Linux运行时的参数、命令、网络、磁盘参数和日志监控
一、监控
1. free
- 功能:用于查看系统内存使用情况,包括物理内存总量、已用内存、空闲内存、缓冲区(buffer)和缓存(cache)占用,以及交换内存(swap)的使用与剩余情况。
- 常见用法:
free -h:以人类可读的格式(如 GB、MB)显示内存信息,便于直观理解。
2. ping
- 功能:通过发送 ICMP(互联网控制消息协议)回显请求数据包到目标主机,测试网络连通性,可获取响应时间、丢包率等信息,判断网络是否通畅。
- 常见用法:
ping www.example.com:测试与指定域名(如www.example.com)的网络连通性。ping -c 4 www.example.com:仅发送 4 个 ICMP 包后停止(-c参数指定包的数量)。
3. vmstat(Virtual Memory Statistics / 虚拟内存统计)
- 功能:实时统计虚拟内存、进程、CPU 等系统资源的使用情况,可用于分析内存瓶颈、进程调度状态及系统整体负载。
- 常见场景:观察内存换页(swap)活动、CPU 空闲时间比例等,判断系统性能是否受内存或 CPU 影响。
4. iostat
- 功能:报告 CPU 统计信息及磁盘、适配器等输入 / 输出设备的性能数据,用于分析存储设备的读写速度、响应时间等。
- 常见用法:
iostat -x:显示更详细的磁盘统计信息,如设备使用率、平均队列长度等。
5. dstat
- 功能:综合显示 CPU、磁盘、网络、内存等资源的使用情况,输出为彩色,相比
vmstat和iostat信息更详细直观,便于快速定位系统瓶颈。 - 优势:一次展示多类资源数据,减少切换不同命令的操作。
6. pidstat
- 功能:监控全部或指定进程占用的系统资源,如 CPU 使用率、内存占用、设备 I/O、任务切换等,精准定位单个进程的资源消耗。
- 常见用法:
pidstat -u 1:每隔 1 秒显示进程的 CPU 使用率(-u表示 CPU 利用率统计)。
7. top
- 功能:动态显示系统综合性能信息,包括系统负载、进程状态、CPU 使用率、内存使用、交换分区等,实时更新数据。
- 特点:是系统管理员查看系统整体运行状态的常用工具,可按资源占用排序进程。
8. iotop
- 功能:实时监控进程的 I/O 使用情况,界面风格类似
top,可直观查看哪些进程在大量读写磁盘。 - 适用场景:排查磁盘 I/O 性能问题,定位 I/O 密集型进程。
9. htop
- 功能:交互式的进程查看器(需
ncurses库支持),相比top界面更直观,支持鼠标操作,可显示进程树、内存 / CPU 使用百分比等。 - 优势:操作更便捷,信息展示更丰富,适合快速浏览进程状态。
10. mpstat
- 功能:报告 CPU 相关统计信息,尤其是多处理器系统中每个 CPU 的使用率、中断率等,用于分析 CPU 负载分布。
- 常见用法:
mpstat -P ALL:显示所有 CPU 的详细统计信息。
11. netstat
- 功能:显示与 IP、TCP、UDP、ICMP 协议相关的统计数据,如网络连接、路由表、端口状态等,用于检查网络连接问题。
- 常见场景:netstat -anop | grep:80 查看端口是否被占用、网络连接是否正常建立。
12. ps
- 功能:静态显示当前进程的状态信息,如进程 ID(PID)、用户、CPU 使用率、内存占用等。
- 常见用法:
ps -aux:以详细格式显示所有进程(a表示所有用户进程,u显示详细用户信息,x包含无控制终端的进程)。
13. strace
- 功能:跟踪程序执行过程中产生的系统调用及接收到的信号,帮助分析程序运行时的行为,排查程序崩溃、异常等问题。
- 示例:
strace -o output.txt ls:将ls命令执行过程中的系统调用记录到output.txt文件。
14. ltrace
- 功能:跟踪进程对库函数的调用情况,显示函数的输入参数、返回值等,用于调试程序对库的使用是否正确。
- 适用场景:分析程序与动态库交互时的问题。
15. uptime
- 功能:显示系统已运行的时间、当前登录用户数,以及 1 分钟、5 分钟、15 分钟内的系统平均负载(负载越高表示系统越繁忙)。
- 输出示例:
14:23:01 up 10 days, 23:50, 2 users, load average: 0.50, 0.60, 0.70。
16. lsof(list open files)
- 功能:列出当前系统中所有打开的文件,包括普通文件、目录、网络套接字等,可查看文件被哪些进程占用,或进程打开了哪些文件。
- 常见用法:
lsof /path/to/file:查看指定文件被哪些进程打开。- lsof -i:80
17. perf
- 功能:Linux 内核自带的性能优化工具,紧密结合内核,可分析热点函数、缓存未命中(cache miss)比率等,帮助开发者优化程序性能。
- 优势:能最先应用内核新特性,精准定位性能瓶颈。
18. tcpdump
- 功能:命令行下的网络抓包工具,可根据协议(如 TCP、UDP)、端口、IP 地址等条件过滤捕获数据包,用于网络流量分析、故障排查。
- 常见用法:
tcpdump -i eth0 port 80:仅捕获网卡eth0上与 80 端口(如 HTTP 协议)相关的流量。
19. btrace
- 功能:动态跟踪 Java 程序,在不修改代码或重启应用的情况下,监控运行时的方法调用、参数、返回值等,用于 Java 程序调试与性能分析。
- 注意:需遵循使用规范,避免影响生产环境中的 Java 应用。
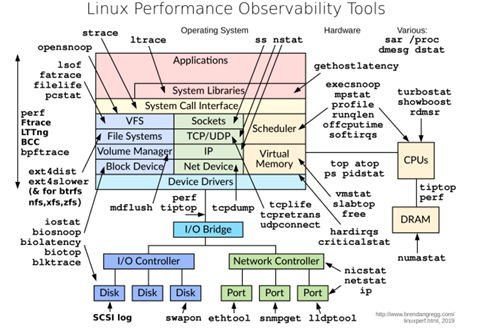
二、测试
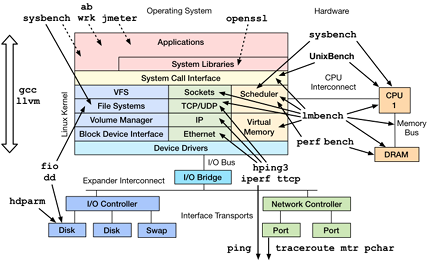
一、sysbench 工具详解及命令示例
sysbench 是一款功能强大的基准测试工具,以下是其支持的性能测试类型、原理及具体命令示例:
1. CPU 性能测试
- 原理:通过让 CPU 执行大量数学运算(如质数计算),测试 CPU 的计算能力。
- 命令示例:
sysbench cpu --cpu-max-prime=20000 run
--cpu-max-prime=20000:设置最大质数计算范围,数值越大,计算量越大。run:执行测试,结束后会输出 CPU 处理耗时、每秒计算次数等指标。2. 磁盘 I/O 性能测试
- 原理:模拟文件读写操作,测试磁盘的读写速度、响应时间等。
- 命令示例(以写测试为例):
# 准备测试文件(先创建 2GB 测试文件) sysbench fileio --file-total-size=2G prepare # 执行写测试 sysbench fileio --file-total-size=2G --file-test-mode=write run # 清理测试文件(避免占用磁盘空间) sysbench fileio --file-total-size=2G cleanup
--file-total-size:指定测试文件总大小。--file-test-mode:支持read(读)、write(写)、rw(读写混合)等模式。3. 调度程序性能测试
- 原理:通过多线程并发执行任务,测试系统对线程的调度能力。
- 命令示例:
sysbench threads --threads=10 --events=1000 run
--threads=10:创建 10 个线程。--events=1000:每个线程执行 1000 个事件,测试线程调度的效率和开销。4. 内存分配及传输速度测试
- 原理:向内存写入数据并读取,测试内存的读写带宽和分配效率。
- 命令示例:
sysbench memory --memory-block-size=1K --memory-total-size=1G run
--memory-block-size=1K:每次操作的内存块大小为 1KB。--memory-total-size=1G:总共操作 1GB 内存,评估内存传输速度。5. POSIX 线程性能测试
- 原理:测试多线程环境下线程的创建、销毁和执行效率。
- 命令示例:
sysbench threads --threads=20 --time=30 run
--threads=20:启动 20 个线程。--time=30:测试持续 30 秒,观察线程在时间内的执行情况。6. 数据库性能(OLTP 基准测试)
- 原理:模拟数据库的联机事务处理(如读、写、更新),测试数据库的并发处理能力。
- 命令示例(以 MySQL 为例):
# 准备测试数据(创建表和插入数据) sysbench oltp_read_write --mysql-host=localhost --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest --tables=10 --table-size=10000 prepare # 执行测试(8 线程并发) sysbench oltp_read_write --mysql-host=localhost --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest --threads=8 run # 清理测试数据 sysbench oltp_read_write --mysql-host=localhost --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest cleanup
--mysql-*:指定数据库连接参数。--tables=10:创建 10 张表。--table-size=10000:每张表插入 10000 条数据。
二、Linux CPU 使用率维度详解
Linux 通过多个维度统计 CPU 使用率,各指标含义及典型场景如下:
指标 含义 示例与场景 %usr 普通进程在用户态下的执行时间占比。 运行 sysbench cpu测试时,top命令中%usr会显著升高。%sys 进程在内核态(系统调用)的执行时间占比。 频繁读写磁盘(如 dd命令)时,系统调用增多,%sys升高。%nice 被调整过优先级( nice值)的进程在用户态的执行时间占比。对某个进程执行 nice -n 10 <command>后,若该进程活跃,%nice会增加。%idle CPU 空闲时间占比。 系统无负载时, %idle接近 100%;若持续低于 20%,可能表示 CPU 过载。%iowait 等待 I/O(如磁盘、网络)完成的时间占比。 用 dd if=/dev/sda of=/dev/null测试磁盘时,若磁盘速度慢,%iowait升高。%irq 处理硬中断(如硬件设备触发的中断)的时间占比。 频繁插拔 USB 设备时, %irq可能短暂升高。%soft 处理软中断(如网络包处理、内核线程调度)的时间占比。 高并发网络请求时, %soft可能升高(如 Web 服务器处理大量 HTTP 包)。%steal 虚拟机被同一宿主机上其他虚拟机占用的 CPU 时间占比(仅虚拟机环境)。 用 vmstat命令查看,若%steal持续高于 10%,说明宿主机资源紧张。
三、优化
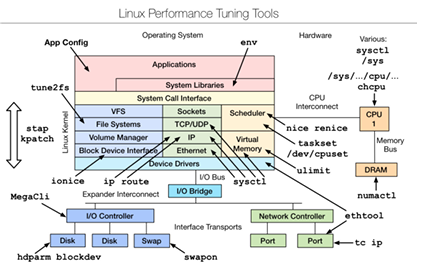
tune2fs(文件系统调优)
- 功能:调整文件系统(如
ext4)的参数,如日志模式、预留空间等。- 示例:查看文件系统参数
tune2fs -l /dev/sda1;调整日志模式为ordered(优化数据完整性与性能):bash
tune2fs -O ^has_journal /dev/sda1 # 先停用日志 mkfs.ext4 -O has_journal,ordered_data /dev/sda1 # 重新启用并设置模式
sysctl(内核参数调优)
- 功能:动态调整内核参数,如网络、内存、进程调度等相关参数。
- 示例:修改 TCP 连接保活时间(减少空闲连接占用资源):
sysctl -w net.ipv4.tcp_keepalive_time=300 # 单位:秒
或永久修改,编辑/etc/sysctl.conf,添加net.ipv4.tcp_keepalive_time = 300,再执行sysctl -p生效。
ionice(IO 优先级调整)
- 功能:调整进程的 IO 调度优先级,避免某些进程占用过多 IO 资源影响系统整体性能。
- 示例:将进程
1234的 IO 调度类设为idle(最低优先级):ionice -c 3 -p 1234
ethtool(网络设备调优)
- 功能:配置网络接口参数,如速率、双工模式、接收缓冲区大小等。
- 示例:将网卡
eth0的速率设为1000M,全双工模式:ethtool -s eth0 speed 1000 duplex full
numactl(NUMA 架构优化)
- 功能:在 NUMA(非统一内存访问)架构下,优化进程对内存的访问,减少跨节点访问延迟。
- 示例:强制进程在本地节点分配内存并运行:
numactl --localalloc --cpunodebind=0 --membind=0 <command>
如numactl --localalloc --cpunodebind=0 --membind=0 mysql -u root -p,优化数据库服务的内存访问。
四、Linux基础命令和工具
1. grep 搜索字符
grep 命令用于在文件中搜索关键词,并显示匹配的结果。以下是部分常用选项及示例:
| 参数 | 作用 |
|---|---|
| -c | 仅显示找到的行数 |
| -i | 忽略大小写 |
| -n | 显示行号 |
| -v | 反向选择 —— 仅列出没有关键词的行(v 是 invert 的缩写) |
| -r | 递归搜索文件目录 |
| -Cn | 打印匹配行的前后 n 行 |
示例:
- 在指定文件查找:
grep login Imfilter.cpp—— 在Imfilter.cpp文件中查找login关键字。 - 多个文件中搜索:
grep login Imfilter.cpp MsgCom.cpp—— 在多个文件中搜索login,可使用通配符(如在.cpp结尾文件中搜索含login的行)。 - 递归搜索目录:
grep -r login msg_server/—— 搜索msg_server目录下所有文件,打印出包含login的行。 - 反向查找:
grep -v CImUser Imfilter.cpp—— 查找文件中不包含CImUser的行。 - 找出并打印行:
grep -w login Imfilter.cpp—— 找出文件中包含login的行并打印。 - 打印行号及前后行:
grep -C 3 -n login Imfilter.cpp—— 找出文件中含login的行,显示行号及前后 3 行。 - 忽略大小写:
grep -C 3 -i -n login Imfilter.cpp—— 找出文件中含login的行,显示行号及前后行,同时忽略大小写。
2. find 查找文件
通过文件名查找文件(支持精确匹配),格式为 find [指定查找目录] [查找规则] [查找后执行的 action]。
常用选项:
find. -name FILE_NAME—— 在当前目录(.)查找名为FILE_NAME的文件。find. -iname FILE_NAME—— 忽略文件名大小写进行查找。find -atime +n/find -atime -n—— 查找n天前或n天内访问过的文件(+表示大于,-表示小于)。find -size +20k/find -size -20k—— 查找大于或小于20k大小的文件。find -type d—— 仅查找目录(d表示目录,f表示文件)。find -amin +10/find -amin -10—— 查找10分钟前或10分钟内访问过的文件。find -cmin +10/find -cmin -10—— 查找10分钟前或10分钟内文件状态修改过的文件。find -mmin +10/find -mmin -10—— 查找10分钟前或10分钟内文件内容修改过的文件。
示例:
find. -name "*password*"—— 查找当前目录(.)下名称中带password的文件。find. -iname "*password*"—— 忽略大小写,查找名称中带password的文件。find. -size +20k -a -size -20M—— 查找大于20k且小于20M的文件。find. -type d -name "mydir"—— 仅查找名为mydir的目录。find. -mmin +10—— 查找10分钟以上未修改过内容的文件。
3. ls 显示文件
-t:可以按重量修改的时间排序,新修改的在前重显示。-lh:以易读格式显示文件的 GB、MB 等(带human)。-R:递归显示。-l:显示类似ll的详细信息。
练习:
ls -t:按最新修改的时间排序,新修改的在前重显示。ls -lhR:按最新修改的时间排序,新修改的在前重显示,并显示子目录的文件信息。
4. wc 行计数
wc命令用于行、字数、字节数计算。利用wc命令可以计算文件的行数、字数,或是字节数。若不加任何文件名,或是所给予的文件名为-,则wc命令会从标准输入设备读取数据。
语法:wc [-cwm][--help][--version][文件...]
参数:
-c/--bytes/--chars:只显示bytes数。-l/--lines:只显示行数。-w/--words:只显示字数。--version:显示版本信息。
练习:
wc testfile:显示testfile文件的行、字、字节信息。7 52 607 testfile:testfile文件的行数为 7、单词数 52、字节数 607。
wc -l testfile:只显示testfile文件的行数。
5. ulimit 用户资源
Linux 系统对每个登录的用户都限制其最大进程数和打开的最大文件句柄数。为了提高性能,可以根据硬件资源的具体情况设置适合每个用户的最大进程数和打开的最大文件句柄数。可以用ulimit -a来显示当前的各种系统对用户使用资源的限制。
[root@localhost ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 11538
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real - time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 65535
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
设置用户的最大进程数:
ulimit -u 1024
设置用户可以打开的最大文件句柄数:
ulimit -n 65535
查看全部资源
ulimit -a
6. curl HTTP 请求
由于当前的线上服务较多地使用了 RESTful 风格的 API,所以集成测试就需要进行 HTTP 调用,查看返回的结果是否符合预期,curl命令当然是首选的测试方法。
使用方式:
curl -i "http://www.sina.com" # 打印请求响应头信息
curl -I "http://www.sina.com" # 仅返回HTTP头
curl -v "http://www.sina.com" # 打印更多的调试信息
curl -verbose "http://www.sina.com" # 同上(-v与-verbose等价)
curl -d 'abc=def' "http://www.sina.com" # 使用POST方法提交数据
curl -sw '%{http_code}' "http://www.sina.com" # 打印HTTP响应码
7. scp 远程拷贝
scp是secure copy的缩写,基于 SSH 协议实现安全的远程文件拷贝,支持本地与远程双向传输,常用于线上问题定位时下载文件或上传修改。
使用方式:
# 安装OpenSSH服务(若未安装)
sudo apt-get install openssh-server # 从远程下载文件到本地
scp username@remote_ip:/path/to/remote/file.txt ./ # 上传本地文件到远程
scp local_file.mp3 username@remote_ip:/path/to/remote/ # 下载远程目录(-r表示递归)
scp -r username@remote_ip:/home/test ./ # 上传本地目录到远程
scp -r local_dir/ username@remote_ip:/home/test/
8. dos2unix 和 unix2dos
用于转换 Windows(CRLF)和 UNIX(LF)的换行符,解决跨系统脚本运行问题。
使用方式:
# 单个文件转换(Windows→UNIX)
dos2unix script.bat # 单个文件转换(UNIX→Windows)
unix2dos config.sh # 批量转换目录下所有文件
find . -type f -exec dos2unix {} \;
find . -type f -exec unix2dos {} \;
9. sed 行处理
sed(Stream Editor)是文本流处理工具,支持基于正则表达式的行过滤、替换、删除等操作,常用于批量修改配置文件或日志处理。
基础格式:
sed [参数] '范围 操作' 文件
核心参数:
-n:静默模式,仅输出处理后的结果-i:直接修改原文件(危险!需谨慎)-e:执行多个编辑命令
范围匹配:
| 示例 | 含义 |
|---|---|
2,5 | 第 2 行到第 5 行 |
/^void/ | 以void开头的行 |
/pattern/,+3 | 匹配行及其后 3 行 |
1~2 | 奇数行(1,3,5...) |
常用操作:
-
打印匹配行
sed -n '2,5p' data.txt # 打印2-5行 sed -n '/ERROR/p' log.txt # 打印包含"ERROR"的行 -
删除匹配行
sed '1d' header.txt # 删除第1行(表头) sed '/^#/d' config.ini # 删除以#开头的注释行 -
替换字符串
命令 含义 sed 's/old/new/' file替换每行中第一个匹配项 sed 's/old/new/g' file替换每行中所有匹配项(g = 全局) sed -i 's/192.168.1.1/10.0.0.1/g' config.xml直接修改文件中的 IP sed 's/[a-z]/& uppercase/g'&代表匹配内容,转为大写 -
高级用法:反向引用与分组
# 将"user:admin"转换为"admin:user" sed 's/\(user\):\(admin\)/\2:\1/' info.txt
示例场景:
- 批量注释配置项:
sed -i 's/^listen_port.*/#&/' /etc/nginx/nginx.conf - 提取日志中的时间戳:
cat access.log | sed -n '/2025-05-16/ s/^\([0-9:]*\).*/\1/p'
10. awk 列处理
awk 是 Linux 中强大的文本分析工具,与 sed 互补:sed 擅长行操作(如替换、删除行),而 awk 擅长列(字段)处理,可按指定分隔符切割文本行,提取、计算或过滤特定列数据。
10.1 核心原理与语法
- 原理:逐行读取文件或输入流,按指定分隔符(默认空格 / 制表符)将每行拆分为多个字段(列),通过字段索引(
$1、$2...)引用列数据,结合条件判断或运算逻辑处理每一行。 - 语法格式:
awk [选项] 'BEGIN{初始化语句} 模式{处理语句} END{结束语句}' 文件名- 选项:
-F:指定字段分隔符,如-F","(逗号分隔)、-F":"(冒号分隔)。
- 三部分逻辑:
- BEGIN:在处理文件前执行(可选),常用于初始化变量、打印表头。
- 模式(Pattern):筛选需要处理的行(可选),可以是条件表达式(如
$2>90)或正则匹配(如/ERROR/)。 - 处理语句(Action):对符合模式的行执行操作,如打印字段、计算、赋值等。
- END:在处理完所有行后执行(可选),常用于输出统计结果。
- 选项:
10.2 基础用法:字段提取与打印
-
默认分隔符(空格 / 制表符):
# 示例:切割字符串并反转列顺序 $ echo "I love you" | awk '{print $3, $2, $1}' you love I- 字符串被空格拆分为 3 列:
$1="I",$2="love",$3="you"。
- 字符串被空格拆分为 3 列:
-
指定分隔符(-F):
# 示例:以点(.)分隔 IP 地址,提取第 2 列(子网部分) $ echo "192.168.1.1" | awk -F "." '{print $2}' 168
10.3 条件过滤与判断语句
-
基于字段值的条件筛选:
# 示例:从成绩文件中筛选第 2 列(语文)≥90 分的行 $ cat score.txt tom 60 60 60 kitty 90 95 87 jack 72 84 99 $ awk '$2>=90 {print $0}' score.txt # $0 表示整行 kitty 90 95 87 -
复合条件与逻辑运算符:
# 示例:筛选语文≥80 且数学≥80 的行 $ awk '$2>=80 && $3>=80 {print $1, "优秀"}' score.txt kitty 优秀 jack 优秀 -
判断语句(if-else):
# 示例:根据成绩输出等级 $ awk '{if($2>=90) print $1, "优秀"; else print $1, "良好"}' score.txt tom 良好 kitty 优秀 jack 良好
10.4 BEGIN 与 END 块的高级应用
-
BEGIN:初始化表头或变量:
# 示例:打印带表头的成绩表,使用 printf 格式化输出 $ awk 'BEGIN{print "姓名 语文 数学 英语"; printf "%-8s %-5d %-5d %-5d\n", "tom", 60, 60, 60}' 姓名 语文 数学 英语 tom 60 60 60%-8s:左对齐,宽度 8 位;%d:整数格式。
-
END:汇总统计结果:
# 示例:计算总成绩和平均分 $ awk ' BEGIN{print "姓名 语文 数学 英语 总成绩"; sum=0; count=0} {total=$2+$3+$4; print $1, $2, $3, $4, total; sum+=total; count++} END{print "---------------------"; printf "平均分: %.2f\n", sum/count} ' score.txt 姓名 语文 数学 英语 总成绩 tom 60 60 60 180 kitty 90 95 87 272 jack 72 84 99 255 --------------------- 平均分: 235.67
10.5 数据计算与数组应用
-
数学运算:
# 示例:将所有成绩乘以 1.2(加分) $ awk '{print $1, $2*1.2, $3*1.2, $4*1.2}' score.txt tom 72 72 72 kitty 108 114 104.4 jack 86.4 100.8 118.8 -
数组统计(按状态分组计数):
# 示例:统计 TCP 连接状态分布(结合 netstat 命令) $ netstat -ant | awk ' BEGIN{print "State\tCount"} # 表头 /^tcp/ {rt[$6]++} # 匹配以 tcp 开头的行,统计第 6 列(状态)的出现次数 END{for(state in rt) print state, rt[state]} # 遍历数组输出结果 ' State Count LISTEN 64 ESTABLISHED 719 TIME_WAIT 146rt[$6]++:以状态($6)为数组键,出现次数为值,自动累加计数。
10.6 实战场景:日志分析与格式化
-
场景:过滤 NGINX 日志中的错误请
# 日志格式:时间 客户端IP 状态码 请求路径 $ cat access.log 2025-05-16 192.168.1.1 404 /error 2025-05-16 192.168.1.2 200 /index 2025-05-16 192.168.1.3 404 /file $ awk '$3>=400 {print "错误请求:", $1, $2, $4}' access.log 错误请求:2025-05-16 192.168.1.1 /error 错误请求:2025-05-16 192.168.1.3 /file -
格式化输出:自动对齐列(配合 column 命令)
$ awk '{print $1, $2, $3}' score.txt | column -t tom 60 60 kitty 90 95 jack 72 84column -t:自动根据内容宽度对齐列,提升可读性。
10.7 注意事项
- 字段索引从 1 开始:
$0:表示整行;$1:第一列;$NF:最后一列(NF是内置变量,代表字段总数)。
- 引号使用:
- awk 脚本需用单引号(
')包裹,避免与 shell 变量冲突;若需嵌套双引号,直接使用即可。
- awk 脚本需用单引号(
- 性能优化:
- 大数据量处理时,避免在
BEGIN/END块中执行复杂操作,优先使用内置函数(如length、substr)。
- 大数据量处理时,避免在
总结:awk 的核心优势
- 列处理高效:通过字段索引直接操作列数据,无需复杂正则匹配。
- 逻辑完整:支持条件判断、循环(
for、while)、数组等编程特性,适合复杂统计。 - 管道友好:可与
grep、sed、sort等工具结合,构建强大的数据处理流水线。
五、CPU性能监控
1. 平均负载和 CPU 使用率
1.1 平均负载基础
定义:
平均负载(Load Average)是指单位时间内系统中处于可运行状态(R 状态)和不可中断状态(D 状态)的平均进程数,反映系统的整体负载压力。
- 可运行状态(R 状态):正在使用 CPU 或等待 CPU 的进程(如计算任务)。
- 不可中断状态(D 状态):正在内核态执行关键操作且不可中断的进程(如等待磁盘 I/O 响应)。
核心理解:
平均负载 ≈ 平均活跃进程数,与 CPU 核心数密切相关。例如:
- 在1 核 CPU系统中,平均负载为 1 表示 CPU 刚好饱和;负载 > 1 表示进程排队等待。
- 在4 核 CPU系统中,平均负载为 4 表示 CPU 饱和,负载 > 4 才意味着排队。
1.2 使用uptime命令分析平均负载
功能:
查看系统运行时间、当前用户数、以及1 分钟 / 5 分钟 / 15 分钟的平均负载,常用于快速判断系统整体状态。
命令输出解析:
[root@ubuntusrc]# uptime
13:01:52 up 46 days, 22:03, 4 users, load average: 0.13, 0.08, 0.05
- 当前时间:13:01:52
- 运行时长:46 天 22 小时 3 分钟
- 在线用户数:4 个(终端连接数)
- 平均负载:
0.13(1 分钟)、0.08(5 分钟)、0.05(15 分钟)
负载值判断(结合 CPU 核数):
- 单核 CPU 参考阈值:
load < 0.7:系统空闲,可部署更多服务。0.7 < load < 1:状态正常。load > 1:开始出现进程等待,需排查原因。load > 5:系统严重繁忙,可能导致性能恶化。
- 多核 CPU 需换算:
若系统为N核,则负载阈值为N。例如 4 核系统中,load=4表示 CPU 饱和,load=8表示负载翻倍。
典型负载趋势分析:
| 1 分钟负载 | 5 分钟负载 | 15 分钟负载 | 含义说明 |
|---|---|---|---|
| >5 | <3 | <1 | 短期抖动,可能是临时任务触发 |
| >5 | >3 | <1 | 中期负载上升,需关注后续趋势 |
| >5 | >5 | >5 | 系统长期繁忙,已出现拥塞 |
| <1 | >3 | >5 | 负载正在下降,系统恢复中 |
示例:
单 CPU 系统中,若负载为1.73(1m)、0.60(5m)、7.98(15m),说明:
- 最近 1 分钟负载偏高(超载 73%),但 15 分钟负载显示之前曾严重超载(698%),当前趋势好转。
1.3 平均负载与 CPU 使用率的区别
| 指标 | 定义 | 影响因素 |
|---|---|---|
| 平均负载 | 单位时间内活跃进程数(可运行 + 不可中断) | CPU 计算、I/O 等待、进程调度队列长度 |
| CPU 使用率 | 单位时间内 CPU 繁忙时间的百分比(用户态 + 内核态 + 空闲等) | CPU 计算密集型任务的比例 |
关键区别:
- I/O 密集型场景:
若大量进程因等待磁盘 I/O 处于 D 状态,平均负载会升高,但 CPU 使用率可能较低(CPU 空闲)。 - CPU 密集型场景:
进程持续占用 CPU(R 状态),平均负载和 CPU 使用率会同步升高。 - 调度队列过长:
若 CPU 核心数不足,大量 R 状态进程排队等待,平均负载和 CPU 使用率均会升高(CPU 忙但无法及时处理所有进程)。
1.4 CPU 使用率监测命令
系统自带工具:
top:动态显示系统整体资源占用,按1可查看各 CPU 核心负载。ps:静态查看进程 CPU 占用,如ps aux | sort -k3nr | head(按 CPU 使用率排序)。
第三方工具(需安装):
# 安装sysstat(包含mpstat/pidstat)和压力测试工具stress
apt install stress sysstat
mpstat:分析多核 CPU 各核心的性能指标。mpstat -P ALL 1 # 每秒输出所有CPU核心的使用率- 输出字段:
%user(用户态)、%system(内核态)、%idle(空闲)等。
- 输出字段:
pidstat:监控指定进程的 CPU 占用。pidstat -u 1 -p <PID> # 每秒查看进程PID的CPU使用情况- 可区分进程在用户态(
%usr)和内核态(%system)的 CPU 消耗。
- 可区分进程在用户态(
压测工具:stress
用于模拟负载场景,验证系统稳定性。
stress --cpu 2 --timeout 60 # 启动2个CPU密集型进程,持续60秒 2. ps 命令:查看进程信息
1. 命令用途
ps 用于显示系统中当前运行的进程信息,支持多种格式和过滤条件,常用于排查进程状态、定位异常程序。
2. 常用选项与参数
| 选项 / 参数 | 说明 |
|---|---|
-ef | 以完整格式显示所有进程(包含其他用户的进程),输出字段包括:UID PID PPID C STIME TTY TIME CMD |
-elf | 长格式显示所有进程,包含更多细节(如优先级、标志位等)。 |
-x | 显示没有控制终端的进程。 |
-p <PID> | 仅显示指定进程 ID(PID)的进程信息。 |
-u <用户> | 显示指定用户的进程。 |
--sort | 按指定键排序(如 --sort=-%cpu 按 CPU 占用降序)。 |
3. 输出字段说明(以 ps -ef 为例)
root@ubuntu:/home/lqf# ps -ef
UID PID PPID C STIME TTY TIME CMD
lqf 44540 3510 0 00:46 ? 00:00:03 /usr/bin/python3 /usr/bin/update-manager --no-update --no-focus-on
- UID:进程所属用户。
- PID:进程 ID(唯一标识)。
- PPID:父进程 ID。
- C:CPU 占用率(百分比)。
- STIME:进程启动时间。
- TTY:进程关联的终端(
?表示无终端)。 - TIME:进程累计运行时间。
- CMD:进程对应的命令或程序路径。
4. 实用技巧与练习
(1)过滤目标进程
# 查找包含 "nginx" 的进程(排除 grep 自身)
ps -ef | grep "nginx" | grep -v grep
(2)统计进程数量
# 统计名为 "java" 的进程数
ps -ef | grep "java" | grep -v grep | wc -l
(3)按 CPU / 内存排序
# 按 CPU 占用降序显示前 5 个进程
ps -ef --sort=-%cpu | head -n 5# 按内存占用降序显示指定用户的进程
ps -u lqf --sort=-%mem
3. top 命令:实时监控进程资源
1. 命令用途
top 用于实时显示系统中进程的资源占用情况(CPU、内存、线程等),支持动态刷新和交互式操作,适合监控系统性能瓶颈。
2. 核心输出解析
top - 15:51:30 up 1 day, 23:45, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 280 total, 1 running, 199 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.4 us, 0.1 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 6143776 total, 1103656 free, 1211704 used, 3828416 buff/cache
KiB Swap: 998396 total, 998384 free, 12 used. 4461984 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 185308 5828 3844 S 0.0 0.1 0:05.00 systemd
- 系统摘要:
- 负载平均值:过去 1/5/15 分钟的系统负载(理想值 < CPU 核心数)。
- 资源统计:
- CPU:
us(用户态)、sy(内核态)、id(空闲)等。 - 内存:总内存、已用、空闲、缓存(
buff/cache)。
- CPU:
- 进程列表:
%CPU:进程占用 CPU 百分比。%MEM:进程占用物理内存百分比。COMMAND:进程对应的命令(可按F键自定义显示列)。
3. 交互式快捷键
| 快捷键 | 功能描述 |
|---|---|
t | 切换 CPU 状态显示(进程树与 CPU 利用率分层)。 |
m | 切换内存使用显示(按内存占用排序)。 |
r | 调整进程优先级(输入 PID 和优先级值,值越小优先级越高)。 |
k | 终止进程(输入 PID,默认发送 SIGTERM 信号,可改用 9 强制终止)。 |
s | 修改刷新间隔(如输入 5 设为每 5 秒刷新一次)。 |
u | 过滤显示指定用户的进程(输入用户名,如 lqf)。 |
q | 退出 top 界面。 |
4. 实用练习
(1)查找高 CPU 占用进程
top -o %CPU # 按 CPU 占用降序排序,实时监控
(2)查看进程下的线程
top -Hp <PID> # 例如:top -Hp 57009 查看 PID 为 57009 的进程的所有线程
(3)定位内存占用异常进程
top -o %MEM # 按内存占用降序排序,识别占用过高的进程4. mpstat 命令:CPU 性能分析
1. 命令用途
mpstat 用于实时监控系统 CPU 的统计信息,支持多核 CPU 环境,可查看全局或单个 CPU 核心的使用情况,数据来源于 /proc/stat。
核心场景:
- 分析 CPU 利用率(用户态、内核态、空闲等)。
- 定位 CPU 瓶颈,如高 I/O 等待(
%iowait)或中断负载(%irq/%soft)。
2. 语法格式
mpstat [-P {ALL | CPU列表}] [interval [count]]
-P:指定监控的 CPU(ALL表示所有核心,CPU列表如0,1,2或ALL)。interval:采样间隔时间(秒)。count:采样次数(可选,默认无限次,直到手动终止)。
3. 关键参数说明
| 参数 | 描述 |
|---|---|
%usr | 用户态程序占用 CPU 百分比(不包含 nice 进程)。 |
%sys | 内核态程序占用 CPU 百分比。 |
%iowait | CPU 等待磁盘 I/O 的时间百分比(值过高可能表示磁盘瓶颈)。 |
%irq/%soft | 硬中断 / 软中断占用 CPU 百分比(反映硬件或软件中断处理负载)。 |
%idle | CPU 空闲百分比(理想值越高越好,过低表示 CPU 繁忙)。 |
4. 输出示例与解析
# 每 5 秒监控所有 CPU 核心,共采样 2 次
mpstat -P ALL 5 2
Linux 3.10.0-957.5.1.el7.x86_64 (VM_0_ubuntu) 08/22/2019 x86_64 (4 CPU)
05:04:39 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
05:04:44 PM all 1.41 0.00 1.21 3.42 0.00 0.00 0.00 0.00 0.00 93.96 # 所有 CPU 平均值
05:04:44 PM 0 1.41 0.00 1.21 3.42 0.00 0.00 0.00 0.00 0.00 93.96 # CPU 0 核心数据
05:04:49 PM all 1.21 0.00 0.80 3.02 0.00 0.00 0.00 0.00 0.00 94.97 # 下一个采样周期数据
CPU:all表示全局平均值,0/1/2/3表示具体 CPU 核心编号。%iowait高:可能存在磁盘性能瓶颈(如大量文件读写)。%usr/%sys高:用户态或内核态程序占用过高(如计算密集型任务)。
5. 实用示例
- 查看单个 CPU 核心(如 CPU 0)的实时数据:
mpstat -P 0 2 - 监控系统启动以来的 CPU 平均利用率:
mpstat # 不带参数,输出全局平均值 - 定位高 I/O 等待场景:
mpstat -P ALL 5 | grep -v "Average" # 实时观察 %iowait 变化
5. pidstat 命令:进程级资源监控
1. 命令用途
pidstat 用于监控指定进程的详细资源占用情况,包括 CPU、内存、磁盘 I/O、上下文切换 等,支持按线程或进程维度统计。
核心场景:
- 定位单个进程的资源瓶颈(如某进程占用过高 CPU 或内存)。
- 分析进程的磁盘读写行为或上下文切换频率。
2. 语法格式
pidstat [选项] [interval [count]] -p <PID>
- 常用选项:
选项 描述 -u监控 CPU 使用率(默认选项)。 -r监控内存使用(虚拟内存、物理内存、缺页错误等)。 -d监控磁盘 I/O 读写速率(kB/s)。 -w监控上下文切换次数(自愿 / 非自愿)。 -t按线程维度监控(默认监控进程,需与 -w等选项结合)。-p指定进程 ID( PID),多个 PID 用逗号分隔(如-p 1234,5678)。
3. 关键输出解析
(1)CPU 监控(-u)
pidstat -u -p 24615 5
03:48:12 PM UID PID %usr %system %guest %CPU CPU Command
03:48:17 PM 0 24615 5.00 2.00 0.00 7.00 0 nginx
%CPU:进程占用 CPU 的总百分比(多核场景下可能超过 100%)。CPU:进程当前绑定的 CPU 核心编号(用于排查 CPU 亲和性问题)。
(2)内存监控(-r)
pidstat -r -p 24615 5
03:48:12 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
03:48:17 PM 0 24615 2.00 0.00 582520 24940 1.32 nginx
minflt/s:每秒次缺页错误(内存地址映射正常,性能影响小)。majflt/s:每秒主缺页错误(需从磁盘读取数据,性能影响大)。RSS:进程占用的物理内存大小(KB)。
(3)磁盘 I/O 监控(-d)
pidstat -d -p 24615 5
03:48:12 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:48:17 PM 0 24615 100.00 50.00 0.00 nginx
kB_rd/s:进程每秒从磁盘读取的数据量。kB_wr/s:进程每秒写入磁盘的数据量。
(4)上下文切换监控(-w)
pidstat -w -p 24615 5
03:48:12 PM UID PID cswch/s nvcswch/s Command
03:48:17 PM 0 24615 5.00 2.00 nginx
cswch/s:每秒自愿上下文切换次数(因资源等待,如 I/O)。nvcswch/s:每秒非自愿上下文切换次数(因 CPU 竞争)。
4. 场景实战
场景一:CPU 密集型进程排查
- 模拟 CPU 压力:
stress --cpu 1 --timeout 600 # 启动一个 CPU 使用率 100% 的进程 - 监控 CPU 占用:
pidstat -u 5 1 # 每 5 秒采样一次,查看具体进程的 %CPU- 输出中
%CPU接近 100% 的进程即为目标进程。
- 输出中
场景二:高 I/O 等待分析
- 模拟磁盘压力:
stress -i 1 --timeout 600 # 启动一个 I/O 密集型进程 - 监控磁盘读写:
pidstat -d 5 | grep "kB_rd/s\|kB_wr/s" # 过滤出 I/O 相关字段- 观察
kB_rd/s或kB_wr/s异常高的进程。
- 观察
场景三:上下文切换分析
- 模拟多进程竞争:
stress --cpu 8 --timeout 600 # 启动 8 个进程竞争 4 核 CPU - 监控上下文切换:
pidstat -w 5 # 观察 cswch/s 和 nvcswch/s 是否显著升高- 高 cswch/s:可能存在资源等待(如锁竞争、I/O 阻塞)。
- 高 nvcswch/s:可能 CPU 资源不足,进程频繁被调度。
6. 使用 vmstat 监控系统级切换
1. 命令用途
vmstat 用于实时监控系统的 进程状态、内存、磁盘 I/O、中断、上下文切换 等核心指标,尤其适合分析上下文切换的整体趋势。
2. 语法格式
vmstat [options] [delay [count]]
delay:采样间隔时间(秒)。count:采样次数(可选,默认持续输出直到终止)。
3. 关键输出字段(与上下文切换相关)
vmstat 1 # 每秒输出一组数据
| 列名 | 描述 |
|---|---|
r | 就绪队列长度(等待 CPU 的进程 / 线程数)。值过高表示 CPU 竞争激烈。 |
b | 阻塞队列长度(处于不可中断睡眠的进程数,通常与磁盘 I/O 相关)。 |
in | 每秒中断次数(包括硬中断和软中断)。 |
cs | 每秒上下文切换次数(核心指标),包括自愿和非自愿切换的总和。 |
us | 用户态 CPU 使用率(%)。 |
sy | 内核态 CPU 使用率(%)。上下文切换主要消耗内核态时间。 |
4. 示例分析
空闲系统状态
vmstat 1 1 # 间隔 1 秒,采样 1 次
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 12 1173896 470200 3318136 0 0 6 20 49 74 0 0 99 0 0
cs:约 49 次 / 秒(正常空闲状态下切换次数较低)。r:0,表示无等待 CPU 的进程。
压力测试状态(模拟多线程切换)
sysbench --num-threads=10 --max-time=300 test=threads run # 启动 10 个线程压测
vmstat 1 # 实时监控
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa st
8 0 206356 67344 548612 0 0 0 0 1700 1493243 8 93 0 0 0 0 0
cs:飙升至约 149 万次 / 秒(上下文切换激增)。r:8(就绪队列长度远超 CPU 核心数,导致竞争)。sy:93%(内核态 CPU 使用率极高,主要用于处理切换)。
7. 使用 pidstat 定位进程 / 线程级切换
1. 命令用途
vmstat 提供系统整体切换次数,而 pidstat 可深入到 进程或线程级别,区分自愿(cswch/s)和非自愿(nvcswch/s)切换。
2. 关键选项
| 选项 | 描述 |
|---|---|
-w | 输出上下文切换指标(默认显示进程级数据)。 |
-t | 按线程维度输出(需与 -w 结合,否则仅显示进程数据)。 |
-p | 指定进程 ID(PID),或 -p ALL 监控所有进程。 |
3. 示例分析
进程级切换(默认)
pidstat -w -p <PID> 1 # 监控指定进程的上下文切换
08:14:05 UID PID cswch/s nvcswch/s Command
08:14:05 0 10551 6.00 0.00 sysbench # 主线程切换次数低
线程级切换(加 -t 参数)
pidstat -wt -p <PID> 1 # 监控进程下所有线程的切换
08:14:05 UID TGID TID cswch/s nvcswch/s Command
08:14:05 0 10551 - 6.00 0.00 sysbench # 主线程
08:14:05 0 - 10552 18911.00 103740.00 |__sysbench # 子线程 1
08:14:05 0 - 10553 18915.00 100955.00 |__sysbench # 子线程 2
cswch/s:自愿切换次数(子线程因资源等待频繁切换)。nvcswch/s:非自愿切换次数(子线程因 CPU 竞争被强制调度)。
如何判断是否正常?
1. 经验阈值
- 正常范围:
- 系统级切换次数:数百到 1 万次 / 秒 以内通常正常(取决于 CPU 性能)。
- 单线程切换次数:数千次 / 秒可能正常,但需结合业务场景。
- 异常特征:
- 切换次数突然飙升(如从几十到百万级)。
r队列长度持续大于 CPU 核心数(表示 CPU 资源不足)。sy使用率超过 30%(内核态消耗过高,可能由切换引起)。
2. 问题定位逻辑
- 系统级分析:
- 若
cs高且r大 → CPU 竞争导致非自愿切换(需优化 CPU 资源或减少线程数)。 - 若
cs高但r小 → 自愿切换为主(可能是 I/O 阻塞或锁竞争)。
- 若
- 进程 / 线程级分析:
- 用
pidstat -wt找出cswch/s或nvcswch/s异常高的线程。 - 结合业务逻辑,排查线程是否在等待 I/O、持有锁时间过长,或线程数过多。
- 用
实战案例:多线程切换导致性能下降
1. 模拟场景
- 目标:通过
sysbench启动 10 个线程,模拟高并发调度。 - 步骤:
- 启动压测:
sysbench --num-threads=10 --max-time=300 test=threads run - 监控系统级切换:
vmstat 1 # 观察到 `cs` 飙升至百万级,`r`=8,`sy`=93% - 定位线程级问题:
pidstat -wt 1 # 发现子线程的 `nvcswch/s` 高达 10万次/秒
- 启动压测:
2. 结论
- 过多线程(10 个)竞争有限 CPU 核心(假设 2 核),导致大量非自愿上下文切换,内核态 CPU 使用率激增,系统性能下降。
- 优化方向:减少线程数,或通过 CPU 亲和性绑定线程到特定核心,降低调度压力。
8. 遇到CPU利用率高该如何排查
遇到CPU使用率高时,首先确认CPU是消耗在哪一块,如果是内核态占用CPU较高:
1. %iowait 高,这时要重点关注磁盘IO的相关操作,是否存在不合理的写日志操作,数据库操作等;
2. %soft或%cs 高,观察CPU负载是否较高、网卡流量是否较大,可不可以精简数据、代码在是否在 多线程操作上存在不合适的中断操作等;
3. %steal 高,这种情况一般发生在虚拟机上,这时要查看宿主机是否资源超限; 如果是用户态较高,且没有达到预期的性能,说明应用程序需要优化
8.1 根据指标查找工具
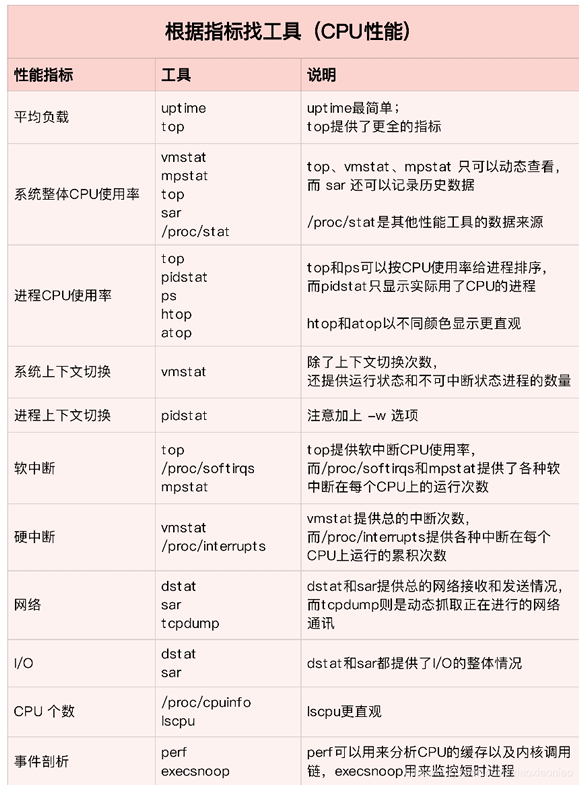
8.2 根据工具查指标

六、内存性能监控
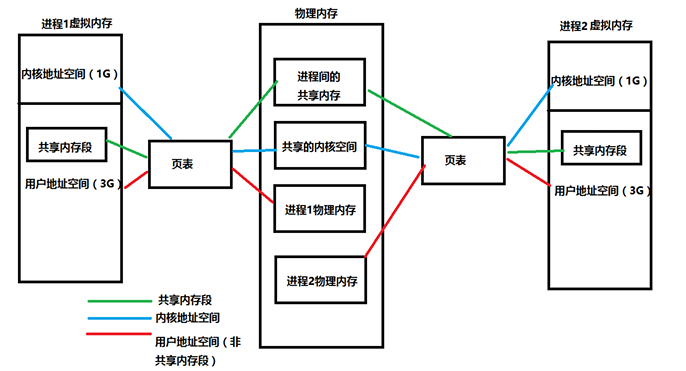
1. 内存是什么-虚拟内存和物理内存
操作系统有虚拟内存与物理内存的概念。在很久以前,还没有虚拟内存概念的时候,程序寻址用的都是物理地址。程序能寻址的范围是有限的,这取决于 CPU 的地址线条数。比如在 32 位平台下,寻址的范围是 232 也就是 4G,并且这是固定的。如果没有虚拟内存,且每次开启一个进程都给 4G 的物理内存,就可能会出现很多问题:
- 因为物理内存有时有限,当有多个进程执行的时候,都要给 4G 内存,很显然内存小一点,很快就分配完了,于是没有得到分配资源的进程就只能等待。当一个进程执行完了以后,再将等待的进程装入内存。这种频繁的装入内存的操作是很没效率的。
- 由于指令都是直接访问物理内存的,那么这个进程就可以修改其他进程的数据,甚至会修改内核地址空间的数据,这是我们不想看到的。
- 因为内存是随机分配的,所以程序运行的地址也是不正确的。
一个进程运行时都会得到 4G 的虚拟内存。这个虚拟内存你可以认为,每个进程都认为自己拥有 4G 的空间,这只是每个进程认为的,但是实际上,在虚拟内存对应的物理内存上,可能只对应的一点点的物理内存,实际用了多少内存,就会对应多少物理内存。进程得到的这 4G 虚拟内存是一个连续的地址空间(这也只是进程认为),而实际上,它通常是被分隔成多个物理内存碎片,还有一部分存储在外部磁盘存储器上,在需要时进行数据交换。
进程开始访问一个地址,它可能会经历下面的过程:
- 每次我要访问地址空间上的某一个地址,都需要把地址翻译为实际物理内存地址。
- 所有进程共享这一整块物理内存,每个进程只把自己目前需要的虚拟地址空间映射到物理内存上。
- 进程需要知道哪些地址空间上的数据在物理内存上,哪些不在(可能这部分存储在磁盘上),还有在物理内存上的哪里,这就需要通过页表来记录。
- 页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)。
- 当进程访问某个虚拟地址的时候,就会先去看页表,如果发现对应的数据不在物理内存上,就会发生缺页异常。
- 缺页异常的处理过程,操作系统立即阻塞该进程,并将硬盘里对应的页换入内存,然后使该进程继续,如果内存已经满了,没有空地方了,那就找一个页覆盖,至于具体覆盖哪个页,就需要看操作系统的页面置换算法是怎么设计的了。
虚拟内存与物理内存的联系:
页表工作原理:
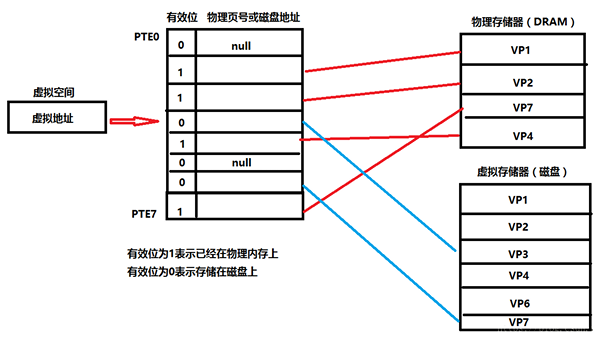
- 我们的 cpu 想访问虚拟地址所存的虚拟页 (VP3),根据页表,找出页表中第三条的值,判断有效位。如果有效位为 1,DRMA 缓存命中,根据物理页号,找到物理页当中的内容,返回。
- 若有效位为 0,参数缺页异常,调用内核缺页异常处理程序。内核通过页面置换算法选择一个页面作为被覆盖的页面,将该页的内容刷新到磁盘空间当中,然后把 VP3 映射的磁盘文件缓存到该物理页面上。然后页表中第三条,有效位变 1,第二部分存储上了可以对应物理内存页的地址的内容。
- 缺页异常处理完毕后,返回中断前的指令,重新执行,此时缓存命中,执行 1。
- 将找到的内容映射到告诉缓存当中,CPU 从告诉缓存中获取该值,结束。
当每个进程创建的时候,内核会为进程分配 4G 的虚拟内存,当进程还没有开始运行时,这只是一个内存布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码 (比如.text,.data 段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射)。这个时候数据和代码还是在磁盘上的,当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存上,而是在磁盘上,于是发生缺页异常,于是将磁盘上的数据拷贝到物理内存中。
另外在进程运行过程中,要通过 malloc 来动态分配内存时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。可以认为虚拟空间都被映射到了磁盘空间中(事实上也是按需要映射到磁盘空间,通过 mmap,mmap 是用来建立虚拟空间和磁盘空间的映射关系的)
2. I/O 的两种方式(缓存 I/O 和直接 I/O)
1. 缓存 I/O(标准 I/O)
定义:数据先经内核空间缓冲区中转,再在用户空间和磁盘间传输。
流程:
- 读操作:
- 检查内核缓冲区是否有数据,有则直接复制到用户空间;
- 无则从磁盘读取数据到内核缓冲区,再复制到用户空间。
- 写操作:
数据从用户空间复制到内核缓冲区即视为 “完成”,实际写入磁盘由系统异步处理(可通过sync强制同步)。
优点:
- 隔离用户空间与内核空间,提升系统安全性;
- 利用内核缓冲区减少磁盘 I/O 次数,提升性能。
缺点:
- 数据需在用户空间和内核空间间多次拷贝(如读操作需两次拷贝:磁盘→内核缓冲区→用户空间),增加 CPU 和内存开销;
- 依赖内核缓冲区,无法直接控制数据缓存策略(如数据库场景)。
应用场景:
- 通用文件读写(如文本文件、日志文件);
- 对实时性要求不高的场景(如普通文件写入)。
2. 直接 I/O(Direct I/O)
定义:应用程序直接访问磁盘,绕过内核缓冲区。
流程:
数据直接在用户空间和磁盘间传输,无需经过内核缓冲区(需用户程序自行管理缓存)。
优点:
- 减少数据拷贝次数(仅一次:磁盘→用户空间 或 用户空间→磁盘),降低 CPU 开销;
- 允许应用程序自定义缓存策略(如数据库可实现更高效的缓存机制)。
缺点:
- 失去内核缓冲区的缓存优化,频繁 I/O 可能导致性能下降;
- 需应用程序自行处理 I/O 同步和错误处理,复杂度增加。
应用场景:
- 数据库系统(如 MySQL、PostgreSQL,需自定义缓存);
- 高性能计算(HPC)、实时数据处理等对 I/O 延迟敏感的场景。
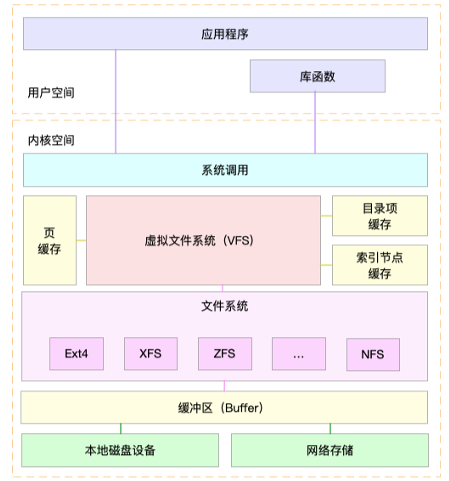
3. 监控磁盘 I/O 的命令
1. iostat:统计 I/O 状态
功能:监控 CPU 利用率、磁盘 I/O 速率、队列长度等核心指标。
常用参数:
| 参数 | 说明 |
|---|---|
-c | 仅输出 CPU 统计信息 |
-d | 仅输出磁盘统计信息(默认同时输出 CPU 和磁盘信息) |
-k -m | 以 KB/s 或 MB/s 为单位显示数据传输速率,替代默认的 “块 /s” |
-t | 输出结果时显示时间戳 |
-x | 输出详细扩展信息(如等待时间、队列长度、设备利用率等) |
interval | 统计间隔时间(单位:秒) |
count | 统计次数(可选,默认持续输出) |
关键指标解释:
| 字段 | 含义 |
|---|---|
rrqm/s | 每秒合并的读请求数(文件系统合并同块读取请求) |
wrqm/s | 每秒合并的写请求数 |
r/s /w/s | 每秒完成的读 / 写次数 |
rkB/s /wkB/s | 每秒读 / 写数据量(KB 为单位) |
avgrq-sz | 平均每次 I/O 操作的数据量(扇区数) |
avgqu-sz | 平均等待处理的 I/O 请求队列长度(值越高,队列积压越严重) |
await | 平均每次 I/O 请求的等待时间(包括队列等待和处理时间,ms) |
svctm | 平均每次 I/O 请求的处理时间(ms,理想情况下应接近 await) |
%util | 设备繁忙率(周期内 I/O 非空闲时间的比例,长期高于 70% 可能存在瓶颈) |
示例命令:
# 以 KB/s 显示磁盘统计信息,每 2 秒刷新一次
iostat -d -k 2 # 显示磁盘详细扩展信息,每秒刷新一次,共刷新 10 次
iostat -dkx 1 10 # 分析 await 与 svctm:若 await >> svctm,说明队列等待时间长,磁盘可能存在性能问题
输出示例:
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 5.00 0.00 80.00 32.00 0.00 2.00 2.00 1.00
2. swapon:查看交换分区使用情况
功能:显示系统交换分区(Swap)的使用状态。
命令示例:
# 查看交换分区详细信息(类型、大小、已用空间等)
swapon -s
输出示例:
Filename Type Size Used Priority
/var/swap file 8192M 472M -2
3. df:查看文件系统磁盘占用
功能:统计文件系统的磁盘空间使用情况(挂载点、总容量、已用空间等)。
常用参数:
-h:以人类可读格式(如 GB、MB)显示。
命令示例:
# 以易读格式显示所有文件系统的磁盘使用情况
df -h
输出示例:
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 50G 42G 5.6G 89% /
tmpfs 920M 24K 920M 1% /dev/shm
4. du:统计目录 / 文件大小
功能:递归计算目录或文件的磁盘占用空间。
常用参数:
| 参数 | 说明 |
|---|---|
-h | 以人类可读格式显示(如 KB、MB) |
-a | 显示目录下所有文件和子目录的大小 |
-s | 仅显示目录总大小(不显示子项) |
-c | 显示各项目大小并统计总和 |
--max-depth=1 | 仅显示当前目录下一级子项的大小 |
命令示例:
# 查看当前目录下所有文件和子目录的大小(易读格式)
du -ha # 查看 home 目录总大小(易读格式)
du -sh home # 查看当前目录下一级子目录的大小
du -lh --max-depth=1
输出示例:
6.1M ./php
11M ./ios
146M ./server
总结对比
| 场景 | 推荐工具 | 核心指标 / 参数 |
|---|---|---|
| 磁盘 I/O 性能分析 | iostat -x | await、svctm、%util、avgqu-sz |
| 交换分区状态查询 | swapon -s | 已用空间(Used)、分区路径 |
| 磁盘空间占用统计 | df -h / du -h | 挂载点、目录大小、使用率(Use%) |
| 目录层级大小分析 | du --max-depth=1 -h | 子目录大小、总和 |
七、网络IO性能监控
一、网络性能核心指标
1. 带宽(Bandwidth)
- 定义:链路的最大理论传输速率(物理极限),单位为
b/s(比特 / 秒)。
- 例:100M 带宽表示每秒最多传输 100×10^6 比特。
- 作用:衡量链路的 “最大能力”,是吞吐量的上限。
2. 吞吐量(Throughput)
- 定义:单位时间内实际成功传输的数据量,单位为
b/s或B/s(字节 / 秒)。
- 公式:吞吐量 = 实际传输速率,受带宽、网络拥塞、协议开销等影响。
- 使用率 = 吞吐量 / 带宽,反映链路利用率(如 80% 使用率可能导致拥塞)。
3. 延时(Latency)
- 定义:数据从发送到接收的时间延迟,常见场景包括:
- RTT(往返时间):数据包往返一次的时间(如 ping 的
time值)。- TCP 握手延时:建立连接的耗时(三次握手的 RTT)。
- 影响因素:物理距离、路由跳数、设备处理速度、网络拥塞。
4. PPS(Packet Per Second,包 / 秒)
- 定义:每秒传输的数据包数量,衡量网络设备(如交换机、路由器)的转发能力。
- 特点:
- 硬件交换机通常支持线性转发(接近理论最大值)。
- Linux 服务器受数据包大小影响(小包转发压力更大,如 64B 小包 vs 1500B 大包)。
5. 其他重要指标
- 丢包率:丢失数据包占总发送包的比例(常见于拥塞、硬件故障)。
- 重传率:因丢包等原因重新传输的数据包比例(TCP 重传影响性能)。
- 并发连接数:同时存在的 TCP 连接数量(高并发可能耗尽服务器资源)。
- 可用性:网络正常通信的时间比例(如 99.99% 可用性要求)。
二、网络信息查看工具与实战
1. 网络配置:
ifconfigvsip
- 作用:查看 / 配置网络接口参数(IP、MAC、MTU、收发统计等)。
- 区别:
ifconfig属于net-tools包(传统工具,部分系统默认安装)。ip属于iproute2包(新一代工具,功能更强大)。- 关键输出解读(以
ip addr show为例):2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> # 接口状态(UP+LOWER_UP 表示物理连通)mtu 1500 # MTU 值(默认 1500,叠加网络如 VXLAN 需调小至 1450 左右)inet 192.168.206.134/24 # IP 地址和子网掩码link/ether 00:0c:29:11:82:79 # MAC 地址RX: bytes 35667821 packets 48505 errors 0 dropped 0 # 接收统计(errors/dropped/overruns 非零表示异常)TX: bytes 8831315 packets 124236 errors 0 dropped 0 # 发送统计- 异常指标含义:
errors:校验错误、物理层问题(如电缆故障)。dropped:内核因内存不足丢弃数据包(需检查内存或队列长度)。overruns:接口接收速度超过 CPU 处理能力(优化驱动或硬件)。2. 套接字信息:
netstatvsss
- 作用:查看网络连接、监听端口、进程关联等。
- 区别:
ss比netstat更快,推荐优先使用。- 关键参数与输出:
ss -ltnp # 查看 TCP 监听端口(-l=监听,-t=TCP,-n=数字端口,-p=进程) State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 0.0.0.0:80 *:* users:(("nginx",pid=1234,fd=4))
- 监听状态:
Recv-Q:全连接队列已积压的连接数(超过该值会导致连接失败)。Send-Q:全连接队列的最大长度(由somaxconn和backlog控制)。- 连接状态:
Recv-Q:应用程序未读取的接收缓冲区数据(非零表示处理慢)。Send-Q:未被对端确认的发送数据(非零可能因网络延迟或拥塞)。3. 协议栈统计:
netstat -s/ss -s
- 作用:查看 TCP/UDP/IP 协议的全局统计(如连接数、重传次数、分片情况)。
- 示例输出:
netstat -s | grep TCP # 查看 TCP 相关统计 1234 active TCP connections established # 主动建立的连接数 567 retransmissions # TCP 重传次数(高值可能因丢包)- 用途:快速定位协议层问题(如重传率高提示网络不稳定)。
4. 网络吞吐监控:
sar -n DEV
- 作用:实时监控网络接口的流量和 PPS,定位吞吐量瓶颈。
- 关键参数:
sar -n DEV 1 # 每秒采样一次,显示接口流量 IFACE rxpck/s txpck/s rxkB/s txkB/s %ifutil # 指标含义:
rxpck/s/txpck/s:接收 / 发送的 PPS(包 / 秒)。rxkB/s/txkB/s:接收 / 发送的吞吐量(KB / 秒)。%ifutil:接口利用率(全双工模式取收 / 发最大值与带宽的比值)。- 示例场景:若
%ifutil接近 100%,说明接口带宽不足,需扩容或优化流量。5. 连通性与延时测试:
ping
- 作用:测试主机间连通性,测量 RTT 和丢包率。
- 常用参数:
ping -c 5 -s 1024 baidu.com # 发送 5 个 1024B 的包(默认 56B+28B 包头=84B)- 输出解读:
64 bytes from 220.181.38.251: icmp_seq=1 ttl=128 time=32.0 ms # time=RTT --- baidu.com ping statistics --- 5 packets transmitted, 5 received, 0% packet loss # 丢包率 rtt min/avg/max/mdev = 31.7/32.7/34.3/1.15 ms # 延时分布- 注意:
TTL可判断操作系统类型(如 Linux TTL 通常为 64,Windows 为 128)。- 大尺寸包(如
-s 1472)可测试 MTU 适配性(超过 MTU 会分片,影响性能)。
三、典型故障排查思路
场景 1:网络延迟高
- 第一步:
ping测试 RTT 和丢包率,确认是否为链路问题。- 第二步:
sar -n DEV查看接口利用率,若%ifutil高,检查带宽瓶颈。- 第三步:
ss查看套接字队列(Recv-Q/Send-Q 非零),判断是否为应用处理慢或网络拥塞。场景 2:丢包率高
- 检查接口统计:
ip -s addr show查看errors/dropped/overruns是否非零,定位物理层或驱动问题。- 协议栈分析:
netstat -s查看 TCP 重传次数,若高则可能为网络拥塞或路由不稳定。- 硬件排查:检查网线、交换机端口、服务器网卡是否存在故障(如双工模式不匹配导致
carrier错误)。场景 3:连接建立失败
- 查看监听状态:
ss -ltnp确认端口是否正确监听,全连接队列(Send-Q)是否已满(调大somaxconn)。- 防火墙检查:确认
iptables/firewalld是否放行端口。- 半连接问题:若大量
SYN_RECV状态,可能为 SYN Flood 攻击(启用 TCP SYN Cookie 或增加半连接队列长度)。
四、其他常用网络相关命令
1.
telnet:远程登录与端口测试
- 功能:用于远程登录到主机(明文传输),也可测试目标端口是否开放(TCP)。
- 语法:
telnet [IP/域名] [端口]- 示例:
telnet 192.168.1.100 22 # 测试 SSH 端口连通性 telnet www.baidu.com 80 # 测试 HTTP 端口(可配合 `tcpdump` 抓包)- 与
ssh区别:
- 端口:
telnet默认 23 端口,ssh默认 22 端口。- 安全性:
telnet明文传输,ssh加密传输。2.
nc(NetCat):网络调试瑞士军刀
- 功能:通过 TCP/UDP 传输数据,用于端口检测、文件传输、网速测试等。
- 常用参数:
参数 说明 -l监听模式(作为服务器) -u使用 UDP 协议(默认 TCP) -v显示详细交互信息 -w <秒数>超时时间 -s <IP>指定源 IP(多网卡场景) - 示例:
nc -l 9999 # 监听本地 9999 端口(TCP),等待客户端连接 nc -ul 12345 # 监听 UDP 12345 端口 nc -vw 2 192.168.1.1 80 # 测试目标 80 端口是否开放(超时 2 秒) nc 192.168.1.2 9999 < test.txt # 向目标端口发送文件内容 nc -l 9999 > recv.file # 接收数据并保存为文件- 应用场景:
- 检测防火墙规则(端口是否被封禁)。
- 模拟网络流量(测试带宽,配合
sar监控)。3.
mtr:连通性与丢包率测试
- 功能:结合
ping和traceroute,实时显示路由路径及每跳的丢包率、延迟。- 语法:
mtr [选项] [IP/域名]- 常用参数:
-c <次数>:指定测试次数。-r:显示路由信息。- 示例:
mtr baidu.com # 实时监控到百度的连通性和丢包率 mtr -c 10 192.168.1.100 # 发送 10 次测试包并退出- 关键指标:
- 第 2 列(% Loss):每跳的丢包率(理想值为 0%)。
- Time:每跳的延迟(ms)。
4.
nslookup:DNS 解析测试
- 功能:查询域名对应的 IP 地址,检测 DNS 服务器是否正常工作。
- 语法:
nslookup [域名] [DNS服务器](可选指定 DNS 服务器)- 示例:
nslookup www.0voice.com # 查询域名解析结果 nslookup baidu.com 8.8.8.8 # 使用 Google DNS 解析- 输出解读:
Server:使用的 DNS 服务器地址。Address:域名对应的 IP 地址。5.
traceroute:路由路径追踪
- 功能:显示数据包从本地到目标主机的路由路径及每跳延迟。
- 语法:
traceroute [IP/域名]- 示例:
traceroute sina.com # 追踪到新浪服务器的路由路径 traceroute -I 192.168.1.100 # 使用 ICMP 协议追踪(部分防火墙可能屏蔽)- 输出说明:
- 每行代表一个路由节点,包含 IP 地址和三次延迟测试值(ms)。
*表示该节点无响应(可能因防火墙过滤)。6.
iptraf:实时网络流量监控
- 功能:交互式实时监控网络流量,显示 TCP 连接、接口、协议、端口等信息。
- 安装:
# Ubuntu sudo apt-get install iptraf # CentOS yum install iptraf ncurses- 使用:
sudo iptraf # 进入交互式界面,按提示选择监控维度(如接口、协议、端口)- 特点:
- 彩色文本界面,实时更新流量数据。
- 支持多维度过滤(如仅显示 TCP 连接或特定端口流量)。
7.
tcpdump:网络抓包工具
- 功能:捕获网络数据包,支持过滤和保存,配合 Wireshark 分析。
- 常用参数:
参数 说明 -i <接口>指定网卡(如 -i eth0)-c <次数>抓取指定数量的数据包后退出 -s <字节>设置抓包字节数(默认 262144, -s 0抓取完整包)-w <文件>保存抓包结果到文件 -r <文件>读取抓包文件(用于分析) - 过滤表达式:
- 协议:
tcp、udp、icmp。- 方向:
src(源)、dst(目标)。- 端口:
port 80、portrange 8000-9000。- 组合条件:
src host 192.168.1.100 and dst port 80。- 示例:
tcpdump -i eth0 -c 10 port 80 # 抓取 eth0 接口 80 端口的 10 个数据包 tcpdump -w capture.pcap -s 0 'tcp and (port 80 or port 443)' # 抓取 HTTP/HTTPS 完整包并保存 tcpdump -r capture.pcap # 读取抓包文件并显示(可导入 Wireshark)8.
nmap:端口扫描与服务探测
- 功能:扫描主机开放端口、服务类型、操作系统指纹等。
- 常用参数:
参数 说明 -p <端口>指定扫描端口(如 -p 80,443或-p 1-1000)-sSSYN 扫描(半开放扫描,隐蔽性强) -O探测操作系统类型 -A全面扫描(含服务版本、操作系统探测) -v显示详细扫描过程 - 示例:
nmap -v -A localhost # 扫描本地主机所有开放端口及服务信息 nmap -p 80-443 192.168.1.100 # 扫描目标主机 80-443 端口 nmap -O 192.168.1.1 # 探测路由器操作系统类型9.
lsof:查看打开文件与网络连接
- 功能:列出进程打开的文件、网络套接字,用于排查端口占用、文件句柄泄漏等。
- 常用参数:
参数 说明 -i:<端口>查看指定端口的占用进程(如 -i:80)-p <PID>查看进程打开的文件和连接 -c <进程名>筛选指定进程名的进程 - 示例:
lsof -i:80 # 查看占用 80 端口的进程 lsof -p 1234 # 查看进程 ID 1234 打开的所有文件 lsof -c nginx # 查看 nginx 进程打开的文件和连接10.
ethtool:网卡配置与状态查询
- 功能:查看 / 修改网卡参数(如速率、双工模式、自动协商等)。
- 常用参数:
参数 说明 <接口>指定网卡接口(如 eth0、ens33)-i查看网卡驱动信息 -s修改网卡参数(如速率、双工模式) -k查看 / 修改网卡 offload 功能(如校验和卸载) - 示例:
ethtool ens33 # 查看网卡 ens33 的配置信息 ethtool -s ens33 speed 100 autoneg off # 设置速率为 100Mb/s,关闭自动协商 ethtool -k ens33 | grep tx-checksum # 查看 TCP 校验和卸载状态总结:工具快速参考表
工具 核心功能 典型场景 telnet远程登录、TCP 端口测试 测试服务器端口是否开放 nc网络数据传输、端口监听、UDP 测试 搭建临时服务、传输文件、测试防火墙规则 mtr连通性与丢包率实时监控 定位网络延迟和丢包的具体路由节点 nslookupDNS 解析测试 排查域名无法解析问题 traceroute路由路径追踪 查看数据包经过的网关和延迟 iptraf实时网络流量监控 交互式分析流量分布、协议占比 tcpdump网络抓包与过滤 分析网络协议交互、定位丢包或异常请求 nmap端口扫描、服务探测、操作系统指纹 安全审计、服务发现 lsof查看进程打开的文件和网络连接 排查端口占用、文件句柄泄漏 ethtool网卡配置与状态查询 调整网卡速率、诊断物理层问题
八、 日志监控工具
一、tail:基础日志查看工具
1. 功能简介
tail是 Linux 系统自带的命令行工具,用于显示文件的末尾内容,常用于实时监控日志文件的更新。- 核心功能:实时追踪文件新增内容、显示指定行数 / 字节数、配合管道处理日志等。
2. 常用命令参数
参数 说明 -f或--follow实时追踪文件新增内容(文件不关闭时持续监控),按 Ctrl+C停止。-n <行数>显示文件末尾的指定行数(如 -n 10显示最后 10 行)。-c <字节数>显示文件末尾的指定字节数(如 -c 500显示最后 500 字节)。--pid=<PID>与 -f配合使用,当日志文件被轮换(如切割)时,自动重新打开新文件。3. 典型用法示例
实时监控单个日志文件:
tail -f /var/log/syslog
- 效果:持续显示
syslog的新增内容,常用于跟踪服务运行日志。显示最新 100 行日志:
tail -n 100 /var/log/nginx/access.log监控轮换日志(如切割后的新文件):
tail -f --pid=$(cat /var/run/nginx.pid) /var/log/nginx/access.log
- 场景:当日志文件被切割(如
logrotate处理)时,tail会自动重新关联新文件。配合管道过滤特定内容:
tail -f /var/log/nginx/access.log | grep "404"
- 效果:实时显示包含
"404"的日志行。二、multitail:多窗口日志监控工具
1. 功能简介
multitail是一个增强型日志监控工具,支持同时监控多个日志文件,并以分屏、彩色高亮的方式展示,适合需要同时观察多个日志的场景(如微服务多模块日志、前后端分离日志等)。- 核心功能:多文件分屏显示、颜色高亮、日志过滤、自定义布局等。
2. 安装方法
- Debian/Ubuntu 系统:
sudo apt-get install multitail- CentOS/RHEL 系统(需启用 EPEL 源):
sudo yum install multitail3. 常用命令参数
参数 说明 -l <文件>指定要监控的日志文件(可多次使用,如 -l file1 -l file2)。-s <秒数>设置刷新间隔(默认 1 秒,如 -s 2每 2 秒刷新一次)。-c启用颜色高亮(根据日志内容自动着色,需终端支持颜色)。 -p <模式>按指定模式分割窗口(如 -p 2垂直分割为 2 个窗口,-p 2x2分割为 4 个)。-e <正则>过滤包含指定正则表达式的日志行(仅显示匹配内容)。 4. 典型用法示例
同时监控两个日志文件,垂直分屏显示:
multitail -l /var/log/nginx/access.log -l /var/log/nginx/error.log -p 2
- 效果:窗口左右分割,左侧显示访问日志,右侧显示错误日志。
监控单个文件并过滤错误日志:
multitail -l /var/log/app.log -e "ERROR\|FAIL"
- 效果:仅显示包含
"ERROR"或"FAIL"的日志行,并自动高亮。自定义颜色规则(通过配置文件):
- 创建配置文件
~/.multitail.conf:color "ERROR" red # 红色高亮 ERROR color "INFO" green # 绿色高亮 INFO- 启动时加载配置:
multitail -c -C ~/.multitail.conf /var/log/app.log交互式操作:
- 在
multitail界面中,可通过键盘快捷键操作:
Tab:切换窗口。F2:添加新文件。F3:设置过滤规则。F9:退出。三、tail vs multitail:功能对比
特性 tail multitail 多文件支持 单一文件 多文件分屏 实时监控 支持 支持 颜色高亮 不支持(需配合其他工具) 内置支持 过滤功能 需配合 grep等工具内置正则过滤 界面交互 无 支持快捷键操作 系统依赖 系统自带 需手动安装 适用场景 简单单文件监控 复杂多文件、分屏监控
0voice · GitHub