Redis——三大策略
过期删除策略
Redis可以对key设置过期时间,因此需要有相应的机制将已过期的键值对删除
设置了过期时间的key会存放在过期字典中,可以用presist命令取消key过期时间
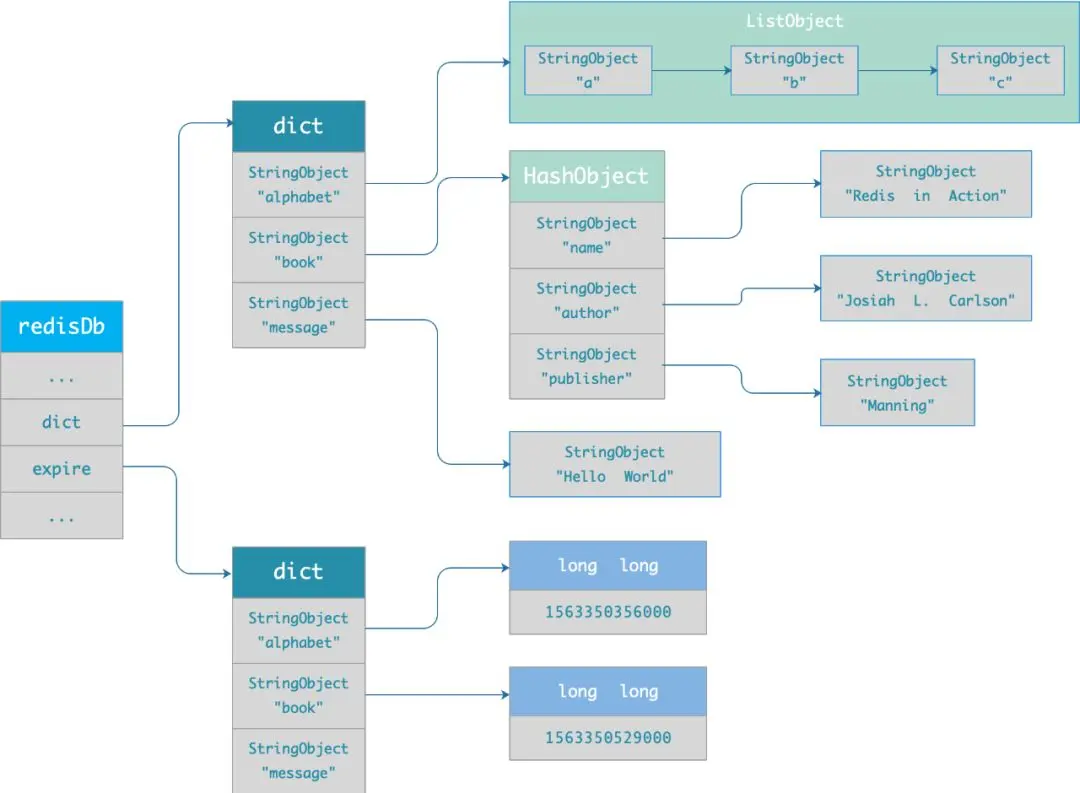
过期字典存储在redisDb结构中:
typedef struct redisDb {dict *dict; /* 数据库键空间,存放着所有的键值对 */dict *expires; /* 键的过期时间 */....
} redisDb;过期字典数据结构:
- key是一个指针,指向某个键对象
- value是一个long long类型整数,保存key的过期时间
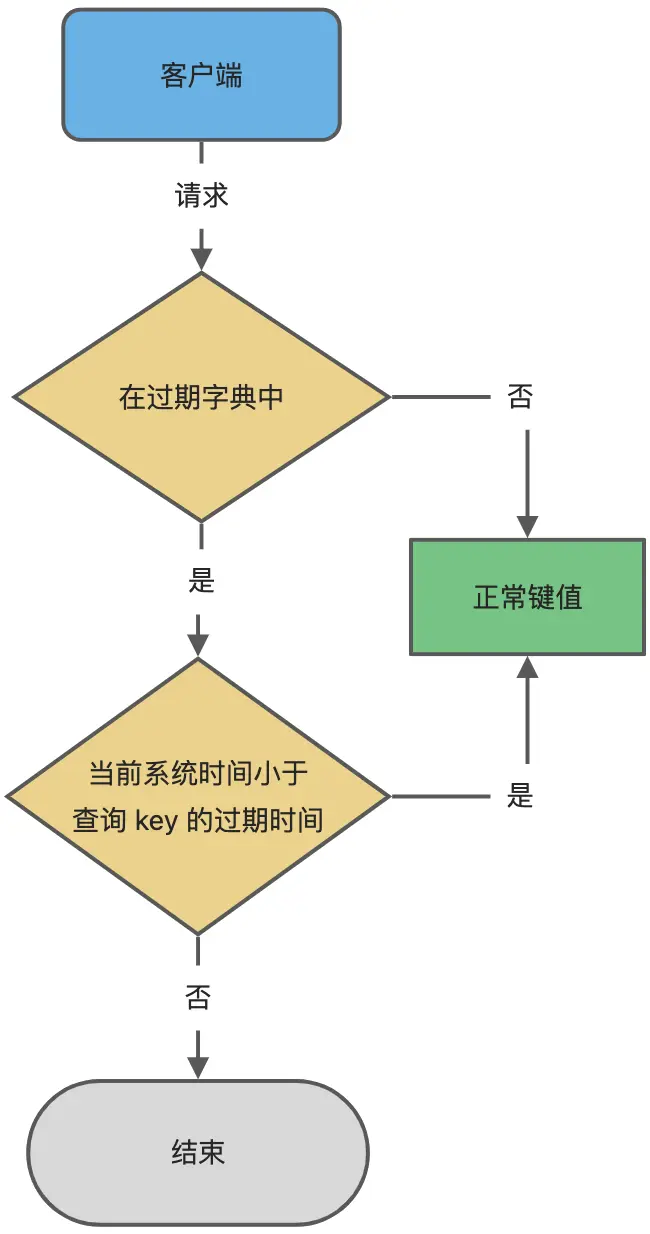
过期判断流程:
- 字典实际上是哈希表,当我们查询一个key时,Redis会先检测该key是否存在于过期字典中
- 如果不在,则直接读取键值
- 如果存在,则会获取该key的过期时间,与当前系统时间进行对比,如果比系统时间小则判断为过期
三种过期删除策略:
定时删除:
设置key过期时间的同时,创建一个定时任务,由事件处理器自动执行key的删除操作
- 优点:保证过期key被尽快删除,也就是内存尽快释放。对内存友好
- 缺点:过期key较多时,删除过期key需要占用CPU时间进行处理,可能对服务器响应时间和吞吐量造成影响,对CPU不友好
惰性删除:
不主动删除过期key,访问数据库的key时才检查是否过期,并删除过期key
- 优点:每次访问时才触发检查和删除过期key操作,所以对CPU友好
- 缺点:若过期key一直未被访问,那么它占用的内存就不会释放,对内存不友好
定期随机删除:
每隔一段时间随机取出一定数量(Redis默认20个)的key进行检查,并删除其中的过期key
- 优点:限制删除操作的执行频率,减少对CPU的影响,同时可释放一定内存
- 缺点:执行频率较高会导致对CPU影响较大,执行频率较低又会导致无效内存堆积
Redis的删除策略实现:
惰性删除+定期随机删除策略,在合理使用CPU时间和避免内存浪费之间取得平衡
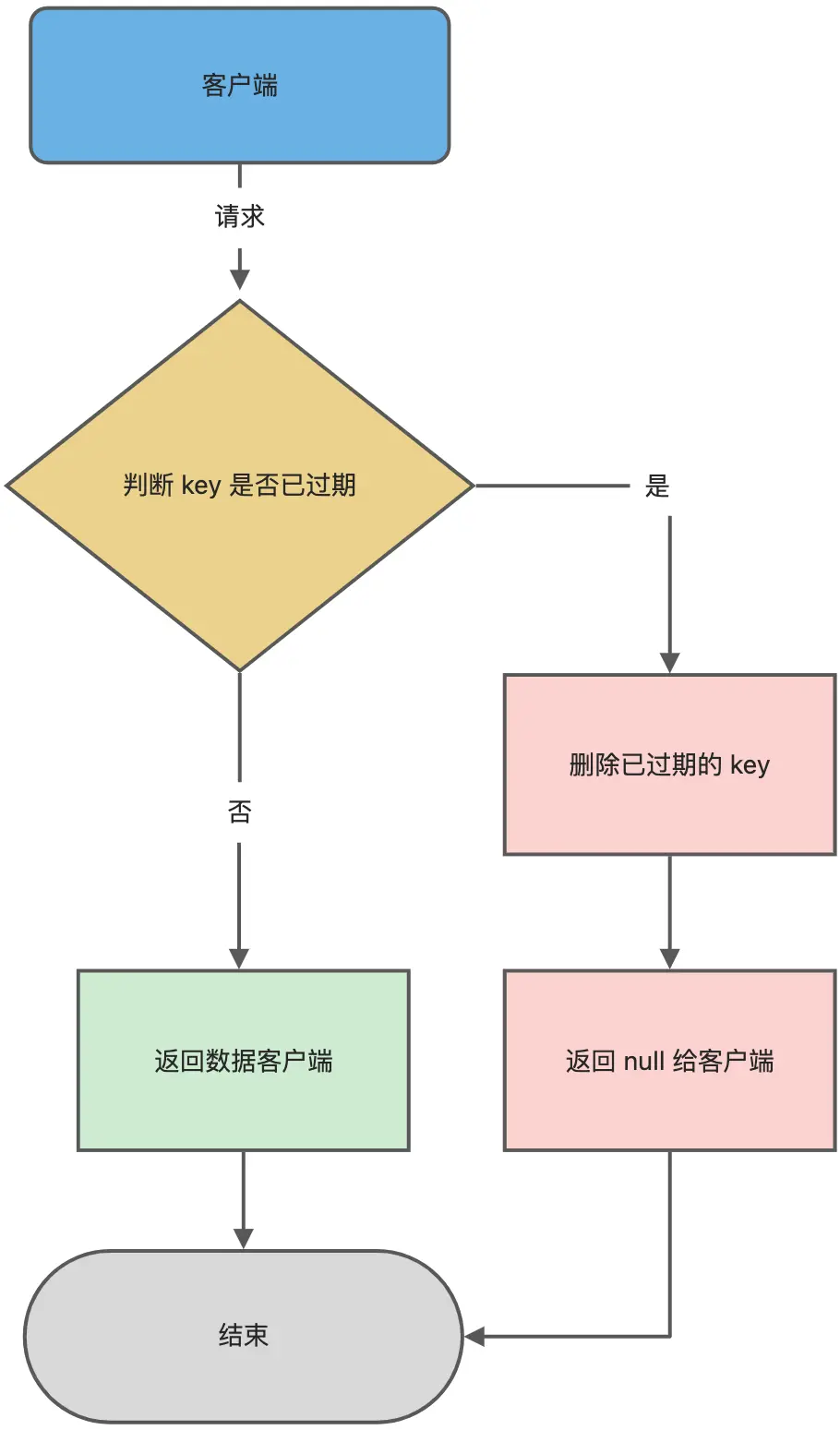
Redis如何实现惰性删除?
通过expireIfNeeded函数实现:
int expireIfNeeded(redisDb *db, robj *key) {// 判断 key 是否过期if (!keyIsExpired(db,key)) return 0;..../* 删除过期键 */....// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :dbSyncDelete(db,key);
}如果key过期,可选择同步删除或异步删除,并返回null:
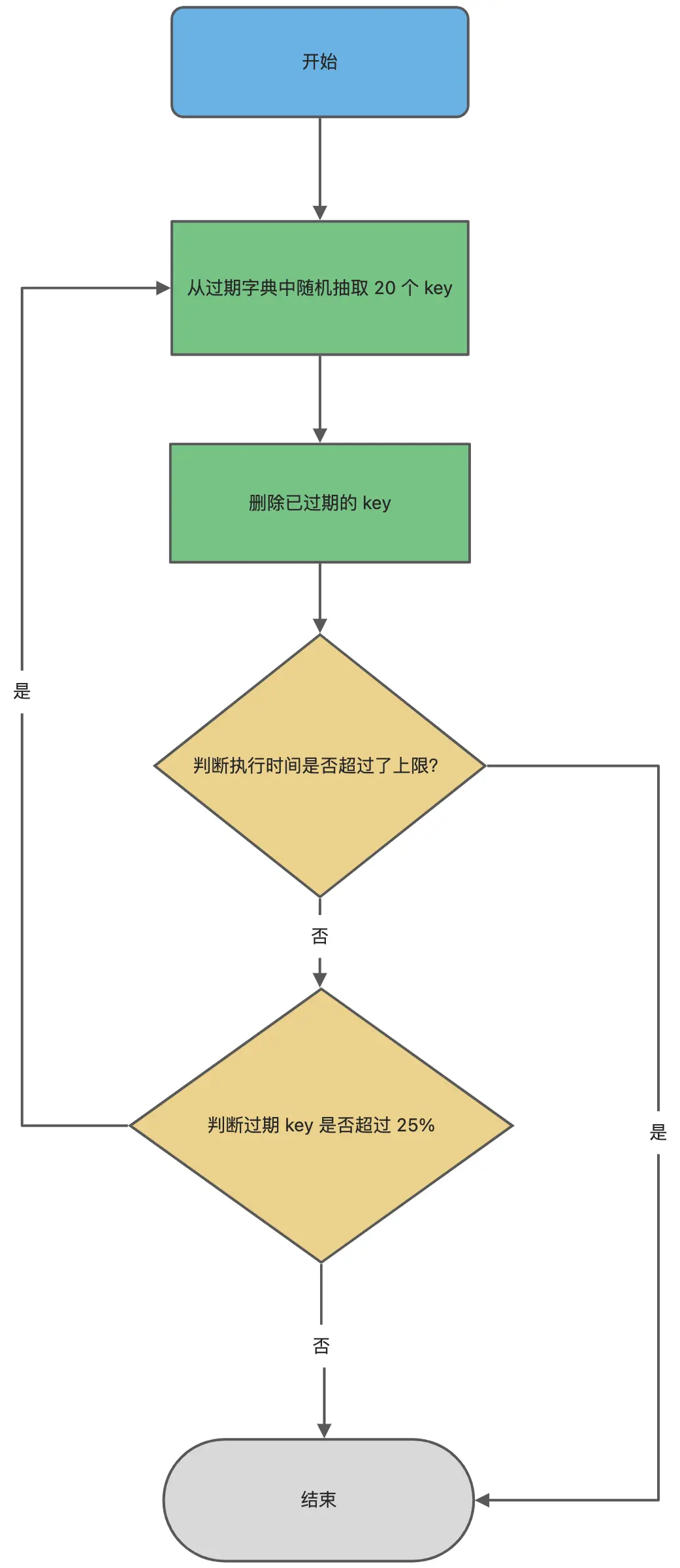
Redis如何实现定期随机删除?
- 间隔检查时间:默认每秒进行10次过期随机抽查,可通过redis.conf的hz参数进行配置
- 随机抽查数量:默认20个,但并不是每次都会检查到10次才结束,如果单次检查中过期Key占比超过25%(即5个以上),会继续重复抽样删除,直到比例低于25%或总耗时达到25ms上限,防止线程卡死。
内存淘汰策略
Redis运行内存超过设定的最大内存之后,会通过淘汰策略删除符合条件的key来保障Redis高效运行。可以在redis.conf中的参数maxmemory <bytes>来设定最大允许内存,默认为0,也就是没有大小限制。
Redis的内存淘汰策略
不进行数据淘汰的策略(Redis3.0后默认的淘汰策略)
- 当内存超限时,不淘汰任何数据
- 禁止新数据写入并报错通知
- 查询和删除操作正常进行
进行数据淘汰的策略
在设置了过期时间的数据中淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值
- volatile-ttl:优先淘汰更早过期的键值
- volatile-lru(3.0前的默认淘汰策略):淘汰最久未使用的键值
- volatile-lfu:淘汰最少使用的键值
在所有数据中淘汰:
- allkeys-random:随机淘汰
- allkeys-lru:淘汰最旧未使用
- allkeys-lfu:淘汰使用最少的
LRU(Least Recently Used)最久未使用:
- 传统的LRU算法是使用链表实现的,被访问到的数据会移动到表头。但Redis没有使用,因为缓存链表需要额外空间,且链表频繁变动有性能损耗。
- Redis则是在对象结构体中添加一个额外字段用于记录此数据的最后一次访问时间。
- 内存淘汰时,Redis采用随机采样的方式来淘汰数据,随机取5个值(可配置)并淘汰最久未使用的那个
- 但LRU会造成缓存污染和误删除热点数据问题,因为它只记录了最近访问时间,可能会导致不怎么使用的数据保留下来,以及误删除一定时间内未访问的热门数据。
LFU(Least Frequent Used)最不常使用:
在LRU的基础上,增加了数据访问频次信息,更具访问频率来淘汰数据。
缓存更新策略
1、Cache Aside(旁路缓存)策略
由应用程序与缓存和数据库交互
写策略:
- 先更新数据库中的数据
- 再删除缓存中的对应数据
读策略:
- 若读取的数据命中了缓存,直接返回数据
- 读取的数据没有命中缓存,从数据库读取数据并更新缓存,再返回数据
缺点:
- 数据库已更新但由于并发请求查询问题,缓存删除后又被更新为旧数据,造成数据库和缓存数据不一致问题(尤其出现在先删除缓存再更新数据库时)
- 先更新数据再删除缓存时,可能会出现读写请求并发时,读请求读取数据库,而数据库更新完后先删除了缓存,读请求又更新缓存的情况
解决:
- 更新数据库时一起更新缓存,在更新缓存前先加一个分布式锁,这样在同一时间只允许一个线程更新缓存
- 给缓存加较短的过期时间
2、Read/Write Through(读穿写穿)策略
应用程序只与缓存交互,缓存与数据库交互
读策略:
- 先查询缓存中是否存在数据,若不存在则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用
写策略:
- 若缓存中数据已存在,更新缓存中的数据,并且由缓存组件同步更新到数据库中,然后缓存组件告知应用程序
- 缓存数据不存在则直接更新数据库,然后返回
缺点:
- 无论是Memcached还是Redis都不提供写入数据库和自动加载数据库中数据的能力,只有本地缓存可以考虑添加
3、Write Back(写回)策略
更新数据时只更新缓存,并将缓存数据设为脏数据,随后立马返回数据。由开发者决定时机异步批量更新脏数据到数据库
优点:
- 适合写多的场景,只需要更新缓存,不涉及到磁盘
缺点:
- 数据不是强一致,且数据有丢失风险