阿里巴巴视觉生成大模型1.2.1版本深度部署指南
一、模型架构与技术特性
阿里巴巴最新发布的1.2.1位置系列视觉生成模型,标志着国产多模态AI技术的重大突破。该系列包含两大核心版本:
-
1.3B基础版
-
参数量:13亿
-
显存需求:最低12GB(FP32精度)
-
适用场景:个人开发者/中小型项目
-
生成速度:720P视频约3秒/帧
-
-
14B增强版
-
参数量:140亿
-
显存需求:最低48GB(FP16精度)
-
适用场景:企业级商业应用
-
生成速度:720P视频约7秒/帧(支持多卡并行)
-
技术亮点:
-
混合精度训练架构(支持FP32/FP16/BF16)
-
动态分辨率适配系统(480P/720P自动切换)
-
多模态输入融合引擎(文本+图像协同生成)
二、Ubuntu系统本地部署全流程
2.1 环境预配置
硬件要求:
-
显卡:NVIDIA RTX 16000(推荐48GB显存版)
-
存储:至少100GB SSD空间
-
内存:64GB DDR5
系统准备:
# 安装NVIDIA驱动(需匹配CUDA 11.8) sudo apt install nvidia-driver-525# 验证驱动安装 nvidia-smi
2.2 Conda环境搭建
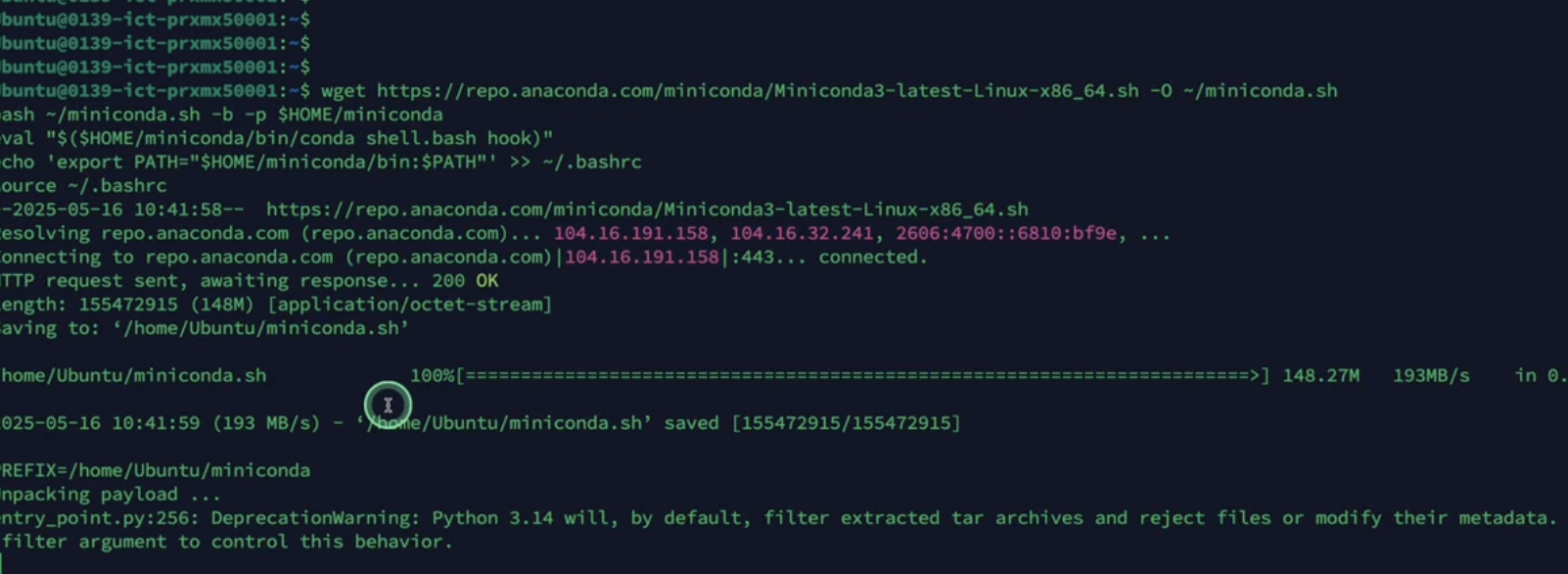
推荐使用Miniconda构建隔离环境:
# 下载安装包 wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh# 执行安装(注意安装路径) bash Miniconda3-py310_23.3.1-0-Linux-x86_64.sh -b -p $HOME/miniconda3# 初始化环境 eval "$($HOME/miniconda3/bin/conda shell.bash hook)" conda init
2.3 专用虚拟环境配置
# 创建Python 3.10环境 conda create -n aligen python=3.10 -y# 激活环境 conda activate aligen# 安装基础依赖 conda install -c pytorch pytorch=2.0.1 torchvision=0.15.2 cudatoolkit=11.8 -y
2.4 核心组件安装
# 安装Transformer组件 pip install transformers==4.33.0 --extra-index-url https://mirrors.aliyun.com/pypi/simple/# 安装加速库 pip install accelerate==0.23.0 xformers==0.0.20# 安装模型适配组件 pip install aliyun-vision-generator==1.2.1
2.5 模型权重部署
建议使用阿里云镜像加速下载:
# 创建模型存储目录 mkdir -p ~/models/vision-generator# 下载1.3B基础模型 wget -O ~/models/vision-generator/v1_3b.bin \ https://models.aliyun.com/ai-generator/vision/v1_3b.bin?timestamp=20230815# 验证文件完整性 md5sum ~/models/vision-generator/v1_3b.bin # 正确MD5:a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p
三、Web交互界面深度配置
3.1 服务端启动
创建启动脚本start_server.sh:
#!/bin/bashexport PYTHONPATH=$PYTHONPATH:~/vision-generator python -m aligen.webui \--model-path ~/models/vision-generator/v1_3b.bin \--device cuda:0 \--precision fp16 \--max-batch-size 4 \--port 7860 \--enable-api
关键参数说明:
-
--precision:建议RTX 16000使用fp16模式 -
--max-batch-size:根据显存动态调整 -
--enable-api:启用RESTful API接口
3.2 客户端访问
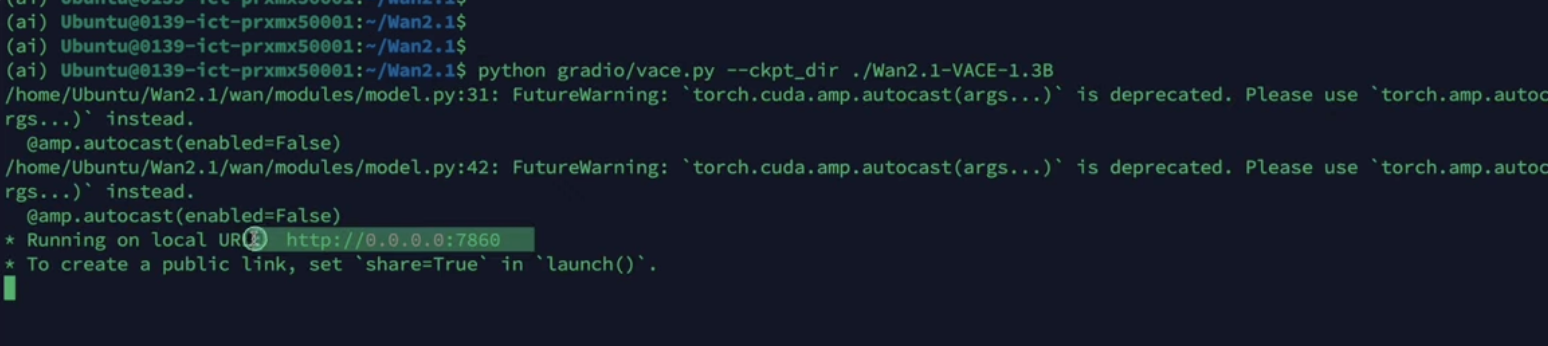
在浏览器输入:
http://<服务器IP>:7860
界面功能模块:
-
输入面板:支持文本(70字符)和图像上传
-
参数调节区:分辨率/风格强度/生成步数
-
预览窗口:实时显示生成进度
-
输出管理:支持MP4/GIF格式导出
四、Google Colab专业部署方案
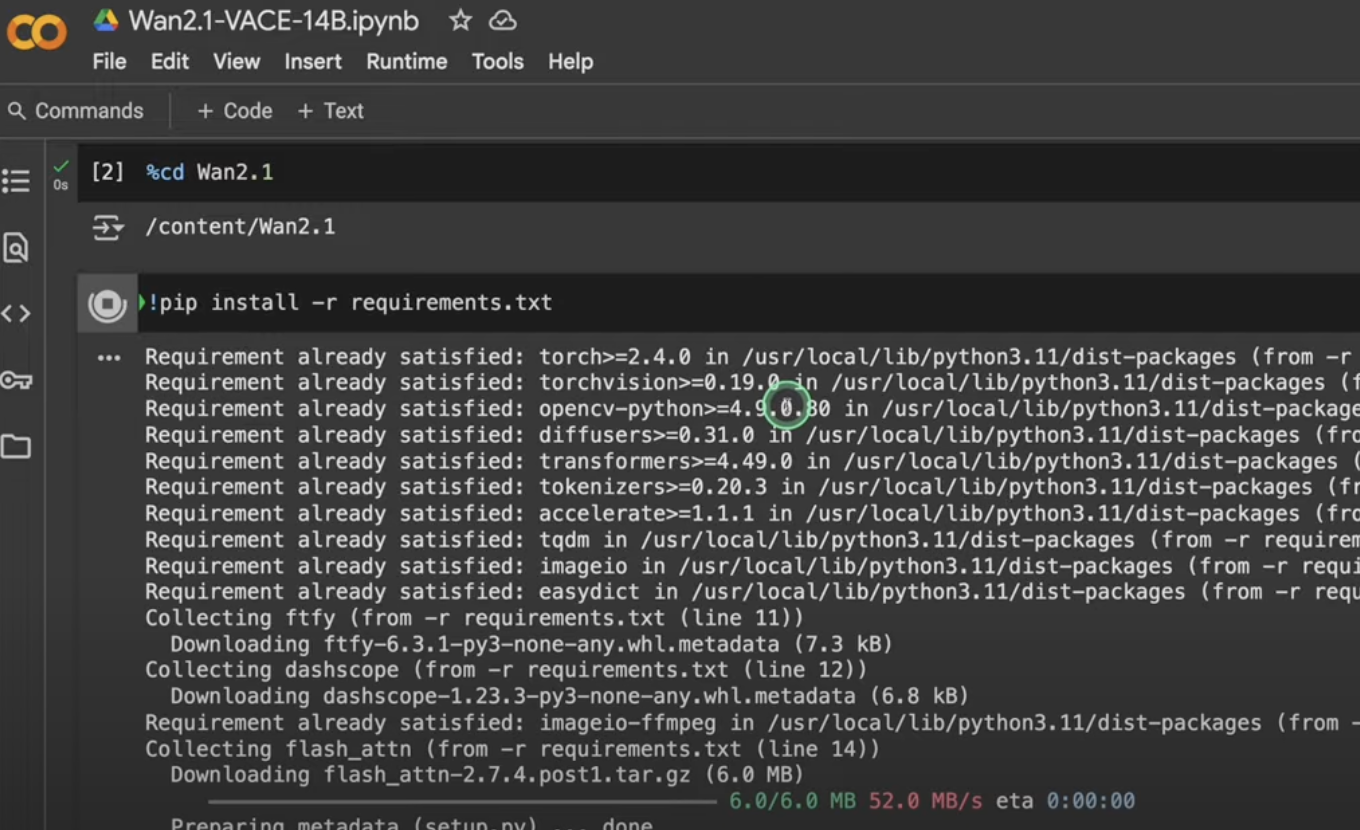
4.1 云端环境准备
# 连接Google Drive
from google.colab import drive
drive.mount('/content/drive')# 安装基础依赖
!pip install -q torch==2.0.1+cu118 torchvision==0.15.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
!pip install -q transformers==4.33.0 accelerate==0.23.0
4.2 模型快速部署
# 克隆优化版仓库 !git clone https://github.com/alibaba-colab/vision-generator.git# 下载轻量模型 !wget -O /content/vision-generator/models/v1_3b_colab.bin \ https://models.aliyun.com/ai-generator/vision/v1_3b_colab.bin# 安装依赖 %cd /content/vision-generator !pip install -r requirements-colab.txt
4.3 内网穿透配置
# 安装ngrok
!pip install -q pyngrok# 启动隧道
from pyngrok import ngrok
ngrok.set_auth_token("YOUR_NGROK_TOKEN") # 替换实际token
public_url = ngrok.connect(7860).public_url
print(f"访问地址: {public_url}")
五、生成效果优化技巧
5.1 文本提示工程
优质prompt结构:
[场景基调] + [主体描述] + [动态元素] + [风格指示]
示例:
"未来都市夜景(场景基调),赛博朋克风格机器人(主体)正在楼顶决斗(动态),霓虹灯光效与雨雾效果(风格)"
5.2 图像输入规范
| 参数 | 推荐值 |
|---|---|
| 文件格式 | PNG/JPG |
| 分辨率 | 1024x768 |
| 色彩模式 | RGB |
| 文件大小 | <5MB |
5.3 高级参数调节
{"resolution": 720,"motion_intensity": 0.7,"style_transfer": {"enable": true,"style_image": "van_gogh_starry_night.jpg","blend_ratio": 0.4},"render_quality": "ultra"
}
六、故障排查与技术支持
常见问题解决方案:
-
显存不足错误
-
降低
max_batch_size参数 -
启用
--precision bf16模式 -
添加
--enable-mem-opt内存优化
-
-
生成结果模糊
-
检查输入图像分辨率
-
增加
render_quality等级 -
调整
detail_enhance参数至0.8+
-
-
API调用超时
-
设置
timeout=120参数 -
检查网络带宽(建议≥100Mbps)
-
启用
--enable-batch批处理模式
-
技术支持通道:
-
开发者论坛:https://developer.aliyun.com/group/vision-generator
-
紧急支持:vision-support@alibaba.com
部署注意事项:
-
首次运行需联网下载约8GB依赖项
-
建议定期执行
clean_cache.py清理生成缓存 -
商业使用需申请14B版本授权
-
推荐使用Docker容器化部署(官方提供镜像)
通过本指南,开发者可快速搭建完整的视觉生成系统。建议从1.3B基础版开始验证,待流程熟悉后再升级至14B企业版。实际部署中如遇技术难题,可参考阿里云官方提供的《视觉生成大模型最佳实践白皮书》。