linux线程基础
1. 什么是线程
进程是承担系统资源分配的基本实体,而线程(Thread)是进程内的一个执行单元,是CPU调度的基本单位。一个进程可以包含多个线程,这些线程共享进程的地址空间和资源(如文件描述符、全局变量等),但每个线程拥有独立的栈、寄存器状态和程序计数器。
(1)线程的核心特点
- 轻量级:轻量级进程、创建、销毁、切换的开销比进程小。
- 共享进程资源:所有线程共享进程的代码段、数据段、堆、打开的文件等。
- 独立执行流:每个线程有自己的独立的栈和 一组寄存器(线程的上下文数据)。
(2)linux线程复用 task_struct,用进程模拟线程,Linux 的线程就是轻量级进程。
- task_struct(任务结构体)是 Linux 内核用于描述进程/线程的数据结构。在 Linux 中,进程和线程的本质是相同的,都是 task_struct 结构的实例。
- 线程 ≈ 轻量级进程(LWP, Lightweight Process):
- 线程是一个特殊的进程,只是共享了部分进程资源(如地址空间、文件描述符等)。
- Linux 使用 clone() 系统调用创建线程,而不是 fork():
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, stack);
这些 CLONE_XXX 标志决定了线程与其父进程共享哪些资源:
CLONE_VM:共享地址空间
CLONE_FS:共享文件系统信息
CLONE_FILES:共享文件描述符表
CLONE_SIGHAND:共享信号处理(3)进程:强独占,部分共享(比如通信)
强独占:
- 每个进程都有自己的独立地址空间,不能直接访问其他进程的内存。
- 进程间的文件描述符、变量、栈等资源默认都是互不影响的。
部分共享:
- IPC 机制可以用于进程间共享数据:
- 共享内存(shm)
- 管道(pipe)、消息队列(mq)
- 套接字(socket)
(4) 线程:部分独占,强调共享
部分独占:
- 线程有自己独立的栈(存储局部变量、返回地址)。
- 线程的寄存器 PC(程序计数器)、SP(栈指针)也是独立的。
强调共享:
- 线程共享同一进程的地址空间,可以访问全局变量、堆上的数据。
- 线程间无需 IPC,即可直接访问共享数据,提高通信效率。
- 但也带来了同步问题,需要用 锁(mutex)、条件变量(cond)、读写锁(rwlock) 控制并发。
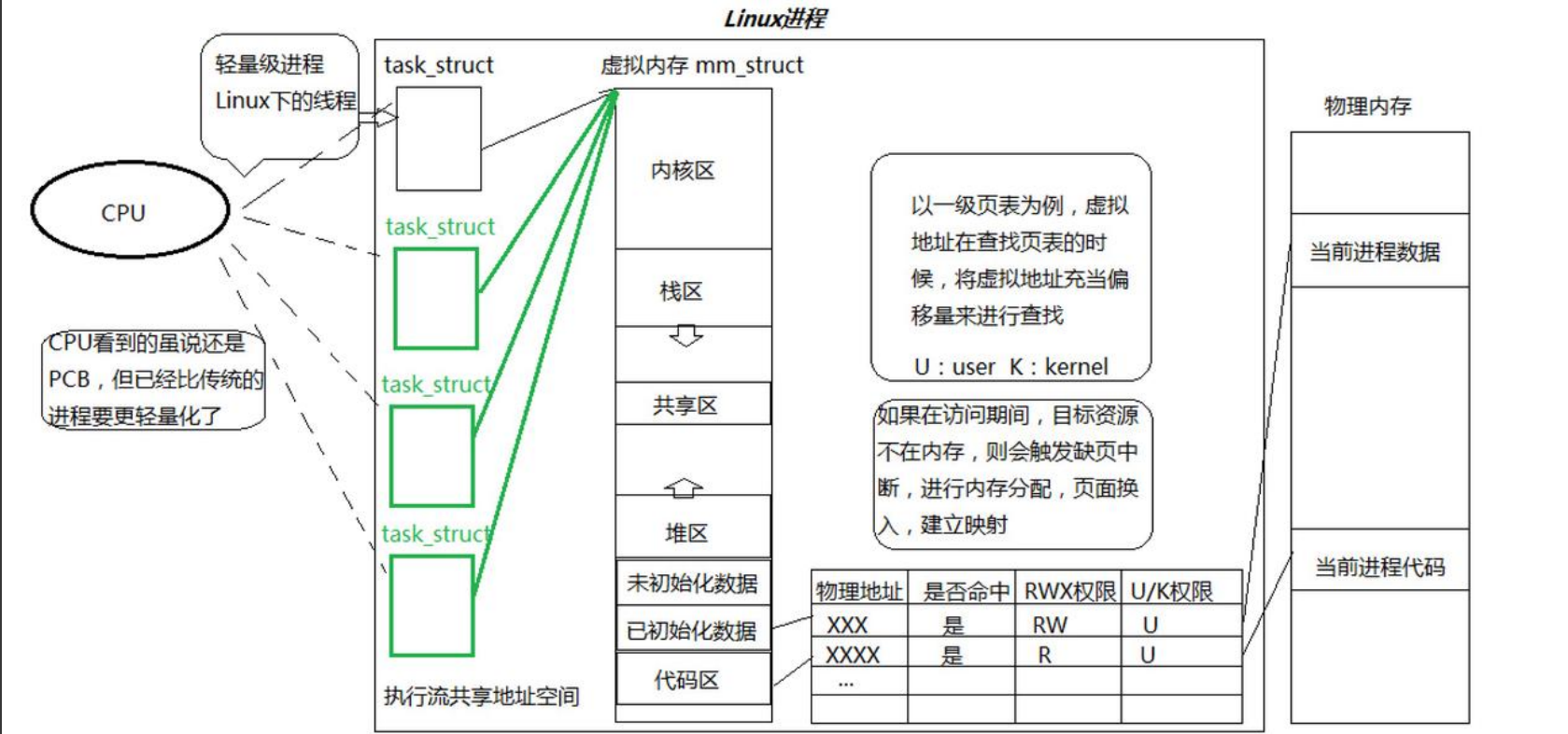
2. 分页式存储管理
1. 进程访问的大部分资源都是通过地址空间访问的,对资源的划分本质上就是对地址空间的划分。地址空间就像是一个“窗口”。
(1)进程的所有资源(代码、数据、堆、栈、文件描述符等)最终都是通过地址空间来组织和管理的。
(2)进程的虚拟地址空间是一个抽象的窗口,它映射到物理内存和其他资源(如文件、共享内存等)。
(3)资源的管理(包括权限、隔离和共享)本质上就是对地址空间的划分:
- 私有地址空间:进程独占,如私有变量、堆、栈等。
- 共享地址空间:进程间通信(IPC)机制,如共享内存(shm)、文件映射等
2. 函数的本质就是虚拟地址空间(逻辑地址)的集合,让线程未来执行ELF程序的不同函数即可。
(1)在 ELF 可执行文件中,每个函数都是一段指令集合,存储在代码段(.text 段)。
(2)线程运行时,通过 程序计数器(PC)和 指令指针(EIP/RIP)访问代码段的不同部分,从而调用不同函数。
(3)函数的本质就是代码段中的一段逻辑地址集合,线程的执行本质上是在不同的函数地址集合之间跳转。
2.1 虚拟地址和页表
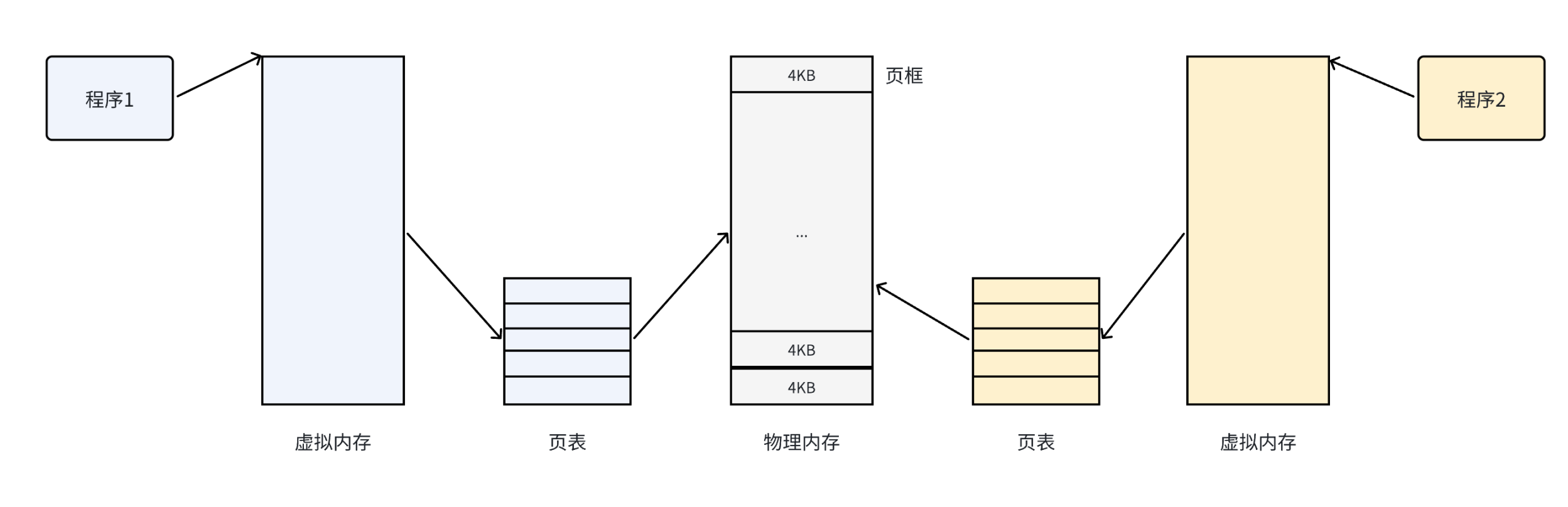
(1)物理内存的分页机制
操作系统将物理内存按照固定长度的页框进行分割,有时也称为物理页。每个页框包含一个物理页(Page),且页的大小与页框的大小相等。
- 大多数 32 位体系结构 支持 4KB 的页。
- 64 位体系结构 通常支持 8KB 的页。
(2)区分页和页框:
页框(Page Frame)
- 是物理内存被划分的固定大小的存储单元(如4KB/8KB),属于硬件层面的划分。
- 操作系统通过页框管理物理内存的分配和回收。
物理页(Physical Page)
- 指存储于页框中的数据块,其大小与页框严格一致(例如4KB页框存放4KB的页)。
- 页本身是逻辑概念,可以存放在物理内存的页框或磁盘(如交换空间)中。
关键关系
- 页框是容器,页是内容。
- 当页被调入物理内存时,必须占用一个完整的页框;换出到磁盘时,页框被释放。
访问机制:
(1)CPU不直接访问物理内存地址,而是通过虚拟地址空间间接访问。虚拟地址空间是操作系统为每个进程分配的逻辑地址范围(如32位系统为0~4GB)。
(2)操作系统通过页表建立虚拟地址与物理地址的映射关系:
- 页表记录每个虚拟页(进程视角)与物理页框(内存视角)的对应关系。
- CPU访问虚拟地址时,由MMU(内存管理单元)自动查页表转换为物理地址。
(3)若目标页不在物理内存中(页表项标记为无效),则触发缺页异常,操作系统负责从磁盘调入缺失页到空闲页框,并更新页表。
2.2 物理内存管理
操作系统通过`struct page` 结构体管理页框
- 每个物理页框对应一个 `struct page`,用于跟踪页框状态(如是否空闲、被哪个进程使用等)。
典型字段(简化示例):
struct page {unsigned long flags; // 状态标志(如脏页、锁定等)atomic_t _count; // 引用计数struct list_head list; // 链表(用于空闲页管理)// 联合体(union)优化存储,根据页框用途复用字段};- 假设每个 `struct page` 占 40字节,则总开销:
40 * 1048476B = 40MB,相对系统 4GB 内存而言,仅是很小的⼀部分罢了。
页大小的权衡
- 页过大
- 优点:减少页表长度,降低转换开销。
- 缺点:内部碎片增大(如进程仅需5KB,但占用8KB页框,浪费3KB)。
- 页过小
- 优点:减少内部碎片。
- 缺点:
- 页表过长(4GB内存需 物理内存的大小/页框的大小(假如是512B) = 8,388,608) 个页框,页表占用更大内存)。
- 频繁的页转换增加CPU和MMU开销。
- 折中选择:
- 4KB页(如Windows/Linux主流选择):平衡碎片与页表开销。
- 大页(Huge Page):针对数据库等场景,减少TLB缺失(如2MB页)。
2.3 页表
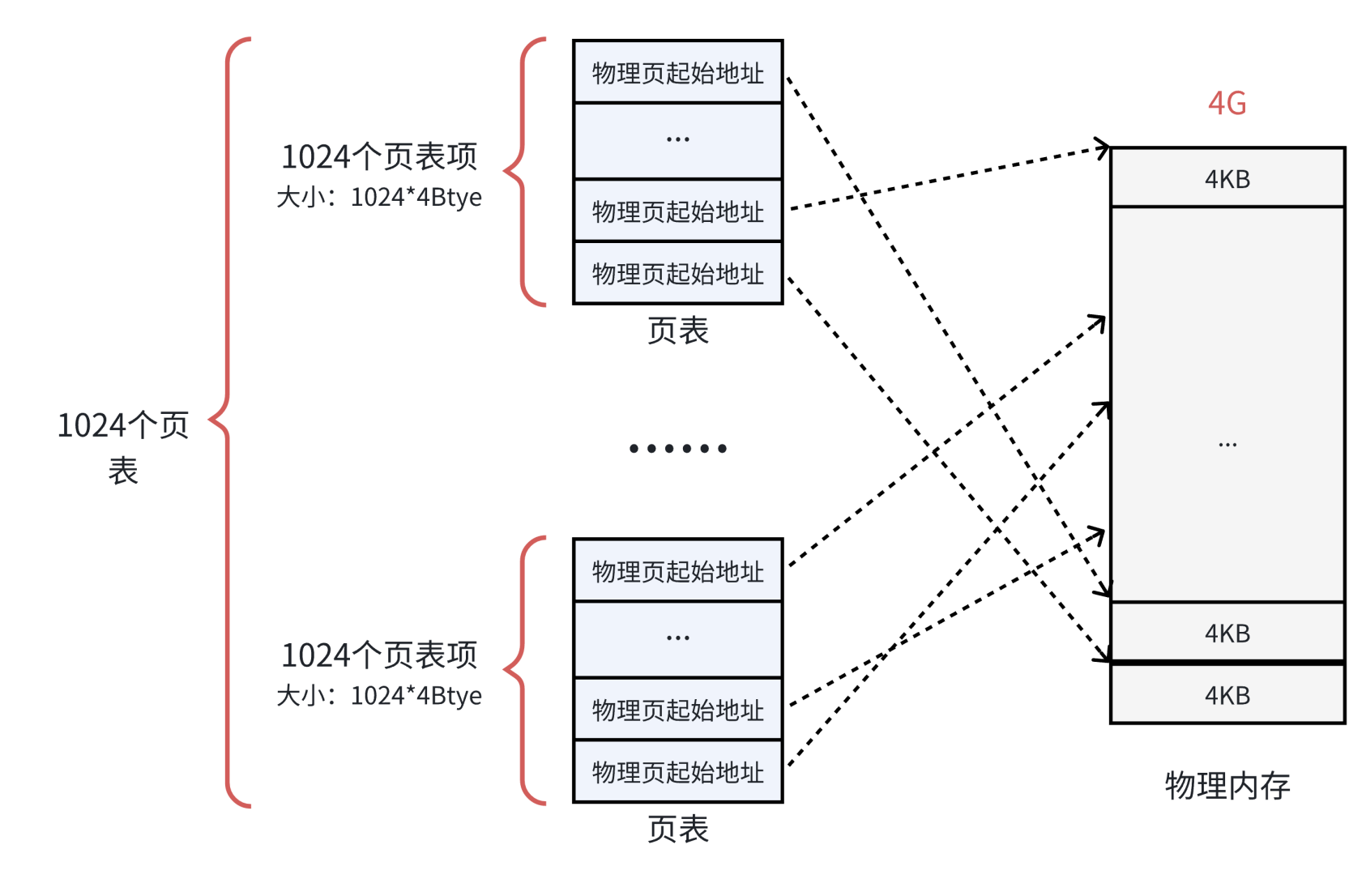
1. 32位系统下页表的空间占用分析
- 虚拟地址空间:4GB((2^32)字节)。
- 页大小:4KB((2^12)字节)。
- 页表项数量: 4GB/4KB = 1,048,576
- 每个页表项大小:4字节(32位物理地址)。
- 页表总大小: 1,048,576 * 4(B) = 4MB
- 占用物理页框数: 4MB/4B = 1,048,576
核心矛盾:
页表本身需要 1,024个连续物理页框,违背了分页机制“允许离散分配”的初衷,且浪费内存。
2. 单级页表的局限性
- 问题1:连续页框需求
页表必须完整驻留内存,且需连续存储,与分页设计目标冲突。
- 问题2:局部性浪费
进程实际运行时仅访问少数页,但单级页表需维护全部映射,导致内存冗余。
3. 解决方案:多级页表
思想:将单级页表拆分为多级结构,按需加载,避免连续存储。
以二级页表为例(32位系统):
1. 虚拟地址划分:
- 10位:一级页表索引(页目录)。
- 10位:二级页表索引。
- 12位:页内偏移(4KB页大小)。
2. 结构设计:
- 一级页表(页目录):
- 含1,024个表项,每项指向一个二级页表。
- 大小:1,024 * 4{字节} = 4{KB}(仅需1个物理页框)。
- 二级页表:
- 共1,024个二级页表,每个含1,024个表项。
- 仅需为实际使用的虚拟地址区域分配二级页表,未使用的区域不分配。
3. 优势:
- 离散存储:各级页表可分散在物理内存中,无需连续。
- 按需加载:仅活跃的二级页表需驻留内存,节省空间。
- 兼容性:仍覆盖全部4GB虚拟地址空间(1,024 * 1,024 = 1,048,576个页)。
2.4 页目录结构
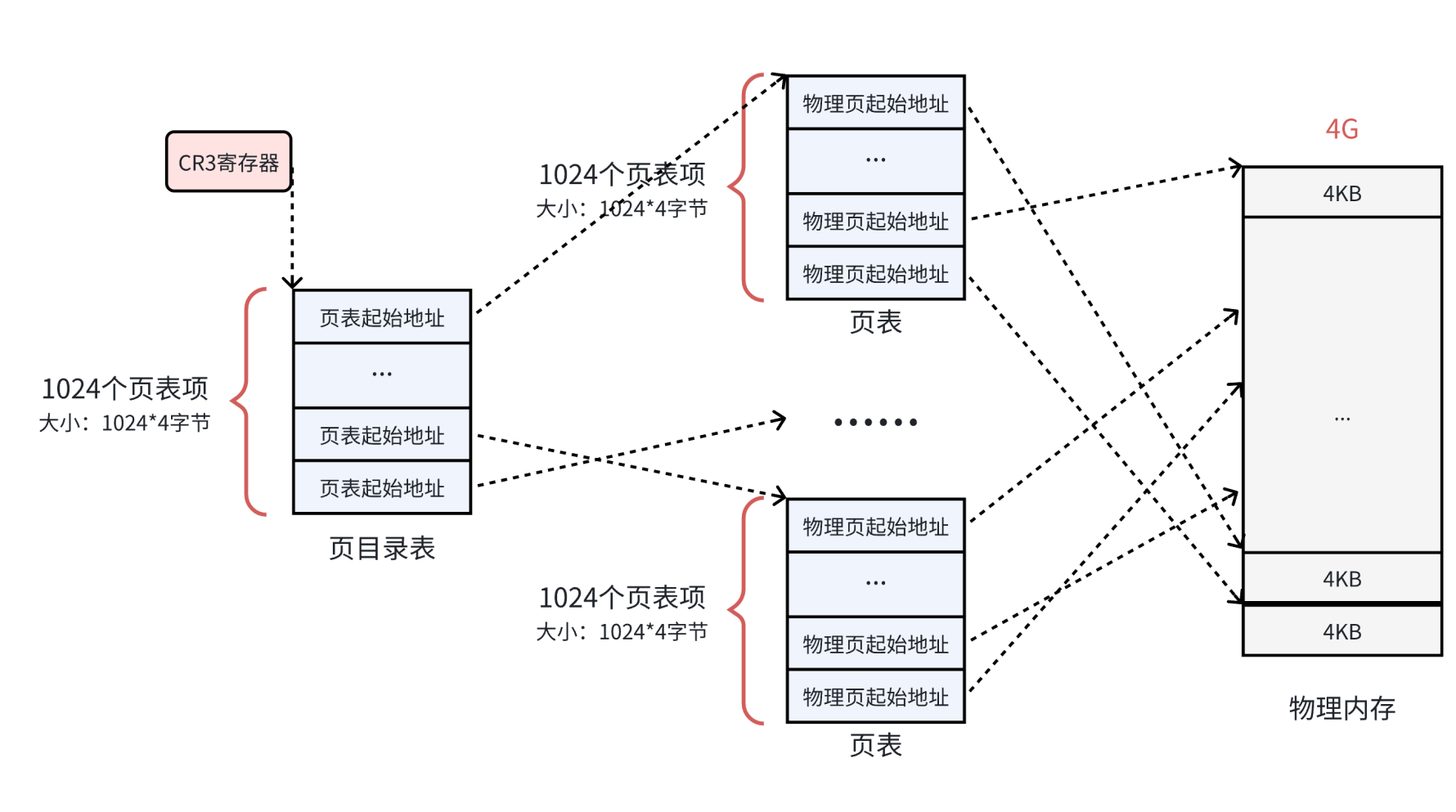
虚拟地址结构解析(32位系统,4KB页)
| 10位 (页目录索引) | 10位 (页表索引) | 12位 (页内偏移) |页目录索引(前10位):
- 取值范围:[0, 1023],对应页目录的1,024个表项。
- 每个表项存储下级页表的物理地址。
页表索引(中间10位):
- 定位到具体页表中的表项,存储目标页框的物理地址。
页内偏移(后12位):
- 与页框物理地址拼接,得到最终物理地址:
- 物理地址=页框基地址+页内偏移物理地址
关键操作:
- CPU通过MMU自动完成两级页表查询(页目录→页表→页框)。
- TLB(快表)缓存近期映射,加速转换。
2.5 虚拟地址与进程管理资源解析
1. 虚拟地址的本质:
- 虚拟地址是CPU看到的地址空间,是进程访问资源的唯一接口
- 每个虚拟地址对应一个资源(物理内存/文件/设备等),是资源的抽象代表
- 32位系统通常有4GB虚拟地址空间(0x00000000-0xFFFFFFFF)
2. 管理数据结构:
- `mm_struct`:进程内存的"总控结构",包含整个地址空间的统计信息
struct mm_struct {unsigned long task_size; /* 地址空间大小 */pgd_t *pgd; /* 页全局目录 */struct vm_area_struct *mmap; /* 内存区域链表 */// ...};- `vm_area_struct`:描述虚拟内存区域(VMA)的"明细表"
struct vm_area_struct {unsigned long vm_start; /* 区域起始地址 */unsigned long vm_end; /* 区域结束地址 */struct file *vm_file; /* 映射的文件(如果有) */// ...};3. 页表的本质:
- 页表是虚拟地址到物理地址的转换地图(多级页表实现)
- 通过MMU硬件完成动态转换,进程切换时通过CR3寄存器切换页表
- 页表项不仅包含物理地址,还包含权限位(R/W/X、用户/内核等)
4. 地址空间布局示例(x86 Linux):
0xFFFF_FFFF +-----------+| 内核空间 | 所有进程共享
0xC000_0000 +-----------+| 栈(stack) | 向下增长+-----------+| ... |+-----------+| 堆(heap)| 向上增长+-----------+| BSS段 |+-----------+| 数据段 |+-----------+| 代码段 |
0x0804_8000 +-----------+| 保留区域 |
0x0000_0000 +-----------+关键结论:
1. 虚拟地址是资源的代表,通过页表实现间接访问,页表是一张虚拟到物理的地图
2. 资源共享的本质是多个页表项指向同一物理资源,是虚拟地址的共享
3. 线程轻量的本质是共享大部分地址空间(mm_struct)
4. 虚拟地址、mm_struct、v_area_struct本质:进行资源的统计数据和整体数据
5. 线程进行资源划分:本质是划分地址空间,获得一定范围的虚拟地址,再本质,就是对页表的划分
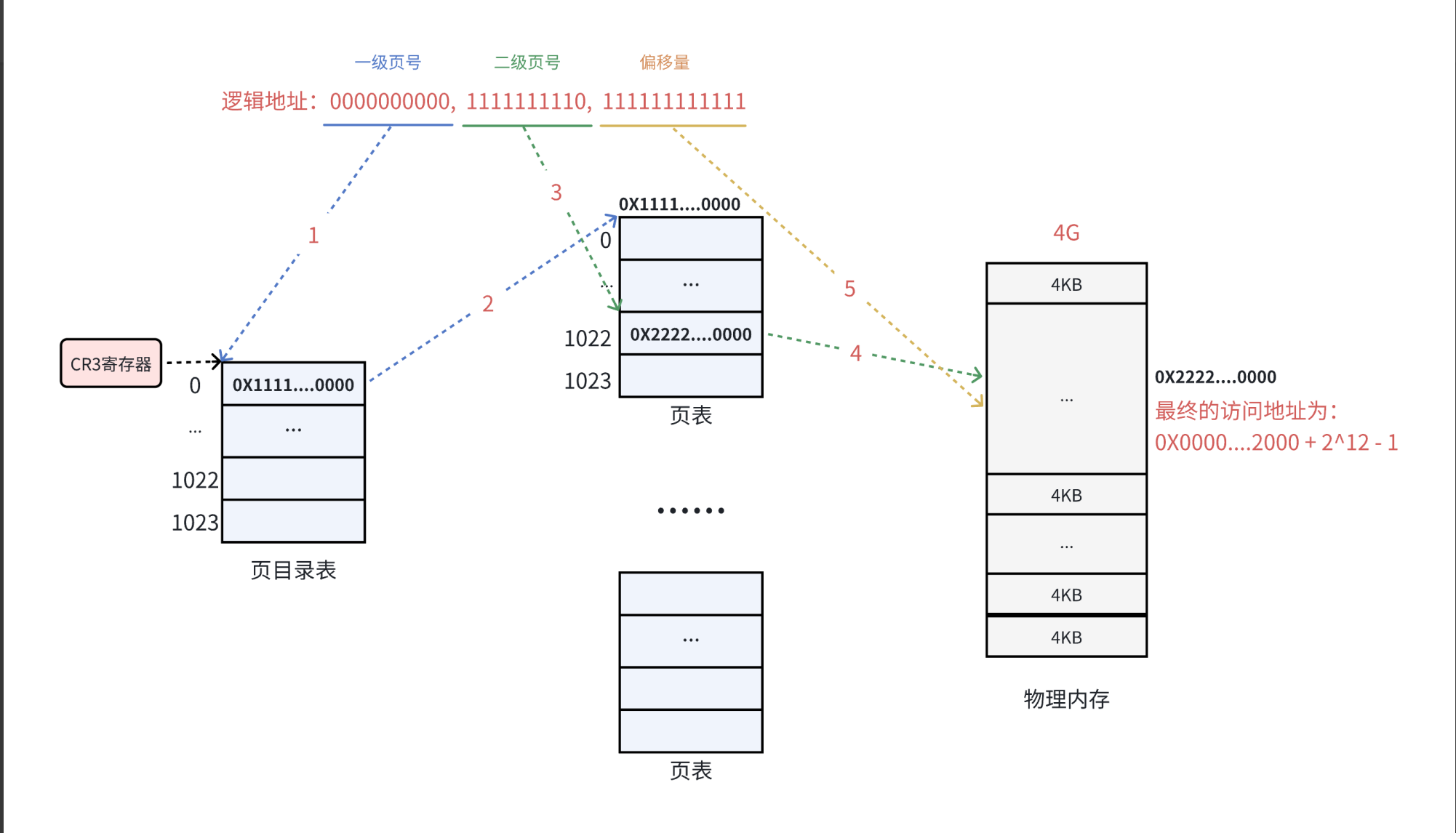
2.6 两级地址的转换
物理地址生成示例
假设虚拟地址:0x12345678
页目录基地址:0x1000
页表基地址:0x2000
页框物理地址:0x8000
转换步骤:
-
拆分虚拟地址:
-
页目录索引:
0x12345678 >> 22 & 0x3FF = 0x48 -
页表索引:
0x12345678 >> 12 & 0x3FF = 0x345 -
页内偏移:
0x678
-
-
查页目录:
0x1000 + 0x48*4→ 获取页表地址0x2000。 -
查页表:
0x2000 + 0x345*4→ 获取页框地址0x8000。 -
物理地址:
0x8000 + 0x678 = 0x8678。
2.7 缺页中断
(1)当目标内存页出现以下情况时:
-
物理内存中无对应的物理页
-
物理页存在但无访问权限
(2)CPU将无法获取数据并触发缺页错误。由于数据缺失会导致计算中断,此时:
-
CPU暂停当前用户进程的执行
-
进程从用户态切换到内核态
-
缺页中断交由内核的Page Fault Handler处理

new和malloc本质上就是对物理内存的延迟申请。首先申请虚拟地址但未申请物理地址,等到真正使用时发生缺页中断,再申请物理地址。
总结
可执行程序也是文件,文件在磁盘那上都是按照4KB存储的。物理内存也被操作系统划分为4KB的内存块。
页框,struct page,struct page mem[1048576],对内存的管理转化成为对数组的管理。
最终物理地址 = 起始物理地址+页内(4KB)偏移
申请物理内存:
(1)查数组,改page
(2)建立内核数据结构的对应关系
3. 线程的优点
1. 创建与切换开销
- 线程创建
代价更小:仅需分配栈和少量寄存器,共享进程资源(内存、文件描述符等)。
- 进程创建
代价更大:需独立分配内存空间、页表、文件资源等,内核管理成本高。
用户级线程的切换完全在用户空间进行,不需要内核介入。只有内核级线程(系统支持线程)的切换才需要内核支持。
- 切换开销对比
|维度 | 线程切换 | 进程切换 |
|------------------|---------------------------------------|-----------------------------|
| 虚拟内存 | 无需切换(共享相同空间) | 需切换页表(TLB刷新) |
| 寄存器 | 部分寄存器需保存/恢复 | 全部寄存器需保存/恢复 |
| 缓存失效 | 仅部分缓存可能失效 | 全部缓存+TLB失效 |
线程切换不会导致TLB、Cache缓存失效。
2. 性能优势
- 资源占用
线程更轻量:共享进程资源(如堆、全局变量),减少内存重复开销。
- 并行能力
多核利用率:线程可并行运行在多处理器上,加速计算密集型任务(如矩阵运算)。
- I/O重叠
非阻塞优化:一个线程等待I/O时,其他线程可继续计算(如Web服务器处理并发请求)。
3. 适用场景
4. 线程的缺点
1. 性能损失
若计算密集型线程数量 超过可用处理器核心数,会导致:
- 额外的同步开销(如锁竞争、上下文切换)
- 资源争用(CPU时间片被频繁切换,缓存利用率下降)
简单来说就是线程创建太多会导致切换成本太高,反而导致性能损失
例如4个计算密集型线程运行在2核CPU上 → 线程频繁切换,实际吞吐量可能低于单线程。
2. 健壮性降低
- 共享数据风险
- 线程间共享变量可能导致:
- 竞态条件(Race Condition):未同步的并发访问引发数据不一致。
- 死锁(Deadlock):多个线程互相等待对方释放锁。
// 线程不安全的计数器
int counter = 0;
void increment() { counter++; } // 多线程并发调用时结果可能错误3. 缺乏访问控制
| 维度 | 进程 | 线程 |
|---|---|---|
| 权限隔离 | 系统调用仅影响当前进程 | 系统调用(如chdir())影响整个进程 |
| 资源管理 | 独立内存空间,崩溃不扩散 | 线程崩溃可能导致整个进程退出 |
例如线程A调用exit() → 整个进程终止,其他线程也被强制结束。
但缺乏访问控制也意味着线程共享资源比较容易。
4. 编程难度提高
5. 线程异常
在多线程环境下,线程是进程的执行单元,共享进程的地址空间和资源(如文件描述符、信号处理等)。当单个线程出现严重异常时(如 **除零错误、野指针访问、段错误**)导致线程崩溃时,整个进程也会随之崩溃。
关键原因包括:
- 信号机制的全局性:
- 线程的异常(如 `SIGSEGV`、`SIGFPE`)会发送给**整个进程**,而非仅限异常线程。
- 默认情况下,这些信号会终止进程(除非程序自定义了信号处理函数)。
- 共享地址空间:
- 线程的非法内存访问(如野指针)可能破坏其他线程的数据,使进程状态不可恢复。
线程异常 vs 进程异常
| 维度 | 线程异常 | 进程异常 |
|------------------|----------------------------|----------------------------|
| 影响范围 | 导致整个进程终止 | 仅终止当前进程 |
| 信号处理 | 信号发送到进程 | 信号发送到进程 |
| 资源回收 | 进程所有资源被释放 | 仅当前进程资源被释放 |
线程异常 ≈ 进程异常:因共享地址空间和信号机制,单个线程崩溃会牵连整个进程。
6. linux进程vs线程
1. 核心角色
(1)进程是资源分配的基本单位
(2)线程是CPU调度的基本单位
2. 资源共享对比
(1)共享的进程资源(所有线程共用):
- 虚拟地址空间(代码段、堆、全局变量)
- 文件描述符、信号处理函数、当前工作目录
- 用户ID、组ID等进程属性
(2)线程私有数据:
线程ID、寄存器状态、errno、信号屏蔽字、调度优先级、栈等。
3. 创建与切换开销
| 操作 | 进程 | 线程 |
|------------------|--------------------------------------------------|----------------------------------------|
| 创建开销 | 高(需复制页表、文件描述符表等) | 低(仅分配栈和寄存器,共享进程资源) |
| 切换开销 | 高(需切换CR3寄存器,TLB刷新) | 低(地址空间不变,仅切换线程上下文) |
4. 通信与同步
- 进程间通信(IPC):
需通过 **管道、消息队列、共享内存、信号量** 等机制(跨越地址空间)。
- 线程间通信:
直接读写 **共享全局变量**,但需同步机制(如互斥锁、条件变量)。
- 进程 = 资源容器,线程 = 执行流
7.线程示例
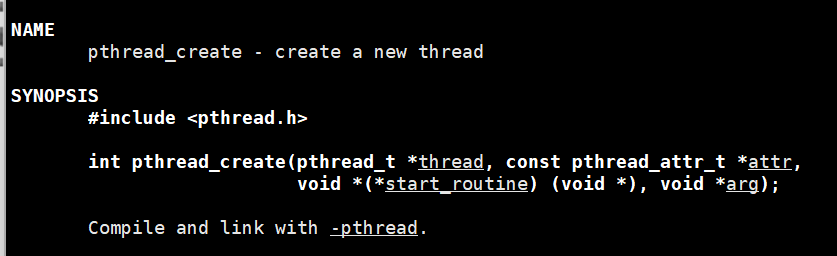

表明pthread_create不是系统调用,使用需要编译并连接pthread库
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>void *threadrun(void *args)
{std::string name = (const char*)args;while(true){std::cout << "我是新线程: name: " << name << std::endl;sleep(1);}return nullptr;
}
int main()
{pthread_t tid;pthread_create(&tid, nullptr, threadrun, (void*)"thread-1");while(true){std::cout << "我是主线程..." << std::endl;sleep(1);}return 0;
}thread: Thread.ccg++ -o $@ $^ -lpthread
.PHONY: clean
clean:rm -f thread

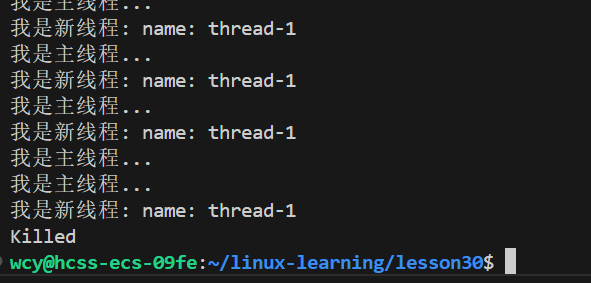
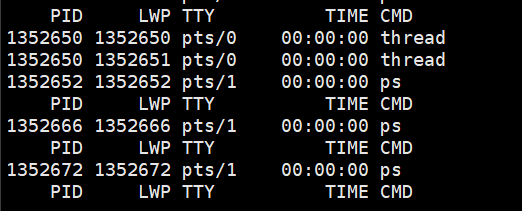
可以看到,当kill其中一个线程时,两个线程都停止了,说明线程之间共享进程资源
查看线程:ps -aL
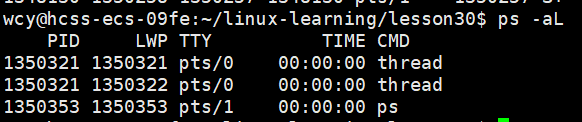
LWP:light weight process 轻量级进程
在task_struct中表示进程的除了pid外还有lwp,当进程中只有一个线程时pid=lwp。所以CPU调度时看的是lwp
健壮性较低,任何一个线程崩溃都会导致整个进程崩溃

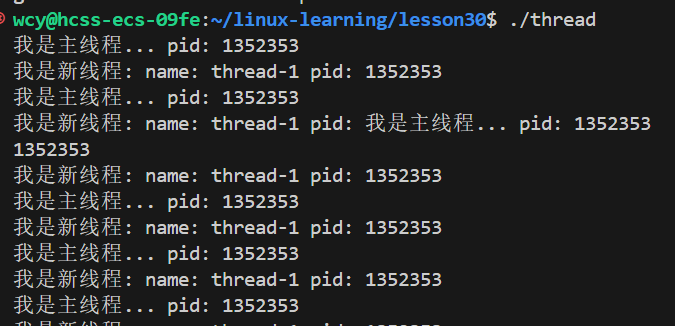
消息混杂在一起,显示器文件本质上也是共享性资源,在没有加保护的时候会发生原子性错误
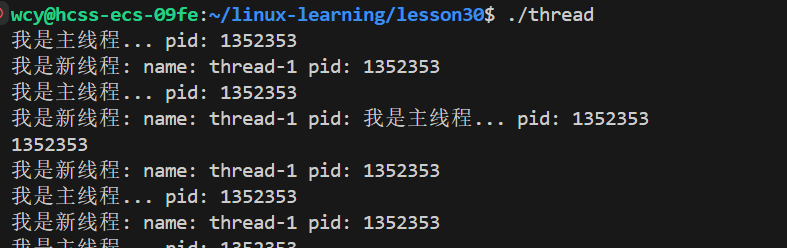
linux系统不存在真正意义上的线程,OS中中只有轻量级进程,线程时我们的叫法,linux只会提供轻量级进程的系统调用
下面是创建和父进程共享地址空间的子进程
 由于用户只认线程,所有的操作系统教程只讲线程,因此在用户和linux系统之间添加一层软件层,即pthread库,pthread库把创建轻量级线程的方法封装起来,给用户提供一批创建线程的接口,这样用户就不用关心底层的LWP了。
由于用户只认线程,所有的操作系统教程只讲线程,因此在用户和linux系统之间添加一层软件层,即pthread库,pthread库把创建轻量级线程的方法封装起来,给用户提供一批创建线程的接口,这样用户就不用关心底层的LWP了。
因此linux的线程实现时在用户层实现的,我们称之为用户级线程, pthread库称之为原生线程库。
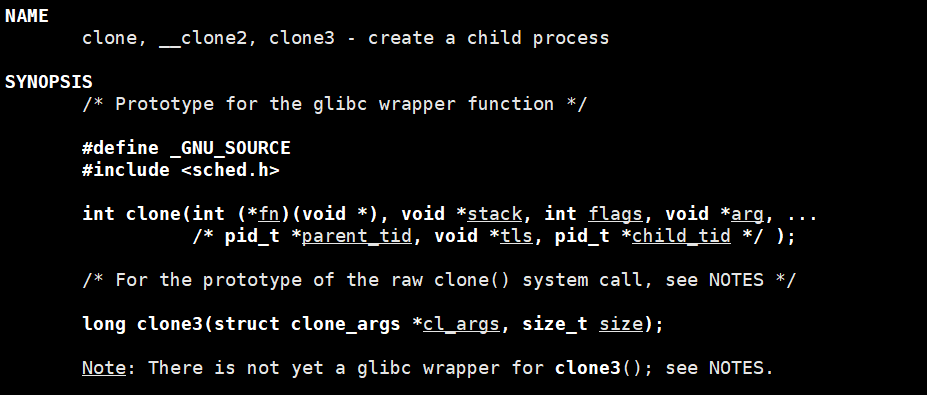
pthread_create的底层其实封装的就是clone
c++11的多线程在linux下,本质上也是封装了pthread库。在windows下是封装windows创建进程的接口。通过条件编译形成库,解决了语言的跨平台和可移植性问题