14 C 语言浮点类型详解:类型精度、表示形式、字面量后缀、格式化输出、容差判断、存储机制
1 浮点类型
1.1 浮点类型概述
浮点类型用于表示小数(如 123.4、3.1415、0.99),支持正数、负数和零,是科学计算和工程应用的核心数据类型。
1.2 浮点数的类型与规格
| 浮点类型 | 存储大小 | 值范围(近似) | 实际有效小数位数 |
|---|---|---|---|
| float(单精度) | 4 字节(32 位) | 负数:-3.4E+38 ~ -1.18E-38 正数:1.18E-38 ~ 3.4E+38 | 6 - 7 位 |
| double(双精度) | 8 字节(64 位) | 负数:-1.8E+308 ~ -2.23E-308 正数:2.23E-308 ~ 1.8E+308 | 15 - 16 位 |
| long double(长双精度,C99 引入) | 32 位:8/10/12/16 字节 64 位:16 字节 | 32 位系统:与 double 相当或更大 64 位系统: 负数:-1.19E+4932 ~ -3.36E-4932 正数:3.36E-4932 ~ 1.19E+4932 | 18 - 19 位(x86 80-bit) |
-
long double 的存储大小实际取决于编译器和架构:
-
ARM 平台:可能直接映射到 double(8 字节)。
-
Windows (MSVC):通常为 8 字节(与 double 相同)。
-
Linux x86:通常为 12 字节(10 字节数据 + 2 字节对齐),但实际内存占用为 16 字节(因对齐到 16 字节边界)。
-
x64 系统:通常为 16 字节(编译器可能使用 16 字节以对齐或简化实现)。
-
不同编译器(如 GCC、Clang、MSVC)对 long double 的实现可能不同,需通过 sizeof(long double) 确认。
-
-
有效小数位数说明:
-
float:尾数(mantissa)为 23 位(隐含 1 位),实际有效位数为 6~7 位(理论值:23 × log₁₀(2) ≈ 6.92)。
-
double:尾数为 52 位(隐含 1 位),实际有效位数为 15~16 位(理论值:52 × log₁₀(2) ≈ 15.65)。
-
long double (x86 80-bit):尾数为 64 位(隐含 1 位),实际有效位数为 18~19 位(理论值:64 × log₁₀(2) ≈ 19.27)。
-
1.3 浮点类型注意事项
平台依赖性
- 浮点类型的存储大小(如 float、double、long double)和精度可能因操作系统、编译器或硬件平台而异。
- 建议通过代码(如 sizeof 运算符)或文档确认实际行为,尤其在跨平台开发中需谨慎。
类型选择建议
- 默认优先选择 double:兼顾精度与性能,适合大多数科学计算和工程场景。
- 高精度需求使用 long double:例如天文计算、物理模拟等极端场景,但需注意平台兼容性(部分平台可能等价于 double)。
- 避免 float 除非必要:仅在存储空间极度受限时使用(如嵌入式系统或大规模数据存储)。
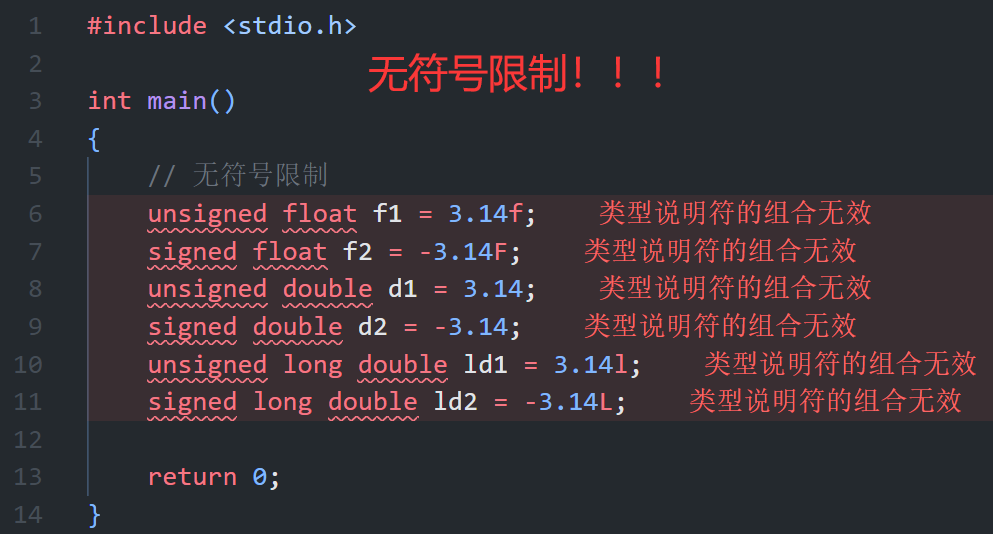
无符号限制
- 浮点类型(如 float、double、long double)无 signed/unsigned 之分,强制使用会触发编译器报错。
- 原因:浮点数的符号位是标准 IEEE 754 格式的一部分,无法通过关键字修改。
1.4 浮点型数据的表示形式
十进制数形式
- 定义:直接以常规小数形式表示浮点数。
- 合法示例:
- 5.12:标准小数形式。
- 512.0f:后缀 f 表示 float 类型(C/C++ 中用于显式指定单精度)。
- .512:等价于 0.512,小数点前的 0 可省略。
科学计数法形式
- 定义:通过基数(mantissa,尾数)和指数(exponent)表示浮点数,适用于极大或极小的数值。
- 表达形式:
- 数学表示:基数(尾数) × 10^指数
- 示例:
- 1.8 × 10¯³ 表示 0.0018。
- -123 × 10¯³ 表示 0.123。
- 示例:
- 编程语法表示:计算机中通常使用 e 或 E 表示指数部分,形式为:基数e指数 或 基数E指数
- 示例:
- 1e-3 表示 1×10¯³(即 0.001)。
- 1.8e-3 表 示 1.8×10¯³(即 0.0018)。
- -123E-6 表示 −123×10¯⁶(即 -0.000123)。
- 示例:
- 数学表示:基数(尾数) × 10^指数
- 表示规则:
- 基数部分:e 或 E 前的数必须为非零有效数字(整数或小数),不可为空。
- 指数部分:e 或 E 后的数必须为整数,可正、可负或为零。
- 正指数:表示基数乘以 10^正指数(小数点右移),例如:e³ 表示 10³。
- 负指数:表示基数乘以 10^负指数(小数点左移),例如:e¯³ 表示 10¯³。
- 零指数:表示基数乘以 10^0 = 1(即基数本身),例如:e⁰ 表示 10⁰ = 1。
-
规则总结:e(或 E)前为有效数字,后为整数。
完整示例:
| 数学表示 | 编程语法 | 等价形式 | 说明 |
|---|---|---|---|
| 1×10¯³ | 1e-3 | 0.001 | 负指数:小数点左移 3 位 |
| 1.8×10¯³ | 1.8e-3 | 0.0018 | 负指数:小数点左移 3 位 |
| −123×10¯⁶ | -123e-6 | -0.000123 | 负指数:小数点左移 6 位 |
| −0.1×10¯³ | -.1E-3 | -0.0001 | 负指数:小数点左移 3 位 |
| 5×10⁰ | 5E0 | 5 | 零指数:基数不变 |
| 3.14×10² | 3.14E2 | 314 | 正指数:小数点右移 2 位 |
错误示例及原因:
| 示例 | 错误原因 |
|---|---|
| e3 | e 前无有效数字 |
| 2.1e3.5 | 指数部分为小数(必须为整数) |
| .E3 | E 前无有效数字 |
| E | E 前无有效数字(指数为 0 可省略) |
1.5 字面量后缀规则
在 C 语言中,字面量(literal)的后缀用于明确指定其类型。浮点数字面量的类型默认规则及后缀用法如下:
默认 double 类型
- 不加后缀:浮点数字面量(如 3.14、0.5)默认是 double 类型。
double d1 = 6.66; // 默认是 double 类型
float f1 = 3.14; // 默认是 double 类型,编译器会自动将 double 类型的字面量隐式转换为 float 类型
long double ld1 = 9.99; // 默认是 double 类型,编译器会自动将 double 类型的字面量隐式转换为 long double 类型指定 float 类型
- 后缀 f 或 F:若需明确表示 float 类型字面量,需在浮点数后加 f 或 F。
float x = 3.14f; // 3.14 被解释为 float 类型
float y = 2.5F; // 2.5 被解释为 float 类型指定 long double 类型
- 后缀 l 或 L:若需明确表示 long double 类型字面量,需在浮点数后加 l 或 L。
- 推荐使用大写 L,避免与数字 1 混淆。
long double a = 3.141592653589793L; // 3.141592653589793 被解释为 long double 类型扩展:编译器如何区分 long double 和 long int 字面量?
在 C 语言中,l 或 L 后缀既可用于浮点数,也可用于整数,但编译器通过上下文确定字面量的类型:
- 整数类型字面量
- 无后缀:默认是 int 类型。若值超出 int 范围,则自动提升为 long int 或 long long int(取决于编译器和平台)。
- 后缀 l 或 L:明确表示 long int 类型。
long int m = 1000000L; // 1000000 被解释为 long int 类型
浮点数类型字面量
- 无后缀:默认是 double 类型。
- 后缀 f 或 F:明确表示 float 类型。
- 后缀 l 或 L:明确表示 long double 类型。
long double ld = 1.23L; // 1.23 是浮点数,后缀 L 表示 long double long int li = 123L; // 123 是整数,后缀 L 表示 long int
- 总结:
- 整数字面量:
- 默认 int 类型(可能自动提升)
- l/L → long int 类型
- 浮点数字面量:
- 默认 double 类型
- f/F → float 类型
- l/L → long double 类型
1.6 浮点类型格式占位符说明
在 C 语言中,格式占位符用于 printf、scanf 等函数中,以指定变量的输出或输入格式。以下是浮点数相关的占位符说明:
%f:double 类型的默认占位符
- 适用场景:
- 在 printf 中,%f 用于输出 double 类型数据。
- float 类型在传递给 printf 时会自动提升为 double,因此也可以用 %f 输出。
- 默认行为:默认保留 6 位小数,结果会进行四舍五入。
- 指定小数位数:可以通过 .n 格式指定小数位数(如 %.2f 保留 2 位小数),结果会进行四舍五入。
#include <stdio.h>int main()
{// 1. 输出 double 类型数据double d = 3.1415926535;// 使用 %f 格式说明符输出 double 类型数据printf("double 类型(默认 6 位小数,四舍五入): %f\n", d); // 3.141593printf("double 类型(保留 2 位小数,四舍五入): %.2f\n", d); // 3.14printf("double 类型(保留 4 位小数,四舍五入): %.4f\n\n", d); // 3.1416// 2. 输出 float 类型数据(float 会自动提升为 double)float f = 1.234567f;// 在 C 语言中,float 会自动提升为 double,因此 %f 也可以用于输出 float 类型数据printf("float 类型(默认 6 位小数,四舍五入): %f\n", f); // 1.234567printf("float 类型(保留 2 位小数,四舍五入): %.2f\n", f); // 1.23printf("float 类型(保留 4 位小数,四舍五入): %.4f\n", f); // 1.2346return 0;
}程序在 VS Code 中的运行结果如下所示:

%lf:double 类型的兼容占位符(C99 起)
- 适用场景:在 printf 中,%lf 与 %f 完全等价(均对应 double 类型,float 类型会自动提升为 double)。
- 习惯用法:通常使用 %f(更简洁,符合惯例)。
- 默认行为:默认保留 6 位小数,结果会进行四舍五入。
- 指定小数位数:可以通过 .n 格式指定小数位数(如 %.2lf 保留 2 位小数),结果会进行四舍五入。
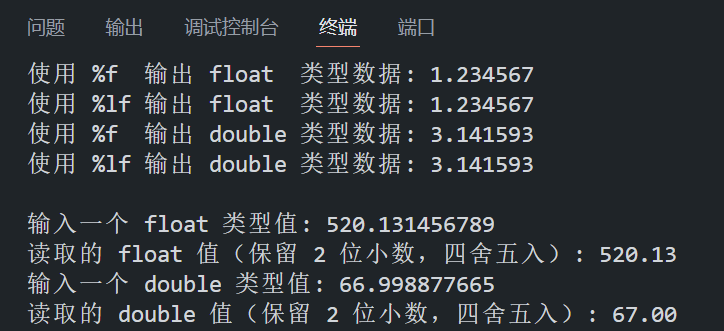
- 与 scanf 的区别:在 scanf 中,%f 用于 float 类型,%lf 用于 double 类型(必须严格区分)。
#include <stdio.h>int main()
{// 1. printf 中 %f 和 %lf 的等价性演示float f = 1.234567f;double d = 3.1415926535;printf("使用 %%f 输出 float 类型数据: %f\n", f); // 输出:1.234567printf("使用 %%lf 输出 float 类型数据: %lf\n", f); // 输出:1.234567printf("使用 %%f 输出 double 类型数据: %f\n", d); // 输出:3.141593printf("使用 %%lf 输出 double 类型数据: %lf\n\n", d); // 输出:3.141593// 2. scanf 中 %f 和 %lf 的严格区分演示float f2;double d2;printf("输入一个 float 类型值: ");scanf("%f", &f2); // 正确:%f 对应 float 类型printf("读取的 float 值: %.2f\n", f2);printf("输入一个 double 类型值: ");scanf("%lf", &d2); // 正确:%lf 对应 double 类型printf("读取的 double 值: %.2lf\n", d2);return 0;
}程序在 VS Code 中的运行结果如下所示:
%Lf:long double 类型的占位符
- 适用场景:在 printf 和 scanf 中,%Lf 专用于 long double 类型。
- 默认行为:默认保留 6 位小数,结果会进行四舍五入。
- 指定小数位数:可以通过 .n 格式指定小数位数(如 %.4Lf 保留 4 位小数),结果会进行四舍五入。
#include <stdio.h>int main()
{long double ld;// 1. 使用 scanf 读取 long double 类型值printf("输入一个 long double 类型值: ");scanf("%Lf", &ld); // 必须使用 %Lf 读取 long double 类型// 2. 使用 printf 输出 long double 类型值printf("读取的 long double 值(默认 6 位小数): %Lf\n", ld);printf("读取的 long double 值(保留 4 位小数): %.4Lf\n", ld);return 0;
}程序在 VS Code 中的运行结果如下所示:

%e 或 %E 等:科学计数法占位符
- 适用场景:
- 用于以科学计数法输出浮点数,但不同类型对应不同的格式占位符。
- %e 输出小写 e(如 1.23e+01),%E 输出大写 E(如 1.23E+01)。
- 默认行为:默认保留 6 位小数,结果会进行四舍五入。
- 指定小数位数:可以通过 .n 格式(如 %.2e 或 %.2E)指定小数位数,结果会进行四舍五入。
- 不同类型对应的占位符:
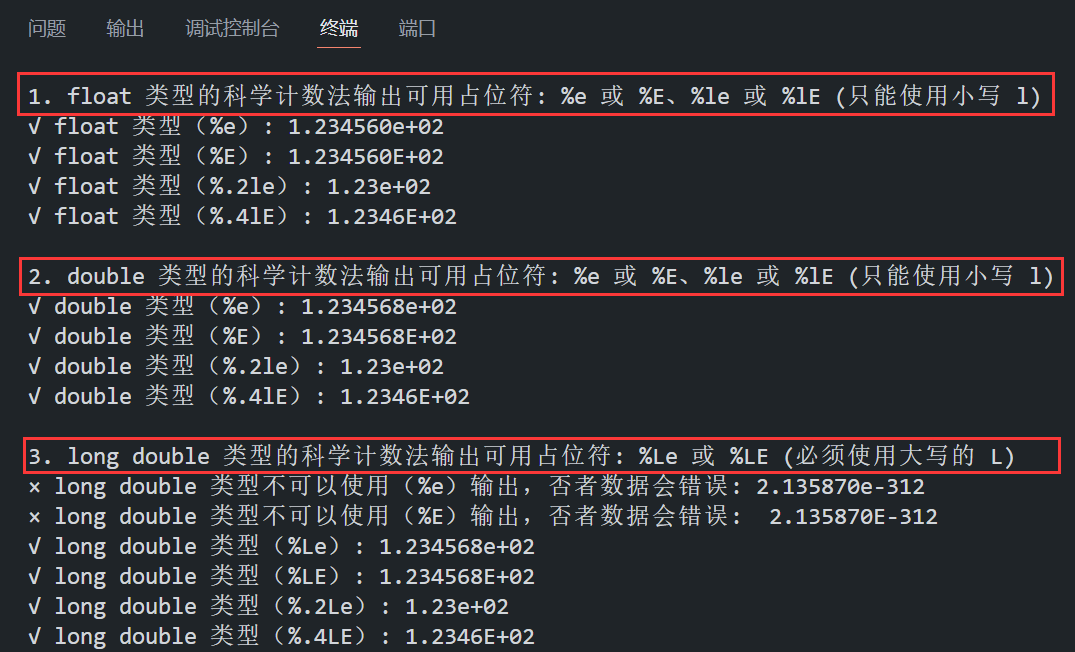
- float 类型 与 double 类型:%e 或 %E、%le 或 %lE(只能是小写 l),因为 printf 中 float 会自动提升为 double,所以 %e 或 %E、%le 或 %lE 对 float 也有效。
- long double 类型:%Le 或 %LE,必须使用大写的 L。
#include <stdio.h>int main()
{float f = 123.456f;double d = 123.456789;long double ld = 123.4567890123456789L;// 1. float 类型的科学计数法输出: %e 或 %E、%le 或 %lE (只能使用小写 l)printf("1. float 类型的科学计数法输出可用占位符: %%e 或 %%E、%%le 或 %%lE (只能使用小写 l)\n");printf("√ float 类型(%%e): %e\n", f); // 输出:1.234560e+02printf("√ float 类型(%%E): %E\n", f); // 输出:1.234560E+02printf("√ float 类型(%%.2le): %.2le\n", f); // 输出:1.23e+02printf("√ float 类型(%%.4lE): %.4lE\n\n", f); // 输出:1.2346E+02// 2. double 类型的科学计数法输出: %e 或 %E、%le 或 %lE (只能使用小写 l)printf("2. double 类型的科学计数法输出可用占位符: %%e 或 %%E、%%le 或 %%lE (只能使用小写 l)\n");printf("√ double 类型(%%e): %e\n", d); // 输出:1.234568e+02printf("√ double 类型(%%E): %E\n", d); // 输出:1.234568E+02printf("√ double 类型(%%.2le): %.2le\n", d); // 输出:1.23e+02printf("√ double 类型(%%.4lE): %.4lE\n\n", d); // 输出:1.2346E+02// 3. long double 类型的科学计数法输出: %Le 或 %LE (必须使用大写的 L)printf("3. long double 类型的科学计数法输出可用占位符: %%Le 或 %%LE (必须使用大写的 L)\n");printf("× long double 类型不可以使用(%%e)输出,否者数据会错误: %e\n", ld);printf("× long double 类型不可以使用(%%E)输出,否者数据会错误: %E\n", ld);printf("√ long double 类型(%%Le): %Le\n", ld); // 输出:1.234568e+02printf("√ long double 类型(%%LE): %LE\n", ld); // 输出:1.234568E+02printf("√ long double 类型(%%.2Le): %.2Le\n", ld); // 输出:1.23e+02printf("√ long double 类型(%%.4LE): %.4LE\n", ld); // 输出:1.2346E+02return 0;
}程序在 VS Code 中的运行结果如下所示:
浮点类型格式占位符总结
| 占位符 | printf 适用类型 | scanf 适用类型 | |
|---|---|---|---|
| %f | double 及自动提升的 float | float | |
| %lf | double 及自动提升的 float(与 %f 等价) | double | |
| %Lf | long double | long double | |
| %e | float、double | 不适用(科学计数法不直接输入) | |
| %E | float、double | 不适用(科学计数法不直接输入) | |
| %le | float、double(与 %e 等价) | 不适用(科学计数法不直接输入) | |
| %lE | float、double(与 %E 等价) | 不适用(科学计数法不直接输入) | |
| %Le | long double | 不适用(科学计数法不直接输入) | |
| %LE | long double | 不适用(科学计数法不直接输入) |
- %e 和 %E 仅适用于 float 和 double 类型的科学计数法输出,不适用于 long double 类型。
- long double 类型的科学计数法输出必须使用 %Le 或 %LE。
- scanf 中必须严格区分 %f(float)、%lf(double)、%Lf(long double)。
- 默认行为:使用 printf 输出浮点数默认保留 6 位小数,结果会进行四舍五入。
- 指定小数位数:可以通过 .n 格式(如 %.2f 或 %.2lf 或 %.2Lf 或 %.2e 等)指定小数位数,结果会进行四舍五入。
2 浮点数特性与精度分析
2.1 浮点类型存储空间检测
要检测浮点数类型的存储空间,可以使用 C 语言提供的 sizeof 运算符。该运算符能够返回变量或数据类型在内存中占用的字节数。以下程序展示了如何利用 sizeof 运算符来检查各种浮点类型的存储空间分配情况:
#include <stdio.h>int main()
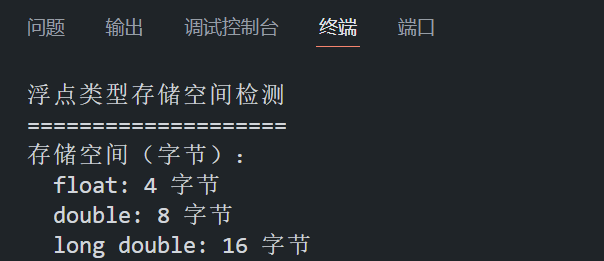
{printf("浮点类型存储空间检测\n");printf("====================\n");// 检测各浮点类型的存储空间printf("存储空间(字节):\n");printf(" float: %zu 字节\n", sizeof(float));printf(" double: %zu 字节\n", sizeof(double));printf(" long double: %zu 字节\n", sizeof(long double));return 0;
}- sizeof(float):返回 float 类型的存储空间大小(通常为 4 字节)。
- sizeof(double):返回 double 类型的存储空间大小(通常为 8 字节)。
- sizeof(long double):返回 long double 类型的存储空间大小(因编译器和架构而异,常见为 16 字节)。
程序在 VS Code 中的运行结果如下所示:
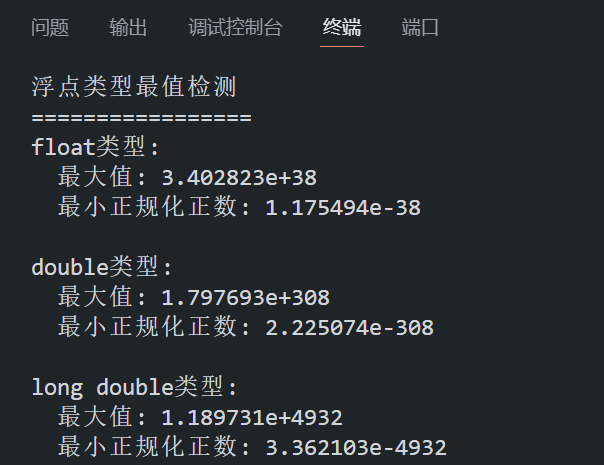
2.2 浮点类型最值检测
要检测 C 语言中浮点数的最大值和最小值,我们可以使用标准库中定义的宏常量。这些宏常量定义在 <float.h> 头文件中,提供了各种浮点类型的极值信息。操作步骤如下:
- 需要包含 <float.h> 头文件,其中定义了浮点数的各种极限值。
- 主要使用的宏常量包括:
- FLT_MAX / DBL_MAX / LDBL_MAX:分别表示 float、double 和 long double 类型的最大值。
- FLT_MIN / DBL_MIN / LDBL_MIN:分别表示 float、double 和 long double 类型的最小正规化正数。
- 使用 printf 函数的格式说明符 %e (科学计数法) 或 %Le (长双精度科学计数法)来输出这些值。
以下是完整的实现代码:
#include <stdio.h>
#include <float.h> // 包含浮点数极值宏定义int main()
{printf("浮点类型最值检测\n");printf("=================\n");// 检测 float 类型的极值printf("float类型:\n");printf(" 最大值: %e\n", FLT_MAX); // 3.402823e+38printf(" 最小正规化正数: %e\n", FLT_MIN); // 1.175494e-38// 检测 double 类型的极值printf("\ndouble类型:\n");printf(" 最大值: %e\n", DBL_MAX); // 1.797693e+308printf(" 最小正规化正数: %e\n", DBL_MIN); // 2.225074e-308// 检测 long double 类型的极值printf("\nlong double类型:\n");printf(" 最大值: %Le\n", LDBL_MAX); // 1.189731e+4932printf(" 最小正规化正数: %Le\n", LDBL_MIN); // 3.362103e-4932return 0;
}程序在 VS Code 中的运行结果如下所示:
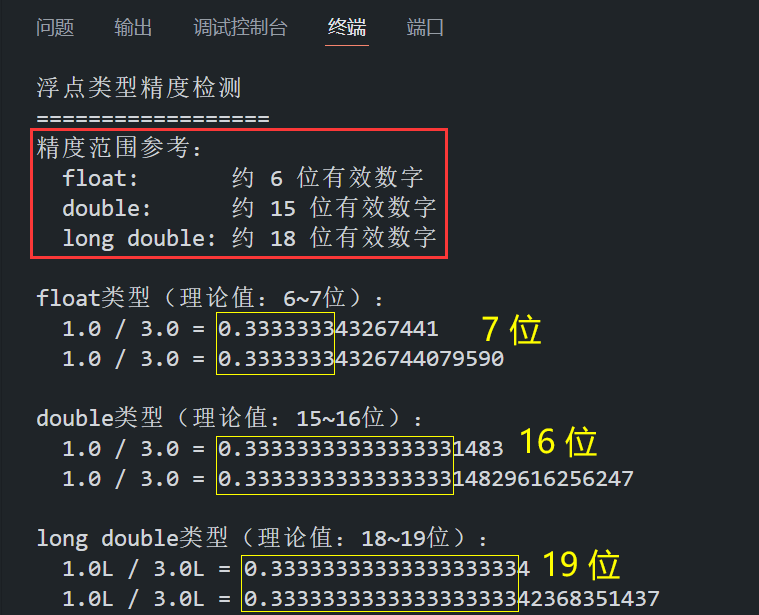
2.3 浮点类型精度检测
浮点数的精度是指它能表示的有效数字位数。在 C 语言中,不同浮点类型有不同的精度限制。我们可以通过两种方式来检测浮点数的精度:
- 宏定义查询法:通过包含 <float.h> 头文件,使用其中定义的宏常量来直接查看浮点类型的理论精度值。
- 包含 <float.h> 头文件
- 使用以下宏常量获取理论精度值:
- FLT_DIG:float 类型的有效数字位数 —— 6
- DBL_DIG:double 类型的有效数字位数 —— 15
- LDBL_DIG:long double 类型的有效数字位数 —— 18
- 实际计算观察法:通过计算简单分数(如 1/3)并观察其小数表示来直观感受浮点数的精度特性。
- 使用除法运算(如 1.0/3.0)产生无限循环小数
- 通过指定不同的输出精度观察数字的表示情况
- 比较不同浮点类型的精度表现:
- float:通常提供约 6-7 位有效数字
- double:通常提供约 15-16 位有效数字
- long double:通常提供更高的精度(约 18-19 位)
#include <stdio.h>
#include <float.h> // 用于浮点数精度常量int main()
{printf("浮点类型精度检测\n");printf("==================\n");// 显示理论精度值(使用 float.h 中的宏定义)printf("精度范围参考:\n");printf(" float: 约 %d 位有效数字\n", FLT_DIG);printf(" double: 约 %d 位有效数字\n", DBL_DIG);printf(" long double: 约 %d 位有效数字\n", LDBL_DIG);printf("\n");// 测试 float 类型的精度(实际计算观察法)printf("float类型(理论值:6~7位):\n");printf(" 1.0 / 3.0 = %.15f\n", 1.0f / 3.0f); // 输出 15 位小数printf(" 1.0 / 3.0 = %.20f\n", 1.0f / 3.0f); // 输出 20 位小数(观察精度损失)printf("\n");// 测试 double 类型的精度(实际计算观察法)printf("double类型(理论值:15~16位):\n");printf(" 1.0 / 3.0 = %.20lf\n", 1.0 / 3.0); // 输出 20 位小数printf(" 1.0 / 3.0 = %.30lf\n", 1.0 / 3.0); // 输出 30 位小数(观察精度损失)printf("\n");// 测试 long double 类型的精度(实际计算观察法)printf("long double类型(理论值:18~19位):\n");printf(" 1.0L / 3.0L = %.20Lf\n", 1.0L / 3.0L); // 输出 20 位小数printf(" 1.0L / 3.0L = %.30Lf\n", 1.0L / 3.0L); // 输出 30 位小数(观察精度损失)return 0;
}程序在 VS Code 中的运行结果如下所示:
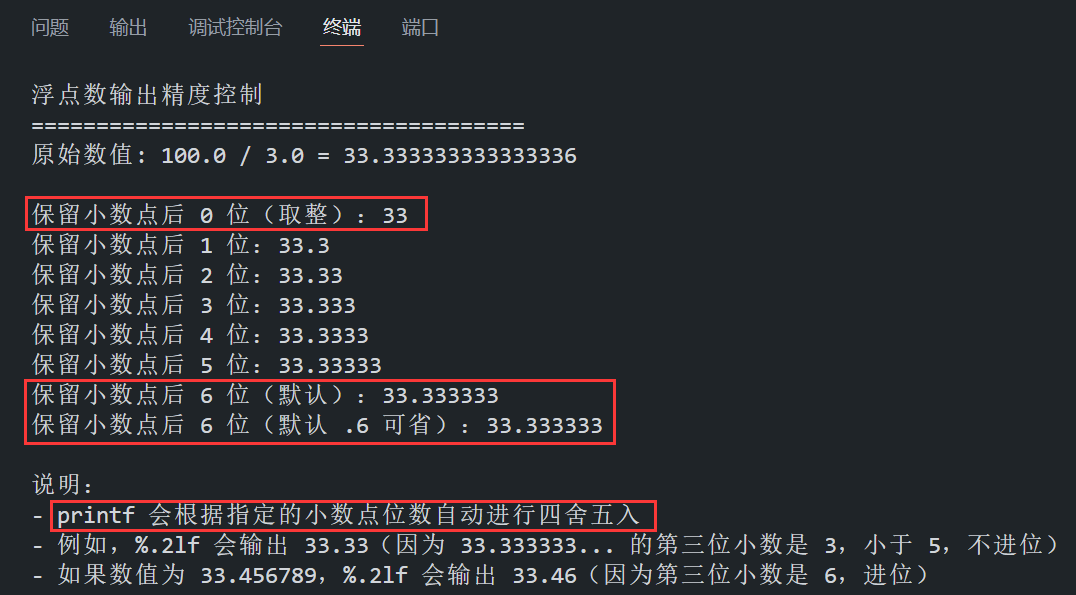
2.4 浮点数输出精度控制
在 C 语言中,printf 函数提供了灵活的小数点精度控制功能。通过指定格式字符串中的小数位数,我们可以控制浮点数输出的精度,并且 printf 会自动执行四舍五入操作。
- 默认输出:当不指定小数位数时(使用 %f),printf 默认输出 6 位小数。
- 指定小数位数:通过在格式说明符中指定小数位数(如 %.2f),可以控制输出的精度。
- 指定小数位数为 0 时,printf 会进行取整操作,输出整数部分。
- 指定小数位数大于 0 时,printf 会根据指定的小数位数进行四舍五入。
- 四舍五入规则:printf 会根据指定的小数点位数自动进行四舍五入。
- 如果舍去部分的首位数字小于 5,则直接舍去。
- 如果舍去部分的首位数字等于或大于 5,则进位。
#include <stdio.h>int main()
{double number = 100.0 / 3.0;printf("浮点数输出精度控制\n");printf("======================================\n");printf("原始数值: 100.0 / 3.0 = %.15lf\n\n", number); // 输出 15 位小数(原始值)// 控制保留小数点后 0~6 位,观察四舍五入效果printf("保留小数点后 0 位(取整):%.0lf\n", number);printf("保留小数点后 1 位:%.1lf\n", number);printf("保留小数点后 2 位:%.2lf\n", number);printf("保留小数点后 3 位:%.3lf\n", number);printf("保留小数点后 4 位:%.4lf\n", number);printf("保留小数点后 5 位:%.5lf\n", number);printf("保留小数点后 6 位(默认):%.6lf\n", number);printf("保留小数点后 6 位(默认 .6 可省):%lf\n\n", number);// 补充说明:观察四舍五入的效果printf("说明:\n");printf("- printf 会根据指定的小数点位数自动进行四舍五入\n");printf("- 例如,%%.2lf 会输出 33.33(因为 33.333333... 的第三位小数是 3,小于 5,不进位)\n");printf("- 如果数值为 %lf,%%.2lf 会输出 %.2lf(因为第三位小数是 6,进位)\n", 33.456789, 33.456789);return 0;
}程序在 VS Code 中的运行结果如下所示:
2.5 浮点数特殊值检测
在浮点数运算中,除了常规的数值外,还可能遇到一些特殊值,如 NaN(非数字,Not a Number)、 Infinity(无穷大)。这些特殊值通常出现在无效运算(如 0.0 除以 0.0)或超出表示范围的运算结果中。为了正确处理这些特殊值,C 标准库提供了 isnan() 和 isinf() 等函数来检测它们。
#include <stdio.h>
#include <math.h> // 包含 math.h 头文件以使用 isnan() 和 isinf() 函数int main()
{double a = 0.0 / 0.0; // 这将产生一个 NaN 值double b = 1.0 / 0.0; // 这将产生一个正无穷大值double c = -1.0 / 0.0; // 这将产生一个负无穷大值double d = 2.0; // 常规浮点数// 检测 NaN 值if (isnan(a)){printf("a 是 NaN 值\n");}else{printf("a 不是 NaN 值\n");}// 检测正无穷大值if (isinf(b) && b > 0){printf("b 是正无穷大值\n");}else{printf("b 不是正无穷大值\n");}// 检测负无穷大值if (isinf(c) && c < 0){printf("c 是负无穷大值\n");}else{printf("c 不是负无穷大值\n");}// 检测常规浮点数if (!isnan(d) && !isinf(d)){printf("d 是一个常规浮点数\n");}else{printf("d 不是一个常规浮点数\n");}return 0;
}程序在 VS Code 中的运行结果如下所示:

在上述代码中,我们使用了 if 分支语句和 math.h 头文件中的 isnan() 和 isinf() 函数来进行特殊值的判断。如果你目前对 if 分支语句的使用还不太熟悉,不用担心,这在学习编程的过程中是很常见的。我们建议你先专注于理解浮点数的基本概念和特殊值的处理。在你学习了 if 语句和数学函数的相关知识后,欢迎你回过头来回顾这个程序,以便更好地理解其实现和逻辑。
2.6 浮点数近似相等判断
在浮点数运算中,由于计算机内部表示的限制,常常会引入微小的舍入误差。因此,直接比较两个浮点数是否相等(如 a == b)通常是不安全的。为了正确处理浮点数的比较,应该使用容差(也称为误差范围)来判断两个浮点数是否 "近似相等"。
- 舍入误差:浮点数在计算机中是以二进制形式存储的,某些十进制小数无法精确表示,导致运算结果可能存在微小误差。
- 近似相等判断:通过计算两个浮点数的差的绝对值,并判断其是否小于一个极小的阈值(容差),来确定它们是否 "近似相等"。
- 容差选择:容差的选择取决于具体的应用场景和精度要求。常见的容差值为 1e-9(即 0.000000001)。
#include <stdio.h>
#include <math.h> // 包含 math.h 头文件以使用 fabs 函数int main()
{double x = 1.0 / 3.0; // 1.0 / 3.0 是一个无限循环小数,无法精确表示double y = 0.3333333333333333; // 近似值double epsilon = 1e-9; // 定义一个非常小的容差值// 直接比较(不推荐)if (x == y){printf("直接比较(不推荐):x == y\n");}else{printf("直接比较(不推荐):x != y (这是由于浮点数舍入误差)\n");}// 使用容差判断(推荐)if (fabs(x - y) < epsilon){printf("容差比较(推荐):x 和 y 近似相等(容差: %e)\n", epsilon);}else{printf("容差比较(推荐):x 和 y 不近似相等(容差: %e)\n", epsilon);}return 0;
}程序在 VS Code 中的运行结果如下所示:

在上述代码中,我们使用了 if 分支语句和 math.h 头文件中的 fabs 函数来进行浮点数的近似相等判断。如果你目前对 if 分支语句的使用还不太熟悉,不用担心,这在学习编程的过程中是很常见的。我们建议你先专注于理解浮点数的基本概念和为什么直接比较浮点数是不安全的。在你学习了 if 语句和数学函数的相关知识后,欢迎你回过头来回顾这个程序,以便更好地理解其实现和逻辑。
3 浮点数存储机制
3.1 浮点数存储结构
浮点数在计算机内部以二进制科学计数法形式存储,其结构由三部分组成:符号位 (S)、指数位 (E) 、尾数位 (M)。
-
符号位 (S):取值为 0 或 1,用于表示浮点数的正负。其中,0 表示正数,1 表示负数。
-
指数位 (E):用于表示浮点数的指数部分,决定了浮点数的范围大小。
-
尾数位 (M):决定了浮点数的精度。
-
在二进制科学计数法中,尾数位的要求是大于等于 1 且小于 2,即其规范化范围是 [1, 2)。这与十进制科学计数法中的尾数范围 [1, 10) 有所不同。
-
在计算机内部,浮点数是以二进制科学计数法的形式存储的。然而,在输出时,浮点数通常会转换为十进制科学计数法,此时尾数范围相应变为 [1, 10)(十进制)。
-
例如,使用 printf("%e", 0.67); 输出结果为 6.700000e-01,其中尾数 6.7 是在 [1,10) 之间的数。这只是输出时转换为十进制科学计数法的表示,并不代表浮点数在计算机内部的存储形式。
-
以数字 120.45 为例,用十进制科学计数法表示为 1.2045 × 10²,因此:
- 符号位 S = 0(正数)
- 指数位 E = 2
- 尾数位 M = 1.2045(在计算机内部以二进制形式存储)
3.2 浮点数存储类型
单精度浮点数 (float):
float 类型是 32 位浮点数,最高的 1 位是符号位 S,接着用 8 位表示指数 E,剩下的 23 位表示尾数 M。

- 总位数:32 位
- 符号位 (S):1 位
- 指数位 (E):8 位
- 尾数位 (M):23 位
双精度浮点数 (double):
double 类型是 64 位浮点数,最高的 1 位是符号位 S,接着用 11 位表示指数 E,剩下的 52 位表示尾数 M。
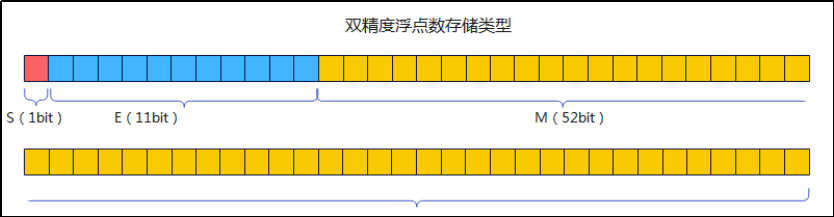
- 总位数:64 位
- 符号位 (S):1 位
- 指数位 (E):11 位
- 尾数位 (M):52 位
长双精度浮点数 (long double):
long double(长双精度浮点数)的具体位数和布局取决于平台和编译器实现,主要分为以下几种情况:
| 平台/编译器 | 总位数 | 存储占用 | 符号位 (S) | 指数位 (E) | 尾数位 (M) | 备注 |
|---|---|---|---|---|---|---|
| x86/x64 (GCC) | 80 | 12/16B | 1 | 15 | 64 (63) | 扩展双精度,填充对齐 |
| Windows (MSVC) | 64 | 8B | 1 | 11 | 52 | 等同于 double |
| PowerPC/SPARC | 128 | 16B | 1 | 15 | 112 | 四精度浮点数(罕见) |
3.3 浮点数存储过程
浮点数在计算机中的存储遵循 IEEE 754 标准,该标准定义了浮点数的表示格式和运算规则。以下是浮点数存储的详细过程:
1. 将十进制浮点数转换为二进制浮点数
浮点数在存储前需要先转换为二进制形式。这包括整数部分和小数部分的转换。
-
整数部分转换:将整数部分不断除以 2,取余数,直到商为 0,余数从下往上排列【除基取余,逆序排序】,即为二进制整数部分。
-
示例:将十进制数 56 转换为二进制数。
-
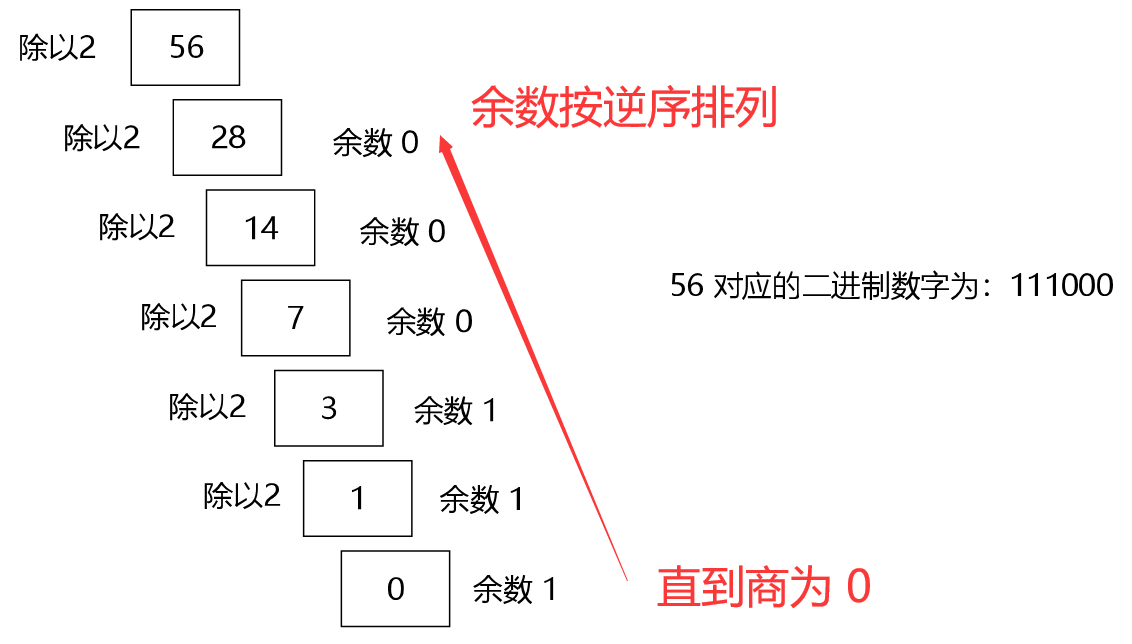
-
小数部分转换:将小数部分不断乘以 2,取整数部分,直到小数部分为 0 或达到所需精度,整数部分从上往下排列【乘基取整,顺序排序】,即为二进制小数部分。
- 示例:十进制 0.625 转二进制。

- 完整示例:将十进制数 12.67 转换为二进制。
- 整数部分12 转换为二进制:1100
- 小数部分 0.67 转换为二进制(近似):0.1010110...(无限循环)
- 因此,12.67 的二进制表示为:1100.1010110...
2. 将二进制浮点数转换为科学计数法形式
将二进制浮点数转换为形如 M × 2^E 的形式,其中:
- M 是尾数(Mantissa)
- E 是指数(Exponent)
步骤:
- 将二进制浮点数的小数点移到第一个 1 的后面,使其成为 1.xxxxxx 的形式。
- 记录移动小数点的位数,作为指数 E。
- 向右移动,E 为负。
- 向左移动,E 为正。
示例:1100.1010110... 转换为科学计数法:
- 移动小数点:1.1001010110... × 2^3
- 因此,M=1.1001010110...,E=3
3. 规格化尾数
在 IEEE 754 标准中,尾数 M 通常规格化为 1 ≤ M < 2 的形式,即:
- 尾数的整数部分为 1(隐含的 1)。
- 实际存储时,只存储小数部分。
示例:
- 规格化后的尾数 M:1.1001010110...
- 存储时只存储小数部分:1001010110...
4. 处理指数
指数 E 通常以偏移二进制的形式存储,以允许表示负指数。
- 偏移量(Bias):
- 单精度 float:偏移量为 127。
- 双精度 double:偏移量为 1023。
- 实际存储的指数值:Estored = E + Bias
- 示例:对于 E=3 和单精度 float:Estored = 3 + 127 = 130,二进制表示:10000010
5. 确定符号位
- 符号位(S):
- 0 表示正数。
- 1 表示负数。
- 示例:对于正数 12.67,符号位 S = 0。
6. 组合成最终的浮点数表示
根据浮点数的类型(单精度或双精度),将符号位(S)、指数位(E)和尾数位(M)组合成一个二进制数。
- 单精度 float(32 位):
- 符号位(S):1 位
- 指数位(E):8 位
- 尾数位(M):23 位
- 双精度 double(64位):
- 符号位(S):1 位
- 指数位(E):11 位
- 尾数位(M):52 位
- 示例:对于 12.67 的单精度表示:
- 符号位 S = 0
- 指数位 E = 10000010
- 尾数位 M = 10010101100110011001101(这里进行了截断和舍入)