从0到1:Python项目部署与运维全攻略(10/10)
摘要:在本文中,我将结合自己多年的实战经验,详细介绍 Python 项目部署与运维的全过程,从环境搭建、项目部署到日常运维和故障排查,为大家提供一套完整的解决方案。无论你是 Python 新手,还是经验丰富的开发者,相信都能从本文中获得一些有价值的信息。
一、引言

在当今数字化时代,Python 无疑是技术领域中一颗璀璨的明星。它以简洁优雅的语法、丰富强大的库和广泛的应用场景,深受广大开发者的喜爱。无论是数据科学、人工智能、Web 开发,还是自动化脚本编写,Python 都展现出了无可比拟的优势 ,在 IEEE Spectrum 发布的 2021 年编程语言排行榜中,Python 荣登榜首,足以证明其在行业中的重要地位。
然而,开发出一个优秀的 Python 项目仅仅是第一步,如何将项目成功部署到生产环境,并进行有效的运维管理,同样是至关重要的环节。项目部署决定了应用程序能否在目标环境中稳定运行,而运维则关系到系统的性能、可用性和安全性。一个小小的配置错误或者运维不当,都可能导致应用程序崩溃、数据丢失,给企业和用户带来巨大的损失。因此,掌握 Python 项目的部署与运维实战技巧,对于每一位开发者来说,都是必备的技能。

二、项目部署前的准备工作
2.1 环境搭建
方式一:pyenv
搭建 Python 开发和部署环境是项目开展的基础,不同操作系统下的搭建步骤虽有差异,但都遵循一定的逻辑。
1、在 Linux 系统中,以 CentOS 为例,首先需要确保系统安装了必要的依赖包,通过
yum install -y gcc make patch gdbm-devel openssl-devel sqlite-devel zlib-devel bzip2-devel命令即可完成安装 。之后可以使用pyenv来管理 Python 版本,这是一种非常灵活的方式,允许在同一系统中安装多个 Python 版本。具体步骤为:先安装git,
yum install git -y再通过
curl -L https://github.com/pyenv/pyenv-installer/raw/master/bin/pyenv-installer | bash下载并安装pyenv。安装完成后,编辑~/.bash_profile文件,添加export PATH="/home/python/.pyenv/bin:$PATH" 、eval "$(pyenv init -)"和eval "$(pyenv virtualenv-init -)",然后执行
source ~/.bash_profile使配置生效。这样就可以使用pyenv安装不同版本的 Python,如pyenv install 3.6.6。
2、在 Windows 系统下,从 Python 官方网站(https://www.python.org/downloads/windows/ )下载 Python 的安装程序,根据操作系统版本选择合适的 Python 版本,一般建议选择最新版本 。下载完成后,双击运行安装程序,在安装向导中,可选择自定义安装选项,如安装路径和要安装的组件,务必勾选 “Add Python to PATH” 选项,这将使得 Python 在命令行中可用。安装完成后,打开命令提示符或 PowerShell,输入python --version验证 Python 是否成功安装。详细推荐看下我之前写的详细教程:
Windows10安装Docker Desktop(大妈看了都会)
本文详细介绍了如何在Windows10上安装DockerDesktop,包括为何选择在Windows上安装、Docker基本概念、下载与安装步骤、启用Hyper-V、解决常见问题,如WSL2安装不完整和设置默认版本。通过本文,开发者可以快速掌握在Windows环境下使用Docker进行容器化开发的流程。
虚拟环境的创建也是环境搭建的重要环节。在 Linux 中,使用pyenv创建虚拟环境的命令是pyenv virtualenv 3.6.6 ql366,这会使用 Python 3.6.6 版本创建出一个独立的虚拟空间 。在 Windows 中,利用内置的venv模块创建虚拟环境,在项目目录下执行python -m venv venv即可创建名为venv的虚拟环境 。激活虚拟环境后,安装的包将仅在该环境中可用,避免了不同项目之间的依赖冲突。
方式二:Python conda环境
Python conda环境
在使用Conda管理Python环境时,你可以执行多种操作来创建、激活、删除和管理环境。以下是一些基本命令和步骤:1. 安装Conda
如果你还没有安装Conda,可以从Anaconda官网下载并安装Anaconda,它包含了Conda。2. 创建新的Conda环境
要创建一个新的Conda环境,可以使用以下命令:conda create --name myenv python=3.8
这里,myenv 是新环境的名称,python=3.8 指定了Python版本。你可以根据需要更改环境名和Python版本。3. 激活环境
创建环境后,你需要激活它才能在该环境中安装包或运行代码。激活环境的命令如下:conda activate myenv
4. 安装包
在激活的环境中,你可以安装所需的包:conda install numpy
或者使用pip:pip install numpy
5. 列出环境中的包
要查看当前环境中已安装的包,可以使用:conda list
6. 导出环境配置
如果你想要分享你的环境配置或备份,可以使用以下命令导出环境:conda env export > environment.yml
这会创建一个environment.yml文件,其中包含了所有已安装的包及其版本。7. 从environment.yml文件创建环境
你可以使用导出的environment.yml文件来创建一个新的环境:conda env create -f environment.yml
8. 删除环境
要删除一个环境,可以使用:conda remove --name myenv --all
或者使用:conda env remove --name myenv
9. 列出所有环境
查看所有可用的Conda环境:conda info --envs
或者简写为:conda env list
10. 更新Conda和包
更新Conda本身:conda update conda
更新特定包:conda update numpy
更新所有包:conda update --all
或者使用pip更新所有包:pip list --outdated | grep -v '^\-e' | cut -d ' ' -f1 | xargs -n1 pip install -U
(注意:这种方法会更新所有通过pip安装的包,而不仅仅是Conda环境的包)通过这些基本命令,你可以有效地管理你的Python环境和包。
2.2 依赖管理
项目依赖管理是确保项目稳定运行的关键,requirements.txt和Pipfile是 Python 中常用的依赖管理工具。requirements.txt文件简单直观,通过pip freeze > requirements.txt命令可以生成项目当前的依赖列表,其中包含了项目所依赖的包及其版本信息 。当在新环境中部署项目时,只需执行pip install -r requirements.txt,pip工具就会根据该文件自动安装所有依赖包。例如,一个 Flask 项目的requirements.txt文件可能包含如下内容:
Flask==2.0.1
Werkzeug==2.0.1
Jinja2==3.0.1这样在新环境中就能准确安装项目所需的依赖版本,避免因版本不一致导致的兼容性问题。
Pipfile则是pipenv工具使用的依赖管理文件,它提供了更高级的依赖管理功能。pipenv是一个将依赖包和虚拟环境管理结合在一起的工具,使用pipenv install命令安装包时,它会自动创建或更新Pipfile和Pipfile.lock文件 。Pipfile记录项目的依赖包,而Pipfile.lock则精确记录每个依赖包的版本及依赖关系,确保在不同环境中安装的依赖完全一致。例如,使用pipenv install flask安装 Flask 包后,Pipfile中会添加如下内容:
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"[packages]
flask = "*"[dev-packages]Pipfile.lock文件则会详细记录 Flask 及其依赖包的精确版本和哈希值,保障依赖的确定性。
2.3 代码版本控制
Git 作为目前最流行的分布式版本控制系统,在项目开发中起着举足轻重的作用。在项目目录下执行git init即可初始化一个 Git 仓库,这会在项目目录下创建一个名为.git的隐藏文件夹,用于存储 Git 的版本控制相关信息 。初始化完成后,就可以将项目中的代码纳入版本控制。使用git add命令将文件添加到暂存区,如git add.表示添加当前目录下的所有文件;然后使用git commit -m "提交说明"命令提交代码,其中-m参数用于添加提交信息,清晰的提交信息有助于后续追溯代码变更。Git的使用详细教程推荐看之前我写的文章,地址如下:
解释 Git 的基本概念和使用方式。
本文介绍了Git版本控制系统的核心概念,如仓库、提交、分支、合并等,推荐了Git客户端工具,包括命令行、图形界面和IDE集成,并详细讲解了Git的操作方法,包括初始化、克隆、配置、添加文件、提交、查看状态等。
分支管理是 Git 的强大功能之一,它允许在同一仓库中并行开发不同的功能。使用git branch <分支名>命令创建新分支,例如git branch feature/login创建一个名为feature/login的分支,用于开发登录功能 。通过git checkout <分支名>命令切换分支,如git checkout feature/login切换到该分支进行开发。当分支开发完成后,可使用git merge <分支名>命令将分支合并到主分支,如在主分支中执行git merge feature/login将登录功能分支合并进来。在多人协作开发中,分支管理能有效避免代码冲突,提高开发效率。同时,通过合理使用git push和git pull命令与远程仓库进行同步,确保团队成员之间的代码一致性。
三、Python 项目部署实战
3.1 常见部署方式介绍
- 本地部署:在本地开发环境中部署项目,主要用于开发和测试阶段。这种方式简单便捷,开发者可以直接在自己的电脑上运行项目,方便进行代码调试和功能测试 。例如,使用python main.py命令即可直接运行 Python 脚本,快速验证代码逻辑是否正确,无需复杂的网络配置和服务器环境搭建。
- 服务器部署:将项目部署到物理服务器或虚拟专用服务器(VPS)上,适用于小型企业或对服务器资源有自主掌控需求的场景。服务器部署需要管理员具备一定的服务器管理知识,包括服务器操作系统的安装与配置、网络设置等 。在 Linux 服务器上部署 Python 项目,需要安装 Python 环境、配置 Web 服务器(如 Nginx)等,以确保项目能够通过网络被外部访问。
- 容器化部署(Docker):Docker 是一种容器化技术,它将应用程序及其依赖项打包成一个独立的容器,使得应用程序在不同环境中具有高度的一致性和可移植性 。容器化部署可以快速部署和扩展应用,提高开发和运维效率。例如,使用 Docker 构建一个 Python Web 应用的镜像,然后在不同的服务器上运行该镜像,都能保证应用以相同的方式运行,避免了因环境差异导致的问题。
- 云平台部署(AWS、阿里云等):利用云服务提供商的基础设施进行项目部署,具有弹性伸缩、高可用性、易于管理等优点 。云平台提供了丰富的服务,如计算资源(云服务器)、存储服务、数据库服务等,可以根据项目的需求灵活选择和配置。以阿里云为例,通过购买云服务器 ECS 实例,在上面部署 Python 项目,并结合阿里云的负载均衡、对象存储等服务,可以快速搭建一个稳定、可扩展的应用系统。
3.2 基于服务器的部署流程
以 Linux 服务器(CentOS 7)为例,详细讲解 Python 项目的部署流程。
上传代码:使用scp命令将本地项目代码上传到服务器。假设本地项目路径为/local/path/to/project,服务器 IP 为192.168.1.100,用户名user,服务器上存放项目的路径为/home/user/project,则上传命令为:
scp -r /local/path/to/project user@192.168.1.100:/home/user/安装依赖:进入项目目录,激活虚拟环境(如果使用虚拟环境),然后安装项目所需的依赖包。假设项目使用requirements.txt管理依赖,执行以下命令:
cd /home/user/projectsource venv/bin/activate # 激活虚拟环境pip install -r requirements.txt配置服务器(Nginx 作为反向代理):首先安装 Nginx,在 CentOS 7 中使用以下命令:
sudo yum install nginx安装完成后,编辑 Nginx 配置文件,如/etc/nginx/conf.d/default.conf,添加如下配置:
server {listen 80;server_name your_domain.com; # 替换为你的域名或服务器IPlocation / {proxy_pass http://127.0.0.1:8000; # 假设Python项目运行在本地8000端口proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;}
}保存配置文件后,重启 Nginx 服务:
sudo systemctl restart nginx启动项目:使用 Gunicorn 启动 Python 项目,假设项目的入口文件为app.py,应用实例名为app,执行以下命令:
gunicorn -w 4 -b 127.0.0.1:8000 app:app其中-w参数指定工作进程数,-b参数指定绑定的 IP 和端口。这样,Python 项目就通过 Nginx 反向代理对外提供服务了。
3.3 Docker 容器化部署
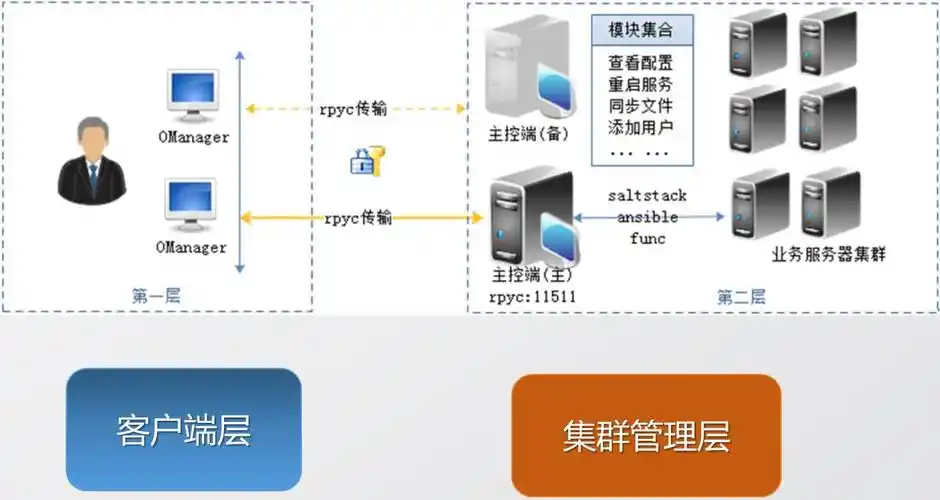
Docker 基本概念:Docker 是一个开源的应用容器引擎,它允许开发者将应用及其依赖打包成一个可移植的容器 。Docker 主要包含镜像(Image)、容器(Container)和仓库(Registry)三个核心概念。镜像是一个只读的模板,包含了运行应用所需的所有文件和配置;容器是镜像的运行实例,可以被启动、停止和删除;仓库则是存放镜像的地方,如 Docker Hub 是一个公共的镜像仓库。
编写 Dockerfile 构建镜像:在项目根目录下创建一个名为Dockerfile的文件,内容如下:
# 使用官方Python镜像作为基础镜像
FROM python:3.8-slim# 设置工作目录
WORKDIR /app# 将项目文件复制到容器中
COPY. /app# 安装项目依赖
RUN pip install -r requirements.txt# 暴露端口
EXPOSE 8000# 定义容器启动时执行的命令
CMD ["gunicorn", "-w", "4", "-b", "0.0.0.0:8000", "app:app"]然后在项目目录下执行
docker build -t your_image_name.命令构建镜像,其中your_image_name是自定义的镜像名称,.表示当前目录。
使用 Docker Compose 编排多容器应用:如果项目依赖多个服务,如数据库、缓存等,可以使用 Docker Compose 进行多容器编排。在项目根目录下创建docker-compose.yml文件,内容如下:
version: '3'
services:web:build:.ports:- "8000:8000"depends_on:- dbdb:image: mysql:5.7environment:MYSQL_ROOT_PASSWORD: rootMYSQL_DATABASE: your_databaseMYSQL_USER: your_userMYSQL_PASSWORD: your_passwordvolumes:-./data:/var/lib/mysql上述配置定义了两个服务,web服务用于运行 Python 项目,db服务用于运行 MySQL 数据库。执行docker-compose up -d命令启动所有容器,-d参数表示在后台运行。这样就实现了 Python 项目的容器化部署,并且通过 Docker Compose 方便地管理多个相关容器。
3.4 云平台部署案例
选择阿里云作为云平台,演示 Python 项目的部署过程。
云服务器配置:登录阿里云控制台,选择 “弹性计算” -> “云服务器 ECS”,创建一个新的 ECS 实例。在创建过程中,选择合适的地域、实例规格(如 2 核 4GB)、操作系统(如 Ubuntu 20.04)等 。创建完成后,获取服务器的公网 IP 地址。
安全组设置:在云服务器的安全组配置中,添加规则允许外部访问项目所需的端口,如 80 端口(用于 HTTP 访问)、8000 端口(假设 Python 项目运行在此端口) 。点击 “配置规则” -> “添加安全组规则”,设置规则如下:
- 端口范围:80/80 或 8000/8000
- 授权类型:0.0.0.0/0(表示允许所有 IP 访问,生产环境可根据实际需求限制)
- 协议类型:TCP
部署项目:使用 SSH 连接到云服务器,按照基于服务器部署流程的步骤,上传项目代码、安装依赖、配置 Nginx 反向代理和启动项目。例如,上传代码可以使用scp命令:
scp -r /local/path/to/project root@your_public_ip:/root/安装依赖和启动项目的步骤与基于服务器部署流程一致。配置 Nginx 反向代理时,编辑/etc/nginx/sites-available/default文件,添加正确的代理配置,然后启用配置并重启 Nginx:
sudo ln -s /etc/nginx/sites-available/default /etc/nginx/sites-enabled/sudo systemctl restart nginx通过以上步骤,即可在阿里云服务器上成功部署 Python 项目,实现项目的对外服务。

四、Python 项目运维要点
4.1 监控与报警
在 Python 项目的运维过程中,对项目性能指标的实时监控和及时报警至关重要,它能够帮助运维人员提前发现潜在问题,确保系统的稳定运行。Prometheus 和 Grafana 是两个强大的开源工具,它们结合使用可以实现高效的监控与报警功能。
Prometheus 是一个开源的监控系统,它通过抓取 HTTP 端点暴露的指标数据来实现监控功能 。Prometheus 将采集到的指标数据存储为时间序列数据,支持高效的查询和数据处理,并提供强大的查询语言 PromQL,用于分析和聚合时间序列数据。以监控 Python Web 应用的 CPU 使用率为例,首先需要在 Python 项目中集成 Prometheus 客户端库prometheus_client 。安装完成后,在项目代码中添加如下代码:
from prometheus_client import start_http_server, Gauge
import psutil
import time# 创建用于监控CPU使用率的指标
cpu_usage_gauge = Gauge('cpu_usage_percent', 'CPU usage percentage')def monitor_cpu_usage():while True:cpu_percent = psutil.cpu_percent(interval=1)cpu_usage_gauge.set(cpu_percent)time.sleep(1)if __name__ == '__main__':start_http_server(8000) # 启动HTTP服务器,用于Prometheus抓取指标数据monitor_cpu_usage()上述代码通过psutil库获取系统的 CPU 使用率,并使用prometheus_client库的Gauge类创建一个指标,将 CPU 使用率数据暴露在本地的 8000 端口 。接下来,配置 Prometheus 抓取该指标。在 Prometheus 的配置文件prometheus.yml中添加如下内容:
global:scrape_interval: 15s # 设置数据抓取的时间间隔scrape_configs:- job_name: 'python_app'static_configs:- targets: ['localhost:8000'] # 监控的Python应用端点这样,Prometheus 就会每隔 15 秒从localhost:8000抓取 CPU 使用率指标数据并存储。
Grafana 是一个开源的数据可视化工具,能够与 Prometheus 等数据源集成,将监控数据以图表、仪表盘等形式进行展示 。安装并启动 Grafana 后,在 Grafana 界面中添加 Prometheus 作为数据源,配置 Prometheus 的 URL(通常是http://localhost:9090,这是 Prometheus 的默认端口) 。然后创建一个新的仪表盘,添加一个图表用于展示 CPU 使用率。在图表的查询选项卡中,使用 PromQL 查询语句cpu_usage_percent获取 CPU 使用率数据,即可在图表中直观地看到 CPU 使用率随时间的变化趋势。
为了实现报警功能,Grafana 支持根据监控数据设定告警规则。在 Grafana 的仪表盘上,点击要设置告警的图表,选择 “Alert” 选项卡 。设置告警规则,例如当 CPU 使用率连续 5 分钟超过 80% 时触发告警。可以配置告警通知方式,如通过邮件、Slack 等工具发送告警信息,以便运维人员及时响应处理,保障系统的稳定运行。
4.2 日志管理
日志在 Python 项目中扮演着不可或缺的角色,它是记录程序运行时各种事件的重要工具,对于排查问题、分析系统行为和优化性能具有重要意义。Python 的logging模块提供了灵活且强大的日志记录功能,能够满足不同项目的日志管理需求。
使用logging模块记录日志非常方便,首先需要导入logging模块并进行基本配置。例如,在一个简单的 Python 脚本中,配置日志输出到文件并设置日志级别为INFO:
import logging# 配置日志
logging.basicConfig(filename='app.log',level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s'
)# 记录日志
logging.info('程序开始')
try:result = 10 / 0
except ZeroDivisionError:logging.exception('发生除零错误')
logging.info('程序结束')上述代码中,basicConfig函数用于配置日志的基本设置,包括日志文件名app.log、日志级别INFO以及日志格式 。日志格式中,%(asctime)s表示时间,%(levelname)s表示日志级别,%(message)s表示日志消息。通过logging.info和logging.exception等方法记录不同类型的日志信息,logging.exception方法会自动记录异常堆栈信息,便于定位问题。
在大型项目中,通常需要更复杂的日志配置,如将日志同时输出到控制台和文件,并且根据不同的模块设置不同的日志级别 。可以通过创建多个处理器(Handler)和记录器(Logger)来实现。以下是一个示例:
import logging# 创建日志记录器
logger = logging.getLogger('my_project')
logger.setLevel(logging.DEBUG)# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)# 创建文件处理器
file_handler = logging.FileHandler('my_project.log')
file_handler.setLevel(logging.DEBUG)# 创建格式化器
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_handler.setFormatter(formatter)
file_handler.setFormatter(formatter)# 将处理器添加到日志记录器
logger.addHandler(console_handler)
logger.addHandler(file_handler)# 记录日志
logger.debug('这是一条DEBUG级别的日志')
logger.info('这是一条INFO级别的日志')
logger.warning('这是一条WARNING级别的日志')
logger.error('这是一条ERROR级别的日志')
logger.critical('这是一条CRITICAL级别的日志')这段代码创建了一个名为my_project的日志记录器,设置其级别为DEBUG 。同时创建了控制台处理器和文件处理器,分别设置不同的日志级别,并为它们设置相同的格式化器。最后将两个处理器添加到日志记录器中,这样日志信息就会同时输出到控制台和文件中,方便调试和分析。
当项目出现问题时,通过分析日志文件可以快速定位问题所在。可以根据时间戳查找问题发生的时间段,根据日志级别筛选出关键的错误信息,结合异常堆栈信息确定错误发生的代码位置,从而进行针对性的修复,确保项目的稳定运行。
4.3 自动化运维脚本
使用 Python 编写自动化运维脚本可以极大地提高运维效率,减少人工操作的繁琐和错误。以下展示两个常见的自动化运维脚本示例:定时备份数据库和重启服务。
定时备份数据库:以 MySQL 数据库为例,使用subprocess模块调用系统命令mysqldump来实现数据库备份,并结合time模块实现定时任务。示例代码如下:
import subprocess
import datetime
import os
import time# 配置信息
DB_HOST = 'localhost'
DB_USER = 'your_username'
DB_PASSWORD = 'your_password'
DB_NAME = 'your_database_name'
BACKUP_PATH = '/path/to/backup/directory/'
INTERVAL = 60 * 60 # 每小时备份一次def create_backup():# 获取当前时间now = datetime.datetime.now()date_time = now.strftime('%Y%m%d_%H%M%S')# 备份文件名backup_file = f"{DB_NAME}_{date_time}.sql"backup_file_path = os.path.join(BACKUP_PATH, backup_file)# 构建mysqldump命令dump_cmd = f"mysqldump -h {DB_HOST} -u {DB_USER} -p{DB_PASSWORD} {DB_NAME} > {backup_file_path}"# 执行备份命令try:subprocess.run(dump_cmd, shell=True, check=True)print(f"备份成功: {backup_file_path}")except subprocess.CalledProcessError as e:print(f"备份失败: {e}")def main():while True:create_backup()time.sleep(INTERVAL)if __name__ == "__main__":main()上述代码中,create_backup函数负责获取当前时间、构建备份文件名和路径,以及执行mysqldump命令进行数据库备份 。main函数通过一个无限循环,每隔INTERVAL秒(这里设置为每小时)调用一次create_backup函数,实现定时备份功能。
重启服务:假设 Python 项目使用 Gunicorn 启动,并且服务的进程 ID 存储在一个文件中,可以使用以下脚本来重启服务:
import subprocess
import timedef restart_service():try:# 读取进程ID文件with open('gunicorn.pid', 'r') as f:pid = int(f.read().strip())# 发送SIGTERM信号停止服务subprocess.run(f"kill -SIGTERM {pid}", shell=True, check=True)time.sleep(5) # 等待服务停止# 启动服务subprocess.run("gunicorn -w 4 -b 127.0.0.1:8000 app:app", shell=True, check=True)print("服务重启成功")except Exception as e:print(f"服务重启失败: {e}")if __name__ == "__main__":restart_service()这个脚本首先读取存储进程 ID 的文件,然后使用kill -SIGTERM命令发送终止信号停止服务,等待 5 秒后,再使用gunicorn命令重新启动服务,实现了服务的自动化重启,提高了运维的效率和可靠性。
4.4 故障排查与处理
在 Python 项目的运行过程中,难免会遇到各种故障,掌握常见故障场景的排查思路和解决方法至关重要。以下分享一些常见的项目故障场景及对应的处理方式。
服务崩溃:当 Python 服务突然崩溃时,首先检查系统日志和应用程序日志。系统日志(如/var/log/syslog在 Linux 系统中)可能包含与服务器硬件、操作系统相关的错误信息,如内存不足、磁盘空间满等 。应用程序日志(使用logging模块记录的日志)则可以帮助定位程序内部的错误,查看是否有未捕获的异常导致程序终止。例如,通过查看应用程序日志发现如下异常信息:
Traceback (most recent call last):File "app.py", line 50, in <module>result = 10 / 0
ZeroDivisionError: division by zero从这个异常信息可以看出,在app.py的第 50 行发生了除零错误,导致服务崩溃。解决方法是修复代码中的除零错误,如添加条件判断避免除数为零。
接口报错:如果项目提供了 API 接口,当接口报错时,首先检查接口请求和响应。可以使用工具如 Postman 或浏览器的开发者工具查看接口请求的 URL、参数、请求头是否正确 。同时,查看接口的响应状态码和响应内容,常见的状态码如 400 表示请求错误,404 表示资源未找到,500 表示服务器内部错误。如果响应状态码为 500,查看应用程序日志,定位服务器端的错误。例如,接口报错提示数据库连接失败,检查数据库配置是否正确,数据库服务器是否正常运行,网络连接是否正常等。可以尝试使用数据库客户端工具(如 MySQL Workbench)连接数据库,验证连接配置是否正确。如果是网络问题,检查服务器的防火墙设置、网络配置等,确保数据库服务器可被访问,从而解决接口报错问题,保障项目的正常运行。
五、总结与展望
在本文中,我们深入探讨了 Python 项目部署与运维的各个关键环节。从部署前的环境搭建、依赖管理和代码版本控制,到多种部署方式的实战操作,包括基于服务器的传统部署、先进的 Docker 容器化部署以及便捷的云平台部署,每一步都为项目在生产环境中的稳定运行奠定了基础 。在运维要点部分,监控与报警确保了我们能及时洞察项目的健康状况,日志管理为故障排查提供了有力依据,自动化运维脚本提高了工作效率,而故障排查与处理则是保障项目持续可用的关键技能。
展望未来,随着技术的飞速发展,Python 项目部署与运维领域也将不断演进。容器编排工具如 Kubernetes 的应用将更加广泛,进一步提升容器化应用的管理和调度能力,实现更高效的资源利用和弹性伸缩 。云原生技术的兴起,将推动 Python 项目更好地与云服务融合,利用云平台提供的各种托管服务,如无服务器计算(Serverless),降低运维成本,提高开发和部署的速度。同时,人工智能和机器学习技术也将逐渐渗透到运维领域,实现智能运维,通过数据分析预测潜在问题,自动优化系统性能。

对于读者而言,持续学习是跟上技术发展步伐的关键。Python 社区充满活力,不断有新的工具、框架和最佳实践涌现。建议大家关注开源项目,参与技术论坛和社区交流,积极学习新技术,将其应用到实际项目中。只有不断学习和实践,才能在快速变化的技术领域中立于不败之地,充分发挥 Python 在项目开发和运维中的强大优势,创造出更具价值的应用。

相关文章推荐:
1、Python详细安装教程(大妈看了都会)
2、02-pycharm详细安装教程(大妈看了都会)
3、如何系统地自学Python?
4、Alibaba Cloud Linux 3.2104 LTS 64位 怎么安装python3.10.12和pip3.10
5、职场新技能:Python数据分析,你掌握了吗?
6、Python爬虫图片:从入门到精通
7、Python+Pycharm详细安装教程(大妈看了都会)
串联文章:
1、Python小白的蜕变之旅:从环境搭建到代码规范(1/10)
2、Python面向对象编程实战:从类定义到高级特性的进阶之旅(2/10)
3、Python 异常处理与文件 IO 操作:构建健壮的数据处理体系(3/10)
4、从0到1:用Lask/Django框架搭建个人博客系统(4/10)
5、Python 数据分析与可视化:开启数据洞察之旅(5/10)
6、Python 自动化脚本开发秘籍:从入门到实战进阶(6/10)
7、Python并发编程:开启性能优化的大门(7/10)
8、从0到1:Python机器学习实战全攻略(8/10)
9、解锁Python TDD:从理论到实战的高效编程之道(9/10)
10、从0到1:Python项目部署与运维全攻略(10/10)