深度学习(第3章——亚像素卷积和可形变卷积)
前言:
本章介绍了计算机识别超分领域和目标检测领域中常常使用的两种卷积变体,亚像素卷积(Subpixel Convolution)和可形变卷积(Deformable Convolution),并给出对应pytorch的使用。

亚像素卷积(Subpixel Convolution):
由低维特征图还原为高维特征图,在上一章已经介绍了一种常用方法:转置卷积,链接如下:深度学习(第2章——卷积和转置卷积)_转置卷积层-CSDN博客![]() https://blog.csdn.net/wlf2030/article/details/147479684?spm=1001.2014.3001.5502
https://blog.csdn.net/wlf2030/article/details/147479684?spm=1001.2014.3001.5502
但转置卷积的核心为填充0或双线性插值再正向卷积,这种做法会导致最后还原的图像出现棋盘伪影(可以通过设置卷积核整除步长或插值上采样缓解)。
亚像素卷积也是一种上采样方法,其核心操作为重新排列多个特征图的单个像素转化为上采样特征图的亚像素,下面图可以直观展现这一过程。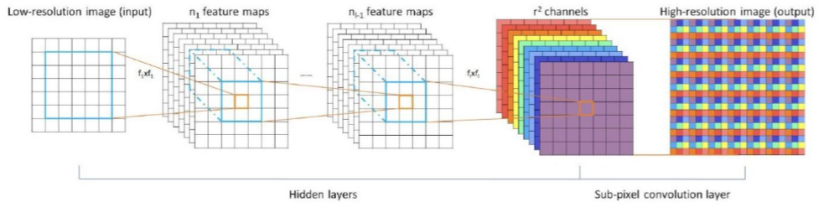
也可借助代码理解。
import torch
import torch.nn as nn
r = 2 # 上采样倍率
PS = nn.PixelShuffle(r) # 初始化亚像素卷积操作
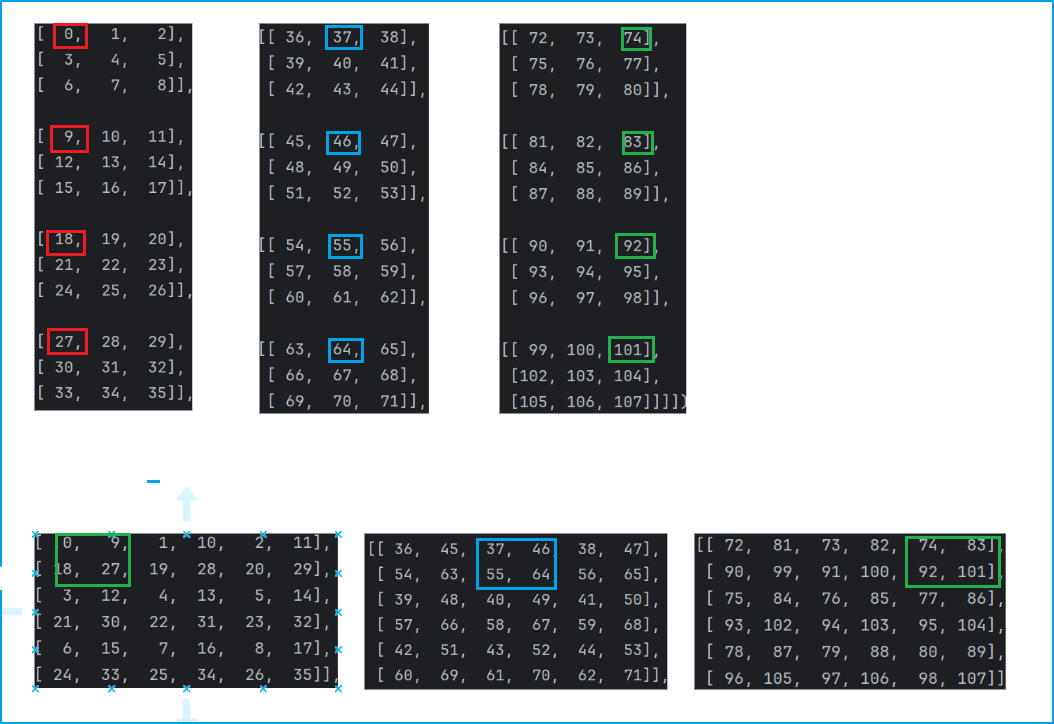
x = torch.arange(3*4*9).reshape(1, 3*(r**2),3, 3) #3通道 r*r表示每个像素对应特征图像素数目,特征图长宽
print(f'*****************************************')
print(f'input is \n{x}, and size is {x.size()}')
y = PS(x) # 亚像素上采样
print(f'*****************************************')
print(f'output is \n{y}, and size is {y.size()}')
print(f'*****************************************')
print(f'upscale_factor is {PS.extra_repr()}')
print(f'*****************************************')
使用torch官方提供的已经定义好的亚像素卷积层,形参为上采样倍数。这里的含义为将一个12通道的3*3的特征图上采样还原为一个3通道6*6的特征图,程序输出如下:
![]() 变为了
变为了![]()
可形变卷积(Deformable Convolution):
传统卷积使用卷积核滑动遍历图片在目标检测的目标发生扭曲时效果较差,原因在于传统卷积固定了位置相对关系,比如对于溜冰鞋的目标检测,卷积层可能提取的特征为在轮子上的鞋子,但当图片反转时变成了轮子在鞋子上方就有可能无法检测到。为了解决相对位置变化对卷积提取的影响,可形变卷积引入一个可学习的偏移矩阵,从而能够输入内容动态调整卷积的位置,自适应地捕捉复杂空间变形。传统卷积操作作用为学习卷积区域的特征,而引入的偏置矩阵用于学习应该使用哪些位置的像素做卷积。
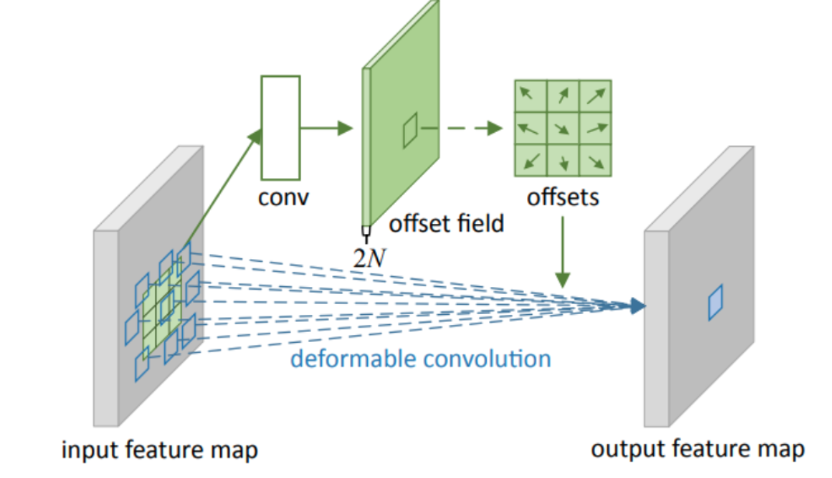
核心注意点:
1.偏移矩阵是针对每次卷积操作卷积核上获取对应每个像素的x,y坐标偏移量。
2.由于偏移矩阵不可能每轮训练最终像素都刚好为整数,所以需要使用双线性插值获取发生小数偏移对应位置的像素。
3.可形变卷积相当于在传统卷积前做了一步位置映射操作,其余部分不变。
结合代码:
import torch
import torch.nn as nn
from torchvision.ops import DeformConv2d# 定义可变形卷积层
class DeformableConv(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3):super().__init__()# 偏移量生成层(学习"Where")self.offset_conv = nn.Conv2d(in_channels,2 * kernel_size * kernel_size, # 2N offsetskernel_size=kernel_size,padding=kernel_size // 2,)# 可变形卷积层(学习"What")self.deform_conv = DeformConv2d(in_channels,out_channels,kernel_size=kernel_size,padding=kernel_size // 2)def forward(self, x):# 生成偏移量offsets = self.offset_conv(x) # [B, 2N, H, W]print(offsets.shape)# 应用可变形卷积return self.deform_conv(x, offsets) # 同时利用卷积核权重和偏移量# 定义输入 (batch=1, channels=1, height=4, width=4)
input = torch.tensor([[[[1., 2., 3., 4.],[5., 6., 7., 8.],[9., 10., 11., 12.],[13., 14., 15., 16.]]
]], requires_grad=True) # 需要梯度以支持反向传播
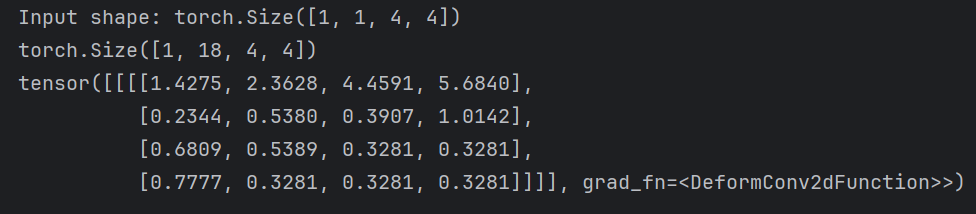
print("Input shape:", input.shape) # [1, 1, 4, 4]dcn = DeformableConv(in_channels=1, out_channels=1, kernel_size=3)
print(dcn(input))
这里是使用一层传统卷积(offset_conv)获取偏移量矩阵,输入通道即为整个可形变卷积层的输入通道,输出通道固定为2倍后续传统卷积的卷积核大小,2表示获取x,y轴上的偏移,如果是1则只能获取单个方向的偏移,乘卷积核大小是应为原本传统卷积对输入特征图的一个像素进行卷积是需要计算卷积核大小的数据,当然卷积核中每个像素都需要一对(x,y)的偏移。而获取偏移量大小的卷积层卷积核大小没有固定要求,这里建议保持和后续传统卷积的卷积核大小相同,但padding一定需要保证为设置的卷积核//2(即保证输入输出的特征图大小相同,否则会导致原特征图的像素1对1映射关系错误),同时使用torch定义好的可形变卷积,其作用在于设置偏移量矩阵后完成后续的双线性插值以及对偏移映射后的矩阵进行传统卷积,其在设置偏移量=0时数学等价于传统卷积(实际上仍然会执行双线性插值可能造成误差)。
最后输出如下:
注意训练时训练的是提取偏移量的传统卷积层卷积核参数(而非直接训练每个特征图的坐标偏移,坐标偏移实际是由这层卷积获取的,否则只训练坐标偏移参数最终相当于仍然固定了映射关系和传统卷积没有任何差异,只有训练卷积核才能让模型知道对于一张特征图应当采用怎样的偏置,以及也可以叠加获取offset矩阵的层数,这里只使用了一层卷积,从而获得更好的泛化能力)+可形变矩阵部分的卷积核参数,如果理解这段话的含义,便可以说理解了可形变卷积的核心。
最后:
目前本人研究方向有超分,目标检测和重识别,对上述方向感兴趣的小伙伴可以关注,后续会更新以上知识以及相关论文。