【机器人】复现 WMNav 具身导航 | 将VLM集成到世界模型中
WMNav 是由VLM视觉语言模型驱动的,基于世界模型的对象目标导航框架。
设计一种预测环境状态的记忆策略,采用在线好奇心价值图来量化存储,目标在世界模型预测的各种场景中出现的可能性。
本文分享WMNav复现和模型推理的过程~
下面是一个查找床示例:

目录
1、创建Conda环境
2、安装habitat模拟器
4、安装依赖库
5、准备数据集HM3D和MP3D
6、准备Gemini VLM
7、修改配置文件
8、进行模型推理
1、创建Conda环境
首先创建一个Conda环境,名字为wmnav,python版本为3.9
进入wmnav环境
conda create -n wmnav python=3.9 cmake=3.14.0
conda activate wmnav然后下载代码,进入代码工程:https://github.com/B0B8K1ng/WMNavigation
git clone https://github.com/B0B8K1ng/WMNavigation
cd WMNavigation2、安装habitat模拟器
我需要安装habitat-sim==0.3.1、headless 和 withbullet
conda install habitat-sim=0.3.1 withbullet headless -c conda-forge -c aihabitat等待安装完成~
3、安装WMNav的src
执行下面命令进行安装:
pip install -e .使用setup.py文件进行安装的:
from setuptools import setup, find_packagessetup(name='WMNav',version='0.1',packages=find_packages('src'),package_dir={'': 'src'},
)
对应的源码文件:
4、安装依赖库
执行下面命令进行安装:
pip install -r requirements.txt主要依赖下面的库(torch==2.2.2、python-dotenv==1.0.1、Flask==3.0.3等)
Flask==3.0.3
magnum==0.0.0
matplotlib==3.8.4
networkx==3.2.1
numpy==1.23.5
numpy_quaternion==2023.0.3
opencv_python==4.9.0.80
opencv_python_headless==4.10.0.84
pandas==2.2.3
Pillow==11.0.0
protobuf==3.20.3
python-dotenv==1.0.1
PyYAML==6.0.2
regex==2024.4.16
Requests==2.32.3
scipy==1.13.1
seaborn==0.13.2
sympy==1.12
torch==2.2.2
transformers==4.43.3
google-generativeai==0.8.3
wandb==0.18.5等待安装完成~
5、准备数据集HM3D和MP3D
该工程代码是基于 Habitat 模拟器 ,HM3D 和 MP3D数据集可 在此处 获得。
将下载的 HM3D v0.1、HM3D v0.2 和 MP3D 文件夹移动到以下配置中:
├── data
│ ├── hm3d_v0.1/
│ │ ├── val/
│ │ │ ├── 00800-TEEsavR23oF/
│ │ │ │ ├── TEEsavR23oF.navmesh
│ │ │ │ ├── TEEsavR23oF.glb
│ │ ├── hm3d_annotated_basis.scene_dataset_config.json
│ ├── objectnav_hm3d_v1/
│ │ ├── val/
│ │ │ ├── content/
│ │ │ │ ├──4ok3usBNeis.json.gz
│ │ │ ├── val.json.gz
│ ├── hm3d_v0.2/
│ │ ├── val/
│ │ │ ├── 00800-TEEsavR23oF/
│ │ │ │ ├── TEEsavR23oF.basis.navmesh
│ │ │ │ ├── TEEsavR23oF.basis.glb
│ │ ├── hm3d_annotated_basis.scene_dataset_config.json
│ ├── objectnav_hm3d_v2/
│ │ ├── val/
│ │ │ ├── content/
│ │ │ │ ├──4ok3usBNeis.json.gz
│ │ │ ├── val.json.gz
│ ├── mp3d/
│ │ ├── 17DRP5sb8fy/
│ │ │ ├── 17DRP5sb8fy.glb
│ │ │ ├── 17DRP5sb8fy.house
│ │ │ ├── 17DRP5sb8fy.navmesh
│ │ │ ├── 17DRP5sb8fy_semantic.ply
│ │ ├── mp3d_annotated_basis.scene_dataset_config.json
│ ├── objectnav_mp3d/
│ │ ├── val/
│ │ │ ├── content/
│ │ │ │ ├──2azQ1b91cZZ.json.gz
│ │ │ ├── val.json.gz
这里可以准备三个数据集,然后逐个测试和验证;
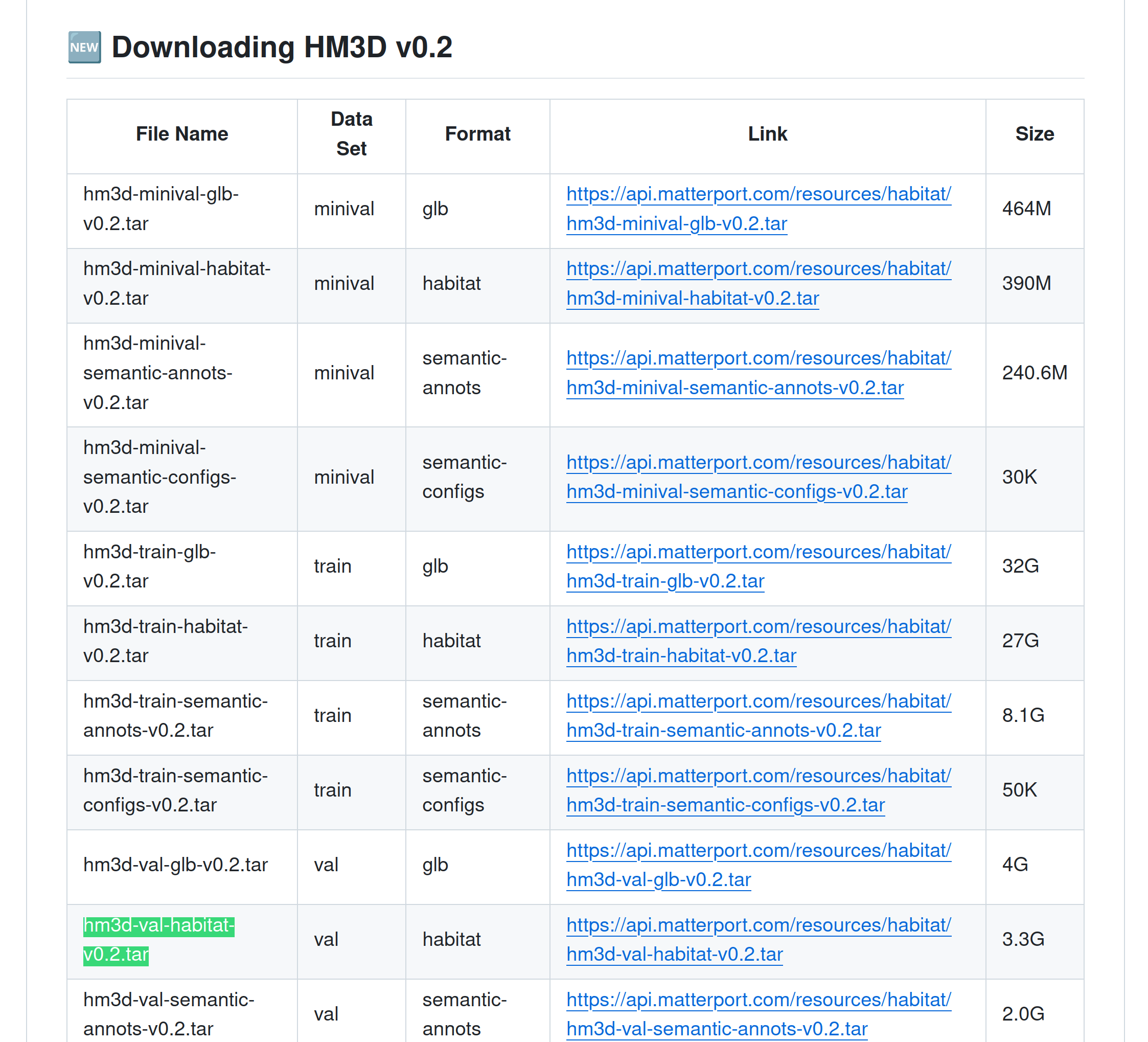
也可以下载其中一个进行验证,比如 HM3D v0.2
hm3d_v0.2下载地址:https://github.com/matterport/habitat-matterport-3dresearch
选择的下载文件:hm3d-val-habitat-v0.2.tar
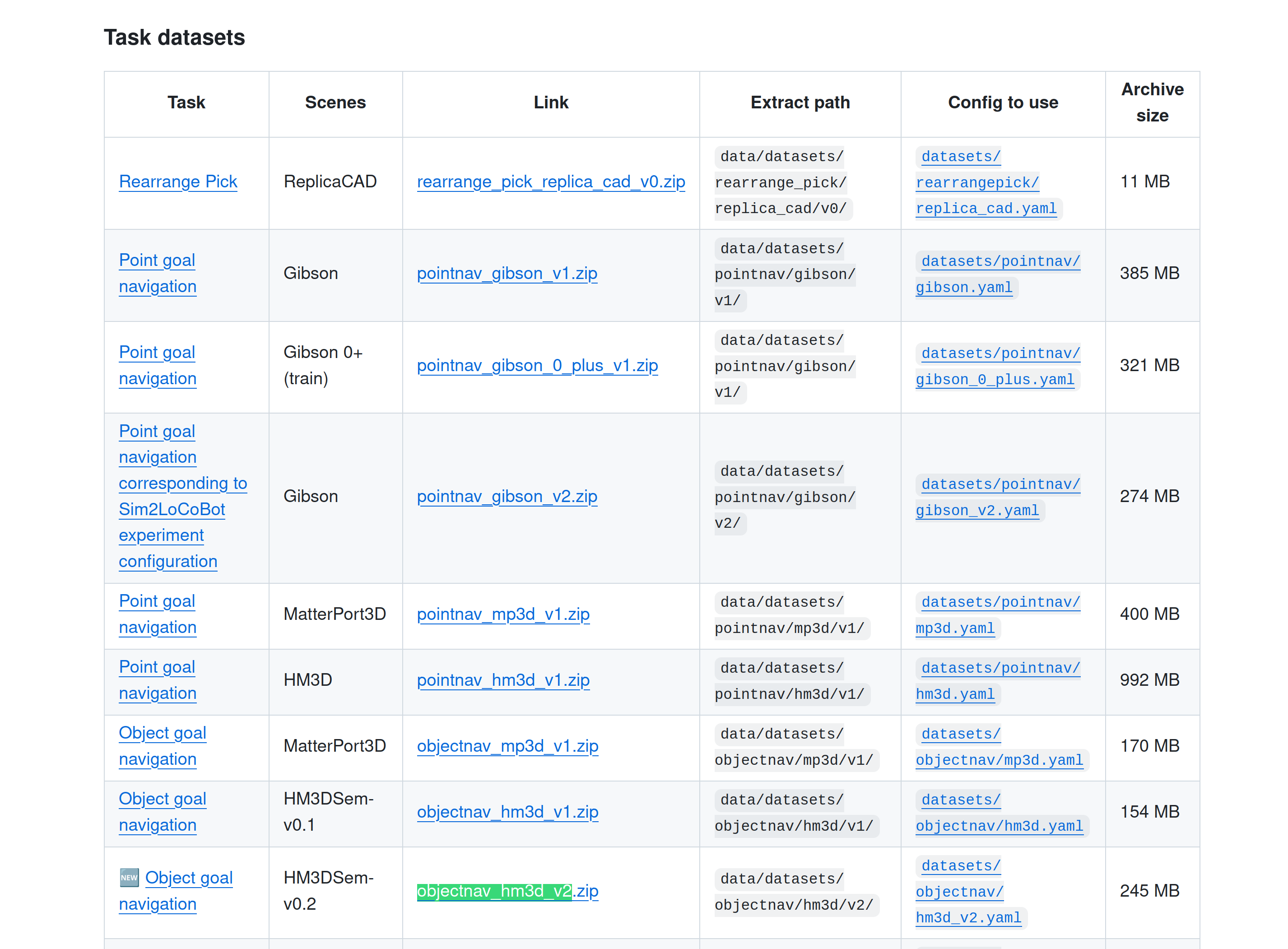
然后需要下载对应的objectnav_hm3d_v2, 下载地址:
https://github.com/facebookresearch/habitat-lab/blob/main/DATASETS.md
6、准备Gemini VLM
默认使用Gemini VLM,需要将基本 URL 和 api 密钥粘贴到 .env 文件 名为 GEMINI_BASE_URL 和 GEMINI_API_KEY 的变量的 中。
我们还可以尝试其他 VLM,方法是修改 api.py(使用 OpenAI 库)
api的申请地址:https://aistudio.google.com/app/apikey
需要使用谷歌帐号登陆,然后点击“创建API密码”进行创建API密匙
后面需要填写:GEMINI_BASE_URL、GEMINI_API_KEY
7、修改配置文件
修改.env文件的,主要是GEMINI_BASE_URL、GEMINI_API_KEY、DATASET_ROOT
GEMINI_BASE_URL= "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash:generateContent?key=GEMINI_API_KEY"GEMINI_API_KEY= "AIzaSyA-DDe-xxxxxxxxxxxxx" #INSERT API KEY
DATASET_ROOT= "./data/"
MAGNUM_LOG=quiet
GLOG_minloglevel=4
HABITAT_SIM_LOG=quiet
HABITAT_LOG_LEVEL=error修改 config/WMNav.yaml配置文件(可选)
# 任务类型:目标导航任务
task: ObjectNav
# 使用的智能体类
agent_cls: WMNavAgent
# 使用的环境类
env_cls: WMNavEnv# 智能体配置
agent_cfg:# 导航性模式:'none'(无导航能力),'depth_estimate'(使用 ZoeDepth 进行深度估计),'segmentation'(使用 Segformer 进行分割),'depth_sensor'(使用深度传感器)navigability_mode: 'depth_sensor' # 上下文历史记录数量,这里设置为 0context_history: 0# 探索偏差,用于调整智能体的行为explore_bias: 4 # 智能体可执行的最大动作距离max_action_dist: 1.7# 智能体可执行的最小动作距离min_action_dist: 0.5# 动作距离裁剪比例,避免智能体过于靠近障碍物clip_frac: 0.66 # 智能体停止后继续执行的动作长度stopping_action_dist: 1.5 # 默认动作距离,当 VLM 选择的动作无效时,智能体向前移动的距离default_action: 0.2 # 视野范围与角度增量的比率spacing_ratio: 360 # 考虑的动作角度数量num_theta: 60 # 图像边缘阈值,当动作投影在图像边缘的 4% 范围内时不进行投影image_edge_threshold: 0.04 # 智能体转向冷却时间,即智能体在转向后需要等待的步数turn_around_cooldown: 3 # 可导航性高度阈值,从地面开始计算的可导航性高度navigability_height_threshold: 0.2 # 地图比例尺,每米对应的像素数量map_scale: 100 # 视觉语言模型(VLM)配置vlm_cfg:# 使用的模型类model_cls: GeminiVLM# 模型参数model_kwargs:# 使用的模型名称model: gemini-1.5-pro# 是否启用全景填充panoramic_padding: False# 仿真环境配置
sim_cfg:# 智能体的高度agent_height: 0.88# 智能体的半径agent_radius: 0.18# 是否允许滑动allow_slide: true# 是否使用目标图像智能体use_goal_image_agent: false# 传感器配置sensor_cfg:# 传感器高度height: 0.88# 传感器俯仰角pitch: -0.25# 传感器视野范围fov: 79# 传感器图像高度img_height: 480# 传感器图像宽度img_width: 640# 环境配置
env_cfg:# 总共的剧集数量(任务数量)num_episodes: 1# 每个剧集的最大步数max_steps: 40# 日志记录频率log_freq: 1# 数据集划分方式,这里使用验证集split: val# 成功阈值,智能体与目标之间的距离小于该值时认为任务成功success_threshold: 1.0# 数据集实例数量,将数据集划分为多个实例instances: 1 # 当前运行的实例编号instance: 0 # 是否并行运行parallel: false# 环境名称name: default# Flask 服务器端口,用于聚合来自不同实例的结果port: 5000 8、进行模型推理
执行下面命令:
python scripts/main.py在logs目录下,运行结果示例:

分享完成~
相关文章推荐:
UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】复现 UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】复现 ECoT 具身思维链推理-CSDN博客
【机器人】复现 SG-Nav 具身导航 | 零样本对象导航的 在线3D场景图提示-CSDN博客