编译原理实验五:LR语法分析器的控制程序
文章目录
- 实验五 LR语法分析器的控制程序
- 一、实验内容
- 二、实验目的
- 三、实验要求
- 四、相关说明
- (一)SLR(1)分析表构造示例
- (二)LR语法分析器分析过程示例
- (三)C语言实现LR语法分析器总控程序
- (四)另一个文法分析示例
- 五、参考代码
- 六、操作步骤
- 七,运行结果
- (一)lex_r.txt文件
- (二)par_r.txt文件
实验五 LR语法分析器的控制程序
一、实验内容
编程实现LR语法分析器的控制程序。
二、实验目的
1.掌握SLR(1)分析表的构造。
2.掌握LR语法分析器的分析过程,具体来讲就是控制程序是如何根据LR分析表来工作的。
三、实验要求
- 写好实验预习报告。
- 编写上机源程序和测试程序。
- 写出实验结果。
- 实验完后要上交实验报告 。
四、相关说明
(一)SLR(1)分析表构造示例
已知文法G[E]:
E→E+T|T
T→T*F|F
F→(E)|i
构造其SLR(1)分析表,步骤如下:
- 预备工作
- 引入产生式S’→E,将文法拓广成G’[S’]。
- 为产生式编号:
S’→E
E→E+T
E→T
T→T*F
T→F
F→(E)
F→i - 构造文法的状态转换函数GO(I,X)和项目集规范族。
- 计算非终结符号的follow集:
follow(S’)={#}
follow(E)={#,+, )}
follow(T)={#,+, ),}
follow(F)={#,+, ),}
- 构造分析表:得到的SLR(1)分析表如下:
| + | * | ( | ) | i | # | E | T | F | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | s4 | 0 | s5 | 0 | 1 | 2 | 3 |
| 1 | s6 | 0 | 0 | 0 | 0 | Acc | 0 | 0 | 0 |
| 2 | r2 | s7 | 0 | r2 | 0 | r2 | 0 | 0 | 0 |
| 3 | r4 | r4 | 0 | r4 | 0 | r4 | 0 | 0 | 0 |
| 4 | 0 | 0 | s4 | 0 | s5 | 0 | 8 | 2 | 3 |
| 5 | r6 | r6 | 0 | r6 | 0 | r6 | 0 | 0 | 0 |
| 6 | 0 | 0 | s4 | 0 | s5 | 0 | 0 | 9 | 3 |
| 7 | 0 | 0 | s4 | 0 | s5 | 0 | 0 | 0 | 10 |
| 8 | s6 | s6 | 0 | s11 | 0 | 0 | 0 | 0 | 0 |
| 9 | r1 | r1 | s7 | r1 | 0 | r1 | 0 | 0 | 0 |
| 10 | r3 | r3 | r3 | r3 | 0 | r3 | 0 | 0 | 0 |
| 11 | r5 | r5 | r5 | r5 | 0 | r5 | 0 | 0 | 0 |
分析表不含多重定义,该分析表是SLR(1)分析表,相应文法为SLR(1)文法。SLR(1)分析法虽理论上不严格,但很实用且容易实现,能解决大部分语言的识别问题。若要更严格精确地向前看一个输入符号,需使用规范LR分析法(LR(1)分析法)。
(二)LR语法分析器分析过程示例
假设源程序为“ab+c”,经词法分析用单词种别表示为“ii+i#” 。利用上述SLR(1)分析表,手工模拟语法分析器的计算过程如下:
| step | 状态栈 | 符号栈 | 输入符号 | 动作 |
|---|---|---|---|---|
| 0) | 0 | # | i*i+i# | 初始 |
| 1) | 05 | #i | *i+i# | 移进 |
| 2) | 03 | #F | *i+i# | 归约 |
| 3) | 02 | #T | *i+i# | 归约 |
| 4) | 027 | #T* | i+i# | 移进 |
| 5) | 0275 | #T*i | +i# | 移进 |
| 6) | 02710 | #T*F | +i# | 归约 |
| 7) | 02 | #T | +i# | 归约 |
| 8) | 01 | #E | +i# | 归约 |
| 9) | 016 | #E+ | i# | 移进 |
| 10) | 0165 | #E+i | # | 移进 |
| 11) | 0163 | #E+F | # | 归约 |
| 12) | 0169 | #E+T | # | 归约 |
| 13) | 01 | #E | # | 归约 |
| Acc(接受) |
分析过程中,栈中元素构成规范句型的活前缀,加上输入串余下部分为规范句型。一旦栈顶出现句柄,马上归约成产生式左部符号。控制程序算法如下:
- 移进:若M[Stop][t.code]=sj,说明句柄尚未形成,执行移进操作。将j移入状态栈,t.code移入符号栈,j成为新的栈顶状态Stop,读下一个单词。
- 归约:若M[Stop][t.code]=rk,说明句柄已出现在栈顶,用编号为K的产生式A→β进行归约。假设LEN(β)=r,M[Stop-r][A]=j。先将栈顶r个元素出栈,再将j和A分别移入状态栈和符号栈,j成为新的栈顶状态Stop,当前处理单词不变。
- 接受:M[Stop][t.code]=Acc,表示输入串是合法句子,程序终止运行。
- 出错:M[Stop][t.code]=空白,表示出错,最简单处理为程序终止运行。
(三)C语言实现LR语法分析器总控程序
以例1中的SLR(1)分析表为例,用C语言实现LR语法分析器的总控程序。为直观起见,产生式按原样储存。产生式的左部符号为p[i][0],产生式右部符号串长度为strlen(p[i]) - 3(ɛ产生式右部符号串长度为0单独计算)。将SLR(1)分析表数字化,si改用i表示,rj改用 - j表示,Acc用99表示,出错用0表示。总控程序源代码如下:
#include <fstream>
using namespace std;
#include <iostream>
#include <stdlib.h>
#include <string.h>struct code_val{char code; char val[20];
};// 产生式
const char *p[]={"S’→E", "E→E+T", "E→T", "T→T*F", "T→F", "F→(E)", "F→i"
};const char TNT[]="+*()i#ETF";// LR分析表数字化,列字符+*()i#ETF用数字012345678标识
const int M[][9]={{0, 0, 4, 0, 5, 0, 1, 2, 3},{6, 0, 0, 0, 0, 99},{-2, 7, 0, -2, 0, -2},{-4, -4, 0, -4, 0, -4},{0, 0, 4, 0, 5, 0, 8, 2, 3},{-6, -6, 0, -6, 0, -6},{0, 0, 4, 0, 5, 0, 0, 9, 3},{0, 0, 4, 0, 5, 0, 0, 0, 10},{6, 0, 0, 11},{-1, 7, 0, -1, 0, -1},{-3, -3, 0, -3, 0, -3},{-5, -5, 0, -5, 0, -5}
};int col(char); void main() {// 状态栈初值int state[50]={0}; // 符号栈初值char symbol[50]={'#'}; // 栈顶指针初值int top=0; // 语法分析结果输出至文件par_r.txtofstream coutf("par_r.txt"); // lex_r.txt存放词法分析结果,语法分析器从该文件输入数据ifstream cinf("lex_r.txt"); // 结构变量,存放单词二元式struct code_val t; // 读一个单词cinf >> t.code >> t.val; int action; int i,j=0; // 输出标题(并非必要)coutf << "step\t状态栈\t符号栈\t输入符号" << endl; do{// 输出step(并非必要)coutf << j++ << ") " << '\t'; for(i=0;i<=top;i++) coutf << state[i] << " "; coutf << '\t'; for(i=0;i<=top;i++) coutf << symbol[i]; // 输出当前输入符号(单词种别,并非必要)coutf << '\t' << t.code << endl; action = M[state[top]][col(t.code)]; // 移进if(action > 0 && action != 99){ state[++top]=action; symbol[top]=t.code; // 读下一个单词cinf >> t.code >> t.val; }// 归约else if(action < 0){ // ε产生式的右部符号串长度为0,无需退栈if(strcmp(p[-action]+3,"ε")){ // "→"为汉字,占二字节,故减3top = top-(strlen(p[-action])-3); }state[top + 1]=M[state[top]][col(p[-action][0])]; symbol[++top]=p[-action][0]; }// 接受else if(action == 99){ coutf << "\tAcc" << endl; break;}// 出错else{ coutf << "Err in main()>" << action << endl; break;}}while(1);
}int col(char c) { for(int i=0;i<(int)strlen(TNT);i++){if(c == TNT[i]) return i; }cout << "Err in col char>" << c << endl; exit(0);
}
假设源程序“a*b+c”的单词二元式存放于文件lex_r.txt中,控制程序处理结果保存在文件par_r.txt中,与手工计算结果一致。
程序中的常量p(产生式)、TNT(列字符)、M(分析表)与文法有关。当控制程序用于其他场合时,修改这些常量值即可,程序其余部分无需改动。
(四)另一个文法分析示例
考虑文法G[S’]:
① S’→S
② S→(S)
③ S→ε
分析步骤如下:
- 构造识别该文法的所有规范句型的活前缀的DFA。
- 对归约项目左部符号求FOLLOW集,FOLLOW(S)={),# }。
- 根据SLR(1)分析表的构造方法,由它的DFA得到分析表如下:
| 状态 | ( | ) | # | S |
|---|---|---|---|---|
| 0 | S2 | r2 | r2 | 1 |
| 1 | Acc | |||
| 2 | S2 | r2 | r2 | 3 |
| 3 | S4 | |||
| 4 | r1 | r1 |
五、参考代码
#include <fstream>
using namespace std;
#include <iostream>
#include <stdlib.h>
#include <string.h>// 定义存储单词二元式的结构体
struct code_val {char code;char val[20];
};// 产生式
const char* p[] = {"S’→E", "E→E+T", "E→T", "T→T*F", "T→F", "F→(E)", "F→i"
};// LR分析表列的字符
const char TNT[] = "+*()i#ETF";// LR分析表数字化,列字符+*()i#ETF用数字012345678标识
const int M[][9] = {{0, 0, 4, 0, 5, 0, 1, 2, 3},{6, 0, 0, 0, 0, 99},{-2, 7, 0, -2, 0, -2},{-4, -4, 0, -4, 0, -4},{0, 0, 4, 0, 5, 0, 8, 2, 3},{-6, -6, 0, -6, 0, -6},{0, 0, 4, 0, 5, 0, 0, 9, 3},{0, 0, 4, 0, 5, 0, 0, 0, 10},{6, 0, 0, 11},{-1, 7, 0, -1, 0, -1},{-3, -3, 0, -3, 0, -3},{-5, -5, 0, -5, 0, -5}
};// 列定位函数,将字符+*()i#ETF分别转换为数字012345678
int col(char c) {for (int i = 0; i < (int)strlen(TNT); i++) {if (c == TNT[i]) return i;}cout << "Err in col char>" << c << endl;exit(0); // 终止程序运行
}int main() {// 状态栈初值int state[50] = { 0 };// 符号栈初值char symbol[50] = { '#' };// 栈顶指针初值int top = 0;// 语法分析结果输出至文件par_r.txtofstream coutf("par_r.txt");// lex_r.txt存放词法分析结果,语法分析器从该文件输入数据ifstream cinf("lex_r.txt");// 结构变量,存放单词二元式struct code_val t;// 读一个单词cinf >> t.code >> t.val;int action;// 输出时使用的计数器,并非必要int i, j = 0;// 输出标题,并非必要coutf << "step\t状态栈\t符号栈\t输入符号" << endl;do {// 输出step,并非必要coutf << j++ << ") " << '\t';for (i = 0; i <= top; i++) coutf << state[i] << " ";coutf << '\t';for (i = 0; i <= top; i++) coutf << symbol[i];coutf << '\t' << t.code << endl;action = M[state[top]][col(t.code)];// 移进if (action > 0 && action != 99) {state[++top] = action;symbol[top] = t.code;// 读下一个单词cinf >> t.code >> t.val;}// 归约else if (action < 0) {// ε产生式的右部符号串长度为0,无需退栈if (strcmp(p[-action] + 3, "ε")) {// "→"为汉字,占二字节,故减3top = top - (strlen(p[-action]) - 3);}state[top + 1] = M[state[top]][col(p[-action][0])];symbol[++top] = p[-action][0];}// 接受else if (action == 99) {coutf << "\tAcc" << endl;break;}// 出错else {coutf << "Err in main()>" << action << endl;break;}} while (1);return 0;
}
六、操作步骤
1,双击程序快捷图标启动程序(可使用其他c++集中环境的程序)。

2,单击【新建项目】。
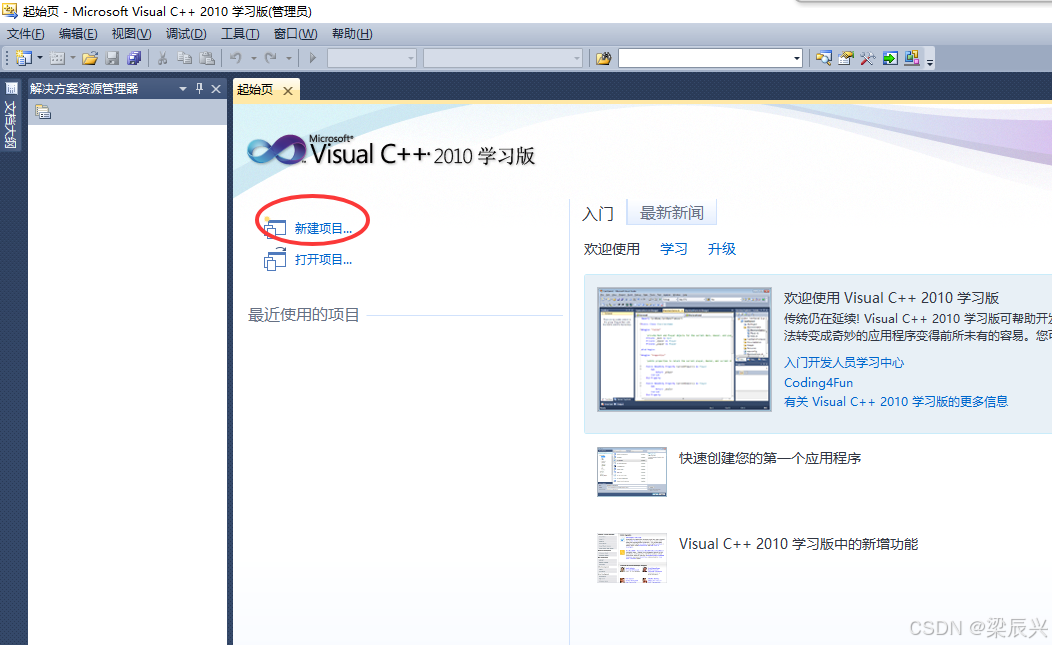
3,选择【空项目】——输入项目名称【shiyan5】——单击【确认】按钮。
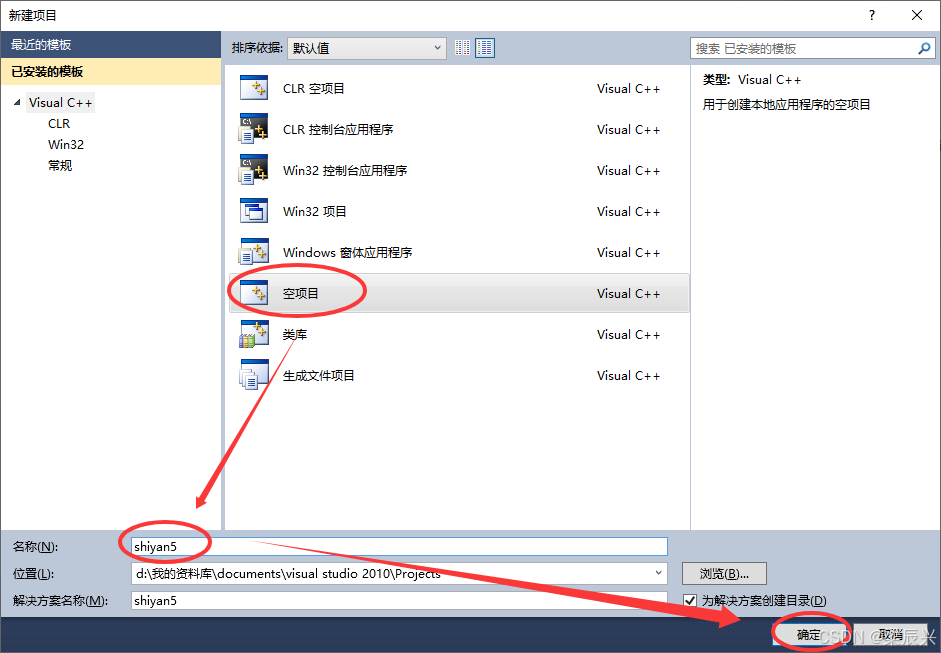
4,右击【源文件】——选择【添加】——单击【新建项】。
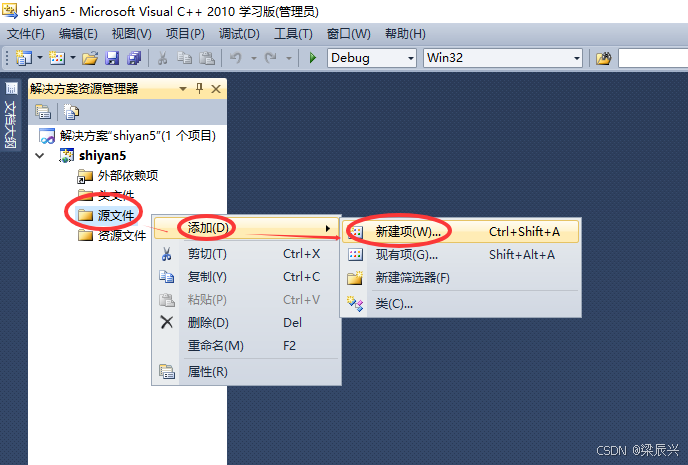
5,选择【C++文件】——输入项目文件名称【shiyan5.cpp】——单击【添加】按钮。
6,将上述的参考代码粘贴到shiyan5.cpp文件的内容中。
7,创建测试文件lex_r.txt,右击【资源文件】——选择【添加】——单击【新建项】。
8,这里不选择文件格式,直接输入完整的文件名【lex_r.txt】——单击【添加】按钮。
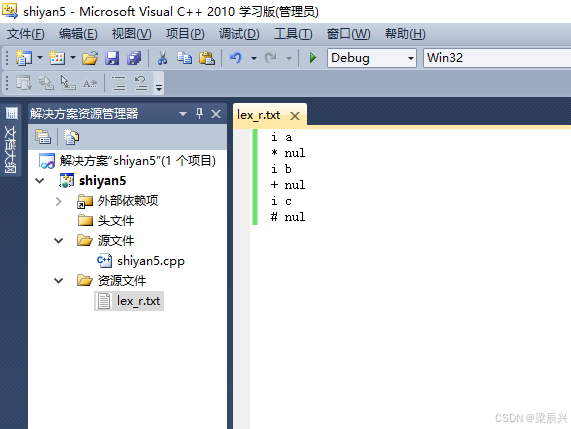
9,将下面的测试内容添加到文件lex_r.txt中。
i a
* nul
i b
+ nul
i c
# nul
10,添加完成后,保持文件。
11,创建输出结果的文件par_r.txt,右击【资源文件】——选择【添加】——单击【新建项】。
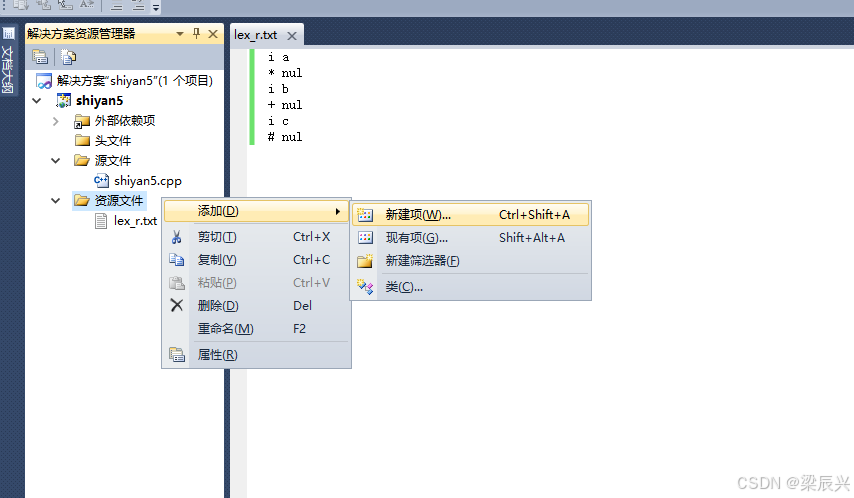
12,输入文件名【par_r.txt】——单击【添加】按钮。
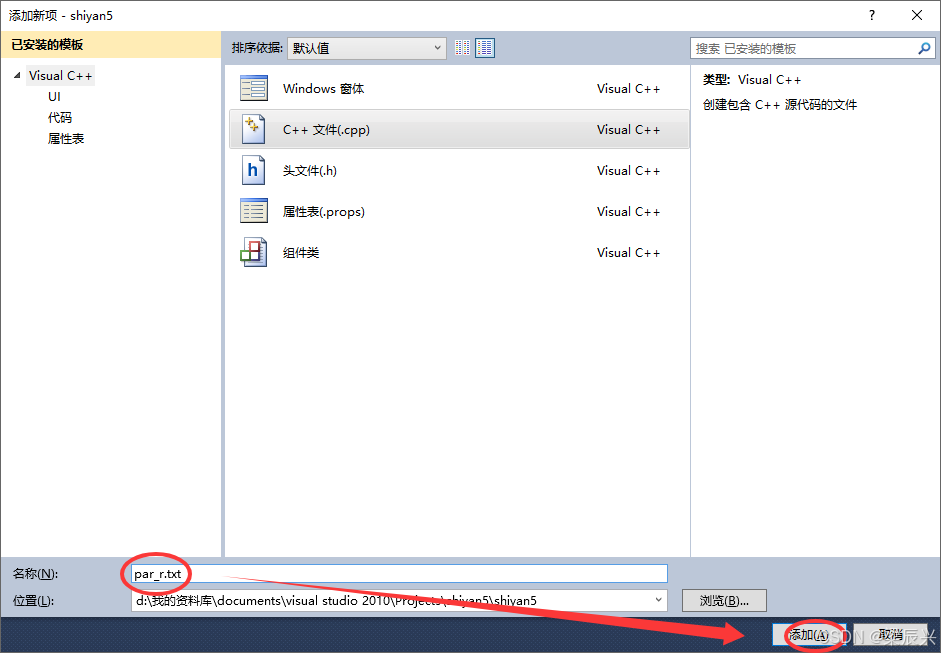
13,创建完成即可,不要添加任何内容。
14,右击【shiyan5.cpp】文件——单击【编译】。
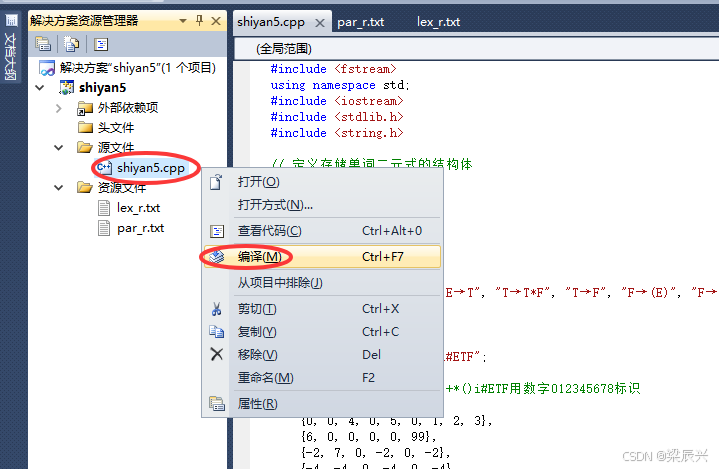
15,如下图编译成功。
16,单击绿色的【运行按钮】,运行项目。
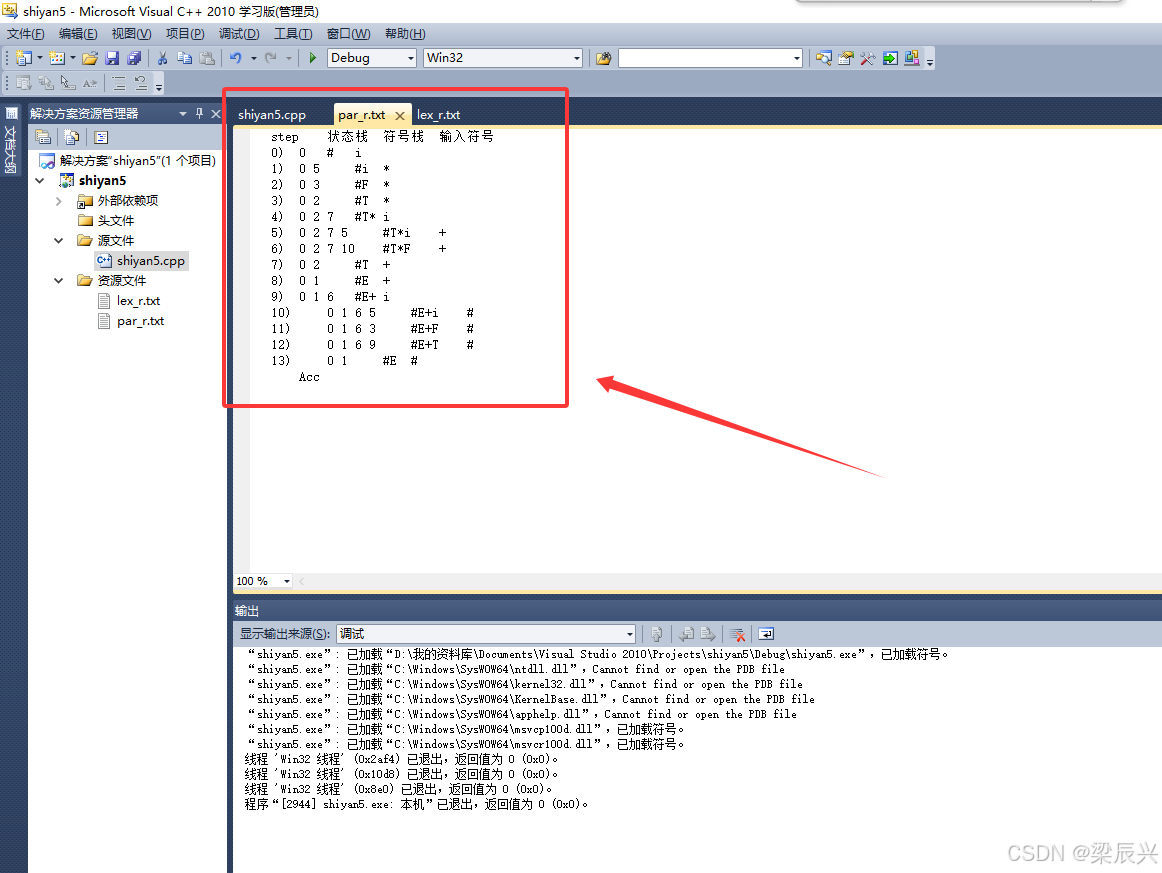
17,par_r.txt文件输出的运行结果。
七,运行结果
(一)lex_r.txt文件
i a
* nul
i b
+ nul
i c
# nul
(二)par_r.txt文件
step 状态栈 符号栈 输入符号
0) 0 # i
1) 0 5 #i *
2) 0 3 #F *
3) 0 2 #T *
4) 0 2 7 #T* i
5) 0 2 7 5 #T*i +
6) 0 2 7 10 #T*F +
7) 0 2 #T +
8) 0 1 #E +
9) 0 1 6 #E+ i
10) 0 1 6 5 #E+i #
11) 0 1 6 3 #E+F #
12) 0 1 6 9 #E+T #
13) 0 1 #E #Acc