图像超分-CVPR2022-Multi-scale Attention Network for Single Image Super-Resolution
图像炒粉-CVPR2022-Multi-scale Attention Network for Single Image Super-Resolution
文章目录
- 图像炒粉-CVPR2022-Multi-scale Attention Network for Single Image Super-Resolution
- 主要创新点
- 模型架构
- 多尺度注意力模块(MLKA)
- 门控空间注意力单元(GSAU)
- Large Kernel Attention Tail(LKAT)
- 💡接各种方向源码讲解,私信
- 💡接模型搭建,你的想法我来实现,包括尝试各种模块的有效性!
该论文提出一种用于图像超分的卷积网络——多尺度注意力网络(MAN),旨在弥补CNN在低级视觉任务中相较Transformer的劣势。MAN包含两个模块:多尺度大卷积核注意力(MLKA)和门控空间注意力单元(GSAU)。MLKA通过多尺度和门控机制增强注意力表达,融合全局与局部信息;GSAU结合门控和空间注意力,有效聚合空间上下文。实验表明,MAN在性能与计算之间实现了良好平衡。
论文链接:Multi-scale Attention Network for Single Image Super-Resolution
源码链接:/icandle/MAN
主要创新点
多尺度大卷积核注意力模块(MLKA):作者提出了一种结合多尺度和门控机制的注意力模块,通过在不同尺度上建模长程依赖关系,增强了模型在多粒度层次下的特征捕捉能力,有效提升了表示能力并缓解了传统CNN在全局建模上的劣势。
门控空间注意力单元(GSAU):在前馈结构中引入门控机制与空间注意力,省略了常规的线性映射层,在降低模型参数量和计算成本的同时,仍能充分挖掘空间上下文信息,从而实现轻量化与性能的协同优化。
多尺度注意力网络(MAN)体系构建:基于MLKA与GSAU模块,作者构建了多个复杂度可调的MAN模型,覆盖轻量化与高性能两类超分辨率任务场景,展示了其在不同资源限制下的灵活性和优越性能。
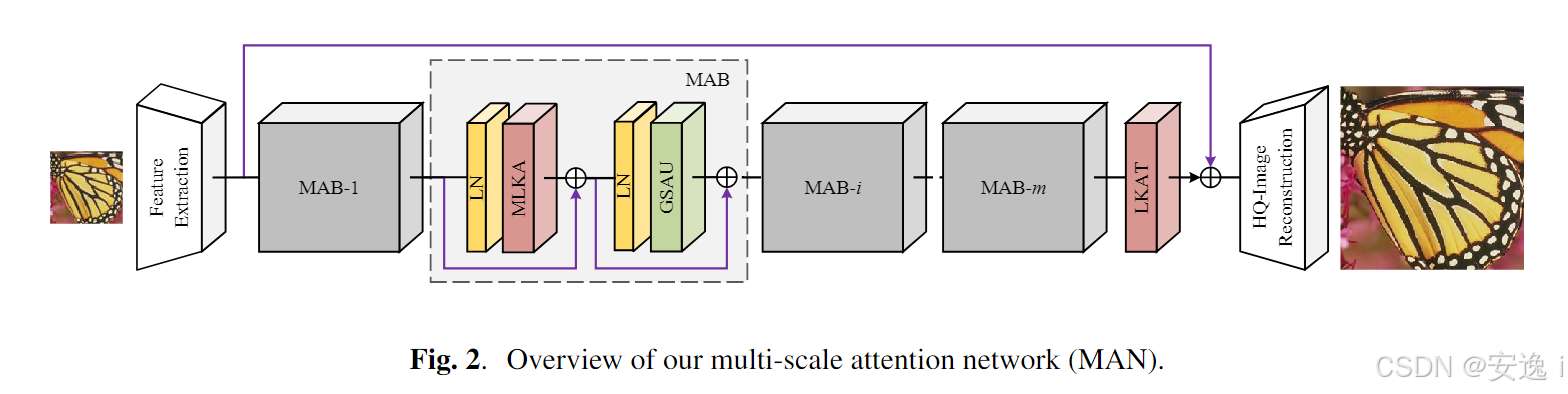
模型架构
多尺度注意力模块(MLKA) 用于在Transformer主干中有效捕捉跨尺度特征信息,结合门控机制提升注意力的选择性和表达力;
Gated Spatial Attention Unit(GSAU) 替代传统MLP作为前馈网络,采用轻量的Depth-wise卷积与空间门控机制,有效降低复杂度的同时保持感受野;
Large Kernel Attention Tail(LKAT) 作为输出尾部结构,引入大感受野卷积操作,增强最终特征融合能力,进一步提升重建图像的质量;
MetaFormer样式的Attention Block(MAB) 构成主干结构,将MLKA与GSAU模块无缝嵌入其中,实现局部与全局信息的高效整合。
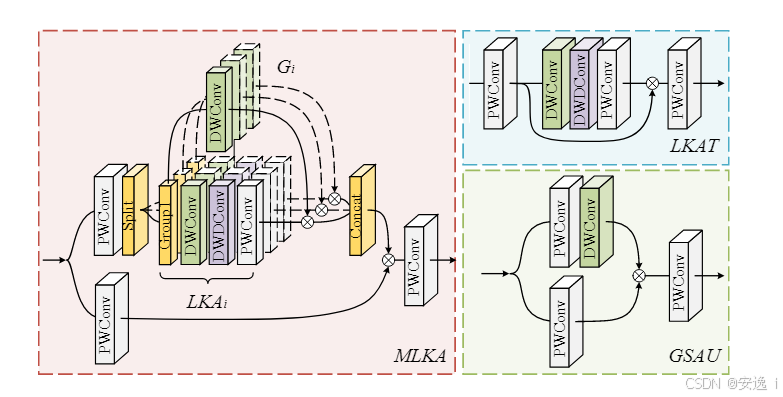
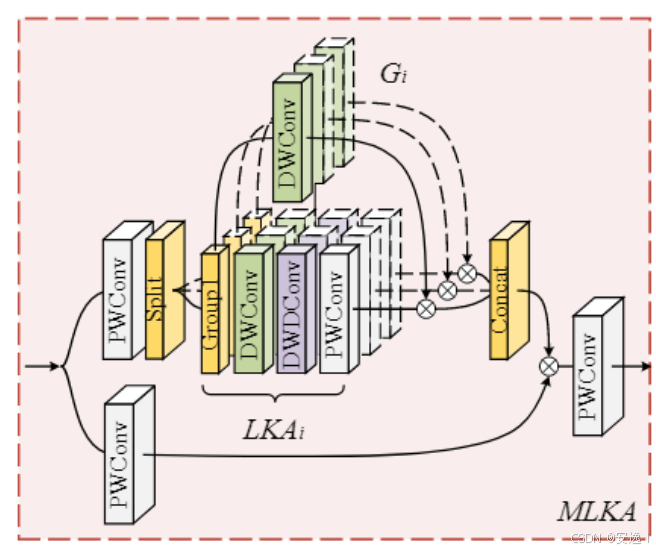
多尺度注意力模块(MLKA)
MLKA 模块实现了多尺度大核空间注意力,通过分组和门控机制提升特征表达能力,具体流程如下:
-
归一化与升维:输入特征先经过
LayerNorm层规范化,再通过 1×1 卷积将通道数扩大为原来的两倍,方便后续分组操作。 -
通道拆分:将扩展后的特征在通道维度一分为二,得到两个子特征
a和x,其中a用于计算注意力权重,x用于被加权。 -
多尺度分组:将
a再分为三等份,每份对应不同感受野大小的卷积组:- 第一组用
3×3深度卷积 +5×5膨胀卷积(膨胀率为2)+1×1卷积, - 第二组用
5×5深度卷积 +7×7膨胀卷积(膨胀率为3)+1×1卷积, - 第三组用
7×7深度卷积 +9×9膨胀卷积(膨胀率为4)+1×1卷积。
这一步通过不同大小和膨胀率的深度卷积,捕获多尺度的空间依赖关系。
- 第一组用
-
门控加权:对每组特征分别用同尺寸的深度卷积生成门控权重
X3,X5,X7,与对应的多尺度大核注意力结果相乘,实现动态调整关注区域,减弱无关信息。 -
融合输出:将三组加权后的特征拼接,乘以原始特征的另一半
x,再通过 1×1 卷积降维,并乘以一个可学习的缩放参数,最后加上输入的残差,实现特征增强与信息传递。
源码
class GroupGLKA(nn.Module):# 多尺度大核注意力模块,结合门控机制提升空间特征表达能力def __init__(self, n_feats, k=2, squeeze_factor=15):super().__init__()i_feats = 2 * n_feats # 扩展通道数,便于拆分和融合self.n_feats = n_featsself.i_feats = i_feats# 对输入特征进行通道归一化,保持通道维度优先(channels_first)self.norm = LayerNorm(n_feats, data_format='channels_first')# 可学习的缩放参数,用于调整输出特征幅度self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)# 多尺度大核注意力子模块,采用深度卷积+膨胀卷积组合,捕获不同感受野信息self.LKA7 = nn.Sequential(nn.Conv2d(n_feats // 3, n_feats // 3, 7, 1, 7 // 2, groups=n_feats // 3), nn.Conv2d(n_feats // 3, n_feats // 3, 9, stride=1, padding=(9 // 2) * 4, groups=n_feats // 3, dilation=4),nn.Conv2d(n_feats // 3, n_feats // 3, 1, 1, 0))self.LKA5 = nn.Sequential(nn.Conv2d(n_feats // 3, n_feats // 3, 5, 1, 5 // 2, groups=n_feats // 3), nn.Conv2d(n_feats // 3, n_feats // 3, 7, stride=1, padding=(7 // 2) * 3, groups=n_feats // 3, dilation=3),nn.Conv2d(n_feats // 3, n_feats // 3, 1, 1, 0))self.LKA3 = nn.Sequential(nn.Conv2d(n_feats // 3, n_feats // 3, 3, 1, 1, groups=n_feats // 3), nn.Conv2d(n_feats // 3, n_feats // 3, 5, stride=1, padding=(5 // 2) * 2, groups=n_feats // 3, dilation=2),nn.Conv2d(n_feats // 3, n_feats // 3, 1, 1, 0))# 对应的门控卷积,用于生成空间门控权重,调整多尺度注意力的激活区域self.X3 = nn.Conv2d(n_feats // 3, n_feats // 3, 3, 1, 1, groups=n_feats // 3)self.X5 = nn.Conv2d(n_feats // 3, n_feats // 3, 5, 1, 5 // 2, groups=n_feats // 3)self.X7 = nn.Conv2d(n_feats // 3, n_feats // 3, 7, 1, 7 // 2, groups=n_feats // 3)# 先通过1×1卷积将通道数从 n_feats 扩展到 i_feats (2倍),为拆分做准备self.proj_first = nn.Sequential(nn.Conv2d(n_feats, i_feats, 1, 1, 0))# 通过1×1卷积将加权后的特征通道数恢复为 n_featsself.proj_last = nn.Sequential(nn.Conv2d(n_feats, n_feats, 1, 1, 0))def forward(self, x, pre_attn=None, RAA=None):shortcut = x.clone() # 残差连接,保留输入特征x = self.norm(x) # 先归一化输入x = self.proj_first(x) # 升维,扩充通道数为2倍# 将扩充后的特征在通道维度一分为二,a用于注意力权重计算,x用于加权后的特征乘法a, x = torch.chunk(x, 2, dim=1) # 将a再分为三份,分别对应不同尺度的注意力子模块a_1, a_2, a_3 = torch.chunk(a, 3, dim=1)# 多尺度大核注意力计算:# 每部分a_i经过对应LKA和门控卷积相乘,捕获不同尺度的空间信息,并通过门控过滤无关信息a = torch.cat([self.LKA3(a_1) * self.X3(a_1), self.LKA5(a_2) * self.X5(a_2), self.LKA7(a_3) * self.X7(a_3)], dim=1)# 将加权的注意力a与另一半x相乘,实现门控加权,# 再通过1×1卷积恢复通道数,乘以可学习缩放参数,最后加上残差x = self.proj_last(x * a) * self.scale + shortcutreturn x门控空间注意力单元(GSAU)
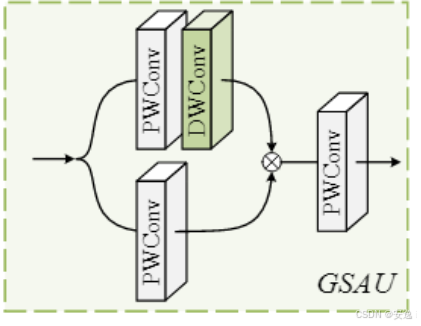
门控空间注意力单元(Gated Spatial Attention Unit, GSAU),特点如下:
- Ghost特征扩展:先用1×1卷积将通道数扩展2倍,再拆分成门控权重和特征两部分,提升表达能力。
- 深度空间卷积门控:对一半特征做深度卷积,捕获空间信息,用作门控权重,对另一半特征做加权。
- 残差连接与缩放:残差保证梯度稳定,缩放参数调节注意力强度。
- 轻量高效:结构简单,计算成本低,但能有效加强空间特征表达。
源码
class SGAB(nn.Module):# Gated Spatial Attention Unit(门控空间注意力单元)def __init__(self, n_feats, drop=0.0, k=2, squeeze_factor=15, attn='GLKA'):super().__init__()i_feats = n_feats * 2 # 通道扩展为2倍,方便分割处理# 1×1卷积,将输入通道数从 n_feats 升维到 2*n_feats(Ghost特征扩展)self.Conv1 = nn.Conv2d(n_feats, i_feats, 1, 1, 0)# 深度卷积,7×7卷积核,分组数等于通道数,实现通道内空间卷积self.DWConv1 = nn.Conv2d(n_feats, n_feats, 7, 1, 7 // 2, groups=n_feats)# 1×1卷积,将处理后通道数恢复为 n_featsself.Conv2 = nn.Conv2d(n_feats, n_feats, 1, 1, 0)# 通道归一化,channels_first格式,提升训练稳定性self.norm = LayerNorm(n_feats, data_format='channels_first')# 可学习的缩放参数,用于调整输出幅度self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)def forward(self, x):shortcut = x.clone() # 残差连接,保留输入特征# 先归一化输入,再通过1×1卷积升维(Ghost Expand)x = self.Conv1(self.norm(x))# 将升维后的特征在通道维度一分为二,a用于深度卷积生成门控权重,x用于加权特征a, x = torch.chunk(x, 2, dim=1)# 用深度卷积DWConv1对a进行空间卷积,得到空间门控权重,再与x逐元素相乘实现门控x = x * self.DWConv1(a)# 用1×1卷积Conv2融合通道信息,调整通道数x = self.Conv2(x)# 乘以缩放参数scale,并加上残差,输出return x * self.scale + shortcutLarge Kernel Attention Tail(LKAT)
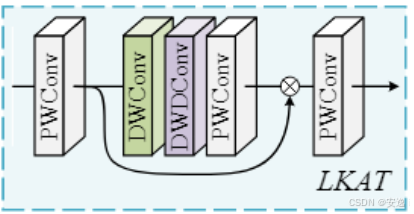
LKAT 模块实现了超分网络尾部的大核注意力增强,具体流程如下:
初始映射与激活:输入特征先通过 1×1 卷积映射到同样通道数,再经 GELU 激活,提升非线性表达能力。
大核注意力:激活后的特征进入深度可分离大核注意力子模块,依次执行
- 7×7 深度卷积(groups=通道数,padding=3)
- 9×9 膨胀卷积(dilation=3,padding=9//2×3)
- 1×1 卷积该组合既扩大了感受野,又保持了计算效率。
门控加权:将初始映射后的特征与大核注意力输出逐元素相乘,动态调整各空间位置的重要性,增强关键信息。
通道融合:最后通过 1×1 卷积将加权结果融合回原始通道维度,生成尾部输出,为后续重建提供更丰富的全局上下文。
class LKAT(nn.Module):"""Large Kernel Attention Tail(尾部大核注意力模块)用于在超分网络的尾部增强全局上下文信息,提升重建效果。"""def __init__(self, n_feats):super().__init__()# conv0: 初始映射 + 非线性激活# 1×1 卷积用于调整通道数并混合通道信息,GELU 提供平滑的非线性self.conv0 = nn.Sequential(nn.Conv2d(n_feats, n_feats, kernel_size=1, stride=1, padding=0),nn.GELU())# att: 大核注意力子模块(深度可分离 + 膨胀卷积)# 7×7 depth-wise 卷积扩展局部感受野# 9×9 dilated depth-wise 卷积(dilation=3)进一步扩大感受野至更大范围# 1×1 point-wise 卷积用于融合通道信息self.att = nn.Sequential(nn.Conv2d(n_feats, n_feats, kernel_size=7, stride=1, padding=7//2, groups=n_feats),nn.Conv2d(n_feats, n_feats, kernel_size=9, stride=1,padding=(9//2)*3, dilation=3, groups=n_feats),nn.Conv2d(n_feats, n_feats, kernel_size=1, stride=1, padding=0)) # conv1: 最终通道融合# 1×1 卷积将加权后的特征再次混合,输出与输入通道数一致self.conv1 = nn.Conv2d(n_feats, n_feats, kernel_size=1, stride=1, padding=0)def forward(self, x):# 初始映射与激活# x0 具有更强的非线性特征表示x0 = self.conv0(x)# 大核注意力计算# att_out 是对 x0 的全局上下文响应图att_out = self.att(x0)# 门控加权# 将原始映射 x0 与注意力图逐元素相乘,突出重要特征,抑制不相关信息x_weighted = x0 * att_out# 通道融合与输出out = self.conv1(x_weighted)return out