布隆过滤器和布谷鸟过滤器
原文链接:布隆过滤器和布谷鸟过滤器
布隆过滤器
介绍
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,检查值是“可能在集合中”还是“绝对不在集合中”
- 空间效率高:通常比精确数据结构占用更少的空间
- 查询速度快:常数时间复杂度 O(1)
- 误报率可控:通过调整哈希函数的数量和布隆过滤器的大小可控制误报率
- 不能删除元素:一旦向布隆过滤器中添加了元素,则不能从中删除
原理
本质是由长度为 m 的向量或列表(仅包含 0、1),最初所有值均设为 0

为了将数据添加到布隆过滤器中,会提供 K 个不同的哈希函数,并将结果位置上对应位置设为“1”,使用多(此处假设为 3 个)个哈希函数得到多个索引值,如输入“semlinker”时,预计得到 2、4、6,将相应位置设为 1
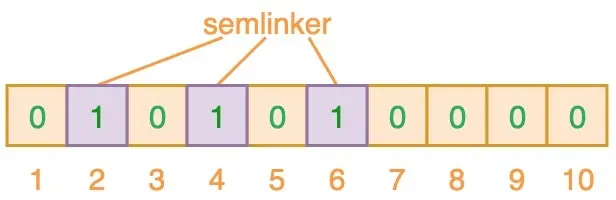
再输入“kakuqo”时,哈希得到 3、4、7,此刻的 4 被标记了两次
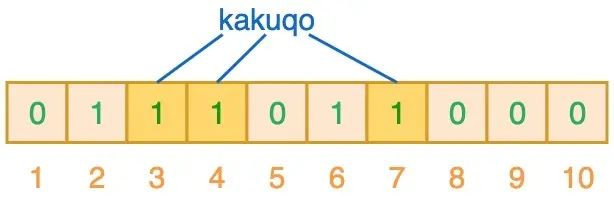
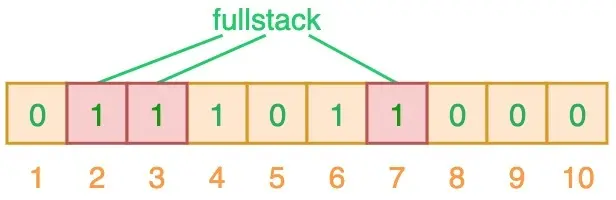
当我们对值进行搜索时,先使用 3 个哈希函数对搜索值进行哈希运算,例如输入“fullstack”时,得到 2、3、7,相应位置都为 1,意味着可能已经插入到集合了。
布隆过滤器的误判率
- n:已经添加的元素
- k:哈希次数
- m:布隆过滤器长度
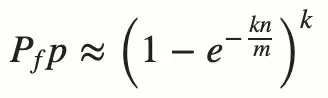
应用场景
- 网页爬虫对 URL 去重,避免爬取相同 URL
- 反辣椒邮件,从数十亿个辣椒邮件列表中判断某邮箱是否为垃圾邮箱
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找
代码实现
package com.yingzi.data_structure;import java.util.BitSet;
import java.util.Random;public class BloomFilter {private final BitSet bitSet;private final int[] hashFunctions;public BloomFilter(int expectedElements, double falsePositiveRate) {// 计算位数组大小int bits = _optimalSize_(expectedElements, falsePositiveRate);// 创建位数组this.bitSet = new BitSet(bits);// 计算所需的哈希函数数量int hashCount = _optimalHashCount_(expectedElements, bits);this.hashFunctions = generateHashFunctions(hashCount);}private static int optimalSize(int expectedElements, double falsePositiveRate) {return (int) (-expectedElements * Math._log_(falsePositiveRate) / (Math._log_(2) * Math._log_(2)));}private static int optimalHashCount(int expectedElements, int bits) {return (int) (bits / expectedElements * Math._log_(2));}private int[] generateHashFunctions(int hashCount) {Random random = new Random();int[] hashes = new int[hashCount];for (int i = 0; i < hashCount; i++) {hashes[i] = random.nextInt();}return hashes;}public void add(String item) {for (int hash : hashFunctions) {int index = Math._abs_(hash ^ item.hashCode()) % bitSet.size();bitSet.set(index);}}public boolean mightContain(String item) {for (int hash : hashFunctions) {int index = Math._abs_(hash ^ item.hashCode()) % bitSet.size();if (!bitSet.get(index)) {return false;}}return true;}
}
- 构造函数 (
BloomFilter): 接收期望的元素数量和期望的误报率。根据这些信息计算出合适的位数组大小和哈希函数数量。 optimalSize方法: 根据公式计算最优的位数组大小。optimalHashCount方法: 根据公式计算最优的哈希函数数量。generateHashFunctions方法: 生成指定数量的哈希函数。add方法: 将元素添加到布隆过滤器中。对于每个哈希函数,计算出一个索引并设置该位。mightContain方法: 检查一个元素是否可能存在于布隆过滤器中。对于每个哈希函数,检查相应的位是否被设置。如果所有相关的位都被设置,则认为该元素可能存在于布隆过滤器中。
public class BloomFilterExample {public static void main(String[] args) {// 假设我们期望有 1000 个元素,希望误报率小于 0.1%BloomFilter bloomFilter = new BloomFilter(1000, 0.001);// 添加一些元素String[] elementsToAdd = {"hello", "world", "java", "programming"};for (String element : elementsToAdd) {bloomFilter.add(element);}// 检查一些元素是否存在System._out_.println("Does 'hello' exist? " + bloomFilter.mightContain("hello")); // trueSystem._out_.println("Does 'world' exist? " + bloomFilter.mightContain("world")); // trueSystem._out_.println("Does 'nonexistent' exist? " + bloomFilter.mightContain("nonexistent")); // false}
}
变体
在海量数据处理的场景中,我们往往无法预测数据的规模,而重建过滤器的开销又过大,因此需要一个支持删除元素的过滤器,根据不同的实现方法,衍生以下变体
计数布隆过滤器:不再使用一个计数器,而是使用一个计数器,删除一个元素时将对应位置的计数减 1,当计数为零时代表元素不存在,该方法虽然支持了删除,但空间随着计数器大小成倍增加阻塞布隆过滤器:多层级的布隆过滤器(类似 CPU 的多级缓冲),将集合分为多个布隆过滤器(每个过滤器相互独立,哈希函数也不同),首先决定哈希到哪个布隆过滤器,再在对应的布隆过滤器中使用对应的哈希函数进行插入,该方法的空间利用率高且假阳率低,实现较复杂,且需要手动调整块大小和哈希函数,否则会因为某个小布隆过滤器负载不均衡导致假阳率增加动态左计数布隆过滤器:结合计数、阻塞的思想。将集合分为多个小布隆过滤器,并且每个块中的每个位置都会维护一个计数器。该方法比起计数布隆过滤器,空间利用率更高,但在分布式场景下和布计数器的开销也会严重增加商过滤器:将集合划分为多个桶,每个桶中保存一个元素和一个余数。对元素哈希得到一个整数值,整数值的高位为桶的下标,地位代表余数,通过对比对应下表的余数是否相同来判断元素存在,该方法的缺点在于需要使用额外的元数据来管理每个元素,桶数需要为 2 的幂次方
在所有变体中,应用最广泛、效果最好的是布谷鸟过滤器
布谷鸟过滤器
介绍
基于布谷鸟哈希算法实现的过滤器,存储了哈希值的布谷鸟哈希表
相比布隆过滤器的优点
-
支持新增和删除元素
-
更节省空间
- 哈希表跟家紧凑
- 在错误率小于 3% 的时候空间性能优于布隆过滤器
- 空间节省 40% 多
-
查询效率高
- 一次哈希
- 而布隆过滤要采用多种哈希函数进行多次哈希
原理
最简单的布谷鸟哈希结构为一维数组结构,会有两个 hash 算法将新来的元素映射到数组的两个位置。若两个位置中有一个位置为空,则将元素直接放进去,若两个位置都满了,就【鸠占鹊巢】随机踢走一个,然后自己霸占该位置
- 保存元素(位置都没有被占):新来元素 a 经过 hash 为(A2,B1)的位置,由于 A2 还没有元素 a,直接落入 A2

- 保存元素(其中一个位置被占):新来元素 b 的 hash 为(A2,B3),由于 A2 已经被 a 占了,所以 b 会落在 b3
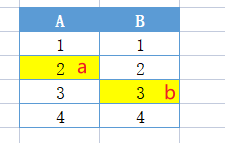
- 保存元素(两个位置都占):新来元素 c 的 hash 为(A2,B3),它会随机将一个元素挤走,这里挤走了 a
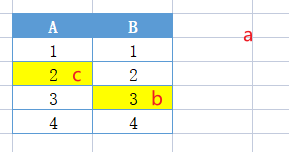
- 被挤掉的元素重新找位置:a 会重新进行 hash,找到还未被占的 B1 位置

问题:若数组太拥挤,将导致连续踢了若干次还未停止,严重影响插入效率。布谷鸟哈希设置一个阈值,当连续占巢行为超出了某个阈值,就认为数组几乎满了,这时需要对它进行扩容
为了提高空间利用率,降低碰撞概率,布谷鸟过滤器在布谷鸟哈希上做了改进, 将其从一维扩展为二维(每个桶存储的元素从 1 个变为 n 个),且每个位置中只存储几个 bit 的指纹,而非完整的元素
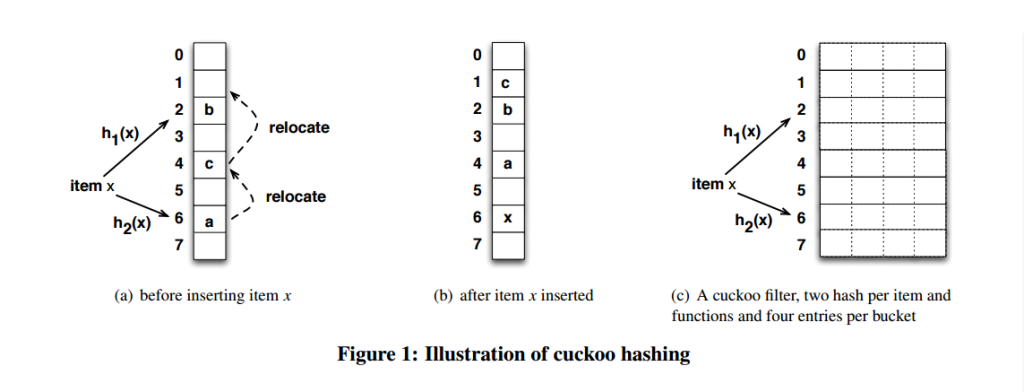
每个桶中存储了 4 个 slot,只有当一个桶中的所有 slot 都被填满的时候,才会使用替换的策略。这里的桶结构使用了一个二维数组来表示
应用场景
布谷鸟过滤器适用于需要支持动态数据集的应用场景,特别是需要支持删除的情况,具体应用场景包括但不限于
缓存系统:用于缓存热点数据,减少后端系统的负载数据库:在数据库中作为索引结构,提高查询效率网络路由:在网络设备中用于快速查找路由表恶意软件检测:快速检测已知的恶意软件签名分布式系统:一致性检查,确保数据的一致性
代码实现
package com.yingzi;import java.util.Random;public class cuckooFilter {static final int _MAXIMUM_CAPACITY _= 1 << 30;//最大的踢出次数private final int MAX_NUM_KICKS = 500;//桶的个数private int capacity;//存入元素个数private int size = 0;//存放桶的数组private Bucket[] buckets;private Random random;//构造函数public cuckooFilter(int capacity) {capacity = _tableSizeFor_(capacity);this.capacity = capacity;buckets = new Bucket[capacity];random = new Random();for (int i = 0; i < capacity; i++) {buckets[i] = new Bucket();}}/** 向布谷鸟过滤器中插入一个元素** 插入成功,返回true* 过滤器已满或插入数据为空,返回false*/public boolean insert(Object o) {if (o == null)return false;/** 当我们知道 f 和 i1,就可以直接算出 i2,同样如果我们知道 i2 和 f,也可以直接算出 i1 (对偶性)* 所以我们根本不需要知道当前的位置是 p1 还是 p2,* 只需要将当前的位置和 hash(o) 进行异或计算就可以得到对偶位置。* 而且只需要确保 hash(o) != 0 就可以确保 i1 != i2,* 如此就不会出现自己踢自己导致死循环的问题。*/byte f = fingerprint(o);int i1 = hash(o);int i2 = i1 ^ hash(f);if (buckets[i1].insert(f) || buckets[i2].insert(f)) {//有空位置size++;return true;//插入成功}//没有空位置,relocate再插入return relocateAndInsert(i1, i2, f);}_/**_
_ * 对插入的值进行校验,只有当未插入过该值时才会插入成功_
_ * 若过滤器中已经存在该值,会插入失败返回false_
_ */_
_ _public boolean insertUnique(Object o) {if (o == null || contains(o))return false;return insert(o);}_/**_
_ * 随机在两个位置挑选一个将其中的一个值标记为旧值,_
_ * 用新值覆盖旧值,旧值会在重复上面的步骤进行插入_
_ */_
_ _private boolean relocateAndInsert(int i1, int i2, byte f) {boolean flag = random.nextBoolean();int itemp = flag ? i1 : i2;for (int i = 0; i < MAX_NUM_KICKS; i++) {//在桶中随机找一个位置int position = random.nextInt(Bucket._BUCKET_SIZE_);//踢出f = buckets[itemp].swap(position, f);itemp = itemp ^ hash(f);if (buckets[itemp].insert(f)) {size++;return true;}}//超过最大踢出次数,插入失败return false;}_/**_
_ * 如果此过滤器包含对象的指纹,返回true_
_ */_
_ _public boolean contains(Object o) {if(o == null)return false;byte f = fingerprint(o);int i1 = hash(o);int i2 = i1 ^ hash(f);return buckets[i1].contains(f) || buckets[i2].contains(f);}_/**_
_ * 从布谷鸟过滤器中删除元素_
_ * 为了安全地删除,此元素之前必须被插入过_
_ */_
_ _public boolean delete(Object o) {if(o == null)return false;byte f = fingerprint(o);int i1 = hash(o);int i2 = i1 ^ hash(f);return buckets[i1].delete(f) || buckets[i2].delete(f);}_/**_
_ * 过滤器中元素个数_
_ */_
_ _public int size() {return size;}//过滤器是否为空public boolean isEmpty() {return size == 0;}//得到指纹private byte fingerprint(Object o) {int h = o.hashCode();h += ~(h << 15);h ^= (h >> 10);h += (h << 3);h ^= (h >> 6);h += ~(h << 11);h ^= (h >> 16);byte hash = (byte) h;if (hash == Bucket._NULL_FINGERPRINT_)hash = 40;return hash;}//哈希函数public int hash(Object key) {int h = key.hashCode();h -= (h << 6);h ^= (h >> 17);h -= (h << 9);h ^= (h << 4);h -= (h << 3);h ^= (h << 10);h ^= (h >> 15);return h & (capacity - 1);}//hashMap的源码 有一个tableSizeFor的方法,目的是将传进来的参数转变为2的n次方的数值static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= _MAXIMUM_CAPACITY_) ? _MAXIMUM_CAPACITY _: n + 1;}static class Bucket {public static final int _FINGERPINT_SIZE _= 1;//桶大小为4public static final int _BUCKET_SIZE _= 4;public static final byte _NULL_FINGERPRINT _= 0;private final byte[] fps = new byte[_BUCKET_SIZE_];//在桶中插入public boolean insert(byte fingerprint) {for (int i = 0; i < fps.length; i++) {if (fps[i] == _NULL_FINGERPRINT_) {fps[i] = fingerprint;return true;}}return false;}//在桶中删除public boolean delete(byte fingerprint) {for (int i = 0; i < fps.length; i++) {if (fps[i] == fingerprint) {fps[i] = _NULL_FINGERPRINT_;return true;}}return false;}//桶中是否含此指纹public boolean contains(byte fingerprint) {for (int i = 0; i < fps.length; i++) {if (fps[i] == fingerprint)return true;}return false;}public byte swap(int position, byte fingerprint) {byte tmpfg = fps[position];fps[position] = fingerprint;return tmpfg;}}public static void main(String args[]){cuckooFilter c=new cuckooFilter(100);c.insert("西游记");c.insert("水浒传");c.insert("三国演义");System._out_.println(c.contains("水浒传"));}
}
参考资料
高级数据结构与算法 | 布谷鸟过滤器(Cuckoo Filter):原理、实现、LSM Tree 优化
Redis–布谷鸟过滤器–使用/原理/实例
布谷鸟过滤器的简单 Java 实现
【大数据管理】Java 实现布谷鸟过滤器(CF)