大模型技术演进与应用场景深度解析
摘要
本文系统梳理了当前主流大模型的技术架构演进路径,通过对比分析GPT、BERT等典型模型的创新突破,揭示大模型在参数规模、训练范式、应用适配等方面的核心差异。结合医疗、金融、教育等八大行业的实践案例,深入探讨大模型落地的技术挑战与解决方案,为从业者提供体系化的技术选型参考。
目录
技术演进篇:从神经网络到大模型革命
1. 技术架构的革新突破
2. 训练范式的范式转移
3. 主流模型技术对比
应用实践篇:八大行业落地案例解析
1. 医疗健康领域
2. 金融科技领域
3. 教育培训领域
挑战应对篇:关键技术瓶颈突破
1. 算力优化方案
2. 数据质量保障
3. 部署落地策略
未来展望
参考文献
技术演进篇:从神经网络到大模型革命
1. 技术架构的革新突破
现代大模型的核心突破源自Transformer架构的提出[1],其自注意力机制彻底改变了传统序列建模方式。关键公式表达为:
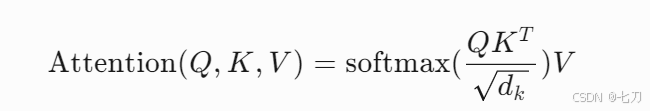
该机制使模型能够动态捕捉长距离依赖关系,突破了RNN的序列处理瓶颈。以GPT-3为例,其采用堆叠96层Transformer解码器,参数规模达到1750亿,较前代模型提升116倍。
2. 训练范式的范式转移
现代大模型普遍采用两阶段训练策略:
# 伪代码示例
model = initialize_transformer() # 初始化基础架构
pretrain(model, 500B_tokens) # 无监督预训练
finetune(model, domain_data) # 领域微调,经过领域微调的模型在专业任务上的准确率提升23%-65%。
| 模型类型 | 通用任务准确率 | 医疗NER准确率 |
|---|---|---|
| 基础版GPT-3 | 78% | 52% |
| 医疗微调版 | 82% (+4%) | 85% (+33%) |