kubernetes的service与服务发现
kubernetes的service与服务发现
- 1 Service
- 1.1 Service概念
- 1.2 Service类型
- 1.2.1 ClusterIP
- 1.2.2 NodePort
- 1.2.3 LoadBalancer
- 1.2.4 ExternalName
- 1.2.5 Headless
- 2 CoreDNS
- 2.1 CoreDNS概念
- 2.2 CoreDNS插件架构
- 2.3 CoreDNS在kubernetes下的工作原理
- 2.4 Pod上的DNS解析策略
- 3 Ingress
- 3.1 Ingress的概念
- 3.2 Ingress的类型
- 3.2.1 Simple fanout
- 3.2.2 Name based virtual hosting
- 3.2.3 TLS
- 3.3 Canary规则
- 3.4 Ingress和LoadBalancer的区别
1 Service
1.1 Service概念
Service是kubernetes标准的API资源类型之一,存在于集群中的各节点之上,kubernetes会为它创建一个稳定不变且可用的 Cluster_IP,为pod提供固定的流量入口。
- 服务发现:通过标签选择器,在同一名称空间下发现一组提供相同服务的pod,并筛选符合条件的pod
- 实际上并非由Service资源自己完成,是由与Service同名的Endpoint或EndpointSlice资源及控制器完成的
- 当创建一个Service时,Kubernetes会为该Service创建一个同名的Endpoints资源。这个Endpoints资源包含了一个或多个后端Pod的IP地址和端口号,是否有该pod取决于这个pod有没有通过readiness探针测试。当Service收到请求时,它会将请求转发给Endpoints中的后端Pod
- EndpointSlice可以支持更大规模的集群
- 四层负载均衡:这组筛选出来的pod的ip地址,将作为service的后端服务器,其流量调度规则是由运行在各工作节点的kube-proxy根据配置的模式生成,可以是iptables或ipvs
- 客户端可以是来自集群之上的Pod,也可以是集群外部的其它端点
- 该节点之上的进程,可通过该Service的Cluster IP进入(集群内部,东西向流量)
- 该节点之外的端点,可经由该Service的NodePort进入(集群外部,南北向流量,两级调度)
Service资源主要是为了解决Pod在服务提供上的不足
- Pod的 IP 具有动态性,当因为故障或重启而更换时,IP地址也会随之变化
- Pod的 IP 只能在kubernetes集群内部访问
1.2 Service类型
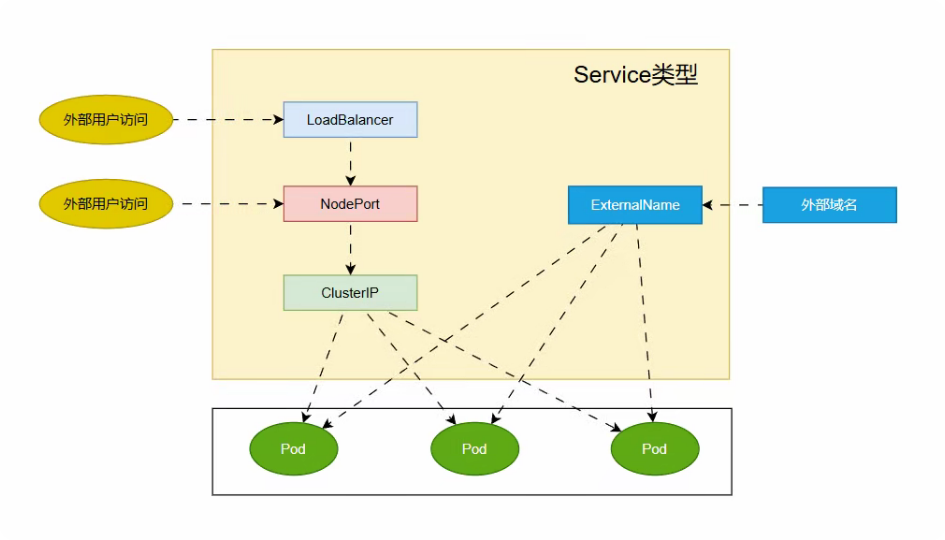
1.2.1 ClusterIP
访问范围:集群内部
依赖条件:无
典型场景:微服务内部通信
支持Service_IP:Service_Port接入,Client --> Service_IP:Service_Port --> Pod_IP:Pod_Port
1.2.2 NodePort
访问范围:集群外部(通过节点)
依赖条件:节点需要有与外部通信的IP
典型场景:开发测试,临时访问
支持Node_IP:Node_Port接入,Client --> Node_IP:NodePort --> Pod_IP:Pod_Port,这里的Node_IP可以集群中任一节点
节点会监听一个端口与service的端口映射,这就是NodePort,一般会分配一个在30000-32767之间的端口
1.2.3 LoadBalancer
访问范围:集群外部(通过LB)
依赖条件:云平台支持
典型场景:生产环境对外暴露服务
由于NodePort不是正常服务的端口,比如用户访问nginx,只知道是80端口,但是我们是30080端口,用户就不知道了,所以直接让用户访问Node不现实,需要在集群外部多加一级代理LoadBalancer,将接入的流量转发至工作节点上的NodePort
支持通过外部的LoadBalancer的LB_IP:LB_Port接入,Client --> LB_IP:LB_PORT --> Node_IP:NodePort --> Pod_IP:Pod_Port
云服务商一般会提供一个负载均衡器,当集群创建一个LoadBalancer类型的service资源时,会自动帮我们关联一个负载均衡器,,生成 EXTERNAL-IP(LB_IP) 供外部客户端使用
若外部LB把流量转发给并非目标Pod所在的节点时,该节点就要把该流量转发给拥有这个pod的Node上,报文转发的路径中就会存在跃点,可以通过 externalTrafficPolicy.Local 设置外部LB只能把流量转发给运行有该Service关联的Pod的Node之上
1.2.4 ExternalName
访问范围:集群内部
依赖条件:外部服务需要有DNS名称
典型场景:代理外部服务
DNS 重定向机制,用于将集群外部的服务引入到集群中,将集群内的服务名称映射到集群外的域名,通过externalName字段进行设置。当集群内的 Pod 访问这个服务时,DNS 解析会将服务名称解析为外部域名。
ServiceName --> external Service DNS Name
1.2.5 Headless
访问范围:集群内部
依赖条件:无
典型场景:有状态应用,直接访问Pod
那些没有ClusterIP的Service则称为Headless Service,它们又可以为分两种情形
- 有标签选择器的有状态应用,或者没有标签选择器但有着与Service对象同名的Endpoint资源。Service的DNS名称直接解析为后端各就绪状态的Pod的IP地址,各Pod IP相关PTR记录将解析至Pod自身的名称,不会解析至Service的DNS名称
- 无标签选择器且也没有与Service对象同名的Endpoint资源,即ExternalName,Service的DNS名称将会生成一条CNAME记录,对应值由Service对象上的
spec.externalName字段指定
2 CoreDNS
2.1 CoreDNS概念
CoreDNS是Kubernetes集群的必备附件(DNS服务器),负责为Kubernetes提供名称解析和服务发现,对于每个Service,自动生成一个或多个A、PTR和SRV(端口名称解析)记录,将Service的name与Service的Cluster_IP地址做一个DNS域名映射,可以基于名称的方式去访问该组Pod上的服务.
每个Service资源对象,在CoreDNS上都会自动生成一个遵循 “<service>.<ns>.svc.<zone>” 格式的名称,围绕该名称会生成一些DNS格式的资源记录
<service>:当前Service对象的名称<ns>:当前Service对象所属的名称空间<zone>:当前Kubernetes集群使用的域名后缀,默认为“cluster.local”,是 Kubernetes 集群中所有域名的根域名
2.2 CoreDNS插件架构
CoreDNS是一种灵活、可扩展的 DNS 服务器,借助插件架构,允许用户根据需求自定义功能。与其他 DNS 服务器BIND、Knot、PowerDNS不同,CoreDNS 非常灵活,几乎所有功能都交给插件去实现。
默认的 CoreDNS 安装中包含了大约 30 个插件,还可以编译许多外部插件到 CoreDNS 中,以扩展其功能。
CoreDNS的插件可大致分为两类:
- 负责处理请求的常规插件,这些插件才是插件链中的有效组成部分,例如errors、kubernetes和forward等,而他们又分为两类
- 负责以某种方式处理请求的插件:这类插件不是区域数据源,它们的运行方式是在自身处理完成后,会将查询传递给下一个插件
- 后端插件:用于配置区域数据的来源,例如etcd、file和kubernetes等
- 这类插件通常要为其负责的区域生成最终结果,它要么能正常响应查询,要么返回NXDOMAIN
- 但也可以使用fallthrough改变这种响应行为:未发现查询的目标资源记录时,将DNS查询请求转交给插件链中的下一个插件,随后终结于另一个后端插件,或再次由 fallthrough 改变这种行为
- 不处理请求的特殊插件,它们仅用来修改Server或Server Block中的配置,例如health、tls、startup、shutdown和root等插件,这类插件不会作为服务器配置段的插件链中的有效组成部署
2.3 CoreDNS在kubernetes下的工作原理
CoreDNS 在 Kubernetes 中作为一个 Deployment 运行,通常会部署两个或多个副本以确保高可用性。它主要通过以下步骤工作:
- 启动与配置:CoreDNS 读取 ConfigMap 配置文件,根据配置启动相应的插件。
- 监听 DNS 请求:CoreDNS 监听来自 Kubernetes 集群内部的 DNS 请求。
- 解析 DNS 请求:根据请求的类型,CoreDNS 调用相应的插件进行解析。
- 返回解析结果:将解析结果返回给请求方。
2.4 Pod上的DNS解析策略
由 spec.dnsPolicy 设置
- Default:Pod直接继承其所在节点的名称解析配置,就无法解析集群内部的服务,csi-nfs-driver默认使用
- ClusterFirst:使用集群内部的CoreDNS服务进行域名解析。如果集群内的服务无法解析请求的域名,那么才将查询转发给从所在节点继承的上游名称服务器
- ClusterFirstWithHostNet:专用于在设置了hostNetwork的Pod对象上使用的ClusterFirst策略。当Pod与宿主机共用同一个网络命名空间时,这类Pod无法访问集群内的服务,所以该策略让这类Pod可以利用集群的DNS服务进行域名解析
- None:用于忽略Kubernetes集群的默认设定,而仅使用由dnsConfig自定义的配置
Pod内解析一个域名时,请求送到CoreDNS的Pod中的流程
1、DNS配置初始化
Pod启动时,kubelet根据集群DNS配置( --cluster-dns 参数)将CoreDNS的Service ClusterIP写入Pod的 /etc/resolv.conf 文件
2、DNS查询发起
应用程序发起域名查询(如my-service)
- 若为非FQDN(如my-service),系统按search域依次补全(如my-service..svc.cluster.local)并尝试解析
- 若为FQDN(如my-service.ns.svc.cluster.local),直接发送DNS请求
3、请求路由至CoreDNS服务
Pod的DNS客户端将请求通过UDP/TCP协议发送至nameserver指定的CoreDNS Service ClusterIP(如10.96.0.10)的53端口,然后节点上的kube-proxy实现流量转发,通过iptables/IPVS规则将目标为CoreDNS ServiceIP的流量负载均衡到后端CoreDNS Pod的Endpoint IP
4、CoreDNS处理请求
- CoreDNS Pod接收请求后,根据配置(corefile)执行插件链
- kubernetes插件:解析集群内Service、Pod域名,通过API Server查询Service/Pod的IP
- forward插件:非集群域名(如baidu.com)转发至上游DNS(如节点/etc/resolv.conf中的外部DNS服务器
- 返回解析结果:CoreDNS将解析后的IP地址按原路径返回至Pod,完成域名解析
Pod应用→ /etc/resolv.conf → CoreDNS Service → kube-proxy→ CoreDNS Pod→ API Server/外部DNS
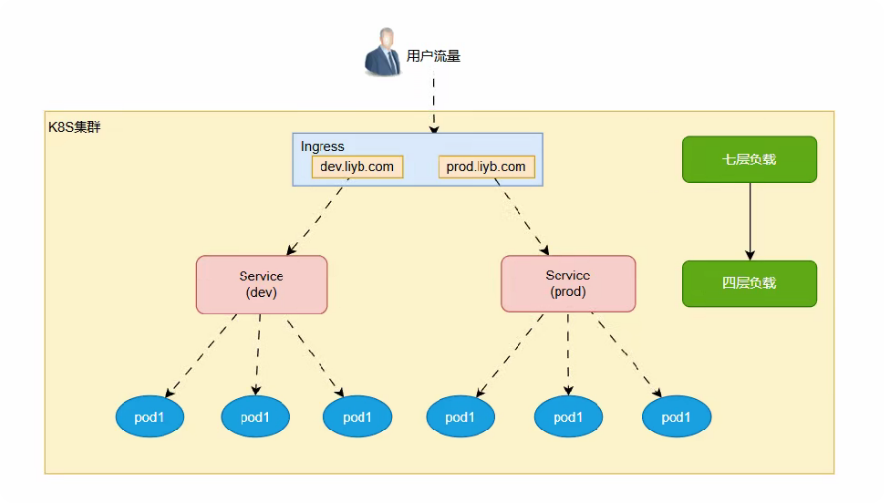
3 Ingress
3.1 Ingress的概念
Service作为四层负载均衡,不支持基于URL等机制对HTTP/HTTPS协议进行高级路由、超时/重试、基于流量的灰度等高级流量治理机制,也难以将多个Service流量统一管理,所以有了Ingress作为七层负载均衡
- 可配置域名和路径规则,为多个服务提供统一入口
- 支持多种高级功能,如 TLS、路径重写等
- 仅支持 HTTP 和 HTTPS
Ingress是Kubernetes上的标准API资源类型之一,由Ingress API和Ingress Controller共同组成
- 前者负责以k8s标准的资源格式定义流量调度、路由等规则
- 后者负责监视(watch)Ingress并生成自身的配置,并据此完成流量转发
Ingress Controller非为内置的控制器,需要额外部署(用户空间的代理进程),实现方案有很多,包括Ingress-Nginx、HAProxy、Envoy、Traefik、Gloo、Contour和Kong等
- 通常以Pod形式运行于Kubernetes集群之上
- 一般应该由专用的LB Service负责为其接入集群外部流量
- Kubernetes支持同时部署二个或以上的数量的Ingress Controller,所以在创建Ingress资源时,应该指明其所属的Ingress Controller
Ingress、Ingress Controller和Service的关系
- Ingress需要借助于Service资源来发现后端端点
- Ingress Controller会基于Ingress的定义将流量直接发往其相关Service的后端端点,该转发过程并不会再经由Service进行
- Client --> LB Service --> Ingress Controller Pod --> Upstream Service --> Upstream Pod
- LB Service是NodePort类型或者是LoadBalancer类型
- Upstream Service仅发挥服务发现功能,来发现后端Pod,并不需要负载均衡功能,这样做可以减少一层代理
- 所以流量流向可以认为是Client --> LB Service --> Ingress Controller Pod --> Upstream Pod
- 当然对那些未通过Ingress Controller进入的流量service会执行负载均衡
3.2 Ingress的类型
3.2.1 Simple fanout
在同一个FQDN下通过不同的URI完成不同应用间的流量分发
- 基于单个虚拟主机接收多个应用的流量
- 常用于将流量分发至同一个应用下的多个不同子应用,同一个应用内的流量由调度算法分发至该应用的各后端端点
- 不需要为每个应用配置专用的域名
基于URI方式代理不同应用的请求时,后端应用的URI若与代理时使用的URI不同,则需要启用URL Rewrite完成URI的重写,Ingress-Nginx支持使用 “annotation nginx.ingress.kubernetes.io/rewrite-target” 注解
3.2.2 Name based virtual hosting
为每个应用使用一个专有的主机名,并基于这些名称完成不同应用间的流量转发
- 每个FQDN对应于Ingress Controller上的一个虚拟主机的定义
- 同一组内的应用的流量,由Ingress Controller根据调度算法完成请求调度
基于FQDN名称代理不同应用的请求时,需要事先准备好多个域名,且确保对这些域名的解析能够到达Ingress Controller
3.2.3 TLS
Ingress也可以提供TLS通信机制,但仅限于443/TCP端口
- 若TLS配置部分指定了不同的主机,则它们会根据通过SNI TLS扩展指定的主机名
- 前提:Ingress控制器支持SNI在同一端口上复用
- TLS Secret必须包含名为tls.crt和 的密钥tls.key,它们分别含有TLS的证书和私钥
基于TLS的Ingress要求事先准备好专用的 “kubernetes.io/tls” 类型的Secret对象
3.3 Canary规则
Ingress Nginx Annotations支持的Canary规则
-
nginx.ingress.kubernetes.io/canary-by-header:基于该Annotation中指定Request Header进行流量切分,适用于灰度发布以及A/B测试- 在请求报文中,若存在该Header且其值为always时,请求将会被发送到Canary版本
- 若存在该Header且其值为never时,请求将不会被发送至Canary版本
- 对于任何其它值,将忽略该Annotation指定的Header,并通过优先级将请求与其他金丝雀规则进行优先级的比较
-
nginx.ingress.kubernetes.io/canary-by-header-value:基于该Annotation中指定的Request Header的值进行流量切分,标头名称则由前一个Annotation(nginx.ingress.kubernetes.io/canary-by-header)进行指定- 请求报文中存在指定的标头,且其值与该Annotation的值匹配时,它将被路由到Canary版本
- 对于任何其它值,将忽略该Annotation
-
nginx.ingress.kubernetes.io/canary-by-header-pattern- 同canary-by-header-value的功能类似,但该Annotation基于正则表达式匹配Request Header的值
- 若该Annotation与canary-by-header-value同时存在,则该Annotation会被忽略
-
nginx.ingress.kubernetes.io/canary-weight:基于服务权重进行流量切分,适用于蓝绿部署或灰度发布,权重范围0 - 100按百分比将请求路由到Canary Ingress中指定的服务- 权重为 0 意味着该金丝雀规则不会向Canary入口的服务发送任何请求
- 权重为100意味着所有请求都将被发送到 Canary 入口
-
nginx.ingress.kubernetes.io/canary-by-cookie:基于 cookie 的流量切分,适用于灰度发布与 A/B 测试- cookie的值设置为always时,它将被路由到Canary入口
- cookie的值设置为 never时,请求不会被发送到Canary入口
- 对于任何其他值,将忽略 cookie 并将请求与其他金丝雀规则进行优先级的比较
规则的应用次序
- Canary规则会按特定的次序进行评估
- 次序:canary-by-header -> canary-by-cookie -> canary-weight
Canary规则策略
- 基于服务权重的流量切分:假如在生产上已经运行了A应用对外提供服务,此时开发修复了一些Bug,需要发布A1版本将其上线,但是我们又不希望直接的将所有流量接入到新的A1版本,而是希望将10%的流量进入到A1中,待A1稳定后,才会将所有流量接入进来,再下线原来的A版本。
- 基于用户请求头Header的流量切分:由于基于权重的发布场景比较粗糙,无法限制具体的用户访问行为。我们有时候会有这样的需求,比如我们有北京、上海、深圳这三个地区的用户,已经有A版本的应用为这三个地区提供服务,由于更新了需求,我们需要发布A1应用,但是我们不想所有地区都访问A1应用,而是希望只有深圳的用户可以访问,待深圳地区反馈没问题后,才开放其他地区。
3.4 Ingress和LoadBalancer的区别
| 特性 | Ingress | LoadBalancer |
|---|---|---|
| 定义 | 集群内外部流量的路由入口,基于URL路径和主机名路由流量 | 云负载均衡器,自动为Service创建外部负载均衡器 |
| 使用场景 | 微服务架构、基于URL路由的流量管理、集群内多个服务共用入口 | 简单的将服务暴露到外部网络,提供公网访问 |
| 支持的协议 | HTTP/HTTPS | HTTP/HTTPS 或 TCP/UDP(依赖云提供商的负载均衡器) |
| 负载均衡 | 通过Ingress Controller(如NGINX)提供 | 云服务商自动创建的负载均衡器,流量转发到NodePort或TargetPort |
| SSL/TLS 支持 | ✅ 支持SSL/TLS配置,提供HTTPS加密 | ✅ 需要配置SSL证书(通常由云提供商管理) |
| 是否依赖外部云平台 | ❌ 不依赖云平台,集群内部处理 | ✅ 依赖云平台的负载均衡器(如AWS ELB, GCP L4/L7等) |
| 成本 | ❌ 无额外成本(Kubernetes原生功能) | 💸 会根据云服务商收费 |
| 扩展性与灵活性 | ✅ 可以在Ingress规则中灵活配置路由、路径重写、重定向 | ✅ 基本上由云服务商管理,适合简单的服务暴露需求 |