【目标检测】RT-DETR
DETRs Beat YOLOs on Real-time Object Detection
DETR在实时目标检测任务中超越YOLO
CVPR 2024

代码地址
论文地址
0.论文摘要
YOLO系列因其在速度与精度间的均衡权衡,已成为实时目标检测领域最受欢迎的框架。然而我们观察到,非极大值抑制(NMS)会对YOLO的速度和精度产生负面影响。近年来,基于Transformer的端到端检测器(DETR)为消除NMS提供了替代方案,但其高昂计算成本制约了实用性,使其难以充分发挥去除NMS的优势。本文提出实时检测变换器(RT-DETR),据我们所知,这是首个解决上述困境的实时端到端目标检测器。我们分两步构建RT-DETR:首先在保证精度前提下提升速度,继而在保持速度基础上优化精度。具体而言,我们设计了高效混合编码器,通过解耦尺度内交互与跨尺度融合来快速处理多尺度特征;进而提出不确定性最小化查询选择机制,为解码器提供高质量初始查询以提升精度。此外,RT-DETR支持通过调整解码器层数实现灵活调速,无需重新训练即可适应不同场景。我们的RT-DETR-R50/R101在COCO数据集上达到53.1%/54.3% AP,在T4 GPU上实现108/74 FPS,速度与精度均超越现有先进YOLO模型。RT-DETR-R50较DINO-R50精度提升2.2% AP,帧率提高约21倍。经过Objects365预训练后,RT-DETR-R50/R101可达到55.3%/56.2% AP。
1.引言
实时目标检测是重要的研究领域,具有广泛的应用场景,如目标跟踪[40]、视频监控[26]和自动驾驶[2]等。现有实时检测器通常采用基于CNN的架构,其中最著名的是YOLO系列检测器[1, 9–11, 14, 15, 24, 28, 35, 37],因其在速度与精度之间实现合理权衡。然而,这些检测器通常需要非极大值抑制(NMS)进行后处理,这不仅会降低推理速度,还会引入超参数,导致速度和精度均不稳定。此外,考虑到不同场景对召回率和精度的侧重不同,需谨慎选择适当的NMS阈值,这阻碍了实时检测器的发展。
最近,基于Transformer的端到端检测器(DETRs)[4, 16, 22, 25, 33, 36, 41, 42]因其简洁的架构和无需手工设计组件的特性受到学术界广泛关注。然而,其高昂的计算成本使其无法满足实时检测需求,因此这种无需非极大值抑制(NMS)的架构并未展现出推理速度优势。这促使我们探索:能否将DETRs拓展至实时场景,在速度和精度上均超越先进的YOLO检测器,从而消除NMS造成的延迟以实现实时目标检测。
为实现上述目标,我们重新审视了DETR模型,并对关键组件进行详细分析以减少计算冗余并进一步提升精度。对于前者,我们观察到尽管引入多尺度特征有助于加速训练收敛[42],但会导致输入编码器的序列长度显著增加。多尺度特征交互产生的高计算成本使得Transformer编码器成为计算瓶颈。因此,实现实时DETR需要重新设计编码器架构。对于后者,先前研究[39,41,42]表明难以优化的对象查询阻碍了DETR性能,并提出用编码器特征替换原始可学习嵌入的查询选择方案。然而我们发现当前查询选择直接采用分类分数进行筛选,忽略了检测器需要同时建模目标类别与位置(二者共同决定特征质量)的事实。这不可避免地导致部分定位置信度较低的编码器特征被选为初始查询,从而引入显著的不确定性并损害DETR性能。我们将查询初始化视为实现性能突破的关键路径。
本文提出实时检测变换器(RT-DETR),据我们所知是首个实时端到端目标检测器。为高效处理多尺度特征,我们设计了一种高效混合编码器以替代原始Transformer编码器,通过解耦不同尺度特征的尺度内交互与跨尺度融合,显著提升推理速度。为避免定位置信度低的编码器特征被选作目标查询,我们提出不确定性最小化查询选择机制,通过显式优化不确定性为解码器提供高质量初始查询,从而提升检测精度。此外,得益于DETR的多层解码器架构,RT-DETR支持无需重新训练即可灵活调节速度,以适应多样化实时场景需求。
RT-DETR在速度与精度之间实现了理想的平衡。具体而言,RT-DETR-R50在COCO val2017数据集上达到53.1% AP,在T4 GPU上实现108 FPS;RT-DETR-R101则达到54.3% AP和74 FPS,其速度与精度均超越先前先进的YOLO检测器L和X型号(图1)。我们还通过采用更小骨干网络缩放编码器-解码器结构,开发了多尺度RT-DETR变体,其性能优于轻量级YOLO检测器(S和M型号)。此外,RT-DETR-R50以53.1% AP优于DINO-Deformable-DETR-R50的50.9% AP(提升2.2%),并以108 FPS远超后者的5 FPS(提速约21倍),显著提升了DETR系列模型的精度与速度。经过Objects365数据集[32]预训练后,RT-DETR-R50/R101分别达到55.3%/56.2% AP,展现出显著性能提升。更多实验结果详见附录。
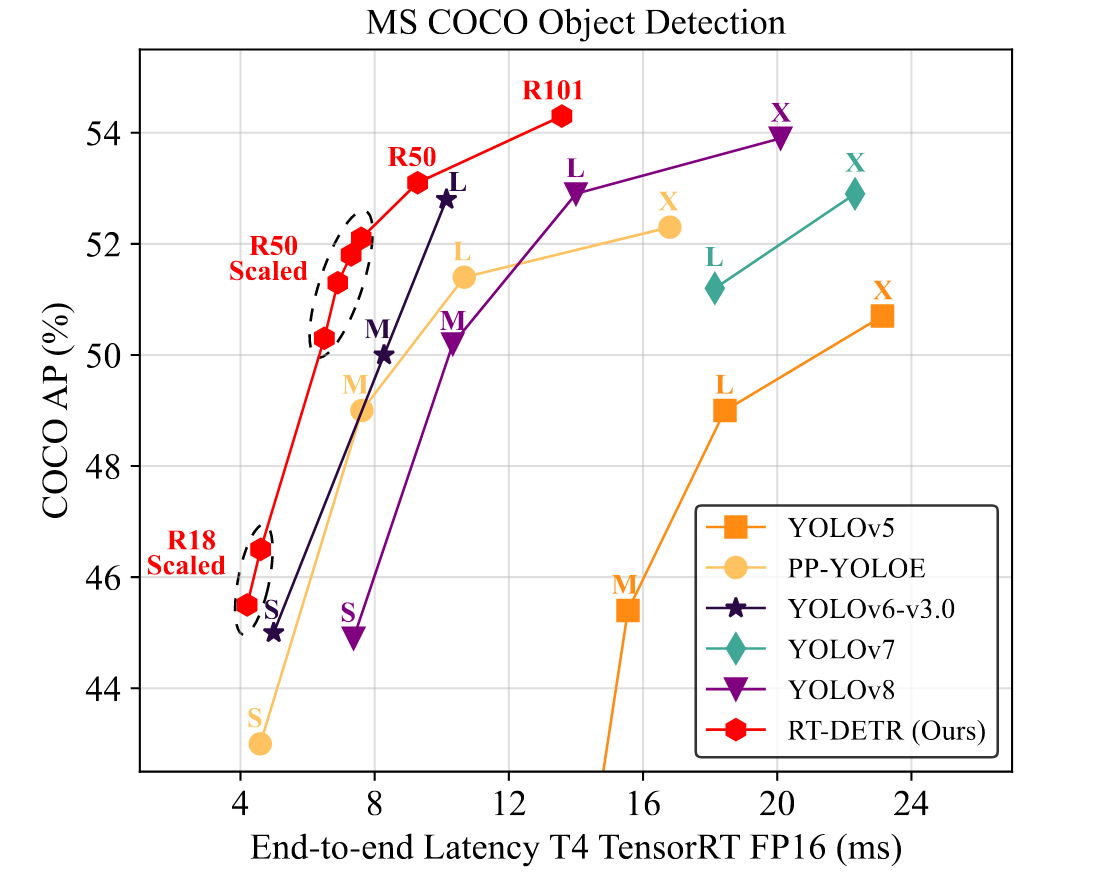
主要贡献总结如下:(i). 我们提出了首个实时端到端目标检测器RTDETR,其不仅在速度与精度上超越了先前先进的YOLO检测器,同时消除了NMS后处理对实时目标检测造成的负面影响;(ii). 我们定量分析了NMS对YOLO检测器速度与精度的影响,并建立了端到端速度基准以测试实时检测器的端到端推理速度;(iii). 所提出的RT-DETR支持通过调整解码器层数进行灵活速度调节,无需重新训练即可适应不同场景。
2.相关工作
2.1. 实时目标检测器
YOLOv1[29]是首个基于卷积神经网络(CNN)的单阶段目标检测器,实现了真正的实时目标检测。经过多年持续发展,YOLO系列检测器性能已超越其他单阶段检测器[20,23],成为实时目标检测的代名词。当前YOLO检测器可分为两类:基于锚框的[1,10,14,24,27,28,34,35]与无锚框的[9,11,15,37],它们在速度与精度间取得良好平衡,被广泛应用于各类实际场景。这些先进的实时检测器会产生大量重叠检测框,必须依赖非极大值抑制(NMS)后处理,从而导致速度下降。
2.2. 端到端目标检测器
端到端目标检测器以其简洁的流水线而著称。Carion等人[4]首次提出了基于Transformer的端到端检测器DETR,因其独特特性而受到广泛关注。特别地,DETR摒弃了手工设计的锚框和非极大值抑制组件,转而采用二分图匹配并直接预测一对一的目标集合。尽管优势显著,DETR仍存在若干问题:训练收敛速度慢、计算成本高以及查询难以优化。针对这些问题,研究者提出了多种DETR改进方案。
加速收敛:Deformable-DETR[42]通过增强注意力机制效率,利用多尺度特征加速训练收敛;DAB-DETR[22]和DN-DETR[16]则通过引入迭代优化方案和去噪训练进一步提升性能;Group-DETR[5]提出了分组式一对多分配策略。
降低计算成本:Efficient DETR[39]和Sparse DETR[31]通过减少编码器/解码器层数或更新查询数量来降低计算开销;Lite DETR[17]采用交错更新方式降低底层特征更新频率,从而提升编码器效率。
优化初始查询:条件DETR[25]和Anchor DETR[36]降低了查询的优化难度。Zhu等人[42]提出了两阶段DETR的查询选择方法,DINO[41]则采用混合查询选择以更好地初始化查询。现有DETR模型仍存在计算量大的问题,且未针对实时检测进行设计。我们的RT-DETR深入探索了计算成本优化方案,并着力改进查询初始化机制,其性能超越了当前最先进的实时检测器。
3.检测器的端到端速度
3.1. NMS分析
非极大值抑制(NMS)是目标检测中广泛使用的后处理算法,用于消除重叠的输出框。该算法需要设置两个阈值:置信度阈值与交并比阈值。具体而言,系统会直接滤除低于置信度阈值的预测框,当任意两个预测框的交并比超过设定阈值时,则丢弃其中得分较低的框。该过程会迭代执行,直至所有类别的预测框均处理完毕。因此NMS算法的执行时间主要取决于预测框数量与两个阈值设置。为验证该结论,我们采用基于锚框的YOLOv5[10]与无锚框的YOLOv8[11]进行对比分析。
我们首先统计在同一输入上以不同置信度阈值过滤输出框后剩余的框数量。从0.001到0.25采样置信度阈值以统计两种检测器的剩余框数量,并将其绘制在柱状图上(图2),直观反映出NMS对其超参数的敏感性。随着置信度阈值增大,更多预测框被过滤,需要计算IoU的剩余框数量减少,从而降低NMS的执行时间。
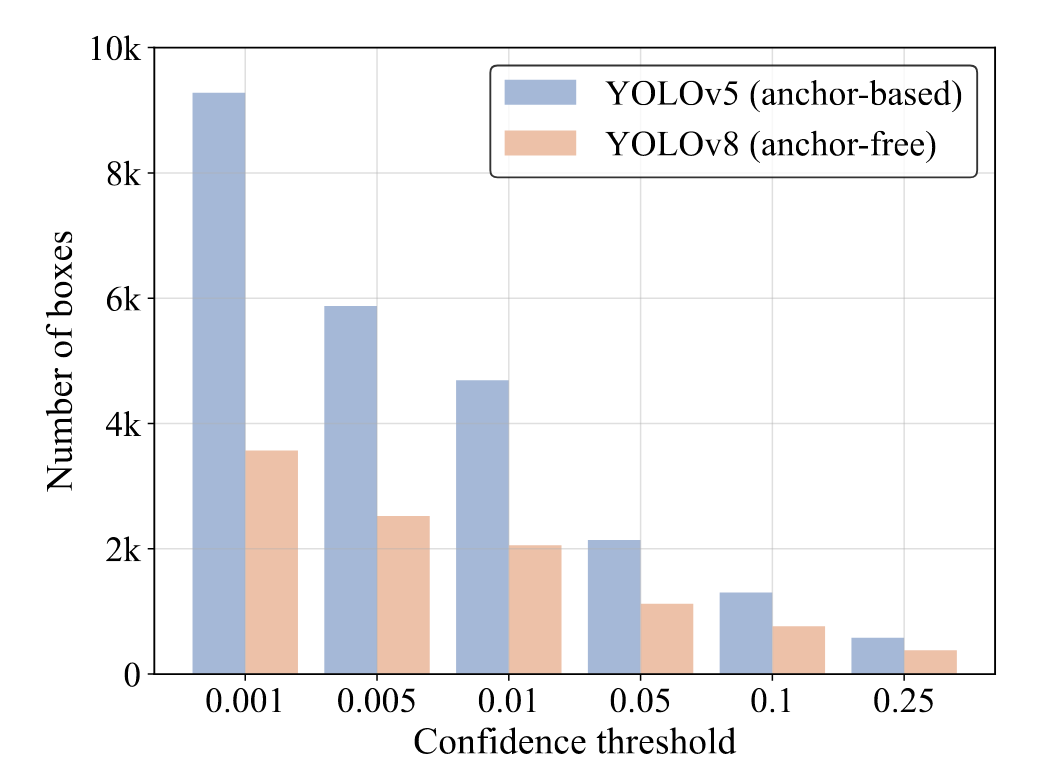
图2. 不同置信度阈值下的检测框数量。
此外,我们采用YOLOv8评估模型在COCO val2017数据集上的精度,并测试其在不同超参数下的NMS执行耗时运算性能分析。需说明的是,本文采用的NMS运算基于TensorRT的efficientNMSPlugin实现,该模块包含EfficientNMSFilter、RadixSort、EfficientNMS等多个内核,本文仅统计EfficientNMS内核的执行耗时。测试在T4 GPU上采用TensorRT FP16精度进行,输入数据与预处理流程保持恒定。具体超参数设置及对应实验结果如表1所示。实验结果表明:当置信度阈值降低或IoU阈值升高时,EfficientNMS内核的执行时间会相应增加。这是因为高置信度阈值会直接过滤更多预测框,而高IoU阈值则会导致每轮筛选保留更多预测框。我们在附录中可视化了YOLOv8模型采用不同NMS阈值的检测效果,结果显示不合理的置信度阈值会导致检测器出现大量误检或漏检。当置信度阈值为0.001、IoU阈值为0.7时,YOLOv8获得最佳AP性能,但相应的NMS耗时处于较高水平。考虑到YOLO系列检测器通常报告模型推理速度时不计入NMS耗时,因此有必要建立端到端的完整速度基准。
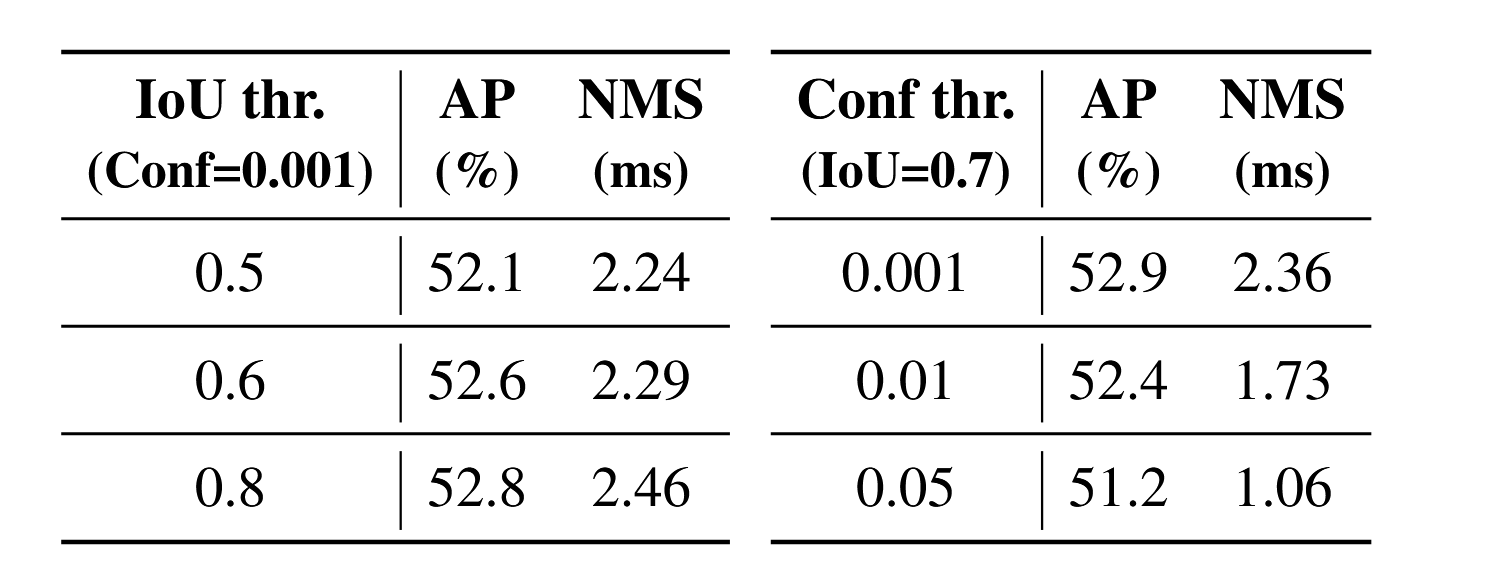
表1. IoU阈值与置信度阈值对准确率和NMS执行时间的影响。
3.2. 端到端速度基准测试
为公平比较各类实时检测器的端到端速度,我们建立了端到端速度基准测试。鉴于非极大值抑制(NMS)的执行时间受输入数据影响,需选定基准数据集并计算多幅图像的平均执行时间。我们选用COCO val2017[19]作为基准数据集,并为YOLO系列检测器附加前述TensorRT的NMS后处理插件。具体而言,根据基准数据集对应精度所采用的NMS阈值测试检测器的平均推理时间(不含I/O与内存拷贝操作)。通过该基准测试,我们评估了基于锚框的检测器YOLOv5[10]和YOLOv7[35],以及无锚框检测器PP-YOLOE[37]、YOLOv6[15]和YOLOv8[11]的在T4 GPU上使用TensorRT FP16运行端到端速度。根据结果(参见表2),我们得出结论:对于YOLO检测器而言,在精度相当的情况下,无锚检测器性能优于基于锚的检测器,因为前者所需非极大值抑制时间更少。这是由于基于锚的检测器产生的预测框数量多于无锚检测器(在我们测试的检测器中多出三倍)。
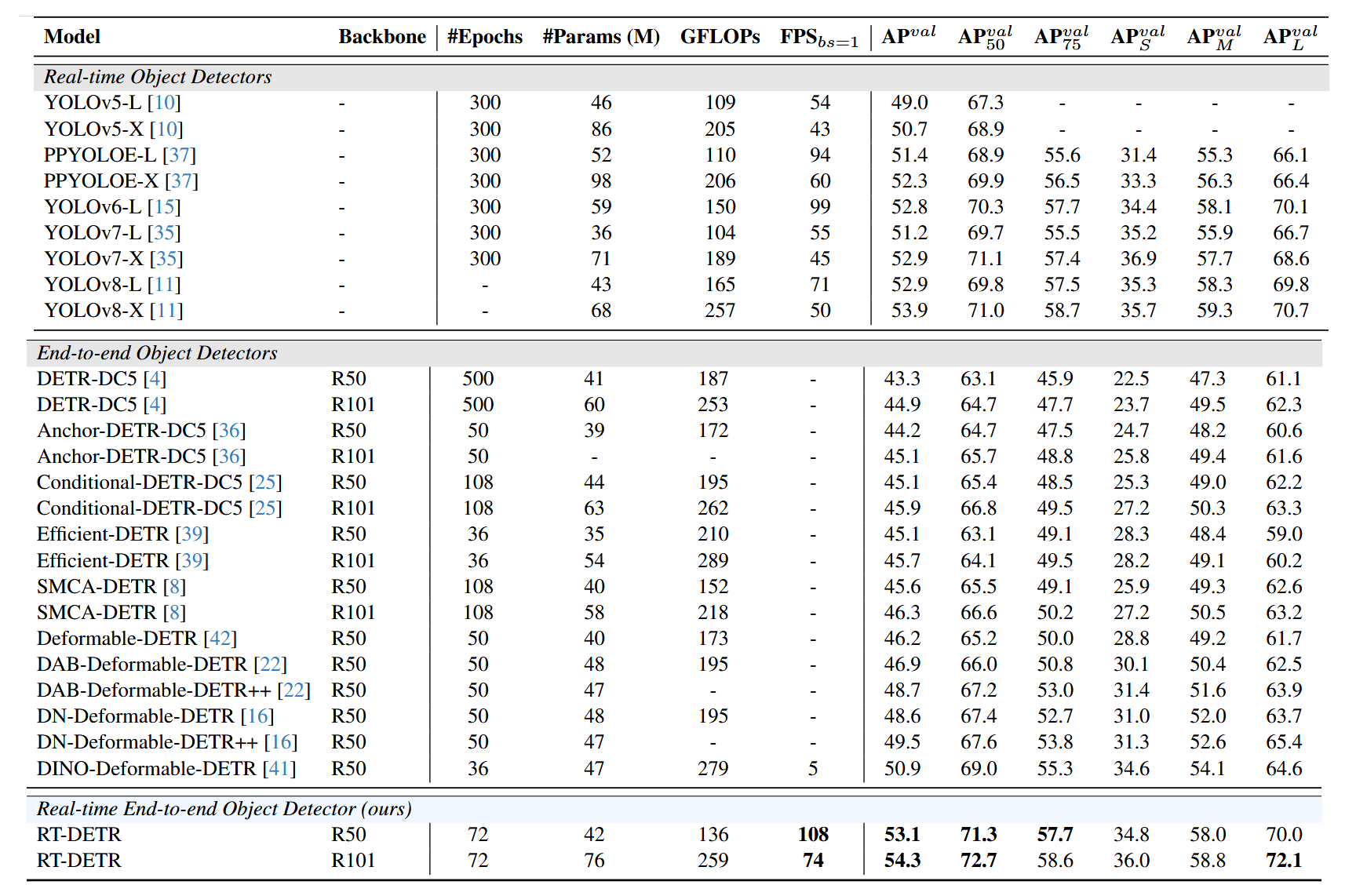
表2. 与SOTA的对比(仅包含YOLO检测器的L和X模型,与S和M模型的对比参见附录)。除DINO-Deformable-DETR[41]用于对比外,我们未测试其他DETR的速度,因其均非实时检测器。我们的RT-DETR在速度和精度上均优于最先进的YOLO检测器及DETR系列方法。
4.实时DETR
4.1 模型概述
RT-DETR由主干网络、高效混合编码器和带有辅助预测头的Transformer解码器构成,其整体架构如图4所示。具体而言,我们将主干网络最后三个阶段{S3, S4, S5}的特征输入编码器。该高效混合编码器通过尺度内特征交互与跨尺度特征融合(参见第4.2节),将多尺度特征转换为图像特征序列。随后采用不确定性最小化查询选择机制,筛选固定数量的编码器特征作为解码器的初始目标查询(参见第4.3节)。最终,带有辅助预测头的解码器通过迭代优化目标查询来生成类别与边界框。
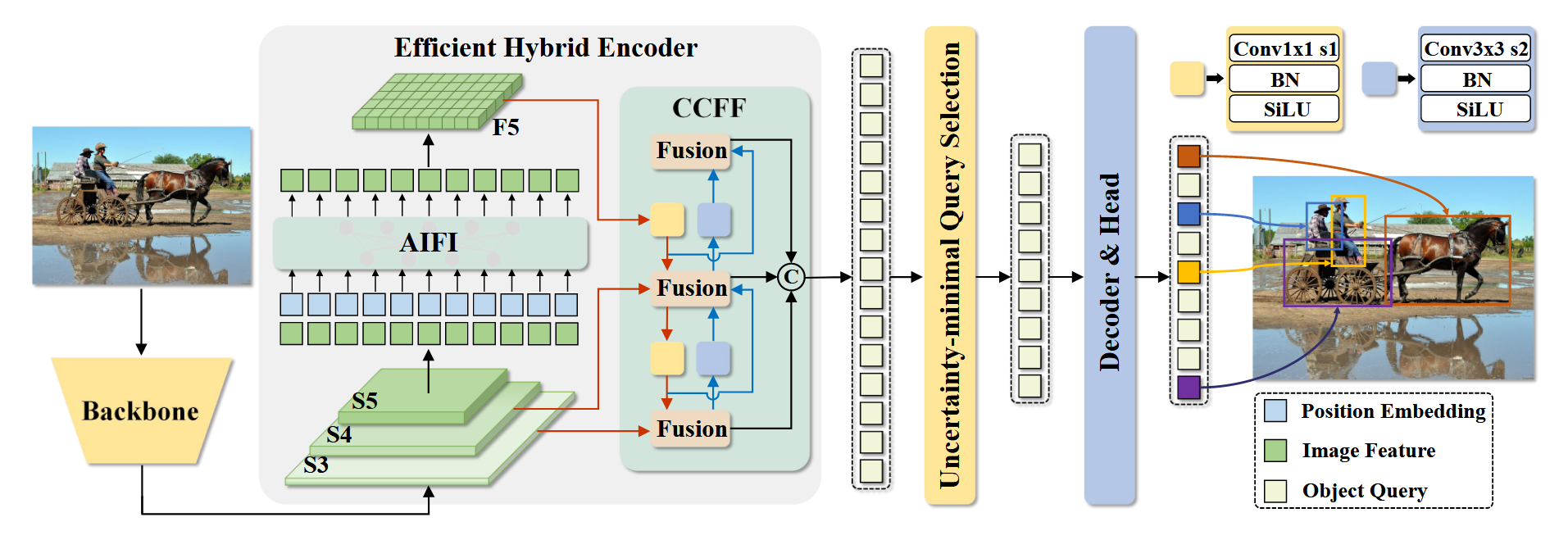
图4. RT-DETR整体架构。我们将主干网络最后三个阶段的特征输入编码器,高效混合编码器通过基于注意力的同尺度特征交互模块(AIFI)和基于CNN的跨尺度特征融合模块(CCFF)将多尺度特征转化为图像特征序列。随后,不确定性最小化查询选择机制选取固定数量的编码器特征作为解码器的初始对象查询。最终,带有辅助预测头的解码器通过迭代优化对象查询来生成类别与边界框。
4.2 高效混合编码器
计算瓶颈分析
多尺度特征的引入加速了训练收敛并提升性能[42]。然而尽管可变形注意力机制降低了计算成本,序列长度的急剧增加仍使编码器成为计算瓶颈。如Lin等人[18]所述,在Deformable-DETR中编码器消耗49%的GFLOPs却仅贡献11%的AP指标。为突破此瓶颈,我们首先分析了多尺度Transformer编码器中存在的计算冗余:直观而言,包含丰富物体语义信息的高层特征是从低层特征提取而来,这使得在拼接后的多尺度特征上执行特征交互存在冗余。因此我们设计了一组采用不同编码器类型的变体模型(图3),证明同时进行尺度内与跨尺度特征交互是低效的。具体而言,实验采用配备RT-DETR小型数据读取器和轻量解码器的DINO-Deformable-R50模型,首先生成去除多尺度Transformer编码器的变体A;随后基于A插入不同类型的编码器得到系列变体(各变体详细指标见表3):
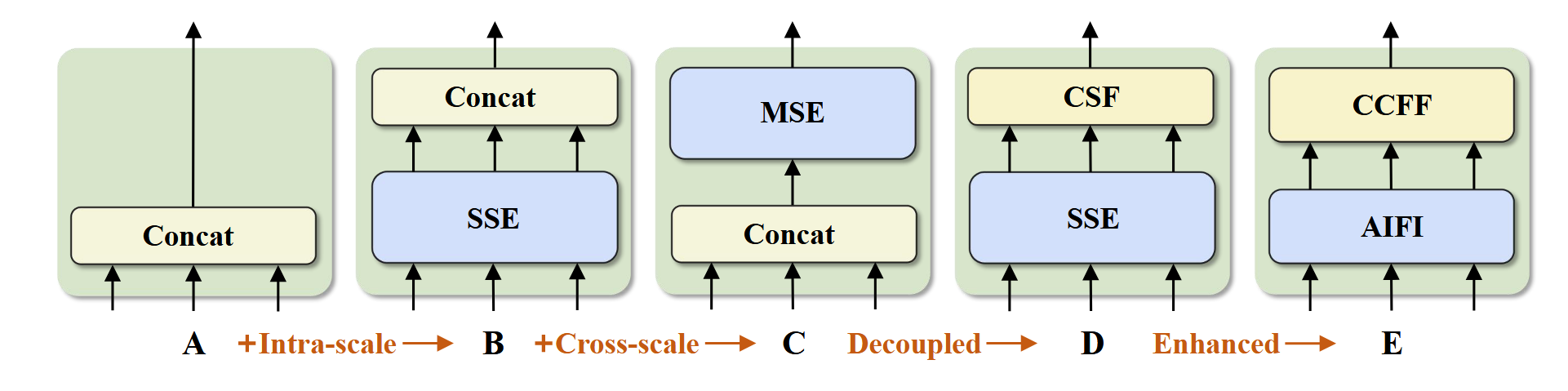
图3. 各变体的编码器结构。SSE表示单尺度Transformer编码器,MSE表示多尺度Transformer编码器,CSF代表跨尺度融合。AIFI与CCFF是我们设计的混合编码器中的两个模块。
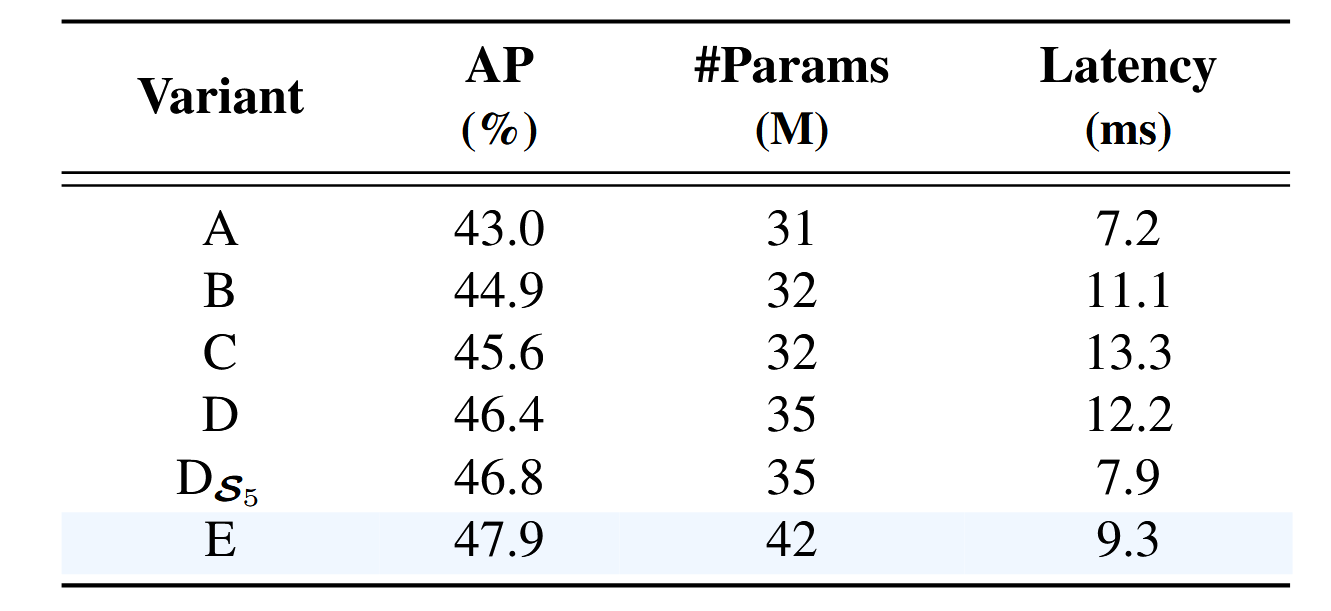
表3. 图3所示各变体组的指标。
• A → B:变体B在A中插入了一个单尺度Transformer编码器,该编码器使用单层Transformer模块。多尺度特征共享该编码器进行尺度内特征交互,随后拼接输出。
• B → C:变体C在B的基础上引入跨尺度特征融合,将拼接后的特征输入多尺度Transformer编码器,实现尺度内与跨尺度的同步特征交互。
• C → D:变体D将尺度内交互与跨尺度融合解耦:前者采用单尺度Transformer编码器,后者通过PANet式[21]结构实现。
• D → E:变体E在D的基础上强化了尺度内交互与跨尺度融合,采用我们设计的高效混合编码器。
混合设计
基于上述分析,我们重新审视了编码器结构并提出一种高效混合编码器,该架构由两个模块组成:基于注意力的同尺度特征交互模块(AIFI)与基于CNN的跨尺度特征融合模块(CCFF)。具体而言,AIFI在变体D基础上进一步降低计算成本——仅对S5层级采用单尺度Transformer编码器进行同尺度交互。其原理在于:对具有更丰富语义概念的高层特征实施自注意力操作,能够捕捉概念实体间的关联,从而有利于后续模块对目标的定位与识别。而低层特征的同尺度交互由于缺乏语义概念,且存在与高层特征交互重复混淆的风险,实无必要。为验证该观点,我们在变体D中仅对S5进行同尺度交互,实验结果如表3所示(参见DS5行)。相较于D、DS5不仅显著降低了延迟(提速35%),还提高了准确率(AP提升0.4%)。CCFF基于跨尺度融合模块进行优化,该模块在融合路径中插入了若干由卷积层构成的融合块。融合块的作用是将相邻两个尺度的特征融合为新特征,其结构如图5所示:包含两个1×1卷积用于调整通道数,采用N个由RepConv[7]构成的RepBlock进行特征融合,并通过逐元素相加实现双路径输出融合。混合编码器的计算公式为:
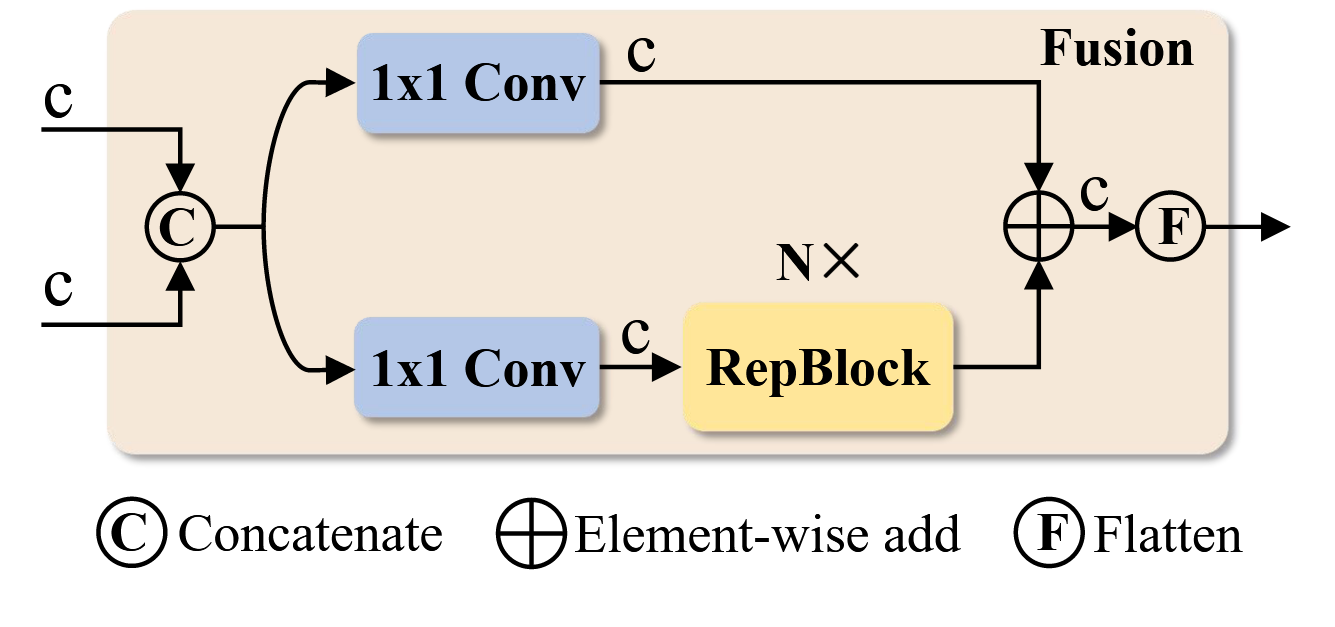
图5. CCFF中的融合模块
Q = K = V = F l a t t e n ( S 5 ) , F 5 = R e s h a p e ( A I F I ( Q , K , V ) ) , O = C C F F ( { S 3 , S 4 , F 5 } ) , \begin{aligned}\mathrm{Q}&=\mathcal{K}=\mathcal{V}=\mathrm{Flatten}(\mathcal{S}_5),\\\mathcal{F}_{5}&=\mathrm{Reshape}(\mathrm{AIFI}(\mathcal{Q},\mathcal{K},\mathcal{V})),\\\mathrm{O}&=\mathrm{CCFF}(\{\boldsymbol{S}_3,\boldsymbol{S}_4,\mathcal{F}_5\}),\end{aligned} QF5O=K=V=Flatten(S5),=Reshape(AIFI(Q,K,V)),=CCFF({S3,S4,F5}),
其中Reshape表示将展平后的特征恢复至与S5相同的形状。
4.3. 不确定性最小化查询选择
为降低DETR中目标查询的优化难度,后续研究[39,41,42]提出了多种查询选择方案,其共同点在于利用置信度分数从编码器中选取前K个特征来初始化目标查询(或仅初始化位置查询)。
置信度分数表示该特征包含前景物体的可能性。然而,检测器需要同时对物体的类别和位置进行建模,这两者共同决定了特征的质量。因此,特征的表现分数是一个与分类和定位双重相关的潜在变量。根据分析,当前查询选择机制会导致所选特征存在显著不确定性,从而造成解码器初始化欠佳,进而影响检测器的性能。
为解决这一问题,我们提出不确定性最小化查询选择方案,该方案显式构建并优化认知不确定性以建模编码器特征的联合潜变量,从而为解码器提供高质量查询。具体而言,特征不确定性U定义为式(2)中定位P与分类C预测分布间的差异。为最小化查询不确定性,我们将该不确定性整合至式(3)基于梯度的优化损失函数中。
U ( X ^ ) = ∥ P ( X ^ ) − C ( X ^ ) ∥ , X ^ ∈ R D \mathcal{U}(\hat{\mathcal{X}})=\|\mathcal{P}(\hat{\mathcal{X}})-\mathcal{C}(\hat{\mathcal{X}})\|,\hat{\mathcal{X}}\in\mathbb{R}^D U(X^)=∥P(X^)−C(X^)∥,X^∈RD
L ( X ^ , Y ^ , Y ) = L b o x ( b ^ , b ) + L c l s ( U ( X ^ ) , c ^ , c ) \mathcal{L}(\hat{\boldsymbol{X}},\hat{\boldsymbol{Y}},\boldsymbol{Y})=\mathcal{L}_{box}(\hat{\mathbf{b}},\mathbf{b})+\mathcal{L}_{cls}(\mathcal{U}(\hat{\boldsymbol{X}}),\hat{\mathbf{c}},\mathbf{c}) L(X^,Y^,Y)=Lbox(b^,b)+Lcls(U(X^),c^,c)
其中Ŷ和Y分别表示预测值和真实值,Ŷ = {ĉ, b̂},ĉ和b̂分别代表类别和边界框,X̂表示编码器特征。
有效性分析
为分析不确定性最小化查询选择的有效性,我们在COCO val2017数据集上对所选特征的分类得分与交并比得分进行可视化(图6)。我们绘制了分类得分大于0.5的散点图,其中紫色与绿色圆点分别代表采用不确定性最小化查询选择训练的模型与基础查询模型所选特征。图中点越靠近右上角,对应特征的质量越高,即预测类别与边界框越可能描述真实物体。顶部与右侧的密度曲线反映了两种类型点的数量分布。
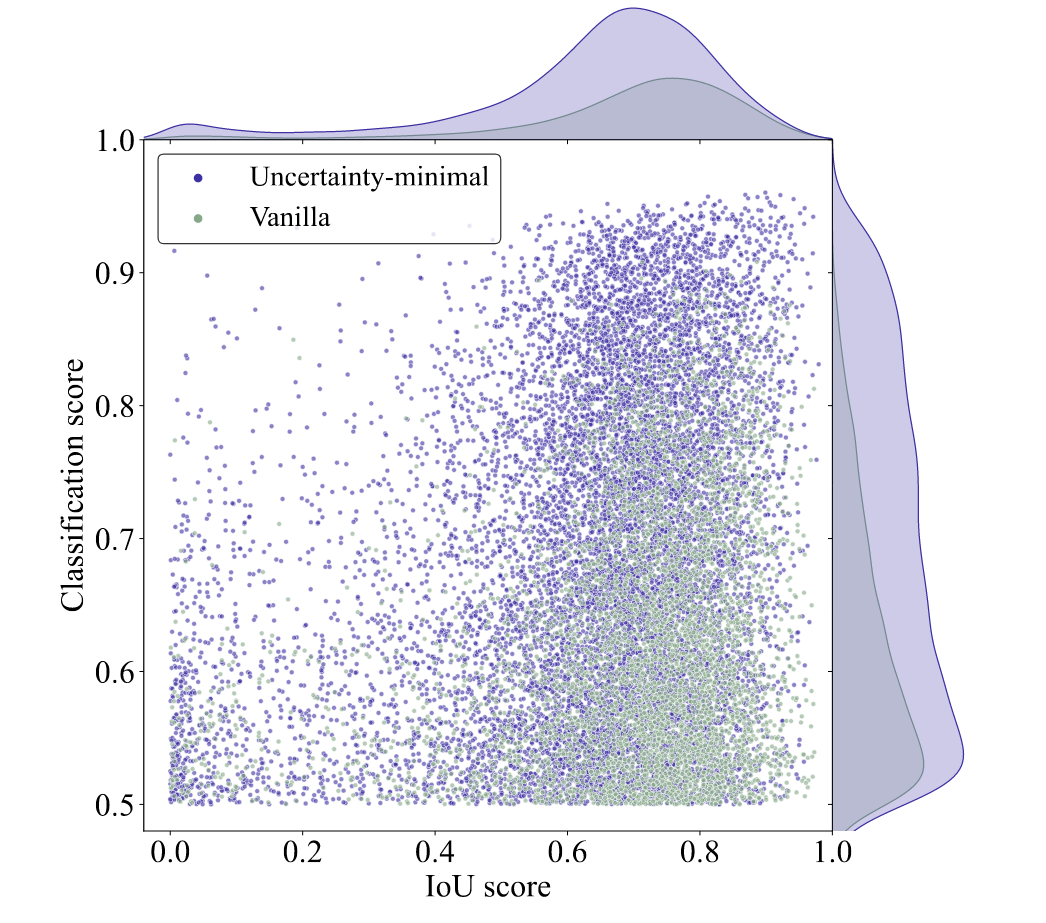
图6. 所选编码器特征的分类与IoU得分。紫色与绿色圆点分别代表采用不确定性最小化查询选择和标准查询选择训练的模型所选特征。
该散点图最显著的特征在于紫色点群集中分布在图形右上区域,而绿色点群则密集分布于右下区域。这表明不确定性最小化查询选择策略能生成更高质量的编码器特征。我们进一步对两种查询选择方案进行定量分析:紫色点数量比绿色点多出138%(即分类分数≤0.5的低质量特征点中绿色点占比更高);而在分类分数与定位分数均>0.5的高质量特征点中,紫色点数量仍比绿色点多出120%。密度曲线同样佐证了这一结论——图形右上区域紫绿两色分布差异最为显著。定量结果进一步表明,不确定性最小化查询选择能为检测器提供更多兼具准确分类与精确定位的查询特征,从而提升检测精度(参见第5.3节)。
4.4. 缩放版RT-DETR
由于实时检测器通常需提供不同尺度的模型以适应不同场景,RT-DETR同样支持灵活缩放。具体而言,在混合编码器中,我们通过调整嵌入维度和通道数量来控制宽度,并通过调整Transformer层数和RepBlocks数量来控制深度。
解码器的宽度和深度可通过调控目标查询数量和解码层数实现灵活控制。此外,RT-DETR的速度支持通过调整解码层数进行弹性调节。实验表明,末端移除少量解码层对精度影响甚微,却能显著提升推理速度(参见第5.4节)。我们将配备ResNet50和ResNet101[12,13]的RT-DETR与YOLO检测器的L、X模型进行对比,通过采用更小规模(如ResNet18/34)或可扩展(如CSPResNet[37])骨干网络,并配合缩放编码器-解码器结构,可设计出更轻量化的RT-DETR变体。附录中对比了缩放版RT-DETR与轻量级(S、M型)YOLO检测器,前者在速度与精度上均超越所有S、M模型。
5.结论
5.1. 与现有最优技术的对比
表2将RT-DETR与当前实时检测器(YOLO系列)和端到端检测器(DETR系列)进行对比,其中仅对比YOLO检测器的L和X模型,S与M模型对比结果见附录。我们的RT-DETR与YOLO检测器采用相同的(640, 640)输入尺寸,其他DETR检测器使用(800, 1333)输入尺寸。FPS数据基于T4 GPU搭配TensorRT FP16测得,YOLO检测器采用官方预训练模型并依据第3.2节提出的端到端速度基准进行测试。RT-DETR-R50实现53.1% AP与108 FPS,RT-DETR-R101实现54.3% AP与74 FPS,在速度与精度上均优于同规模最先进的YOLO检测器及同主干的DETR检测器。具体实验设置详见附录。
与实时检测器的对比
我们对比了RT-DETR与YOLO检测器的端到端速度(参见第3.2节)和准确率。将RT-DETR与YOLOv5[10]、PP-YOLOE[37]、YOLOv6v3.0[15](下文简称YOLOv6)、YOLOv7[35]及YOLOv8[11]进行对比。相较于YOLOv5-L/PP-YOLOE-L/YOLOv6-L,RT-DETR-R50的AP准确率提升4.1%/1.7%/0.3%,FPS提高100.0%/14.9%/9.1%,参数量减少8.7%/19.2%/28.8%。相比YOLOv5-X/PP-YOLOE-X,RT-DETR-R101的AP准确率提升3.6%/2.0%,FPS提高72.1%/23.3%,参数量降低11.6%/22.4%。与YOLOv7-L/YOLOv8-L相比,RT-DETR-R50的AP准确率提升1.9%/0.2%,FPS提高96.4%/52.1%。相较于YOLOv7-X/YOLOv8-X,RT-DETR-R101的AP准确率提升1.4%/0.4%,FPS提高64.4%/48.0%。这表明我们的RT-DETR实现了最先进的实时检测性能。
与端到端检测器的比较
我们还使用相同的主干网络将RT-DETR与现有的DETR模型进行了比较。我们根据在COCO val2017数据集上取得对应精度的设置测试DINO-Deformable-DETR[41]的速度以进行对比,即测试采用TensorRT FP16精度且输入尺寸为(800, 1333)时的速度。表2显示,RT-DETR在使用相同骨干网络的所有DETR模型中,速度与精度均占据优势。相较于DINO-Deformable-DETR-R50,RT-DETR-R50的AP精度提升2.2%,速度提升21倍(108 FPS对比5 FPS),两项指标均有显著改进。
5.2. 混合编码器的消融研究
我们对第4.2节设计的变体指标进行了评估,包括AP(采用1×配置训练)、参数量及延迟(表3)。与基线A相比,变体B的准确率提升1.9% AP,但延迟增加54%,证明尺度内特征交互虽具有显著作用,但单尺度Transformer编码器计算成本较高。变体C较B实现0.7% AP提升,延迟增加20%,表明跨尺度特征融合同样必要,但多尺度Transformer编码器需更高计算开销。变体D较C获得0.8% AP提升,同时降低8%延迟,说明解耦尺度内交互与跨尺度融合不仅能降低计算成本,还可提升精度。与变体D相比,DS5在降低35%延迟的同时实现0.4% AP提升,证实低层级特征的尺度内交互并非必要。最终变体E较D取得1.5% AP提升,尽管参数量增加20%,但延迟降低24%,使编码器效率更高。这表明我们的混合编码器在速度与精度间实现了更优平衡。
5.3. 查询选择的消融研究
我们对不确定性最小化查询选择进行了消融实验,结果基于RT-DETR-R50模型的1×配置呈现在表4中。RT-DETR的查询选择机制根据分类分数选取前K(K=300)个编码器特征作为内容查询,并将所选特征对应的预测框作为初始位置查询。我们在COCO val2017数据集上对比了两种查询选择方案选取的编码器特征,并统计了分类得分大于0.5,以及分类得分与交并比(IoU)均大于0.5的样本比例。结果表明,通过不确定性最小化查询选择所筛选的编码器特征,不仅提升了高分类得分样本占比(0.82%对比0.35%),还提供了更多高质量特征(0.67%对比0.30%)。我们进一步评估了两种查询选择方案在COCO val2017数据集上训练的检测器精度,其中不确定性最小化查询选择实现了0.8%平均精度(AP)的提升(48.7% AP对比47.9% AP)。
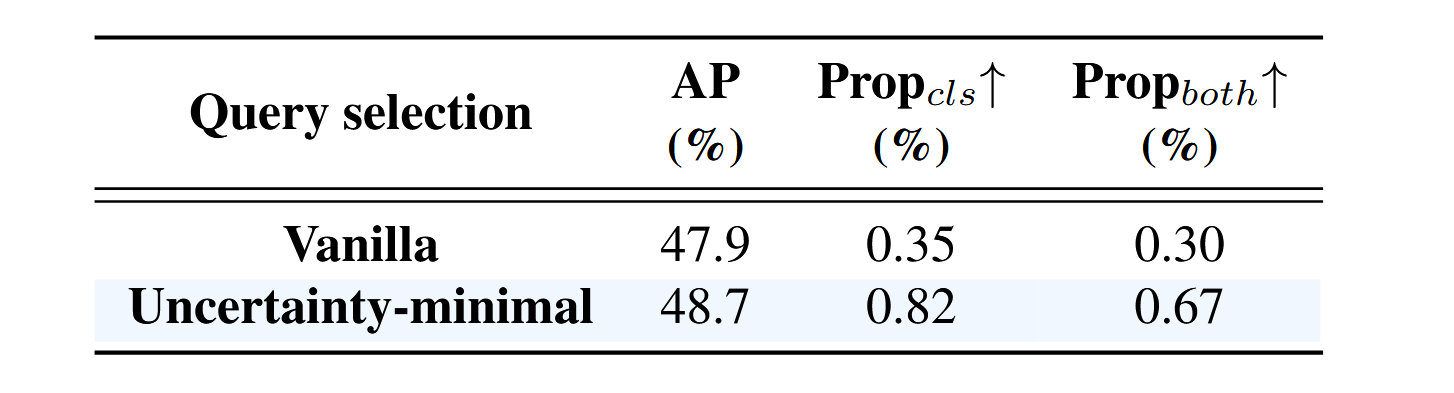
表4. 不确定性最小化查询选择的消融研究结果。 P r o p c l s Prop_{cls} Propcls和 P r o p b o t h Prop_{both} Propboth分别表示分类分数及双分数大于0.5的比例。
5.4. 解码器消融研究
表5展示了不同解码器层数训练的RT-DETR-R50各层推理延迟与精度。当解码器层数设为6时,RT-DETR-R50达到最佳精度53.1% AP。进一步观察发现,随着解码器层索引增加,相邻层间精度差异逐渐减小。以RTDETR-R50-Det6列为例,使用第5层解码器推理仅损失0.1% AP精度(53.1% AP vs 53.0% AP),同时降低0.5 ms延迟(9.3 ms vs 8.8 ms)。因此RT-DETR可通过调整解码器层数实现无需重新训练的灵活速度调节,从而提升其实用性。
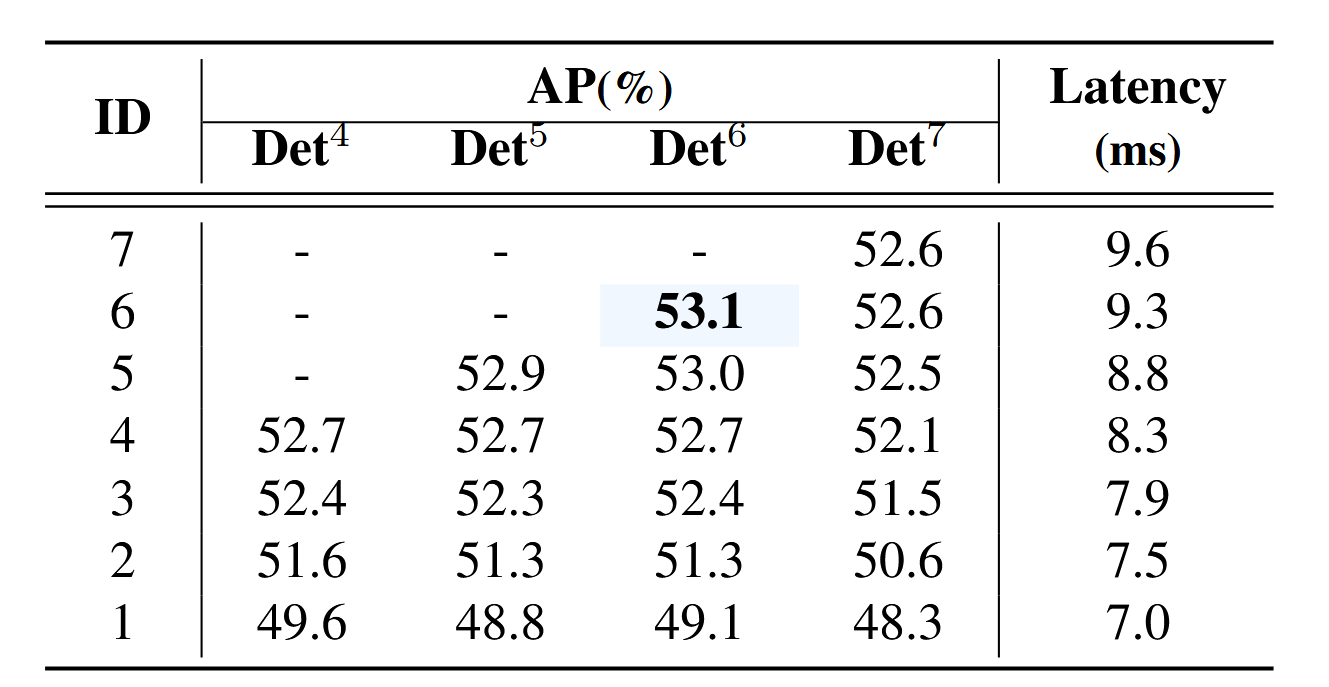
表5. 解码器消融实验结果。ID表示解码器层索引,Detk代表具有k层解码器的检测器。所有结果均在RT-DETR-R50模型6×配置下测得。
6. 局限性与讨论
局限性。尽管提出的RT-DETR在速度和精度上均优于同类规模的先进实时检测器和端到端检测器,但它与其他DETR系列模型存在相同局限——在小物体检测性能上仍逊色于强劲的实时检测器。如表2所示,RT-DETR-R50在 A P S v a l AP^{val}_S APSval指标上比L类模型(YOLOv8-L)的最高值低0.5%,RT-DETR-R101则比X类模型(YOLOv7-X)的最高值低0.9%。我们期待该问题能在未来工作中得到解决。
讨论。现有的大型DETR模型[3,6,30,38,41,43]在COCO test-dev[19]基准测试中展现出卓越性能。我们提出的多尺度RT-DETR保持了与其他DETR模型同构的解码器设计,这使得能够通过高精度预训练大型DETR模型来蒸馏我们的轻量级检测器。我们认为这是RT-DETR相较于其他实时检测器的优势之一,也可能成为未来探索的有趣方向。
7. 结论
在本研究中,我们提出了一种名为RT-DETR的实时端到端检测器,成功将DETR框架扩展至实时检测场景并实现了最先进的性能。RT-DETR包含两项关键改进:高效混合编码器可快速处理多尺度特征,以及不确定性最小化查询选择机制可提升初始目标查询质量。此外,RT-DETR支持无需重新训练的灵活速度调节,并消除了双NMS阈值带来的不便,有利于实际应用。RT-DETR及其模型缩放策略拓宽了实时目标检测的技术路径,为多样化实时场景提供了超越YOLO的新可能性。我们希望RT-DETR能够投入实际应用。
8.引用文献
- [1] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020. 1, 2
- [2] Daniel Bogdoll, Maximilian Nitsche, and J Marius Z ̈ollner. Anomaly detection in autonomous driving: A survey. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4488–4499, 2022. 1
- [3] Yuxuan Cai, Yizhuang Zhou, Qi Han, Jianjian Sun, Xiangwen Kong, Jun Li, and Xiangyu Zhang. Reversible column networks. In International Conference on Learning Representations, 2022. 8
- [4] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer, 2020. 1, 2, 7
- [5] Qiang Chen, Xiaokang Chen, Gang Zeng, and Jingdong Wang. Group detr: Fast training convergence with decoupled oneto-many label assignment. arXiv preprint arXiv:2207.13085, 2022. 2
- [6] Qiang Chen, Jian Wang, Chuchu Han, Shan Zhang, Zexian Li, Xiaokang Chen, Jiahui Chen, Xiaodi Wang, Shuming Han, Gang Zhang, et al. Group detr v2: Strong object detector with encoder-decoder pretraining. arXiv preprint arXiv:2211.03594, 2022. 8
- [7] Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733–13742, 2021. 5
- [8] Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. Fast convergence of detr with spatially modulated co-attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 36213630, 2021. 7
- [9] Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021. 1, 2
- [10] Jocher Glenn. Yolov5 release v7.0. https://github. com/ultralytics/yolov5/tree/v7.0, 2022. 2, 3, 6, 7
- [11] Jocher Glenn. Yolov8. https : / / github . com / ultralytics/ultralytics/tree/main, 2023. 1, 2, 3, 6, 7
- [12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 6
- [13] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 558–567, 2019. 6
- [14] Xin Huang, Xinxin Wang, Wenyu Lv, Xiaying Bai, Xiang Long, Kaipeng Deng, Qingqing Dang, Shumin Han, Qiwen Liu, Xiaoguang Hu, et al. Pp-yolov2: A practical object detector. arXiv preprint arXiv:2104.10419, 2021. 1, 2
- [15] Chuyi Li, Lulu Li, Yifei Geng, Hongliang Jiang, Meng Cheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, and Xiangxiang Chu. Yolov6 v3.0: A full-scale reloading. arXiv preprint arXiv:2301.05586, 2023. 1, 2, 3, 6, 7
- [16] Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1361913627, 2022. 1, 2, 7
- [17] Feng Li, Ailing Zeng, Shilong Liu, Hao Zhang, Hongyang Li, Lei Zhang, and Lionel M Ni. Lite detr: An interleaved multi-scale encoder for efficient detr. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18558–18567, 2023. 2
- [18] Junyu Lin, Xiaofeng Mao, Yuefeng Chen, Lei Xu, Yuan He, and Hui Xue. Dˆ 2etr: Decoder-only detr with computationally efficient cross-scale attention. arXiv preprint arXiv:2203.00860, 2022. 4
- [19] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dolla ́r, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755. Springer, 2014. 3, 8
- [20] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dolla ́r. Focal loss for dense object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2980–2988, 2017. 2
- [21] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8759–8768, 2018. 4
- [22] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. Dab-detr: Dynamic anchor boxes are better queries for detr. In International Conference on Learning Representations, 2021. 1, 2, 7
- [23] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European Conference on Computer Vision, pages 21–37. Springer, 2016. 2
- [24] Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, et al. Pp-yolo: An effective and efficient implementation of object detector. arXiv preprint arXiv:2007.12099, 2020. 1, 2
- [25] Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3651–3660, 2021. 1, 3, 7
- [26] Rashmika Nawaratne, Damminda Alahakoon, Daswin De Silva, and Xinghuo Yu. Spatiotemporal anomaly detection using deep learning for real-time video surveillance. IEEE Transactions on Industrial Informatics, 16(1):393–402, 2019. 1
- [27] Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7263–7271, 2017. 2
- [28] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. 1, 2
- [29] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 779–788, 2016. 2
- [30] Tianhe Ren, Jianwei Yang, Shilong Liu, Ailing Zeng, Feng Li, Hao Zhang, Hongyang Li, Zhaoyang Zeng, and Lei Zhang. A strong and reproducible object detector with only public datasets. arXiv preprint arXiv:2304.13027, 2023. 8
- [31] Byungseok Roh, JaeWoong Shin, Wuhyun Shin, and Saehoon Kim. Sparse detr: Efficient end-to-end object detection with learnable sparsity. In International Conference on Learning Representations, 2021. 2
- [32] Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8430–8439, 2019. 2
- [33] Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14454–14463, 2021. 1
- [34] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13029–13038, 2021. 2
- [35] Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. Yolov7: Trainable bag-of-freebies sets new state-ofthe-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7464–7475, 2023. 1, 2, 3, 6, 7
- [36] Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun. Anchor detr: Query design for transformer-based detector. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2567–2575, 2022. 1, 3, 7
- [37] Shangliang Xu, Xinxin Wang, Wenyu Lv, Qinyao Chang, Cheng Cui, Kaipeng Deng, Guanzhong Wang, Qingqing Dang, Shengyu Wei, Yuning Du, et al. Pp-yoloe: An evolved version of yolo. arXiv preprint arXiv:2203.16250, 2022. 1, 2, 3, 6, 7
- [38] Jianwei Yang, Chunyuan Li, Xiyang Dai, and Jianfeng Gao. Focal modulation networks. Advances in Neural Information Processing Systems, 35:4203–4217, 2022. 8
- [39] Zhuyu Yao, Jiangbo Ai, Boxun Li, and Chi Zhang. Efficient detr: improving end-to-end object detector with dense prior. arXiv preprint arXiv:2104.01318, 2021. 2, 5, 7
- [40] Fangao Zeng, Bin Dong, Yuang Zhang, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. Motr: End-to-end multipleobject tracking with transformer. In European Conference on Computer Vision, pages 659–675. Springer, 2022. 1
- [41] Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. In International Conference on Learning Representations, 2022. 1, 2, 3, 5, 7, 8
- [42] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In International Conference on Learning Representations, 2020. 1, 2, 3, 4, 5, 7
- [43] Zhuofan Zong, Guanglu Song, and Yu Liu. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6748–6758, 2023. 8