【Linux网络】详解应用层http协议
http协议
- 一,再谈协议
- 1.1 例子
- 1.1 序列和反序列化
- 二,预备知识
- 2.1 认识url
- 2.2 urlencode和urldecode
- 三,http协议
- 3.1 http报文格式
- 3.2 post和get
- 3.3 状态码
- 3.4 cookie和session
- 3.5 常见header
- 四,总结
一,再谈协议
1.1 例子
假设们要实现一个网络聊天,那么我们聊天时要知道双方的昵称,和发消息的时间和消息内容,显然我们不可能把这三个信息去逐个发送,所以我们要将这三个信息整和为一条消息去发送,所以就要有结构化字段来打包这三个信息。
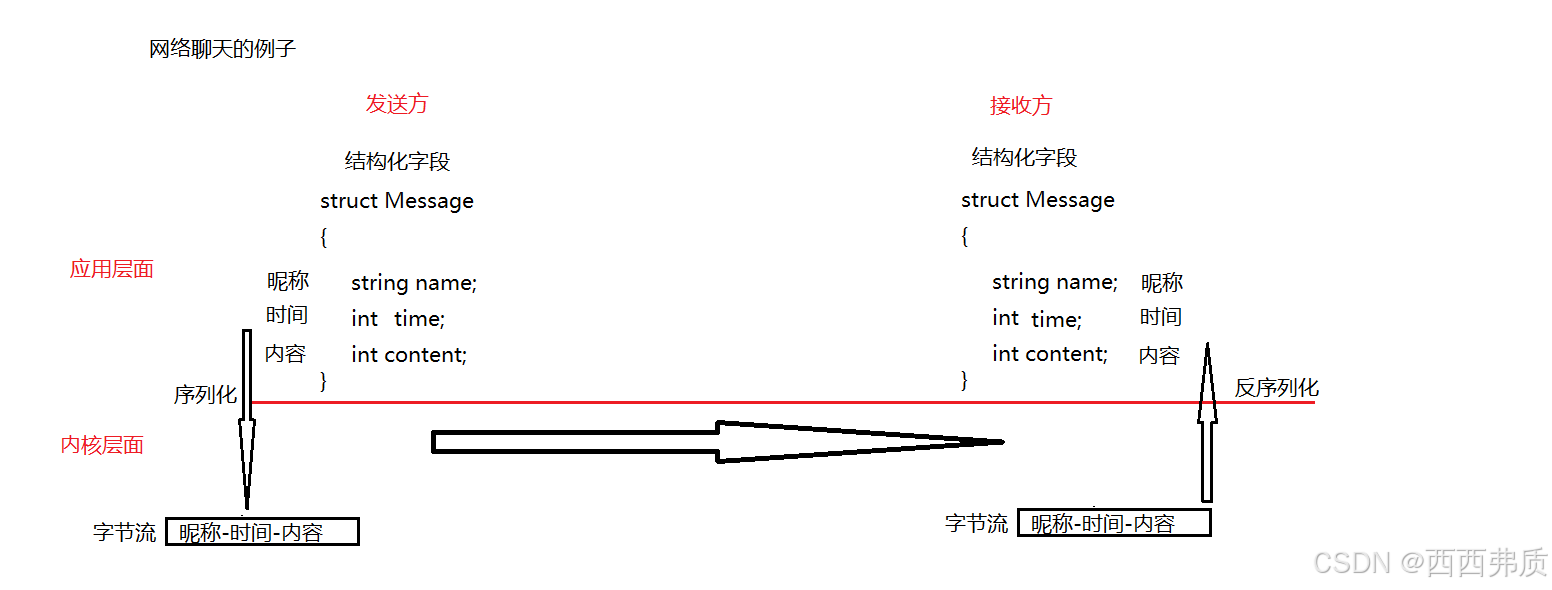
协议其实就是结构化字段,通信的双方通过把要发送的数据存在结构化字段中,然后双方在应用层都认识这个结构化字段,从而取出结构化字段中有效字段,就可以达到互相通信
1.1 序列和反序列化
那么在网络传输中我们不会直接发送这种结构化字段,而是在应用层将结构化字段进行序列化为一个字节流进行发送,同时接收时将这个字节流再进行反序列化为结构化字段
- 序列化:将协议对应的结构化数据转成
字节流(字符串) - 反序列化:将
字节流成结构化数据
为什么要序列和反序列化?
- 序列化是为了方便发送
- 反序列化是为了方便上层业务提取有效字段
- 通信双方的操作系统和语言可能不一样,所以就要在应用层屏蔽不同平台的差异
- 应用层的变化非常多,所以需要比较好扩展的
二,预备知识
在http这里我们不用再去写客户端,而是用浏览器作为客户端,通过url访问我们的server,得到响应后浏览器再为我们显示出来
2.1 认识url
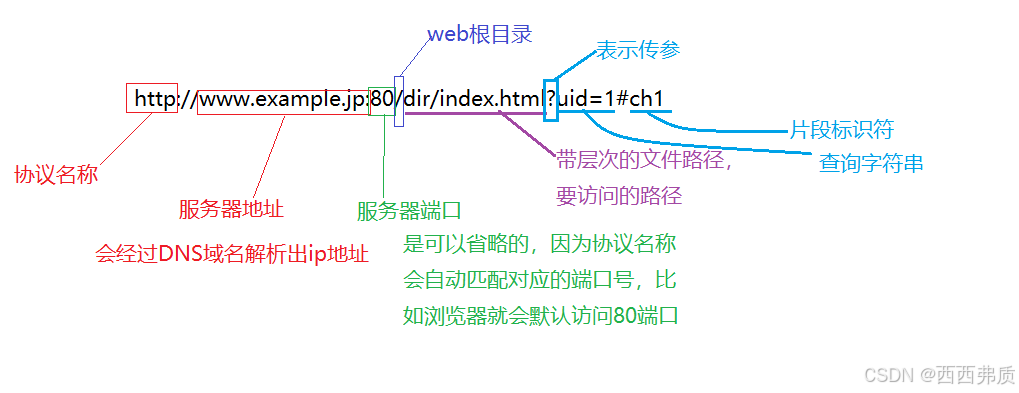
url就是访问浏览器时的网址
2.2 urlencode和urldecode
像 / ? :等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现。比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义
例子:我们在访问浏览器时输入/?后,url会是这样

/? 被转为了 %2F%3F,urldecode就是urlencode的逆过程
三,http协议
虽然应用层协议是我们程序猿自己定的,但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议)就是其中之一
3.1 http报文格式
http是以行为单位的,首先,http底层用的是tcp,所以无论http协议有多少行,在tcp看来http请求都是一行字符串,http中的换行只是/r/n,http反序列化时将/r/n再打散为多行即可。
http请求报文格式
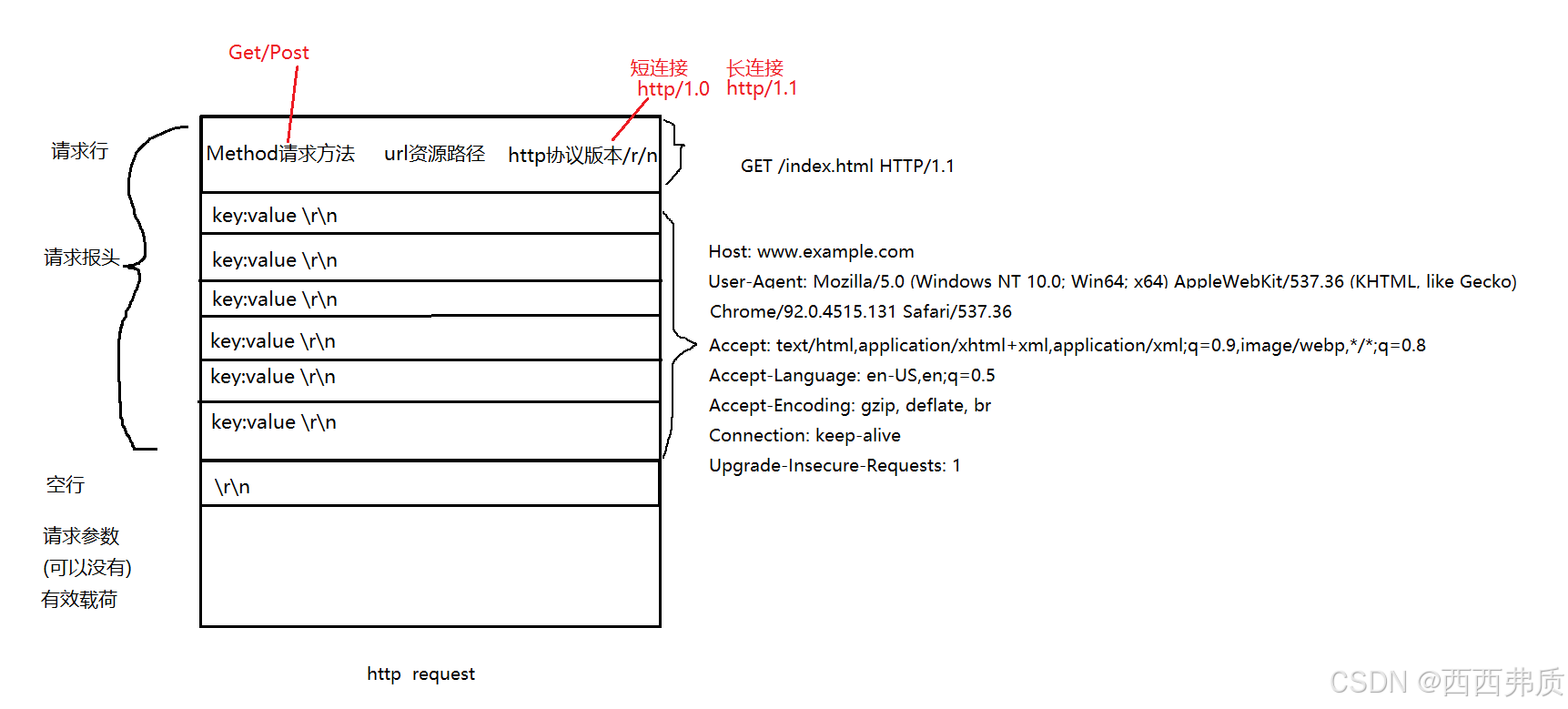
如何一个协议都要解决下面几个问题,我们来看http是如何解决的:
1.http如何保证读到的是一个完整报文?
可以保证的是能够读完请求报头
- 一直读取直到读到空行
- 请求报头中,Content-length表明正文的长度,有正文就读取
2.http如何反序列化?
根据/r/n进行反序列化
3.报头和有效载荷如何分离?
用空行进行分离
http响应报文格式
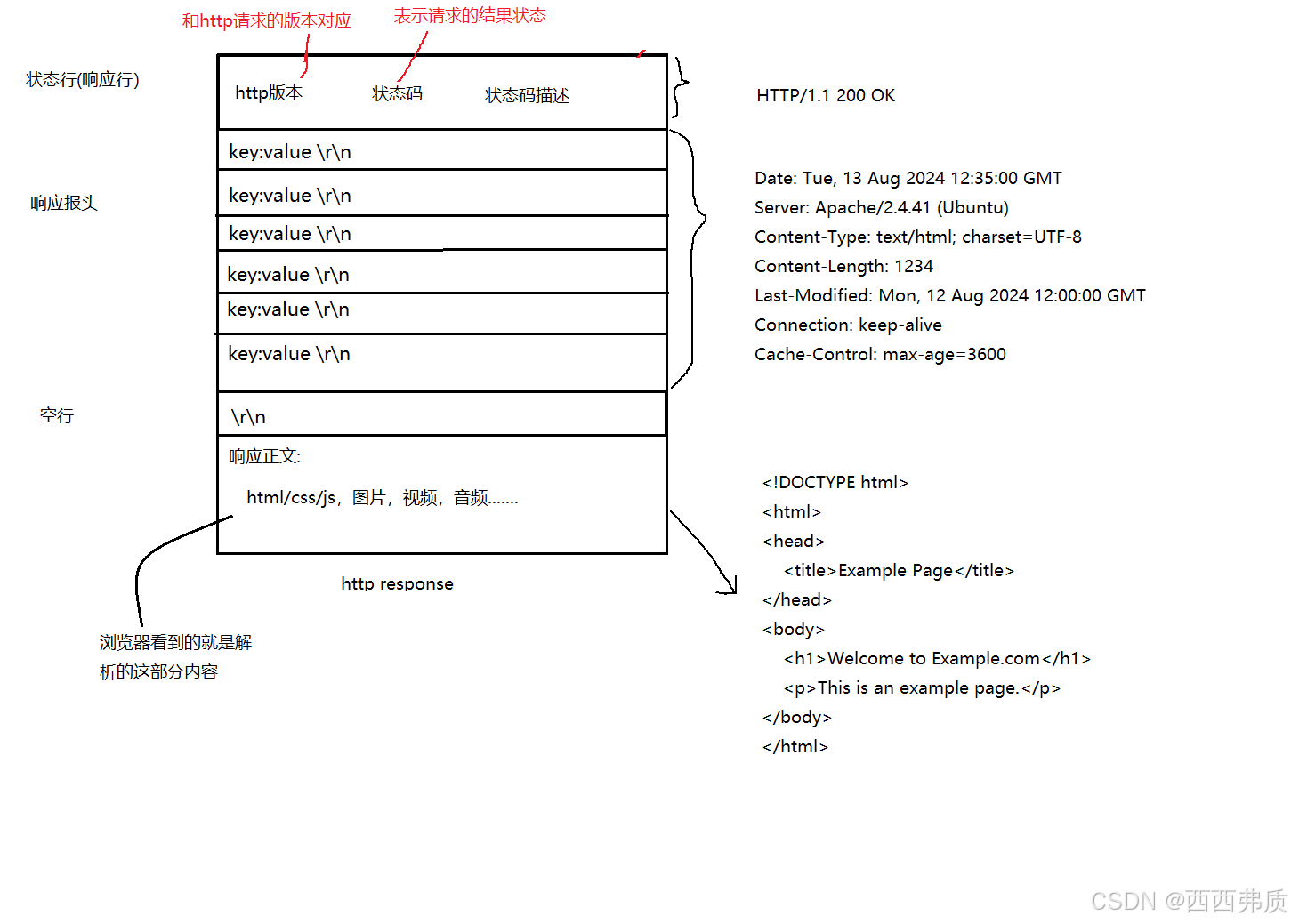
为什么请求和响应都要有http版本?
是为了双方交换版本信息,请求中的版本表示浏览器支持的版本,响应中的版本表示server支持的版本
注:我们可以使用一些抓包工具:fiddler或者telnet,来抓取http请求来看看请求和响应的内容
web根目录
-
当我们在访问一个网址时,没有输入指定的资源路径,而是直接访问
/,web根目录时,其实我们默认访问的是该网站的首页,一般是index.html,所以服务器会将/转换为/index.html -
其次,我们将要被访问的资源存放在web根目录下,访问时通过url中添加请求资源的路径来获取资源:
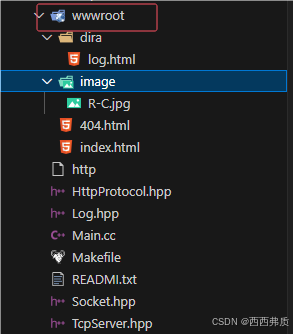
这个wwwroot其实就是web根目录
Content-Type
- 我们通过http请求的资源其实都是文件,那么资源就都有后缀,后缀决定了文件的类型
- http给浏览器响应的时候,响应正文是什么内容可以根据资源文件后缀来判断出来
- http可以支持任意内容的发送,根据响应的content-type来准确解析内容
我们在用http进行访问资源时,如果我们的网页中有图片等资源,那么我们在访问这个页面时可能会发起多个http请求
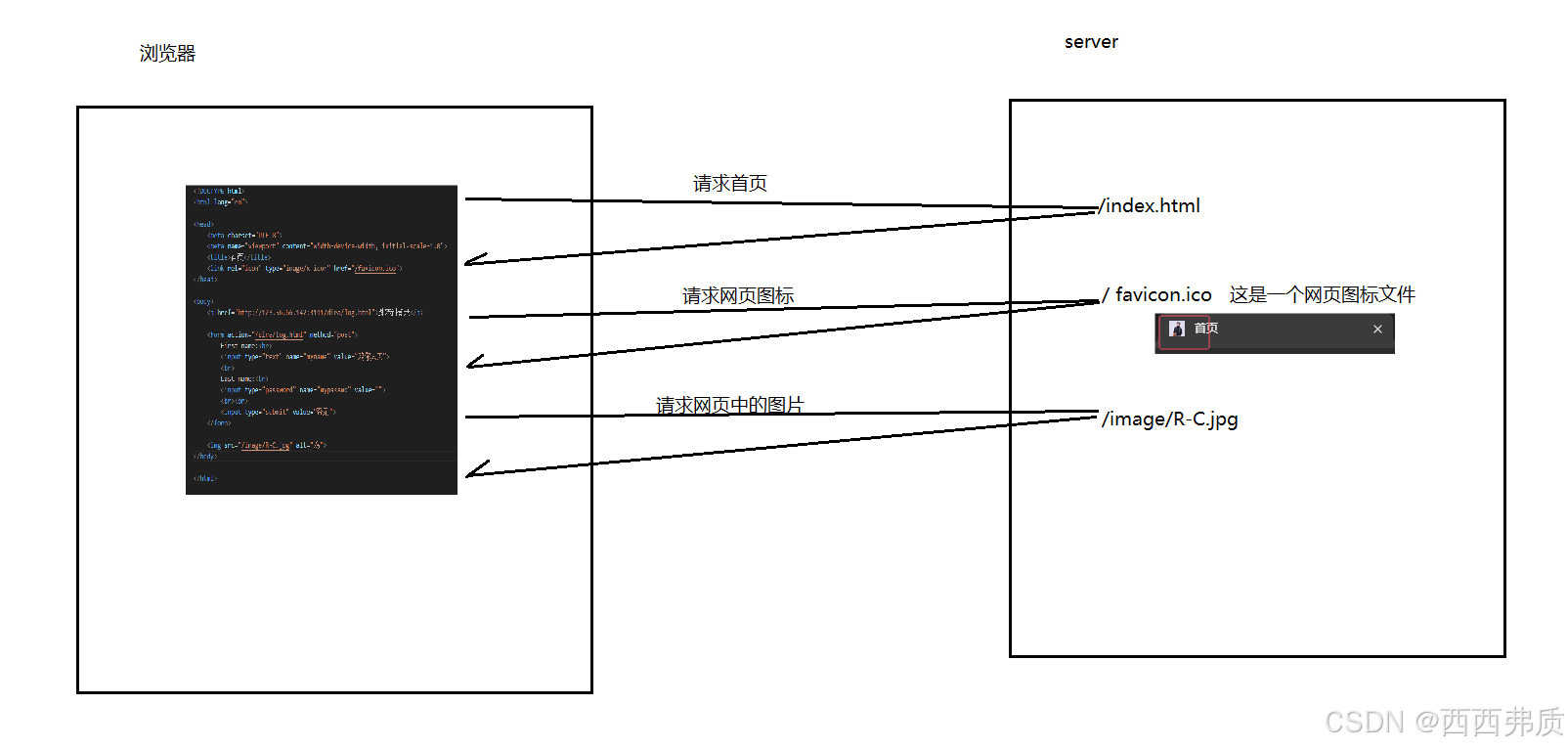
3.2 post和get
我们的上网行为有两种:
- 获取资源
- 向服务器传参,比如登录,注册,搜索
那么上传有两种方法:Get和Post
同时结合表单来进行上传,表单默认是Get方法:
<form action="/dira/log.html" method="post">First name:<br><input type="text" name="myname" value="鸡你太美"><br>Last name:<br><input type="password" name="mypasswd" value=""><br><br><input type="submit" value="登录">
</form>

点击登录后,我们填的字段就会上传给服务器,不一样的是如果是Get方法,那么我们填的字段会显示在请求url后面,如果是Post方法,填写的字段在请求正文中,不会显示在url中
http的请求方法有以下:
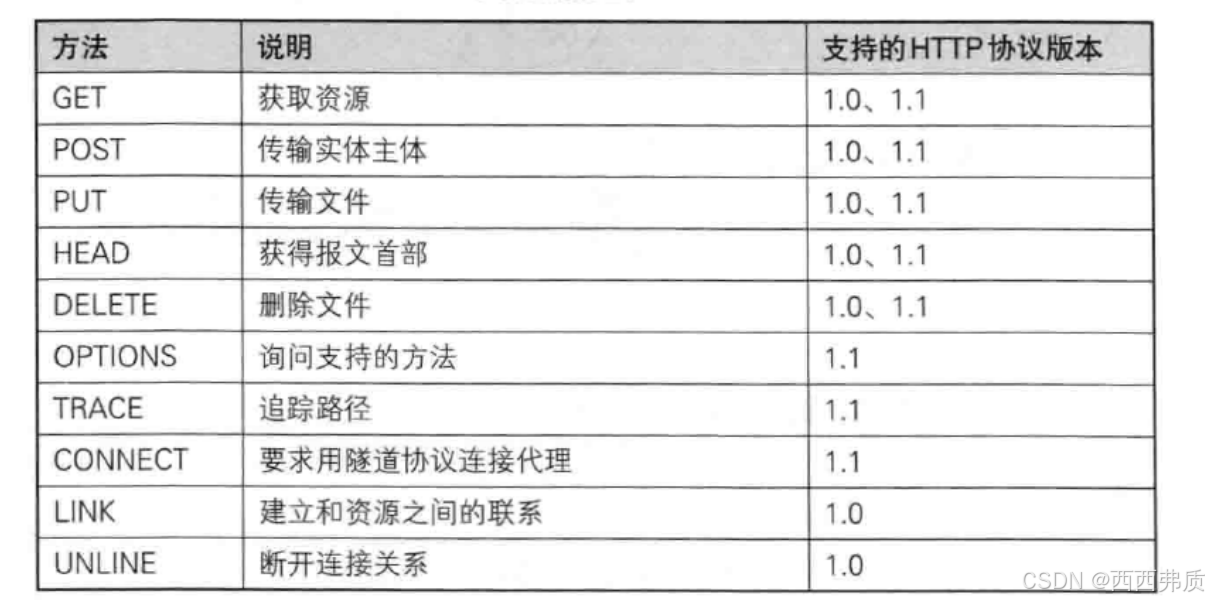
用的最多的就是Get和Post:
- Get:通常用来获取资源,也可以上传数据,提交的参数会加在浏览器的url后面,字节个数有限制
- Post:上传数据,请求参数会加在请求报文的正文部分
3.3 状态码
状态码是HTTP 协议的一部分,
状态码用于表示请求的结果,当客户端(通常是浏览器)向服务器发送一个 HTTP 请求时,服务器会返回一个 HTTP 响应,其中包含一个状态码来表明请求的结果。状态码是一个三位数字的代码,分为五个类别,每个类别都以不同的数字开头
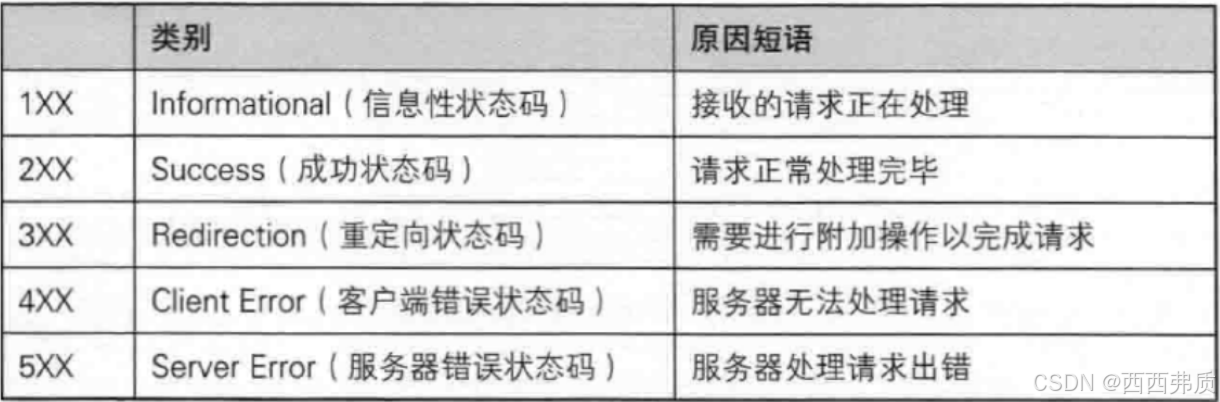
-
4开头表示客户端发起的请求有问题,服务器无法解析
-
3开头表示请求还要进一步操作才可以完成,也就是将这个网页重定向到其他网页
例如:307临时重定向
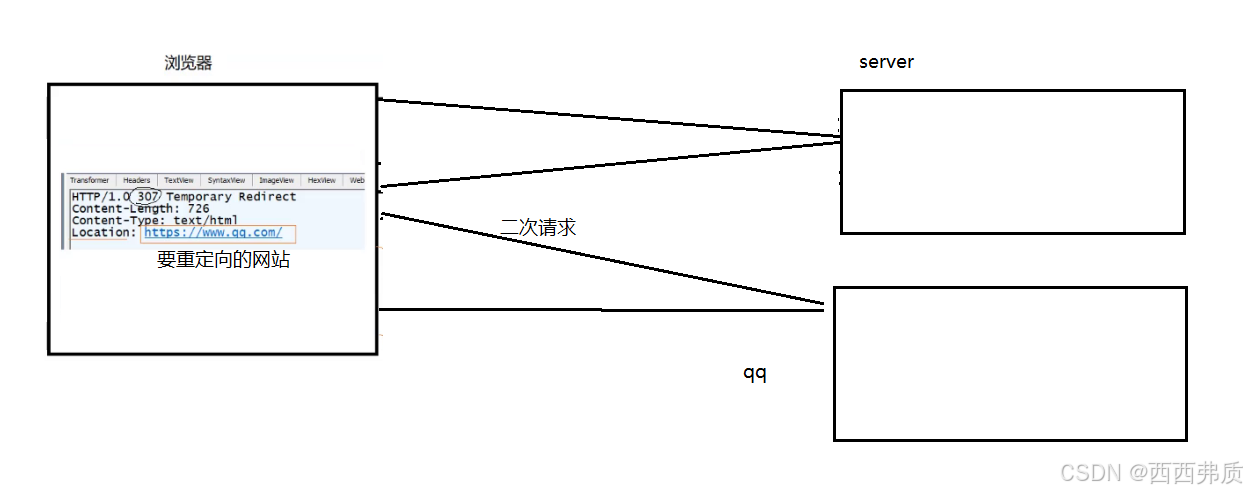
重定向可以让用户跳转到目标网页301永久重定向
用于搜索引擎更新网址的信息
3.4 cookie和session
我们要知道,http是
- 无连接的,虽然底层tcp是有连接的
- 无状态的,浏览器不会记录是否已经访问过哪个资源
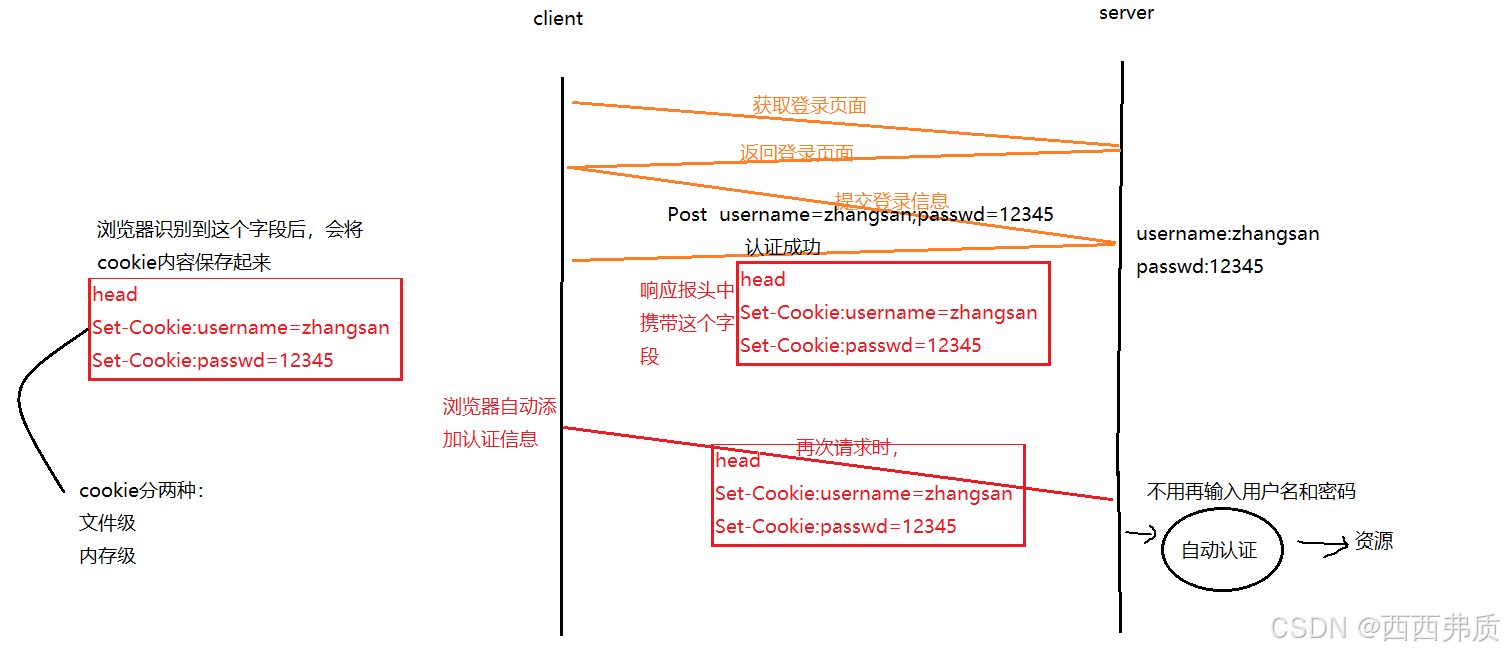
当用户登录某个网站时,浏览器会记录下曾经登录的信息,这些信息保存在请求报头的 cookie 中,当再次访问网站时,会自动认证登录。
cookie分为
- 文件级:关闭浏览器后再次打开,登录信息还在
- 内存级:关闭后再打开,登录信息不在
cookie的信息都保存在客户端,当用户的cookie信息被抓包后会有泄漏的风险
所以当用户第一次登录时,用户的登录信息会在服务端session保存一份,形成唯一的sessionid,发送给客户端
当客户端再次登录时,会向服务器提交sessionid,再在服务端确认得到登录信息
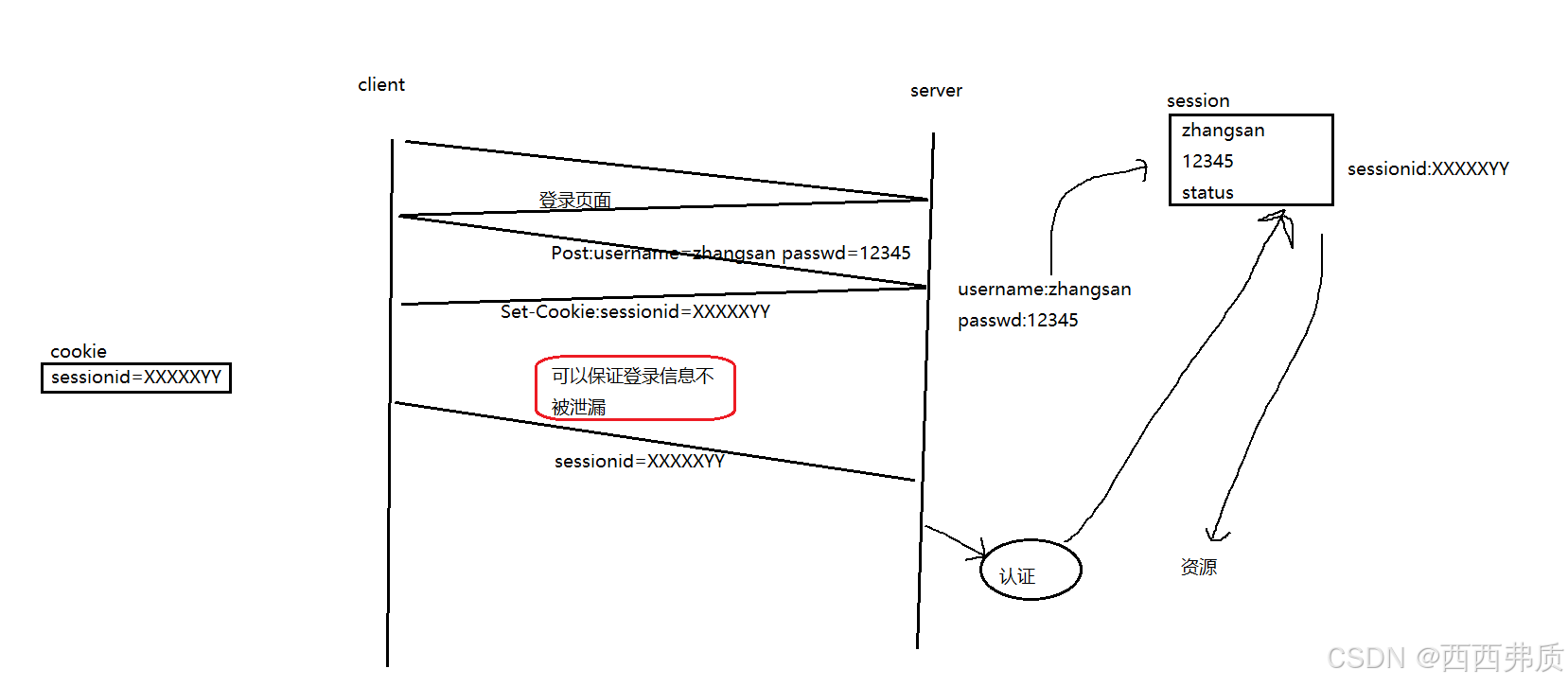
但是这样虽然防止了登录信息不会泄漏,但是还是有抓包后,别人登录我们账号的可能。
我们可以在服务端设置安全策略,比如:检测ip地址,设置sessionid的有效时长等来保护
3.5 常见header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
四,总结
http作为应用层的一个重要的协议,还是要深刻理解,因为很多协议也是在http基础上改造来的,下面是我写的简单的http服务器例子,大家可以看一下:
简单http服务器