基于LLM合成高质量情感数据,提升情感分类能力!!
摘要:大多数用于情感分析的数据集缺乏意见表达的上下文,而上下文对于理解情绪往往至关重要,并且这些数据集主要局限于几种情绪类别。像 GPT-4 这样的基础大型语言模型(Foundation Large Language Models,LLMs)存在过度预测情绪的问题,并且资源消耗过大。为此,我们设计了一个基于 LLM 的数据合成管道,并利用一个大型模型 Mistral-7b 来生成用于训练更易获取、轻量级的 BERT 类型编码器模型的训练样本。我们专注于扩大样本的语义多样性,并提出将生成过程锚定到一个叙事语料库中,以产生以故事角色为中心的独特上下文且不重复的表达,涵盖 28 种情绪类别。通过在 450 GPU 小时内运行 70 万次推理,我们贡献了一个包含 10 万有上下文的样本和 30 万无上下文的样本的数据集,以覆盖这两种情况。我们使用该数据集对预训练编码器进行微调,从而得到了多个情感支柱(Emo Pillars)emoπ模型。我们展示了当这些 emoπ模型针对特定任务(如 GoEmotions、ISEAR、IEMOCAP 和 EmoContext)进行调整时,能够高度适应新领域,并在前三项任务中达到了最先进的性能(State of the Art,SOTA)。我们还对数据集进行了验证,通过统计分析和人工评估确认了我们在表达多样化(尽管中性类别表现稍弱)和上下文个性化方面的措施取得了成功,同时指出需要改进管道中对超出分类体系标签的处理。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 数据合成pipline
1. 内容丰富的指令
2. 多示例生成
3. 软标签
4. 上下文生成与清理
5. 上下文重要性提升
3.2 模型训练与微调
1. 模型选择
2. 无上下文情感分类
3. 有上下文情感分类
四、实验结论
4.1 无上下文情感识别
1. Emo Pillars 合成测试集
2. GoEmotions 数据集
3. ISEAR 数据集
4.2 有上下文情感识别
1. Emo Pillars 合成测试集
2. EmoContext 数据集
五、总结
一、背景动机
文章题目:Emo Pillars emo π : Knowledge Distillation to Support Fine-Grained Context-Aware and Context-Less Emotion Classification
文章地址:https://arxiv.org/pdf/2504.16856
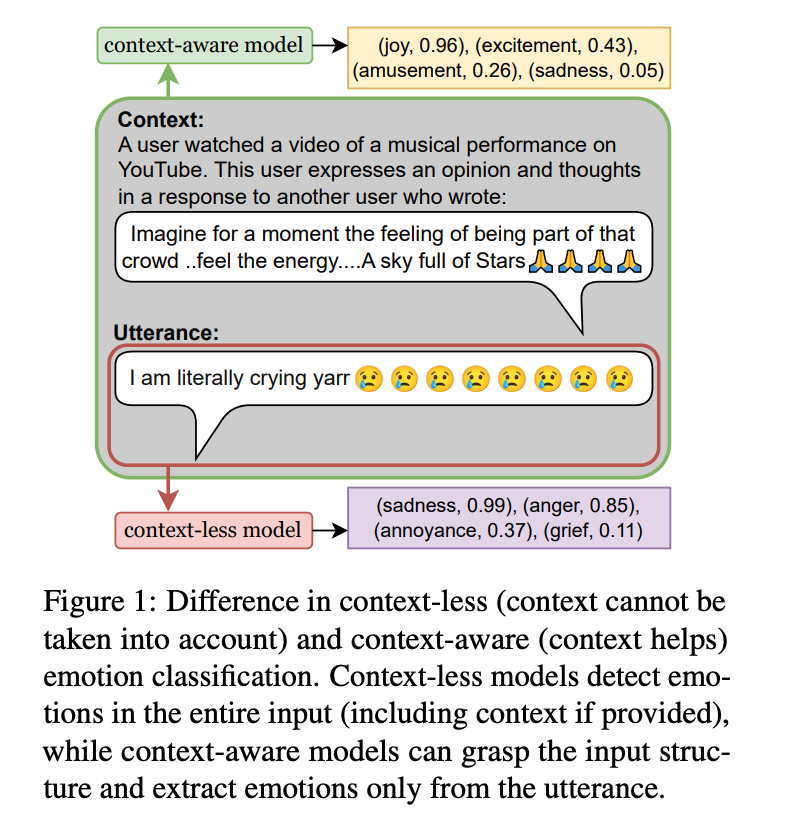
情感分析(sentiment analysis)是自然语言处理(NLP)中的一个重要任务,它旨在从文本中识别和提取情感信息。然而,大多数现有的情感分析数据集缺乏上下文信息,这对于理解情感表达至关重要。此外,现有的数据集通常只涵盖少数几种情感类别,限制了情感分类的细粒度程度。
因此,该文章提出了一个基于LLM的数据合成pipline,利用大型模型(如Mistral-7b)生成训练样本,以支持更轻量级的BERT类型编码器模型。
二、核心贡献
1、设计了一个基于LLM的数据合成pipline,用于生成情感分类数据集。该pipline通过将生成的样本锚定在叙事语料库中,产生具有独特上下文的非重复故事角色中心的表达,覆盖28种情感类别。
2、通过运行700K次推理,消耗450 GPU小时,生成了包含100K有上下文和300K无上下文的样本数据集,用于覆盖两种场景。
3、利用生成的数据集微调预训练编码器模型,开发出多个Emo Pillars emoπ模型。这些模型在多个情感分类任务(如GoEmotions、ISEAR、IEMOCAP和EmoContext)上表现出色,达到或接近SOTA(State-of-the-Art)性能。
4、通过上下文重写步骤,确保上下文在情感理解中的重要性,使得模型在训练阶段学习关注上下文信息。
三、实现方法
3.1 数据合成pipline
1. 内容丰富的指令
-
目标:通过迭代叙事语料库(如故事梗概或新闻报道)中的文本和不同角色(actors),生成多样化的指令。
-
实现方法:
-
使用LLM从叙事文本中提取角色(actors)。这些角色将被用于后续的情感表达生成。
-
迭代语料库中的所有角色,以增加覆盖多种情感和不同立场的样本。
-
2. 多示例生成
-
目标:请求模型在单次推理中生成多个表达(utterances),覆盖多种情感类别,减少重复性。
-
实现方法:
-
请求模型为每个角色生成8个情感表达(utterances),涵盖8种不同的情感类别(非中性情感),并额外生成2个中性情感的表达。
-
提供情感的定义,以减少相关标签(如悲伤和失望)之间的歧义。
-
通过这种方式,模型更有可能生成对比鲜明的示例,其中主要情感表达得更强烈。
-
3. 软标签
-
目标:为每个表达分配多个情感标签,并评估其表达强度,以减少短表达的情感歧义。
-
实现方法:
-
从提示中移除故事梗概,使LLM仅关注当前角色的情感,减少情感幻觉(hallucination)。
-
提供生成表达时的主要情感,允许模型为每个表达分配多个“软”标签(soft labels),并评估每个标签的表达强度(从0到1,步长为0.1)。
-
选择表达强度高于0.3的标签用于后续步骤。
-
4. 上下文生成与清理
-
目标:重构角色表达的背景情境,确保情境不包含情感信息。
-
实现方法:
-
设计提示,使LLM生成的情境围绕角色展开,并在角色表达之前结束,避免透露情感信息。
-
对生成的情境进行清理,移除情感相关的子句,并调整受影响的句子,确保情境中不包含明确的情感信息。
-

5. 上下文重要性提升
-
目标:通过重写表达,降低情感表达的明确性,使上下文成为理解情感的关键。
-
实现方法:
-
在提示中指定,重写表达时应减少情感的明确性,使上下文对情感理解至关重要。
-
原始表达可能包含“害怕”和“安全”等情感标记,而重写后的表达会移除这些标记,使情感更隐晦。
-
3.2 模型训练与微调
生成的数据集被用于微调中等规模的编码器模型(如RoBERTa和BERT),以支持有上下文(context-aware)和无上下文(context-less)的情感分类任务。
1. 模型选择
-
使用了多种预训练的编码器模型,包括BERT、RoBERTa和SentenceBERT。
-
这些模型被训练用于多标签分类任务,每个情感类别使用sigmoid激活函数,并采用二元交叉熵损失函数(binary cross-entropy loss)。
2. 无上下文情感分类
-
数据集:使用生成的无上下文数据集(300K样本)进行训练和评估。
-
实验设置:训练了多个模型,包括BERT、RoBERTa和SentenceBERT,使用默认的AdamW优化器,初始学习率为2e-5,训练了10个epoch,最大序列长度为128,批量大小为64。
-
评估结果:在Emo Pillars合成测试集上,模型在原始表达上表现出色,但在重写表达上性能下降。在GoEmotions数据集上,经过微调的emoπ模型达到了SOTA性能,F1分数为0.55。在ISEAR数据集上,微调后的模型也达到了SOTA性能,F1分数为0.75。
3. 有上下文情感分类
-
数据集:使用生成的有上下文数据集(100K样本)进行训练和评估。
-
实验设置:训练了RoBERTa模型,最大序列长度增加到512,批量大小减少到32。使用默认的AdamW优化器,初始学习率为2e-5,训练10 epoch。
-
评估结果:在Emo Pillars合成测试集上,使用上下文的模型在重写表达上表现更好,表明上下文有助于情感分类。在EmoContext任务上,经过微调的上下文模型表现优于其他模型,F1分数为0.82。
四、实验结论
4.1 无上下文情感识别
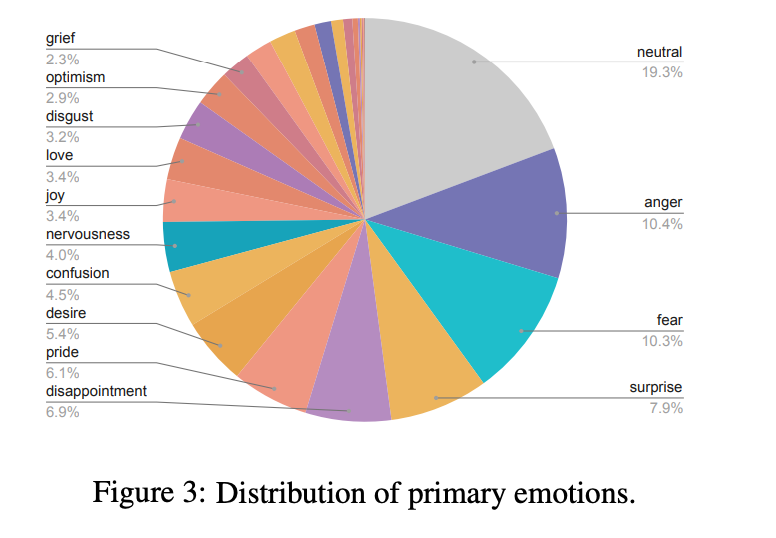
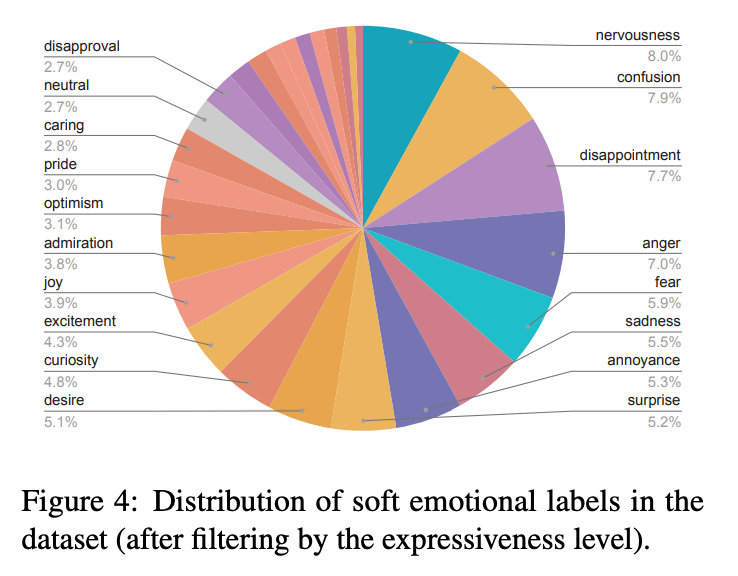
1. Emo Pillars 合成测试集
-
模型在原始表达(Original Utterances)上表现出色,F1分数达到0.80-0.81,表明生成的文本包含足够的情感信号,即使没有上下文,模型也能准确识别情感。
-
对于重写表达(Rewritten Utterances),模型性能有所下降(F1分数为0.65-0.74),这验证了上下文在情感理解中的重要性。
-
结论:生成的数据集能够支持无上下文情感分类任务,且重写步骤增加了情感分类的难度,凸显了上下文的重要性。

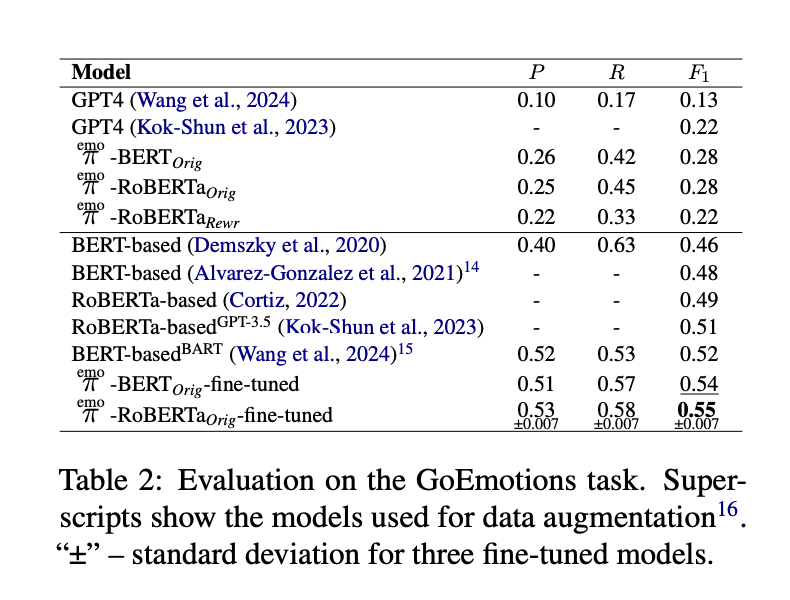
2. GoEmotions 数据集
-
微调后的模型在GoEmotions数据集上达到了SOTA性能,F1分数为0.55(RoBERTa模型)。
-
结论:生成的数据集能够有效支持模型在细粒度情感分类任务上的性能提升,尤其是在情感类别较多的情况下。
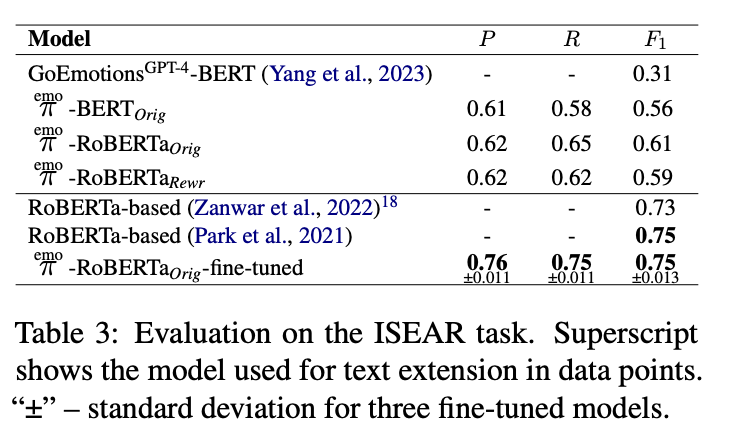
3. ISEAR 数据集
-
微调后的模型在ISEAR数据集上也达到了SOTA性能,F1分数为0.76(RoBERTa模型)。
-
结论:生成的数据集在不同情感分类任务上表现出良好的适应性,能够支持模型在多种情感类别上的高性能。
4.2 有上下文情感识别
1. Emo Pillars 合成测试集
-
使用上下文的模型在重写表达(Rewritten Utterances)上表现更好,F1分数提升了2-3个百分点,表明上下文有助于情感分类。
-
结论:生成的上下文信息能够显著提升模型在情感分类任务中的性能,尤其是在情感表达较为隐晦的情况下。
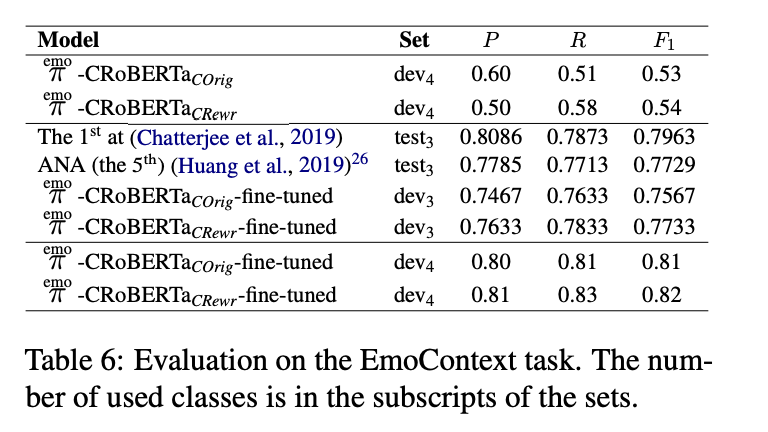
2. EmoContext 数据集
-
在EmoContext任务上,经过微调的上下文模型表现优于其他模型,F1分数为0.82。
-
结论:上下文信息对于情感分类具有显著的提升作用,尤其是在对话场景中,上下文能够帮助模型更好地理解情感。
五、总结
该文章提出了一种基于LLM的数据合成方法,用于生成细粒度情感分类数据集,并通过微调Bert的编码器模型,实现了在多个情感分类任务上的高性能。该方法不仅提高了情感分类的准确性,还通过上下文生成和清理步骤,增强了模型对上下文信息的利用能力。