异常日志规范
目录
一、错误码
二、异常处理
三、日志规约
一、错误码
强制:
1、错误码的制订原则:快速溯源、沟通标准化。
1)错误码必须能够快速知晓错误来源,可快速判断是谁的问题。
2)错误码必须能够清晰地比对(代码中容易equals)。
3)错误码有利于团队快速对错误原因达成一致。
2、错误码不体现版本号和错误等级信息。
说明:错误码以不断追加的方式进行兼容。错误等级由日志和错误码本身的释义决定。
3、当全部正常,但不得不填充错误码时,返回五个零(00000)。
4、错误码为字符串类型,共5位,分为错误产生来源、四位数字编号两部分。
说明:错误产生来源分为A、B、C三种,
A表示错误来源于用户,例如参数错误、用户安装版本过低、用户支付超时等;
B表示错误来源于当前系统,例如业务逻辑出错、程序健壮性差等;
C表示错误来源于第三方服务,例如CDN服务出错、消息投递超时等;
四位数字编号从0001到9999,大类之间的步长间距预留100。
5、编号不与公司业务架构和组织架构挂钩,以先到先得为原则在统一平台上办理,一旦审批生效,编号即被永久固定。
6、错误码使用者避免随意定义新的错误码。
说明:在代码中使用错误码时,尽可能在原有错误码附表中找到语义相同或者相近的错误码。
7、错误码不能直接输出给用户作为提示信息使用。
说明:堆栈、错误码(errorCode)、错误信息(errorMessage)、提示信息(userTip)是一个有效关联并互相转义的和谐整体,但请勿越俎代庖。
推荐:
1、errorCode之外的业务独特信息由errorMessage承载,不要让errorCode本身涵盖过多的具体业务属性。
2、在获取第三方服务错误时,向上抛出允许本系统转义,由C转为B,并且在错误信息上带上原有的errorCode。
参考:
1、错误码分为一级宏观错误码、二级宏观错误码、三级宏观错误码。
说明:在无法确定的错误场景中,可以直接使用一级宏观错误码,分别是:A0001(用户端错误)、B0001(系统执行出错)、C0001(调用第三方服务出错)。
正例:调用第三方服务出错是一级,中间件出错是二级,消息服务出错是三级。
2、错误码的后三位数字与HTTP状态码没有任何关系。
3、错误码尽量有利于具有不同文化背景的开发者进行交流与代码协作。
说明:英文单词形式的错误码不利于非英语母语国家(如阿拉伯语国家、希伯来语国家、俄罗斯语国家等)的开发者之间互相协作。
4、错误码即人性,感性认知+口口相传,使用纯数字编排错误码不利于感性记忆和分类。
二、异常处理
强制:
1、Java类库中定义的可以通过预检查方式规避的RuntimeException不应该通过catch的方式处理,如:NullPointerException、IndexOutOfBoundsException等。
说明:无法通过预检查的异常不在此列,比如当解析字符串形式的数字时,可能存在数字格式错误,通过catch NumberFormatException实现。

2、异常被捕获后不要用来做流程控制和条件控制。
说明:异常设计的初衷是解决程序运行中的各种意外,且异常的处理效率比条件判断方式要低很多。
3、catch时请分清稳定代码和非稳定代码。稳定代码一般指本机运行且执行结果确定性高的代码。对于非稳定代码的catch,尽可能在进行异常类型的区分后,再做对应的异常处理。
说明:对大段代码进行try-catch,将使程序无法根据不同的异常做出正确的“应激”反应,也不利于定位问题,这是一种不负责任的表现。
正例:在用户注册的场景中,如果用户输入非法字符,或用户名称已存在,或用户输入的密码过于简单,那么在程序上会作出分门别类的判断,并提示用户。
4、捕获异常是为了处理异常,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。最外层的业务使用者必须处理异常,将其转化为用户可以理解的内容。
5、在事务场景中,抛出异常被catch后,如果需要回滚,那么一定要注意手动回滚事务。
6、finally块必须对资源对象、流对象进行关闭操作,如果有异常就要做try-catch操作。
说明:对于JDK 7及以上版本,可以使用try-with-resources方式。
7、不要在finally块中使用return。
说明:try块中的return语句执行成功后,并不马上返回,而是继续执行finally块中的语句,如果此处存在return语句,则在此直接返回,无情地丢弃try块中的返回点。
8、捕获异常与抛异常必须完全匹配,或者捕获异常是抛异常的父类。
9、在调用RPC、二方包或动态生成类的相关方法时,捕获异常必须使用Throwable类拦截。
说明:通过反射机制调用方法,如果找不到方法,则抛出NoSuchMethod Exception。在什么情况下会抛出NoSuchMethodError呢?二方包在类冲突时,仲裁机制可能导致引入非预期的版本使类的方法签名不匹配,或者在字节码修改框架(比如:ASM)动态创建或修改类时,修改了相应的方法签名。对于这些情况,即使在代码编译期是正确的,在代码运行期也会抛出NoSuchMethodError。
推荐:
1、方法的返回值可以为null,不强制返回空集合或者空对象等,必须添加注释充分说明在什么情况下会返回null值。此时数据库id不支持存入负数而抛出异常。
说明:防止产生NPE是调用者的责任。即使被调用方法返回空集合或者空对象,对调用者来说,也并非高枕无忧,必须考虑到远程调用失败、序列化失败、运行时异常等场景返回null值的情况。
2、防止产生NPE是程序员的基本修养,注意NPE产生的场景。
1)当返回类型为基本数据类型,return包装数据类型的对象时,自动拆箱有可能产生NPE。
反例:public int f() { return Integer对象}, 如果为null,则自动拆箱,抛NPE。
2)数据库的查询结果可能为null。
3)集合里的元素即使isNotEmpty,取出的数据元素也可能为null。
4)当远程调用返回对象时,一律要求进行空指针判断,以防止产生NPE。
5)对于Session中获取的数据,建议进行NPE检查,以避免空指针。
6)级联调用obj.getA().getB().getC();的一连串调用,易产生NPE。
正例:使用JDK 8的Optional类防止产生NPE。
3、定义时区分unchecked / checked异常,避免直接抛出new RuntimeException(),更不允许抛出Exception或者Throwable,应使用有业务含义的自定义异常。推荐业界已定义过的自定义异常,如:DAOException /ServiceException等。
参考:
1、对于公司外的HTTP/API开放接口,必须使用“errorCode”;应用内部推荐异常抛出;跨应用间RPC调用优先考虑使用Result方式,封装isSuccess()方法、“errorCode”和“errorMessage”。
说明:关于RPC方法返回方式使用Result方式的理由。
1)使用抛异常返回方式,调用方如果没有捕获到,就会产生运行时错误。
2)如果不加栈信息,只是new自定义异常,加入自己理解的errorMessage,对于调用端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输的性能损耗也是问题。
2、避免出现重复的代码(Don't Repeat Yourself),即DRY原则。
说明:随意复制和粘贴代码,必然导致代码的重复,当以后需要修改时,需要修改所有的副本,容易遗漏。必要时抽取共性方法或公共类,甚至将代码组件化。
三、日志规约
强制:
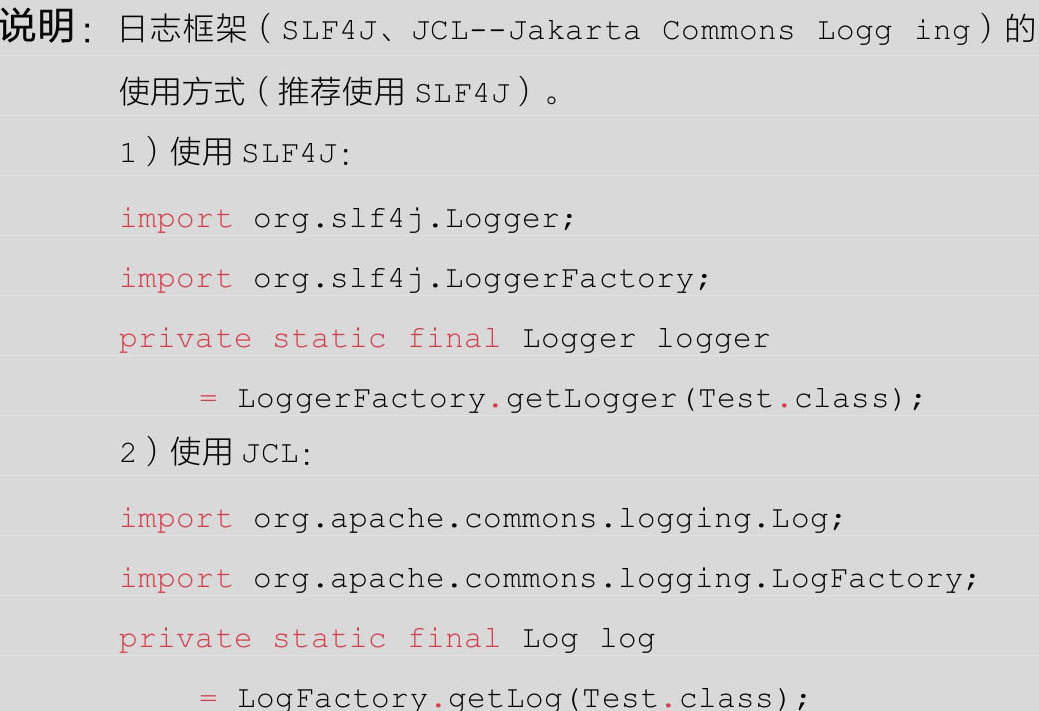
1、应用中不可直接使用日志系统(Log4j、Logback)中的API,而应依赖使用日志框架(SLF4J、JCL--Jakarta Commons Logging)中的API,使用门面模式的日志框架,有利于维护日志并保证各个类的日志处理方式统一。
2、所有日志文件至少保存15天,因为有些异常具备以“周”为频次发生的特点。对于当天日志,以“应用名.log”保存在“/home/admin/应用名/logs/”目录下,过往日志格式: {logname}.log.{保存日期},日期格式:yyyy-MM-dd。
3、根据国家法律,网络运行状态、网络安全事件、个人敏感信息操作等相关记录,留存日志的时间不少于六个月,并且进行网络多机备份。
4、应用中的扩展日志(如打点、临时监控、访问日志等)命名方式:appName_logType_logName.log。logType为日志类型,如stats/monitor/access等;logName为日志描述。这种命名的好处是通过文件名就可以知道日志文件属于哪个应用,哪种类型,有什么目的,这也有利于归类查找。
说明:推荐对日志进行分类,如将错误日志和业务日志分开存放,既便于开发人员查看,也便于通过日志及时监控系统。
5、当输出日志时,字符串变量之间的拼接使用占位符的方式。
说明:因为String字符串的拼接会使用StringBuilder的append()方式,所以有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。
6、对于trace/debug/info级别的日志输出,必须进行日志级别的开关判断。
说明:在debug(参数)的方法体内,虽然当第一行代码is Disabled(Level.DEBUG_INT)为真时(Slf4j的常见实现Log4j和Logback)会直接return,但是参数可能会进行字符串拼接运算。此外,如果debug(getName())这种参数内有getName()方法调用,则会浪费方法调用的开销。
7、避免重复打印日志,否则会浪费磁盘空间,务必在日志配置文件中设置additivity=false。
8、在生产环境中禁止直接使用System.out或System. err输出日志,或使用e.printStackTrace()打印异常堆栈。
说明:只有每次Jboss重启时,标准日志输出文件与标准错误输出文件才滚动,如果大量输出送往这两个文件,则容易造成文件大小超过操作系统大小限制。
9、异常信息应该包括两类:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字throws往上抛出。
10、打印日志时,禁止直接用JSON工具将对象转换成String。
说明:如果对象里某些get方法被覆写,存在抛出异常的情况,则可能会因为打印日志而影响正常的业务流程的执行。
正例:打印日志时,仅打印业务相关属性值或者调用其对象的toString()方法。
推荐:
1、谨慎地记录日志。在生产环境中禁止输出debug日志;有选择地输出info日志;如果使用warn记录刚上线时的业务行为信息,则一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并及时删除这些观察日志。
说明:大量地输出无效日志,既不利于提升系统性能,也不利于快速定位错误点。记录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
2、可以使用warn日志级别记录用户输入参数错误的情况,避免当用户投诉时无所适从。
说明:如非必要,请不要在此场景中打出error级别,避免频繁报警。注意日志输出的级别,error级别只记录系统逻辑出错、异常等重要的错误信息。
3、尽量用英文描述日志错误信息。如果日志中的错误信息用英文描述不清楚,可以使用中文描述,否则容易产生歧义。
说明:国际化团队或海外部署的服务器,由于字符集问题,【强制】使用全英文注释和描述日志错误信息。
---内容来源《阿里巴巴开发手册》