通义千问-langchain使用构建(三)
目录
- 序言
- docker 部署xinference
- 1WSL环境docker安装
- 2拉取镜像运行容器
- 3使用的界面
- 本地跑chatchat
- 1rag踩坑
- 2使用的界面
- 2.1配置个前置条件然后对话
- 2.2rag对话
- 结论
序言
在前两天的基础上,将xinference调整为wsl环境,docker部署。
然后langchain chatchat 还是本地虚拟环境直接跑。
以及简单在这个chatchat框架里上传了一个文本文件,询问大模型文件内容。
还行,跑起来了,坑也是不少
docker 部署xinference
1WSL环境docker安装
参考这个链接内容配置下wsl的docker环境,以及配置下国内私人dockerhub镜像源。
【现在竟然没有公司或者学校配置的dockerhub镜像了,奇怪,真奇怪。不配置就要梯子】
参考链接1:https://blog.csdn.net/wylszwr/article/details/147671490
这里有个坑,C盘如果空间不够,wsl最好迁移到D盘,因为大模型挺占空间的。
2拉取镜像运行容器
参考下面这个链接操作一下就好了,然后配置的端口,回头更新在chatchat的yaml文件就行。
【1050ti的显卡,cuda和torch这些版本适配有些麻烦,所以我就拉去的cpu版本镜像。
docker pull xprobe/xinference:latest-cpu】
参考链接2:https://inference.readthedocs.io/zh-cn/latest/getting_started/using_docker_image.html
3使用的界面
加载模型界面
就运行这里lunch模型,要等一会儿
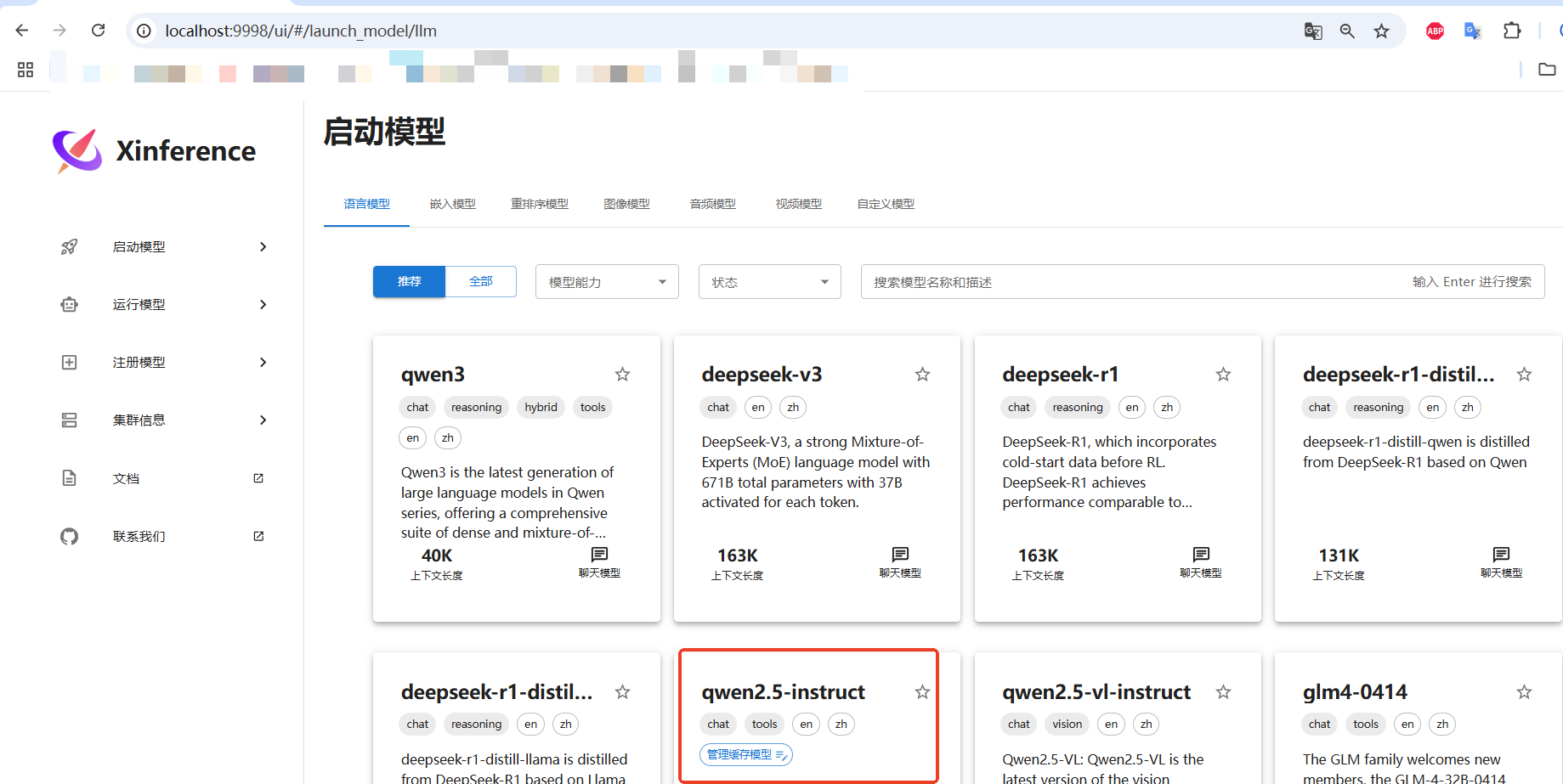
这个运行这里就能看到已经下载到本地的模型了。
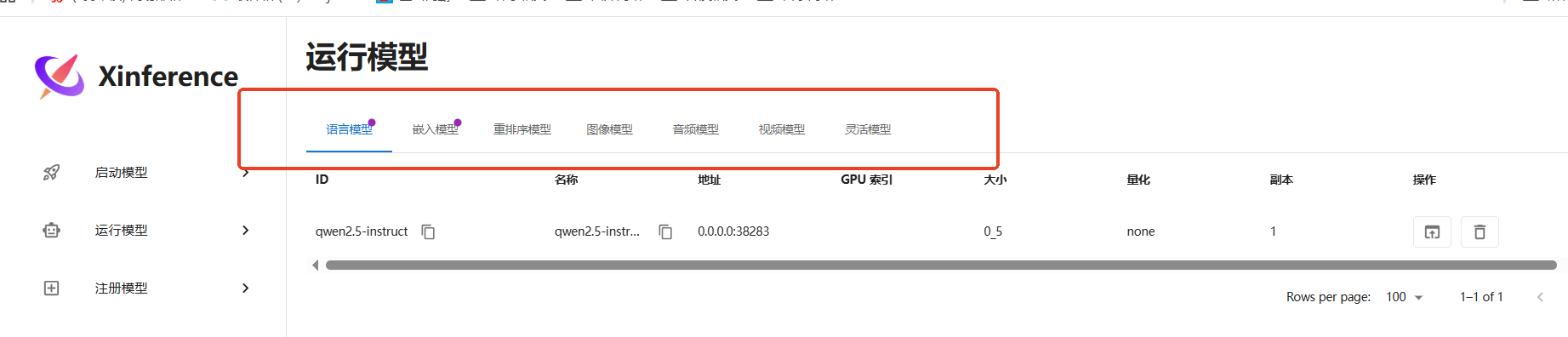
语言模型: 就是正常对话的。
嵌入模型embedding模型: 就是把上传的文本材料,解析成向量,搞到知识库的。
重排序rerank模型: 目前简单理解为嵌入模型的升级版(250517)。
参考链接3:https://blog.csdn.net/2401_84033492/article/details/144546055
图像模型: 简单理解为画图的。
音频模型: 简单理解为听声音,转换为声音的。
视频模型: 生成视频的。
本地跑chatchat
和上一篇的调整没啥区别。
就是yaml文件要更新。
【我看有人不建议chatchat在docker跑。我不搞是因为wsl搞docker compose插件有点繁琐】
1rag踩坑
有个问题就是上传文件半天没反应,参考这个降httpx版本就好了。
参考链接:https://blog.csdn.net/ddyzqddwb/article/details/144347702
2使用的界面
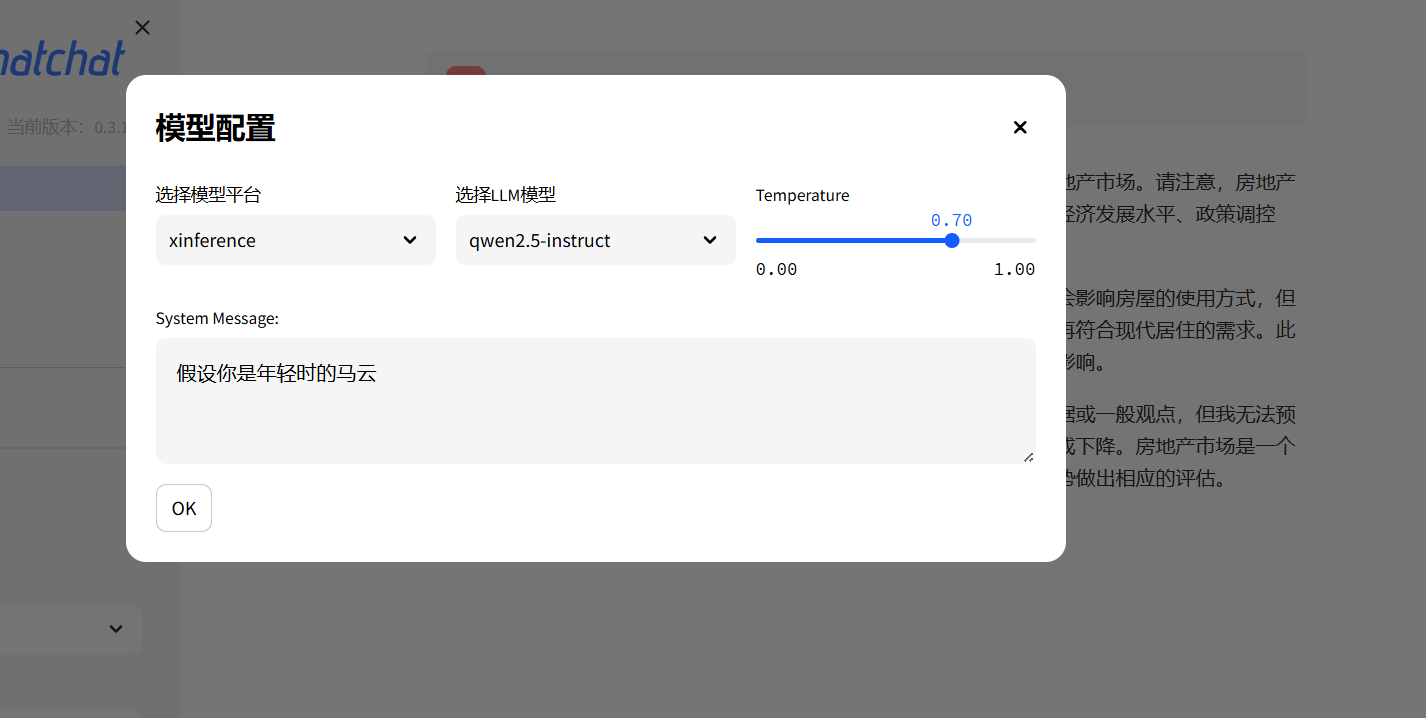
2.1配置个前置条件然后对话
2.2rag对话
往上找了个诗经的txt传上去,然后用模型阅读。只是一部分,全是文言文,我自己看着是挺头大的。
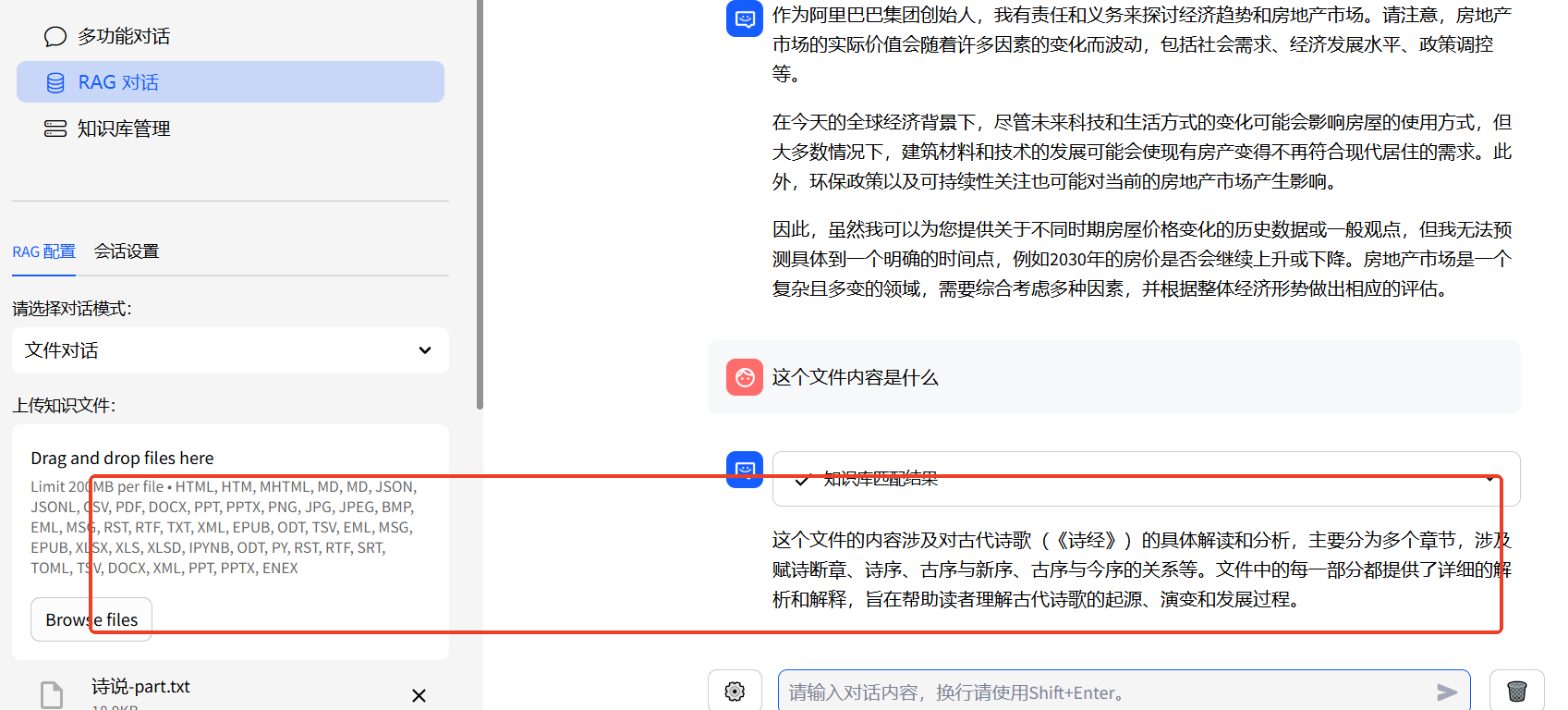
上传的文言文材料。
结论
windows机器。
wsl环境。
docker跑xinference
本地python环境跑了chatchat
实现大模型的管理加载,以及简单的知识库构建与rag管理。
这就是这次的内容。