weibo_comment_pc_tool | 我于2025.5月用python开发的评论采集软件,根据帖子链接爬取评论的界面工具
本工具仅限学术交流使用,严格遵循相关法律法规,符合平台内容的合法及合规性,禁止用于任何商业用途!
一、背景分析
1.1 开发背景
微博(以下简称wb)是国内极具影响力的社交媒体平台,具有内容形式短平快、热点事件实时性强、舆论快速发酵、用户群体年轻且活跃等特点。其中,评论区是用户公开表达观点的重要场域,可通过评论区的数据,实时追踪情绪倾向、挖掘公众诉求、捕捉热点趋势、构建群体画像、从而进行社会学和传播学的研究等。
基于此,我用python开发了一个爬虫采集软件,叫【爬wb评论软件】,下面详细介绍。
1.2 软件界面
软件界面,如下:
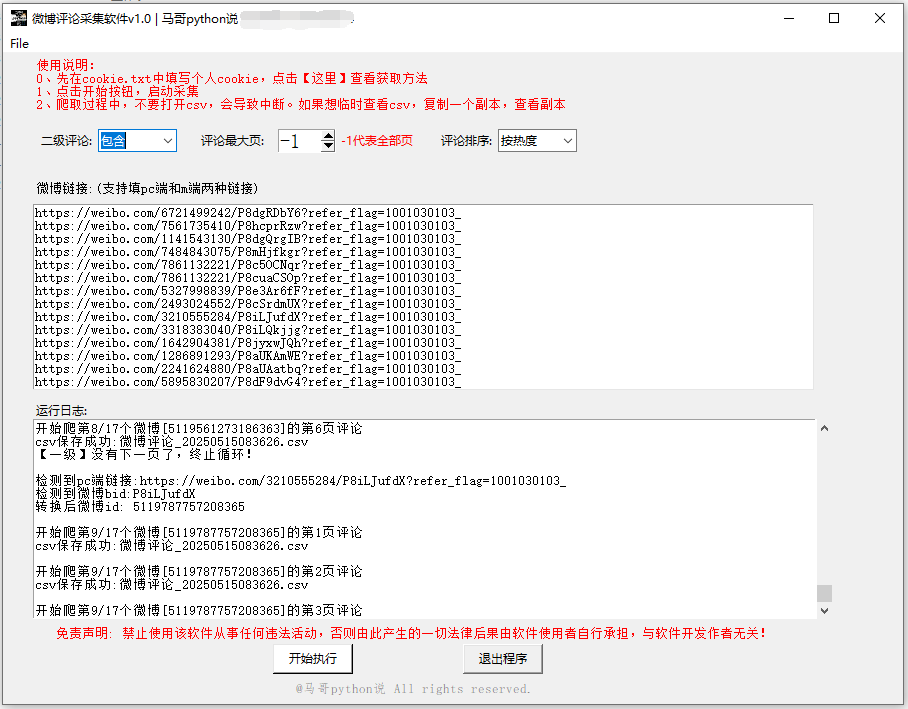
1.3 结果展示
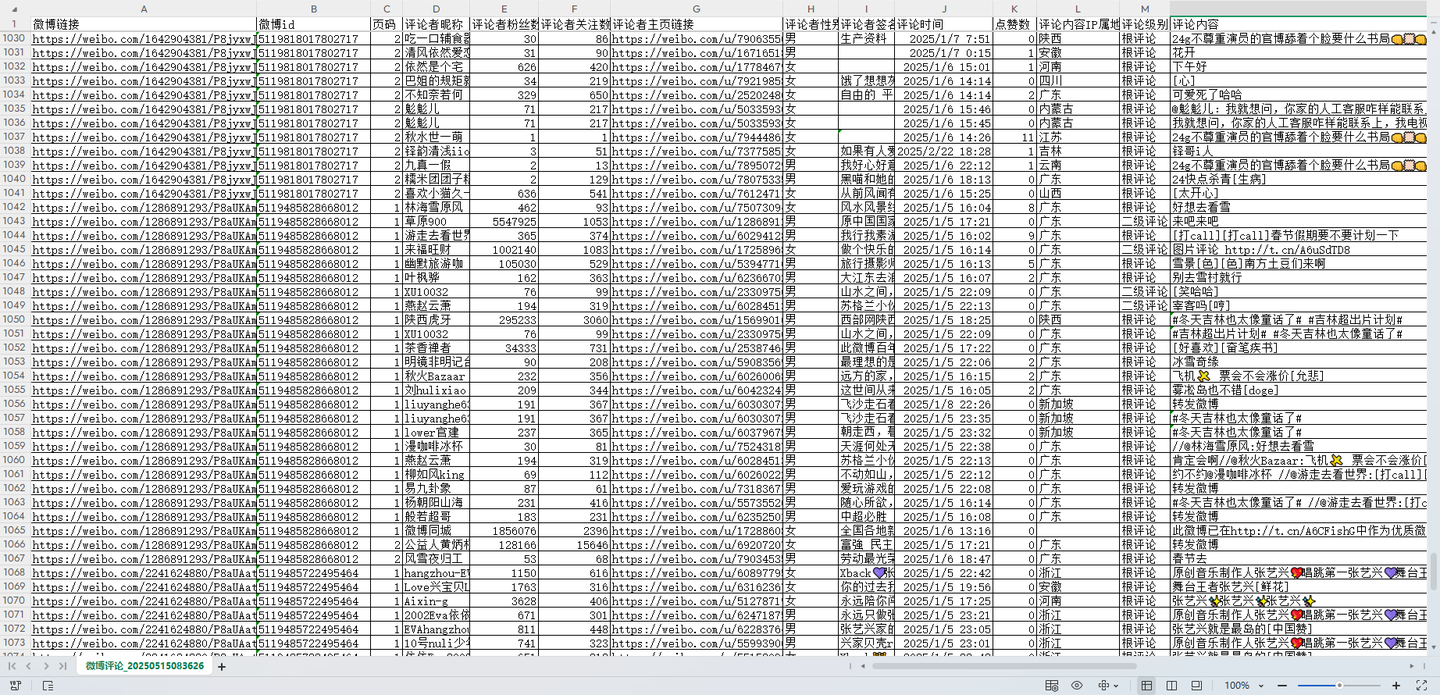
爬取结果:(截图中展示的就是全部字段了)
1.4 软件说明
几点重要说明,请详读了解:
- Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
- 软件通过爬虫程序爬取,经本人专门测试,运行持久,稳定性较高!
- 先在cookie.txt中填入自己的cookie值,方便重复使用(内附cookie获取方法)
- 支持多个帖子链接串行爬取
- 支持选择是否包含二级评论、指定评论排序(按热度/按时间)、指定爬取前几页
- 爬取过程中,每爬一页,存一次csv。并非爬完最后一次性保存!防止因异常中断导致丢失前面的数据(每条间隔1~2s)
- 爬取过程中,有log文件详细记录运行过程,方便回溯
- 结果csv含14个字段,有:wb链接,wbid,页码,评论者昵称,评论者粉丝数,评论者关注数,评论者主页链接,评论者性别,评论者签名,评论时间,点赞数,评论内容IP属地,评论级别,评论内容
以上是现有功能,软件版本持续更新中。
1.5 演示视频
软件运行过程演示:
123
二、主要技术
2.1 模块分工
软件全部模块采用python语言开发,主要分工如下:
tkinter:GUI软件界面
requests:爬虫发送请求
json:解析返回的响应数据
pandas:保存csv结果
logging:日志记录
出于版权考虑,暂不公开源码,仅向用户提供软件使用。
2.2 部分代码
部分代码实现:
发送请求并解析数据:
# 发送请求
r = requests.get(url, headers=h1, params=params)
# 解析数据
json_data = r.json()
解析响应数据,以“评论内容”字段为例:
for data in json_data['data']:# 评论内容text = data['text_raw']text_list.append(text)
保存结果数据到csv文件:
# 保存数据
df = pd.DataFrame({'wb链接': weibo_url,'wbid': weibo_id,'页码': page,'评论者昵称': screen_name_list,'评论者粉丝数': followers_count_list,'评论者关注数': friends_count_list,'评论者主页链接': user_home_url_list,'评论者性别': gender_list,'评论者签名': desc_list,'评论时间': create_time_list,'点赞数': like_counts_list,'评论内容IP属地': source_list,'评论级别': comment_level_list,'评论内容': text_list,}
)
# 保存csv文件
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('结果保存成功:{}'.format(self.result_file))
软件界面底部版权:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
日志模块:
def get_logger(self):self.logger = logging.getLogger(__name__)# 日志格式formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'# 日志级别self.logger.setLevel(logging.DEBUG)# 控制台日志sh = logging.StreamHandler()log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')# info日志文件名info_file_name = time.strftime("%Y-%m-%d") + '.log'# 将其保存到特定目录case_dir = r'./logs/'info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,when='MIDNIGHT',interval=1,backupCount=7,encoding='utf-8')
三、使用介绍
3.0 填写cookie
开始采集前,先把自己的cookie值填入cookie.txt文件。
pc端cookie获取说明:
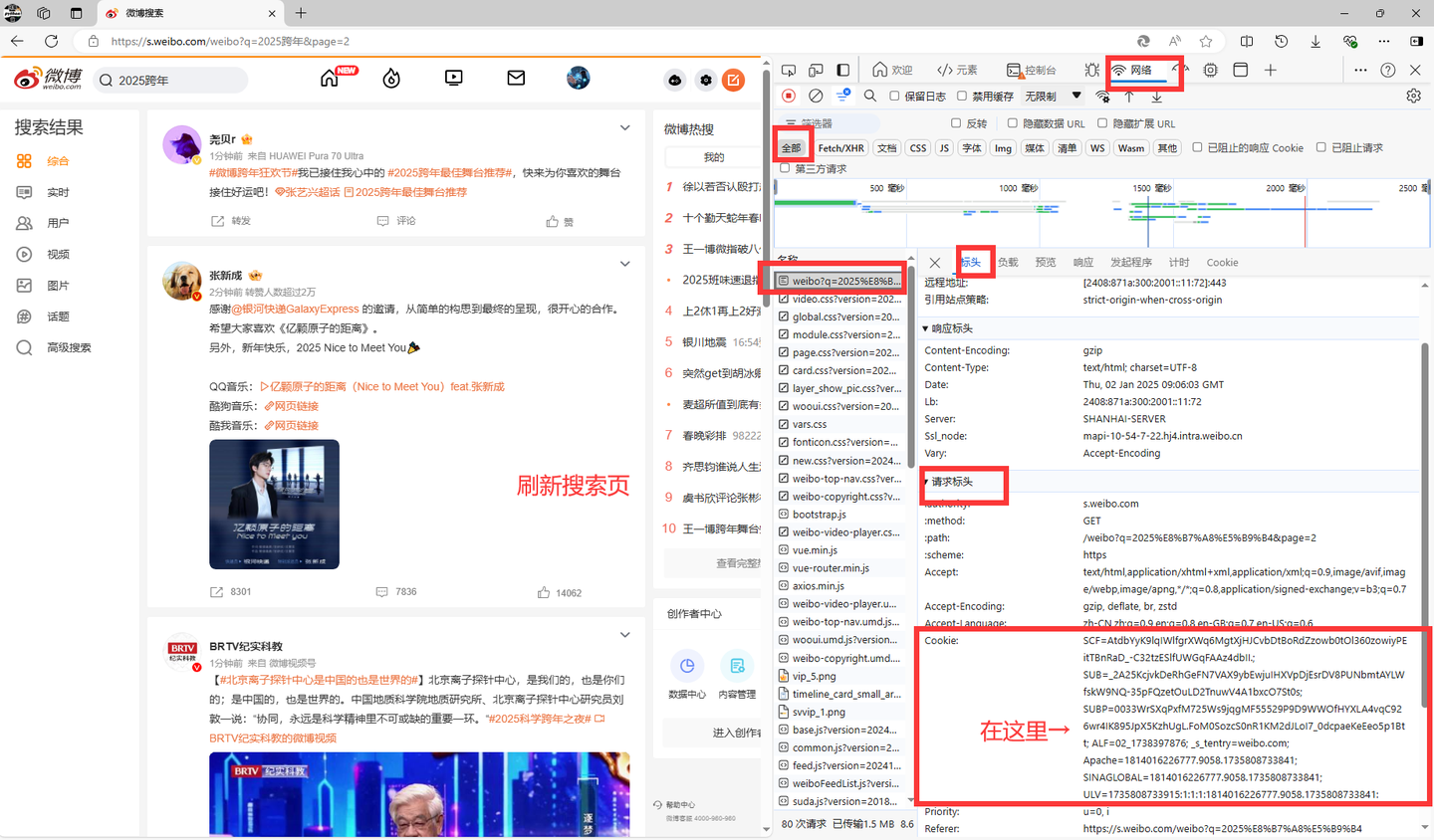
然后把复制的cookie值填写到当前文件夹的cookie.txt文件中。
3.1 软件登录
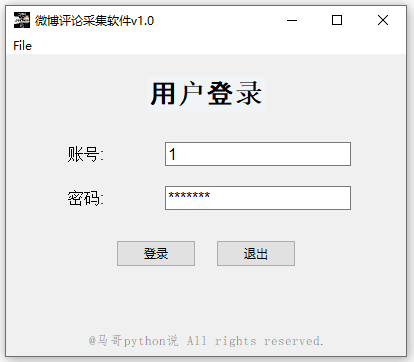
用户登录界面:
3.2 采集wb评论
根据自己的实际情况,在软件界面填写采集条件,点击开始按钮:
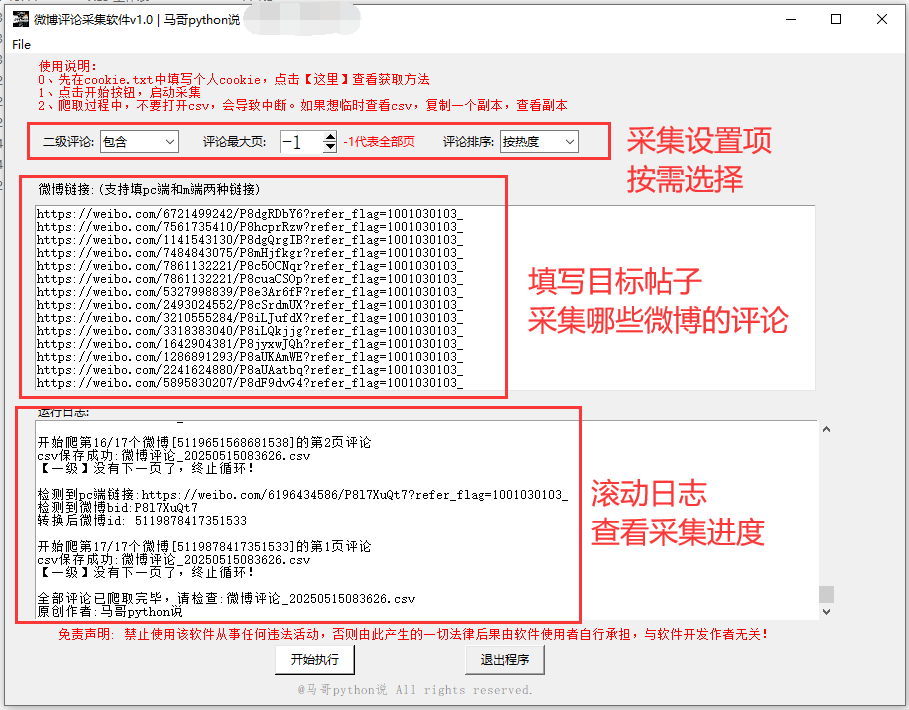
完成采集后,在当前文件夹生成对应的csv文件,文件名以时间戳命名,方便查找。
五、结语
软件首发众公号”老男孩的平凡之路“,欢迎技术交流、深度探讨!