深度学习---知识蒸馏(Knowledge Distillation, KD)
一、知识蒸馏的本质与起源
定义:
知识蒸馏是一种模型压缩与迁移技术,通过将复杂高性能的教师模型(Teacher Model)所学的“知识”迁移到轻量级的学生模型(Student Model),使学生模型在参数量和计算成本大幅降低的同时,尽可能保留教师模型的性能。
起源:
- 由 Geoffrey Hinton 等人于2015年在论文《Distilling the Knowledge in a Neural Network》中首次提出。
- 核心动机:解决深度学习模型在实际部署(如移动端、边缘设备)时的效率问题,同时避免从头训练小模型可能面临的性能下降。
二、核心概念:知识的类型
知识蒸馏中的“知识”分为两类:
-
显性知识(Explicit Knowledge)
- 即传统的标签信息(硬标签,如分类任务中的独热编码)。
- 作用:提供基础监督信号。
-
隐性知识(Implicit Knowledge)
- 指教师模型的输出概率分布(软标签,如softmax层的输出),反映类别间的相似性和相关性。
- 示例:教师模型对“猫”“狗”“狼”的预测概率分别为0.6、0.3、0.1,软标签可揭示“狗”与“狼”的相似性,而硬标签仅显示正确类别为“猫”。
- 价值:软标签携带更丰富的语义信息,帮助学生模型学习类别间的潜在关系,提升泛化能力。
三、基本框架与数学原理
1. 教师-学生架构
- 教师模型:通常为复杂模型(如ResNet、BERT),具有高容量和高准确率。
- 学生模型:轻量级架构(如MobileNet、DistilBERT),目标是模仿教师的行为。
2. 训练过程
-
软标签生成:教师模型对输入数据生成软标签,通过引入温度参数 ( T ) 调整softmax输出的平滑度:
-
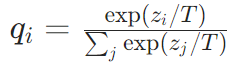
其中 ( z_i ) 为教师模型的logits,( T ) 越高,软标签越平滑(类别差异模糊);( T=1 ) 时退化为标准softmax。
-
损失函数设计:
通常结合软标签损失和硬标签损失:
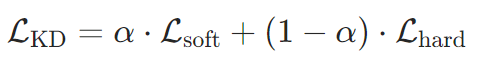
-
软标签损失:衡量学生与教师软标签的差异,常用KL散度(Kullback-Leibler Divergence):
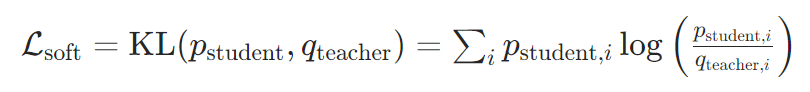
其中 ( p student p_{\text{student}} pstudent) 为学生模型的软化输出(同样使用温度 ( T ))。
-
硬标签损失:传统交叉熵损失,确保学生模型正确分类:
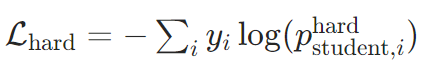
其中 ( p student hard p_{\text{student}}^{\text{hard}} pstudenthard ) 为学生模型的标准softmax输出(( T=1 ))。
-
-
温度的作用:
- 训练阶段:( T>1 ) 使教师软标签更平滑,释放类别间的隐性知识。
- 推理阶段:学生模型的 ( T ) 设为1,恢复标准预测。
四、关键技术与变种
1. 基于输出的蒸馏(传统蒸馏)
- 直接迁移教师模型的输出层知识,适用于分类任务。
- 变种:
- 多教师蒸馏:集成多个教师模型的软标签,提升学生模型的鲁棒性(如使用不同初始化或架构的教师)。
- 跨模态蒸馏:在不同模态间迁移知识(如图像→文本,或语音→视觉)。
2. 基于特征的蒸馏(中间层蒸馏)
- 迁移教师模型中间层的特征表示,适用于复杂任务(如语义分割、生成模型)。
- 典型方法:
- FitNets:强制学生模型的隐藏层输出匹配教师模型的对应层(使用MSE损失)。
- 注意力蒸馏:迁移教师模型的注意力图(如Transformer中的自注意力分布),适用于NLP任务(如DistilBERT)。
3. 自蒸馏(Self-Distillation)
- 无外部教师模型,学生模型通过自身集成或迭代优化实现蒸馏。
- 场景:
- 数据增强:同一模型对不同增强数据的预测作为软标签。
- 模型集成:同一模型的不同副本(不同初始化)相互蒸馏。
4. 无监督/半监督蒸馏
- 在无标签或少量标签数据上,利用教师模型生成伪标签或软标签指导学生训练。
- 应用:跨领域迁移(如源域教师指导目标域学生)。
5. 与其他技术结合
- 神经架构搜索(NAS):在搜索轻量级架构时同步进行蒸馏。
- 联邦学习:在分布式场景中,中央教师模型向边缘设备的学生模型迁移知识,保护数据隐私。
五、应用场景
1. 自然语言处理(NLP)
- 模型压缩:如DistilBERT(BERT的蒸馏版,参数减少40%,速度提升60%)、TinyBERT、MobileBERT。
- 对话系统:将大型预训练模型(如GPT-3)的知识迁移到对话机器人,降低推理延迟。
2. 计算机视觉(CV)
- 轻量级模型设计:如MobileNet蒸馏自ResNet,用于移动端图像分类;YOLO系列的蒸馏版用于实时目标检测。
- 医学影像:将复杂3D CNN的知识迁移到轻量级模型,便于临床快速诊断。
3. 自动驾驶与边缘计算
- 车载模型需低延迟,通过蒸馏将高性能检测模型(如Faster R-CNN)压缩为实时模型(如YOLO-Lite)。
4. 推荐系统
- 将深度推荐模型(如Wide & Deep)蒸馏为轻量级模型,提升在线服务效率。
六、挑战与未来方向
1. 核心挑战
- 负迁移(Negative Transfer):若教师模型存在噪声或过拟合,学生可能学习到错误知识。
- 架构差异:跨架构蒸馏(如CNN→Transformer)时,知识迁移效率低。
- 超参数调优:温度 ( T )、软硬损失权重 ( \alpha ) 需手动调整,缺乏自动化方案。
- 计算成本:训练教师模型需大量资源,限制了在数据稀缺场景的应用。
2. 未来研究方向
- 无教师蒸馏:通过自监督学习或生成模型替代教师(如对比学习、GAN生成软标签)。
- 自动化蒸馏:利用贝叶斯优化、强化学习自动搜索蒸馏参数(如温度、损失权重)。
- 跨领域/跨模态蒸馏:探索异构数据间的知识迁移(如图像→视频、文本→音频)。
- 增量蒸馏:在持续学习场景中,逐步将新教师的知识融入学生模型,避免灾难性遗忘。
- 理论分析:深入研究蒸馏的泛化边界、信息压缩效率,建立更严谨的数学理论基础。
七、与其他模型压缩技术的对比
| 技术 | 核心思想 | 优势 | 局限性 |
|---|---|---|---|
| 知识蒸馏 | 迁移教师模型的隐性知识 | 保留性能的同时压缩架构 | 需预训练教师模型 |
| 剪枝 | 删除冗余连接或神经元 | 减少参数量,保持架构不变 | 可能影响模型稳定性 |
| 量化 | 降低权重/激活值的精度 | 减少内存占用,加速推理 | 可能导致精度损失 |
| 权重共享 | 强制不同层/神经元共享参数 | 减少存储需求 | 适用场景有限 |
互补性:知识蒸馏常与剪枝、量化结合使用(如先蒸馏再剪枝),进一步提升压缩效率。
八、典型案例
-
NLP领域
- DistilBERT:基于BERT-base蒸馏,层数从12层减至6层,参数量从110M减至66M,在GLUE基准上保留97%的性能。
- TinyBERT:同时蒸馏BERT的输出层和中间层特征,压缩率更高(7.5M参数)。
-
CV领域
- MobileNet from ResNet:将ResNet的软标签迁移至MobileNet,在ImageNet上Top-1准确率提升3-4%。
- Face Recognition:蒸馏版FaceNet在移动端实现实时人脸识别,精度接近原版。
-
工业应用
- Google Speech Recognition:通过蒸馏将深度语音模型压缩,部署于手机端语音助手。
- 自动驾驶:NVIDIA的DistilledSSD将目标检测模型压缩,适配车载嵌入式系统。
九、理论分析:为何有效?
- 正则化视角:软标签损失为学生模型提供额外的正则化,避免过拟合。
- 信息迁移视角:软标签揭示数据分布的流形结构(manifold structure),帮助学生模型捕捉类别间的依赖关系。
- 对抗学习视角:教师模型可视为生成器,学生模型为判别器,蒸馏过程类似生成对抗网络(GAN)的优化。
十、总结
知识蒸馏通过迁移教师模型的隐性知识,在模型压缩领域实现了性能与效率的平衡,已成为深度学习落地的关键技术之一。未来,随着无监督蒸馏、自动化调优和跨模态迁移的发展,其应用场景将进一步扩展,推动人工智能向轻量化、泛在化方向迈进。