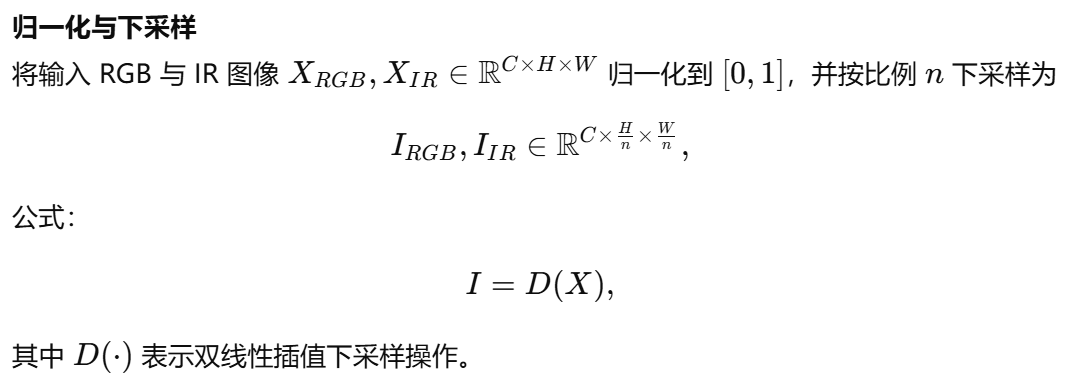


C. 超分辨率(Super Resolution)
如第 III 节所述,骨干网络中用于多尺度检测的特征尺寸远小于原始输入图像。现有大多数方法通过上采样操作来恢复特征尺寸,但由于纹理和模式信息在上采样过程中丢失,因此在遥感图像中检测需要高分辨率(HR)保留的小目标时,效果并不理想。
为了解决这一问题,如图 2 所示,我们引入了一个辅助的 SR 分支。该分支的设计目标有二:
帮助骨干网络提取更多的高分辨率信息,以提升检测性能;
不显著增加计算量,以保证推理速度。
因此,在推理阶段,它能够在准确性和计算时间之间取得平衡。受 Wang 等人 [38] 研究启发——其提出的 SR 方法在无需额外开销的情况下促进了分割任务——我们在框架中引入了一个简单而高效的 SR 分支。该设计在不增加计算和内存负担的前提下提升了检测精度,尤其当输入分辨率较低(LR)时效果尤为显著。
具体而言,该 SR 结构可视为一个简易的编码-解码(Encode-Decoder)模型。我们分别选取骨干网络的低层特征和高层特征,以融合局部纹理/模式信息和语义信息。如图 4 所示,我们将第 4 模块和第 9 模块的输出分别作为低层和高层特征。编码器部分将这两类特征进行集成:
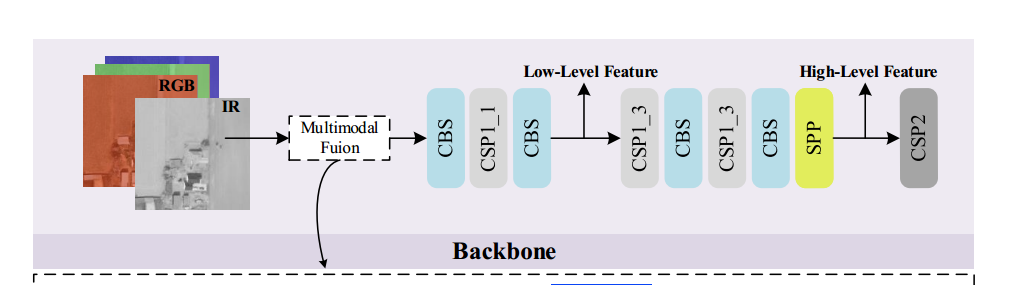
低层特征处理:对低层特征先进行一个 CR 模块(卷积 + ReLU);
高层特征处理:先通过上采样操作将其空间尺寸与低层特征对齐,再与低层特征拼接,随后依次经过两个 CR 模块融合。
在解码器部分,LR 特征被放大到 HR 空间,最终的 SR 输出尺寸是输入图像尺寸的两倍。如图 5 所示,解码器由三个反卷积层(deconvolutional layers)构成。SR 分支通过学习空间维度的映射,将高分辨率信息传递回主干分支,从而提升目标检测性能。此外,我们还尝试将 EDSR [43] 作为编码器,以探索 SR 表现及其对检测性能的影响。
为了更直观地说明效果,我们在图 6 中可视化了 YOLOv5s、YOLOv5x 和 SuperYOLO 的骨干特征。所有特征均上采样至与输入图像相同的尺度进行对比。通过对比图 6 中(c)、(f)与(i);(d)、(g)与(j);(e)、(h)与(k)的成对图像,可以观察到在 SR 分支的辅助下,SuperYOLO 所提取的物体结构更清晰、分辨率更高。最终,我们通过 SR 分支在高质量 HR 表征上获得了丰硕成果,并使用 YOLOv5 的 Head 进行小目标检测。

图6所示。相同输入的YOLOv5s、YOLOv5x和SuperYOLO主干特征级可视化:(a) RGB输入,(b) IR输入;©、(d)、(e)为YOLOv5s的特征;(f)、(g)、(h)为YOLOv5x的特征;(i)、(i)、(k)为SuperYOLO的特征。特征被上采样到与输入图像相同的尺度以进行比较。©、(f)和(i)是第一层的特征。(d)、(g)、(j)为底层特征。(e)、(h)、(k)为同一深度各层的高层特征。
D、损失函数

实验结果


D. 消融实验
首先,我们通过一系列在验证集第一折上进行的消融实验来验证所提方法的有效性。
基线框架验证
在表 I 中,我们从层数、参数量和 GFLOPs 三个方面评估了不同基础检测框架的模型规模和推理能力,并以 mAP50(IOU = 0.5 下的平均精度)衡量其检测性能。虽然 YOLOv4 的检测精度最高,但其层数比 YOLOv5s 多 169 层(393 vs. 224),参数量是 YOLOv5s 的 7.4 倍(52.5M vs. 7.1M),GFLOPs 是 YOLOv5s 的 7.2 倍(38.2 vs. 5.3)。相比之下,YOLOv5s 的 mAP 略低于 YOLOv4 和 YOLOv5m,但其层数、参数量和 GFLOPs 均远小于其他模型,更易于落地部署并实现实时推理。上述事实验证了以 YOLOv5s 为基线检测框架的合理性。
移除 Focus 模块的影响
如第 IV-A 节所述,Focus 模块会降低输入分辨率,不利于遥感图像中小目标的检测。我们在四种 YOLOv5 框架(s/m/l/x)上进行了对比实验(此处结果均在 RGB 与 IR 像素级拼接融合后获得)。表 II 显示,移除 Focus 后,YOLOv5s 的 mAP50 从 62.2% 提升至 69.5%,YOLOv5m 从 64.5% 提升至 72.2%,YOLOv5l 从 63.7% 提升至 72.5%,YOLOv5x 从 64.0% 提升至 69.2%。这是因为移除 Focus 后既避免了分辨率下降,又保留了小目标的空间间隔信息,从而减少了漏检。总体而言,移除 Focus 模块可让各框架的 mAP50 提升超过 5%
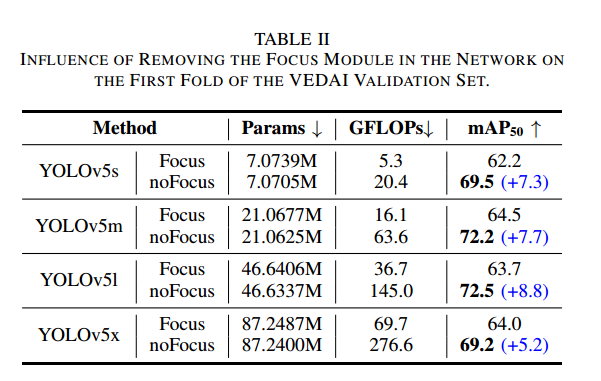
与此同时,移除 Focus 会带来推理计算量(GFLOPs)的增加:YOLOv5s 从 5.3 增至 20.4,YOLOv5m 从 16.1 增至 63.6,YOLOv5l 从 36.7 增至 145,YOLOv5x 从 69.7 增至 276.6。但即便如此,YOLOv5s-noFocus 的 20.4 GFLOPs 仍低于 YOLOv3(52.8)、YOLOv4(38.2)和 YOLOrs(46.4)的计算量;移除 Focus 后模型参数也略有减少。综上,为了在检测更小目标时保留高分辨率,应以检测精度为优先,采用卷积替代 Focus 模块。
不同融合方式比较
为评估各融合方法的效果,我们在 YOLOv5-noFocus 上比较了五种融合结果(详见第 IV-B 节与图 7)。fusion1–fusion4 分别表示在第 1、2、3、4 个块中进行的像素级拼接融合;在特征级融合中,将 IR 图像扩展为三通道以与 RGB 保持一致。表 III 中列出了不同方法的参数量、GFLOPs 和 mAP50:
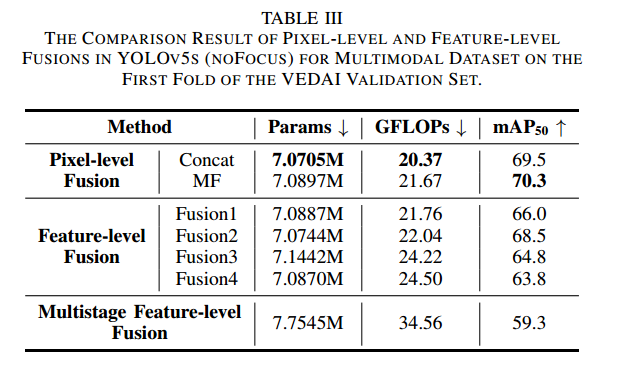
像素级拼接:7.0705M 参数,20.37 GFLOPs,69.5% mAP50
像素级 MF 模块:7.0897M 参数,21.67 GFLOPs,70.3% mAP50(最佳)
特征级融合的参数量接近像素级融合,原因在于其融合发生在中间层,而非双模型最前端;且各融合前模块不同,导致通道数与参数量略异。实验还对比了多阶段特征级融合(图 7©)与像素级融合:其 mAP50 仅为 59.3%,计算量为 34.56 GFLOPs,参数量 7.7545M,均高于像素级融合。这表明像素级创新融合在保持低计算成本的同时,更能有效提升检测精度。最终,我们仅采用像素级融合以确保最低的计算开销。
高分辨率影响
我们在表 IV 中比较了不同训练/测试分辨率组合的性能。在训练和测试分辨率相同的情况下,将 YOLOv5s 的输入从 512→1024 后,mAP50 从 62.2% 提升至 77.7%(增幅 15.5%),GFLOPs 从 5.3 增至 21.3。同理,YOLOv5s-noFocus(1024)较(512)提升 9.8%(79.3% vs. 69.5%)。这说明提高输入分辨率可同时提高召回率和精度,减少漏检与误检。然而,高分辨率也带来更高计算量:YOLOv5s 的 GFLOPs 从 5.3→21.3;YOLOv5s-noFocus 从 20.4→81.5。
当训练/测试分辨率不一致时,mAP50 显著下降(如 10.6% vs. 62.2%、48.2% vs. 77.7%、13.4% vs. 69.5%、62.9% vs. 79.3%),可能因训练与测试时目标尺度不匹配,导致预测框尺寸不再适合测试图像中的目标。
最后,YOLOv5s-noFocus+SR 在 512×512 分辨率下的 mAP50 达到 78.0%,接近 YOLOv5s-noFocus(1024)的 79.3%,且 GFLOPs 仅为 20.4(等同于 LR 512 下的值)。这表明所提 SR 分支能够在测试阶段通过下采样降低计算量,同时保持与高分辨率输入相当的检测精度,充分体现了其优势。
- 超分辨率分支的影响
表 V 中列出了一些关于 SR 分支的消融实验结果。与普通的上采样操作相比,加入超分辨率网络的 YOLOv5s-noFocus 在 mAP50 上提升了 1.8%。这是因为 SR 网络是一种可学习的上采样方式,具有更强的重建能力,能够帮助骨干网络提取更丰富的特征以提升检测效果。
此外,我们在主干网络中删除了 PANet 结构及负责中尺度和大尺度目标检测的两个检测头,因为在诸如 VEDAI 的遥感小目标数据集中,仅使用小尺度检测头即可满足需求。仅保留一个检测头后,模型参数量可从 7.0705M 降至 4.8259M,GFLOPs 从 20.37 降至 16.68,同时 mAP50 从 78.0% 提升至 79.0%。
当我们在 SR 分支中用 EDSR 网络替代三层反卷积解码器,并用 L1 损失替换原先的 L2 损失时,SR 分支在超分重建任务上的表现得到进一步加强,且对检测主干的特征提取也起到了更有力的辅助作用,加速了检测网络的收敛,从而进一步提升了整体检测性能。这表明超分辨率与目标检测两者在特征提取层面是互补且协同增效的。
表 VI 展示了在不同基线网络上加入 SR 分支后的精度-复杂度折中效果。与各自的“裸”基线相比,加入 SR 分支后:
YOLOv3+SR 的 mAP50 比 YOLOv3 提升了 9.2%;
YOLOv4+SR 的 mAP50 比 YOLOv4 提升了 3.3%;
YOLOv5s+SR 的 mAP50 比 YOLOv5s 提升了 2.2%。
值得注意的是,SR 分支在推理阶段可以被移除,因此并不会引入额外的参数或计算开销。这一点尤为难得,因为 SR 分支无需对检测网络进行大规模重构即可带来显著增益。该 SR 分支具备良好的通用性和可扩展性,可直接嵌入到现有的全卷积网络(FCN)框架中。
E. 与现有方法的比较
图 8 展示了在多种场景下,YOLO 系列方法与 SuperYOLO 的可视化检测结果。可以看出,SuperYOLO 能准确检测出在 YOLOv4、YOLOv5s 和 YOLOv5m 中漏检、误分类或模糊识别的目标。遥感图像中的小目标检测难度较大,尤其是 Pickup 与 Car、Van 与 Boat 等外观相似的类别易被混淆。因此,除了定位精度外,提高检测分类性能在该任务中尤为必要,而所提 SuperYOLO 在此方面表现优异。
表 VII 汇总了 YOLOv3 [47]、YOLOv4 [48]、YOLOv5s-x [19]、YOLOrs [27]、YOLO-Fine [49]、YOLOFusion [50] 及本文 SuperYOLO 的检测性能。可见,多模态(RGB+IR)模式下的大多数类别 AP 明显高于单模态(仅 RGB 或 IR),整体 mAP50 亦优于单一模态。这进一步验证了多模态融合通过信息互补提升目标检测效果的有效性。然而,多模态融合所带来的参数与计算量的略微增加,也凸显了像素级融合优于特征级融合的必要性。
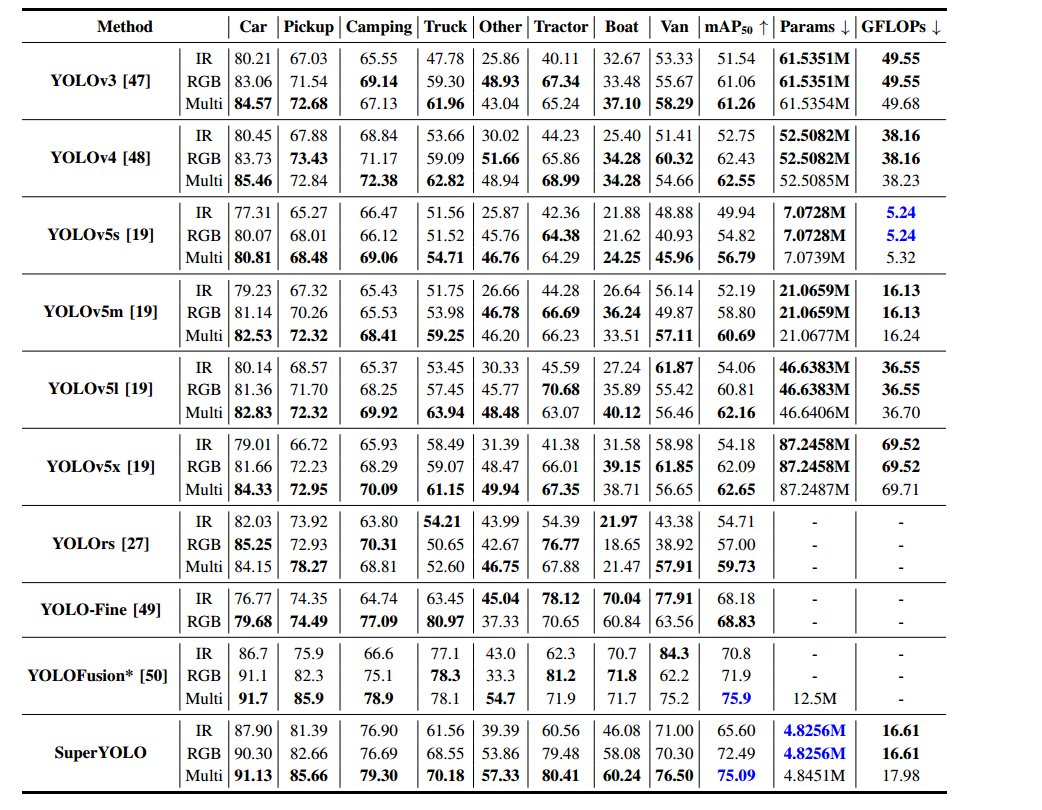
在整体 mAP50 上,SuperYOLO 超越了所有对比框架(YOLOFusion 除外)。YOLOFusion 略胜一筹,因其使用了在 MS COCO [7] 上预训练的权重,但其参数量约为 SuperYOLO 的三倍。YOLO-Fine 在单模态下表现良好,但缺乏多模态融合技术的开发。值得注意的是,在多模态模式下,SuperYOLO 相比 YOLOv5x 提升了 12.44% 的 mAP50,同时参数量和 GFLOPs 分别仅为 YOLOv5x 的约 1/18 和 1/3.8。
此外,Car、Pickup、Tractor 和 Camping 等训练样本最多的类别上,SuperYOLO 的性能提升尤为显著。YOLOv5s 虽在 GFLOPs 上占优(得益于 Focus 模块压缩输入),却在小目标检测上性能欠佳,SuperYOLO 相较于其提升了 18.30% 的 mAP50。总体来看,所提 SuperYOLO 在速度—精度折中方面,相较于最先进的方法展现了优异的性能。
F. 在单模遥感图像上的泛化能力
目前,虽然遥感领域存在大量的多模态图像,但因人工标注成本高昂,目标检测任务的标注数据集仍然匮乏。为验证所提网络的泛化能力,我们选取三个单模态大规模数据集——DOTA、DIOR 和 NWPU VHR-10,与多种一阶/二阶检测方法进行对比。
DOTA
提出时间:2018 年,专为遥感图像目标检测设计。
数据规模:包含 2,806 幅大图,共 188,282 个标注实例,分 15 类。
原图尺寸:4,000×4,000 像素;实验中裁剪为 1,024×1,024,重叠 200 像素。
划分方式:1/2 原图作训练,1/6 作验证,1/3 作测试;输入尺寸统一为 512×512。
NWPU VHR-10
提出时间:2016 年。
数据规模:800 幅图像,其中 650 幅含有目标;采用 520 幅作训练,130 幅作测试。
类别数:10 类;输入尺寸固定为 512×512。
DIOR
提出时间:2020 年。
数据规模:23,463 幅图像,192,472 个实例。
划分方式:11,725 幅训练,11,738 幅测试;输入尺寸统一为 512×512。
为适应上述数据集,我们对训练配置做了如下调整:NWPU VHR-10 与 DIOR 训练 150 个 epoch,DOTA 训练 100 个 epoch;批量大小:DOTA、DIOR 为 16,NWPU 为 8。
对比方法
我们选用了 11 种代表性方法进行对比,包括:
一阶段算法:YOLOv3 [47]、FCOS [53]、ATSS [54]、RetinaNet [51]、GFL [52]
两阶段方法:Faster R-CNN [5]
轻量化模型:MobileNetV2 [55]、ShuffleNet [56]
蒸馏方法:ARSD [59]
专为遥感设计:FMSSD [58]、O2DNet [57]
对比结果(表 VIII)
在 DOTA、NWPU VHR-10、DIOR 三个数据集上,SuperYOLO 分别达到了 69.99%、93.30% 和 71.82% 的 mAP50,模型参数(7.70 M、7.68 M、7.70 M)与 GFLOPs(20.89、20.86、20.93)均远低于其他最先进检测器。
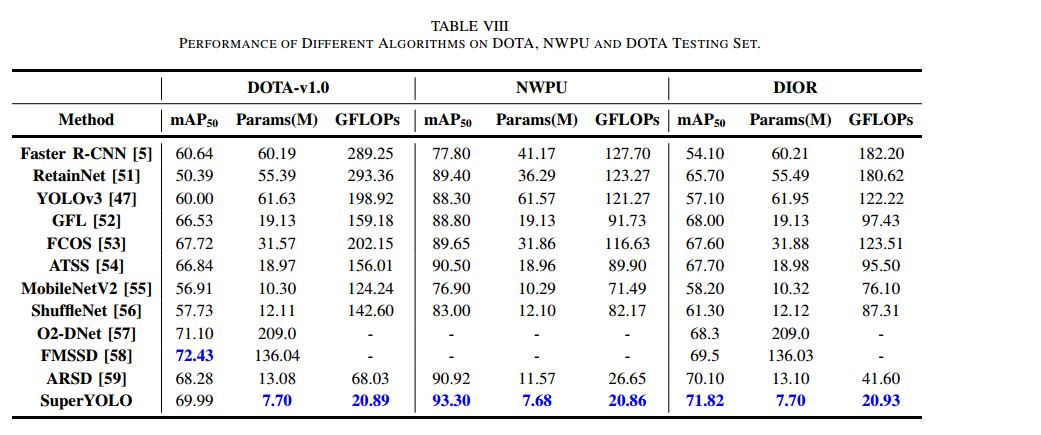
由于这些数据集中存在较大尺度目标(如操场等),我们在 SuperYOLO 中保留了 PANet 结构及三路检测头以增强对小、中、大尺度目标的检测能力,因此其参数量相较于表 VII 中的多模态实验略有增加。虽然 FMSSD 和 O2DNet 在性能上与我们的轻量级模型相近,但二者的参数量和 GFLOPs 均大幅超出,计算资源开销巨大。相比之下,SuperYOLO 在检测效率和准确率之间取得了更优的平衡。
VI. 结论与未来工作
在本文中,我们提出了 SuperYOLO,一种基于广泛使用的 YOLOv5s 的实时轻量化网络,旨在提升遥感图像中小目标的检测性能。首先,我们通过移除 Focus 模块以避免分辨率下降,显著改善了基线网络,减少了小目标的漏检;其次,我们研究了多模态融合技术,通过信息互补进一步提升检测效果;最关键的是,我们引入了一个简单灵活的超分辨率(SR)分支,帮助骨干网络构建高分辨率特征表示,使得仅凭低分辨率输入也能轻松识别大背景下的小目标。我们在推理阶段移除了 SR 分支,保持原网络结构和相同的 GFLOPs,实现了不增加计算量的高精度检测。通过以上多项创新,SuperYOLO 在 VEDAI 数据集上以更低的计算开销达到了 75.09% 的 mAP50,相较于 YOLOv5s 提升了 18.30%,相比 YOLOv5x 提升了超过 12.44%。
我们的方法在性能和推理效率上均体现了超分辨率技术在遥感任务中的价值,为多模态目标检测的未来研究开辟了新方向。未来工作中,我们将聚焦于设计更低参数量的高分辨率特征提取模式,以进一步满足实时性和高精度的双重需求