【LLM】大模型落地应用的技术 ——— 推理训练 MOE,AI搜索 RAG,AI Agent MCP
【LLM】大模型落地应用的技术 ——— 推理训练MOE,AI搜索RAG,AI Agent MCP
文章目录
- 1、推理训练 MOE
- 2、AI搜索 RAG
- 3、AI Agent MCP
1、推理训练 MOE
MoE 是模型架构革新,解决了算力瓶颈。原理是多个专家模型联合计算。
推理训练MoE(Mixture of Experts)
- 核心原理
动态稀疏激活:模型由多个专家子网络(Experts)组成,每个输入仅激活部分专家(如1-2个),显著减少计算量。
门控机制(Gating):通过可学习的路由网络决定输入分配给哪些专家,实现条件计算。 - 应用场景
DeepSeek-V3 采用的 DeepSeekMoE 架构,通过细粒度专家、共享专家和 Top-K 路由策略,实现了模型容量的高效扩展。
超大模型推理:如Google的Switch Transformer(万亿参数),仅激活部分参数,降低计算成本。
多模态任务:不同专家处理不同模态(文本、图像),提升异构数据融合能力。
资源受限设备:通过专家剪枝或量化,适配边缘设备。 - 技术优势
高效率:计算量仅为稠密模型的1/4~1/2,保持性能。
可扩展性:通过增加专家数量而非深度扩展模型能力。 - 挑战
专家负载不均衡(某些专家过载)、路由训练的稳定性。
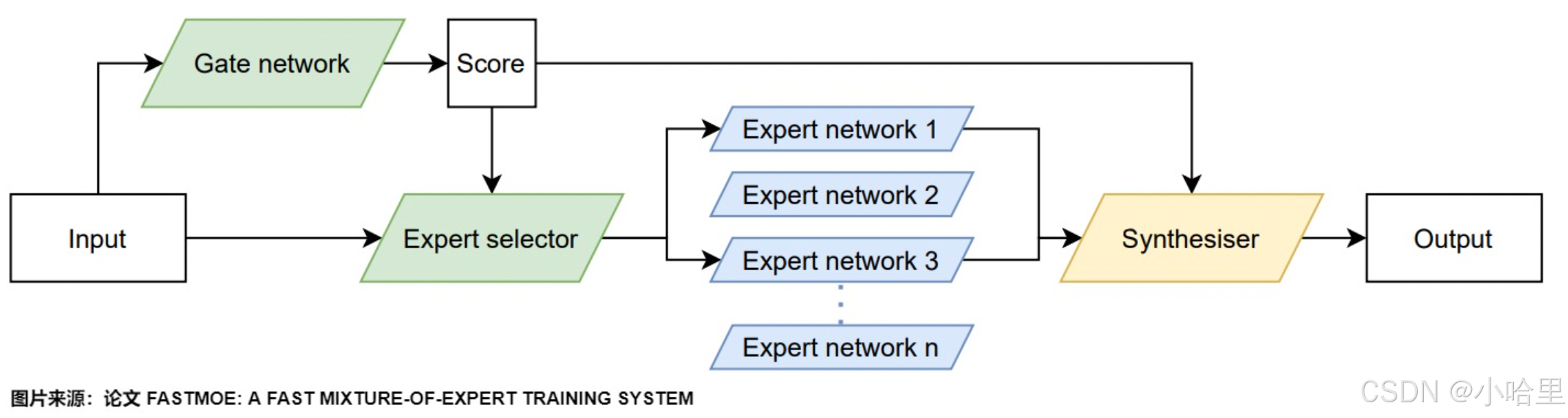
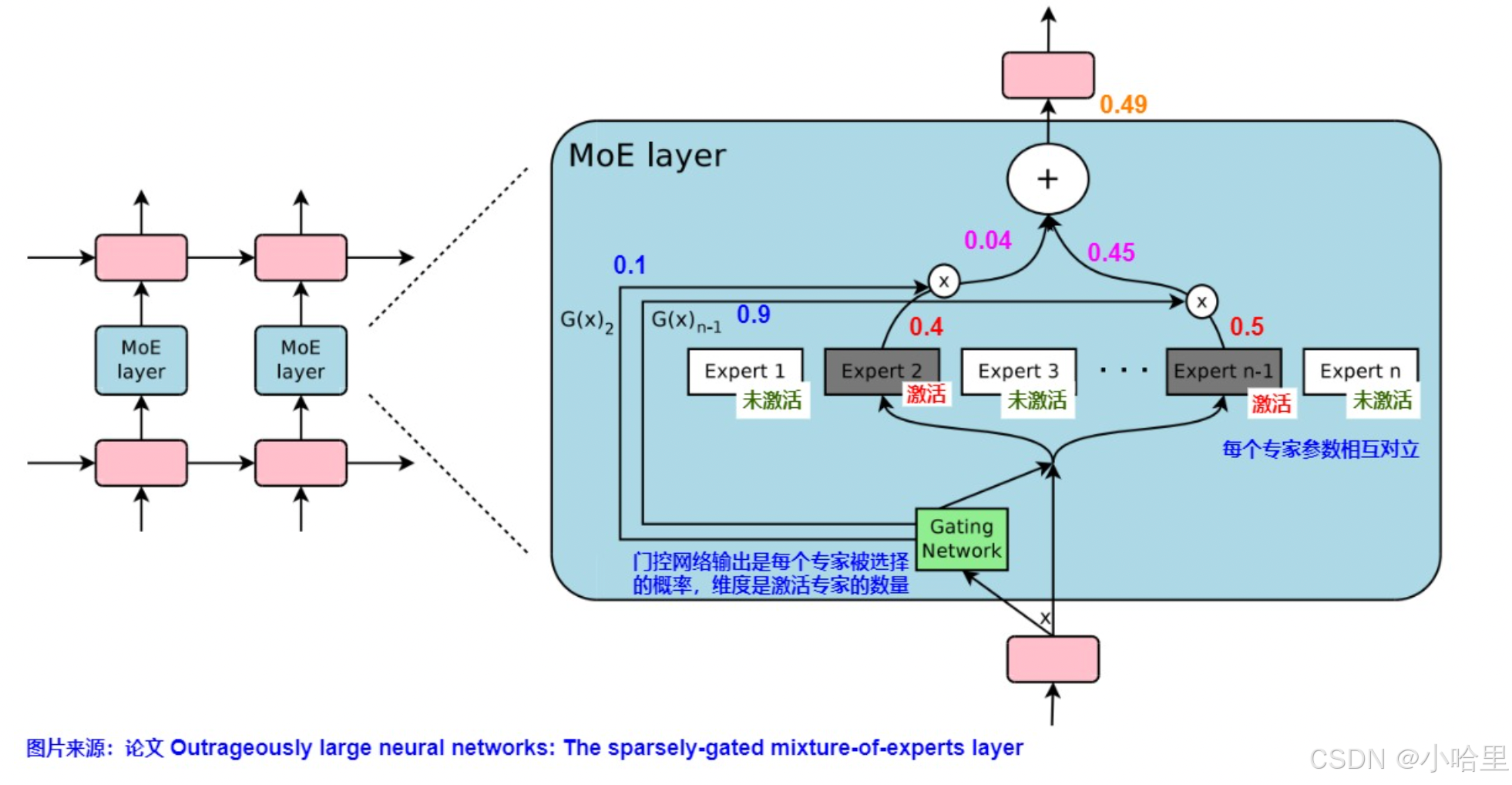
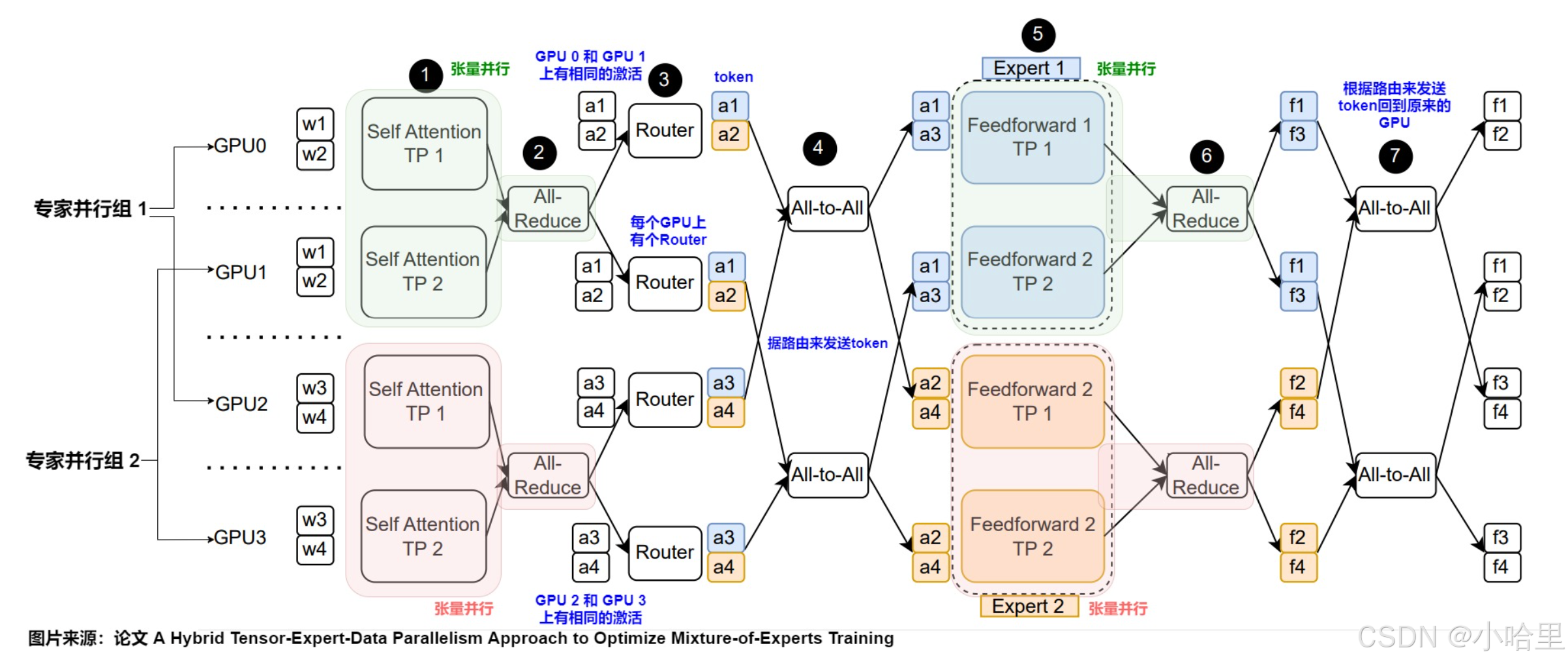
MoE核心架构
- 核心组件
专家网络(Experts):多个独立的子网络(如FFN),每个专家专注不同特征或任务。
门控网络(Gating):动态分配输入到最相关的专家(稀疏激活)。
路由策略(Routing):控制专家选择的算法(如Top-K、噪声容忍)。 - 典型工作流程
输入分发:门控网络计算输入与专家的匹配分数。
专家选择:按分数选择Top-K专家(通常K=1~2)。
计算融合:仅激活所选专家,结果加权求和或拼接。 - 发展历程:
Transformer -> LLM: Transformer的自注意力机制是LLM处理长文本的基础,替代了RNN的梯度消失问题。LLM的成功还需大规模数据+算力(如GPT-3的175B参数)和训练技巧(如RLHF)
Transformer -> MoE: MoE将Transformer中的稠密FFN拆分为多个专家,保留注意力层不变。在相同计算开销下扩大模型容量(更多参数,但激活参数不变, 如Google的GLaM模型,1.2T参数但仅激活97B/step) - 关系类比:
Transformer = 发动机
LLM = 装发动机的超跑(需燃料/数据+车身/算力)
MoE = 涡轮增压(让超跑更省油且动力更强)
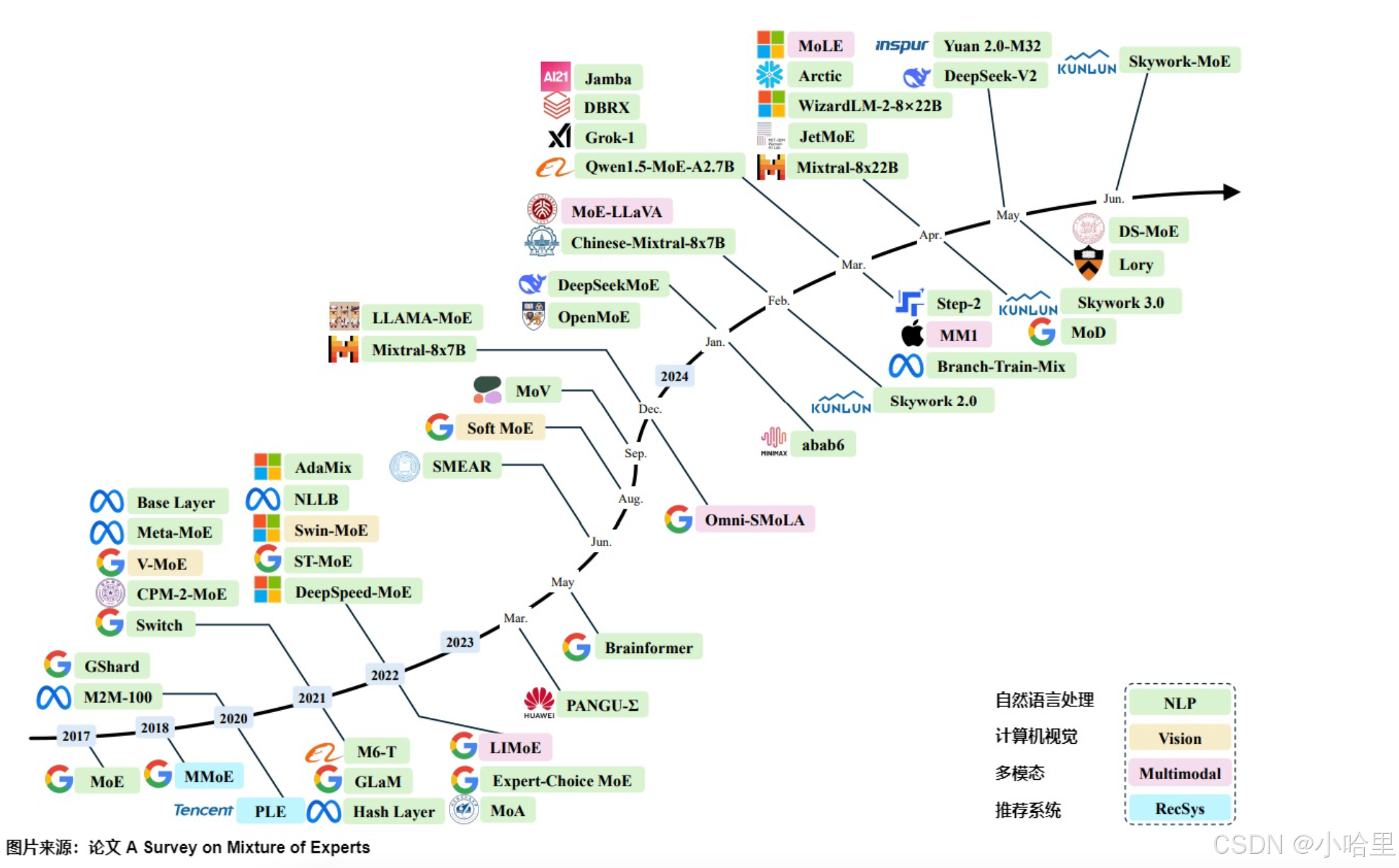
例子
# Transformers库(Hugging Face)
# 支持模型:Switch Transformer、Google的T5-MoE、Meta的FairSeq-MoE。
# 特点:直接加载预训练MoE模型,支持自定义专家数
from transformers import SwitchTransformersForConditionalGeneration
model = SwitchTransformersForConditionalGeneration.from_pretrained("google/switch-base-8", # 8个专家的预训练模型device_map="auto"
)
outputs = model.generate(input_ids, max_length=50)# 训练优化
def load_balancing_loss(gate_logits, num_experts):"""计算专家利用率均衡损失"""probs = jax.nn.softmax(gate_logits, axis=-1)expert_mask = jax.nn.one_hot(jax.argmax(probs, axis=-1), num_experts)expert_frac = expert_mask.mean(axis=0)return jnp.sum(expert_frac * jnp.log(expert_frac + 1e-10))# 推理优化
def sparse_moe_inference(inputs, experts, gate, k=1):gate_scores = gate(inputs)top_k_scores, top_k_indices = torch.topk(gate_scores, k=k, dim=-1)# 仅激活Top-K专家outputs = torch.zeros_like(inputs)for i in range(k):expert_output = experts[top_k_indices[:, i]](inputs)outputs += expert_output * top_k_scores[:, i].unsqueeze(-1)return outputs# pytorch 通用模板
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MoELayer(nn.Module):def __init__(self, input_dim, expert_dim, num_experts, k=2):super().__init__()self.experts = nn.ModuleList([nn.Linear(input_dim, expert_dim) for _ in range(num_experts)])self.gate = nn.Linear(input_dim, num_experts)self.k = kdef forward(self, x):# 1. 路由计算gate_scores = F.softmax(self.gate(x), dim=-1) # (batch_size, num_experts)top_k_scores, top_k_indices = torch.topk(gate_scores, k=self.k, dim=-1) # (batch_size, k)# 2. 稀疏计算output = torch.zeros(x.shape[0], self.experts[0].out_features, device=x.device)for i in range(self.k):expert_idx = top_k_indices[:, i] # (batch_size,)expert_output = torch.stack([self.experts[idx](x[b]) for b, idx in enumerate(expert_idx)])output += expert_output * top_k_scores[:, i].unsqueeze(-1)return output# 使用示例
moe = MoELayer(input_dim=512, expert_dim=1024, num_experts=8, k=2)
x = torch.randn(32, 512) # 假设输入维度为512
out = moe(x) # 输出维度1024
参考资料:ai应用落地
1, 2-moe架构 , 3 moe, 4 moe介绍, 5 moe 基础设施, 6 moe详解
2、AI搜索 RAG
RAG 是知识增强手段,弥补静态训练缺陷和模型幻觉。原理是把数据库检索结果作为模型输入。
RAG是什么?
- RAG(Retrieval-Augmented Generation)
- 核心原理
检索+生成:先通过检索器(如向量数据库)从外部知识库获取相关文档,再输入生成模型(如GPT)生成答案。
动态知识更新:无需重新训练模型,仅更新检索库即可修正知识。 - 应用场景
开放域问答:如客服系统,结合企业文档生成精准回答。
事实性补充:弥补大模型幻觉问题(如医疗、法律场景)。
长尾知识覆盖:检索罕见数据(如最新科研论文)增强生成。 - 技术关键
检索优化:稠密检索(Dense Retrieval)比传统BM25更语义化。
上下文压缩:对检索到的长文档进行摘要或筛选,避免输入过长。 - 挑战
检索延迟(毫秒级要求)、噪声文档干扰生成质量。
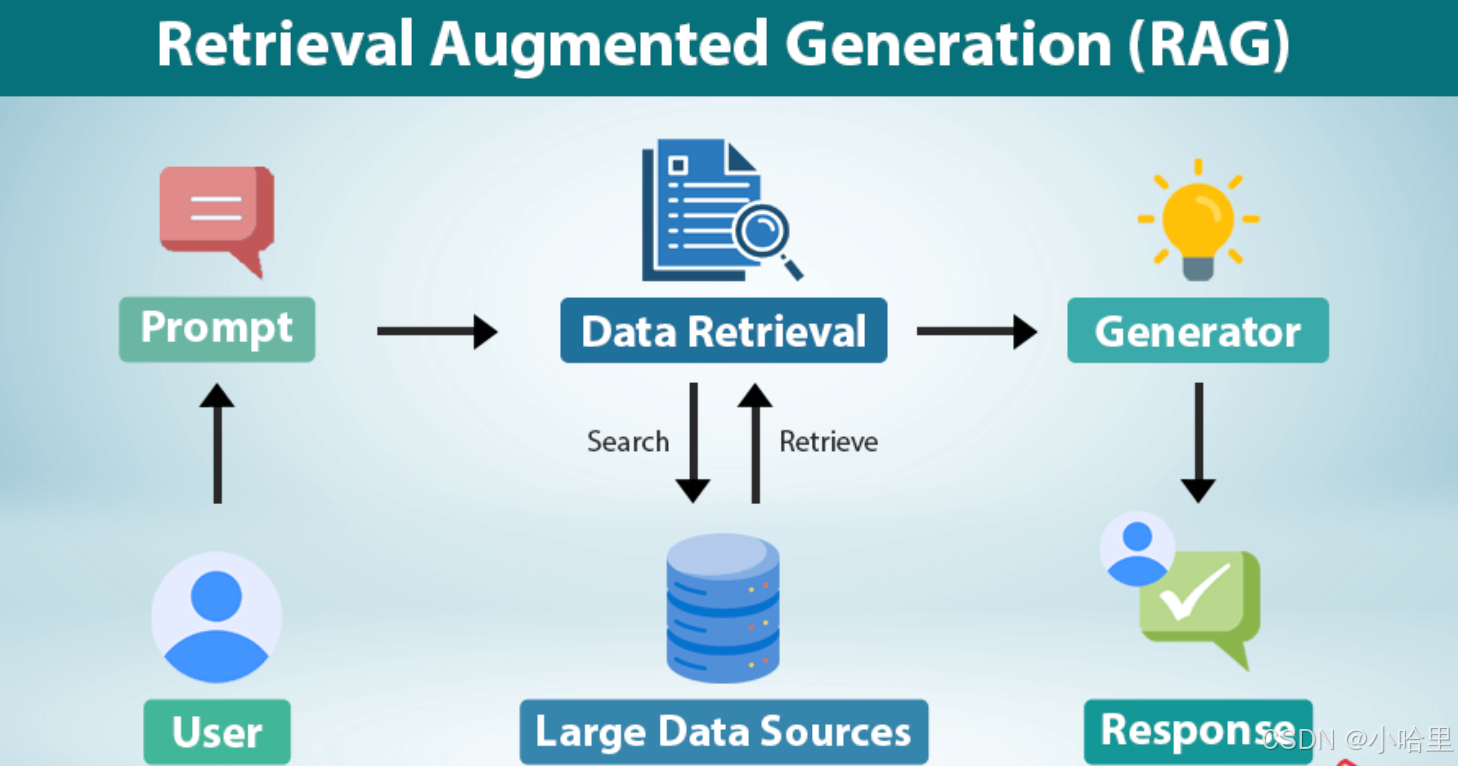
RAG的核心架构
- 1、技术流程
检索(Retrieval):从外部知识库(如文档、数据库)中检索相关片段。稀疏检索(BM25)、稠密检索(向量相似度)、混合检索。
增强(Augmentation):将检索结果与用户输入拼接,作为生成模型的上下文。
生成(Generation):基于上下文生成最终回答(如GPT类模型)。 - 2、关键组件
文本分块:LangChain、TextSplitter、LlamaIndex
向量数据库:FAISS、Pinecone、Weaviate、Milvus
检索模型:BM25、Sentence-BERT、OpenAI Embeddings
生成模型:GPT-4、Llama 2、LangChain LLM
评估工具:RAGAS、BLEU、Recall
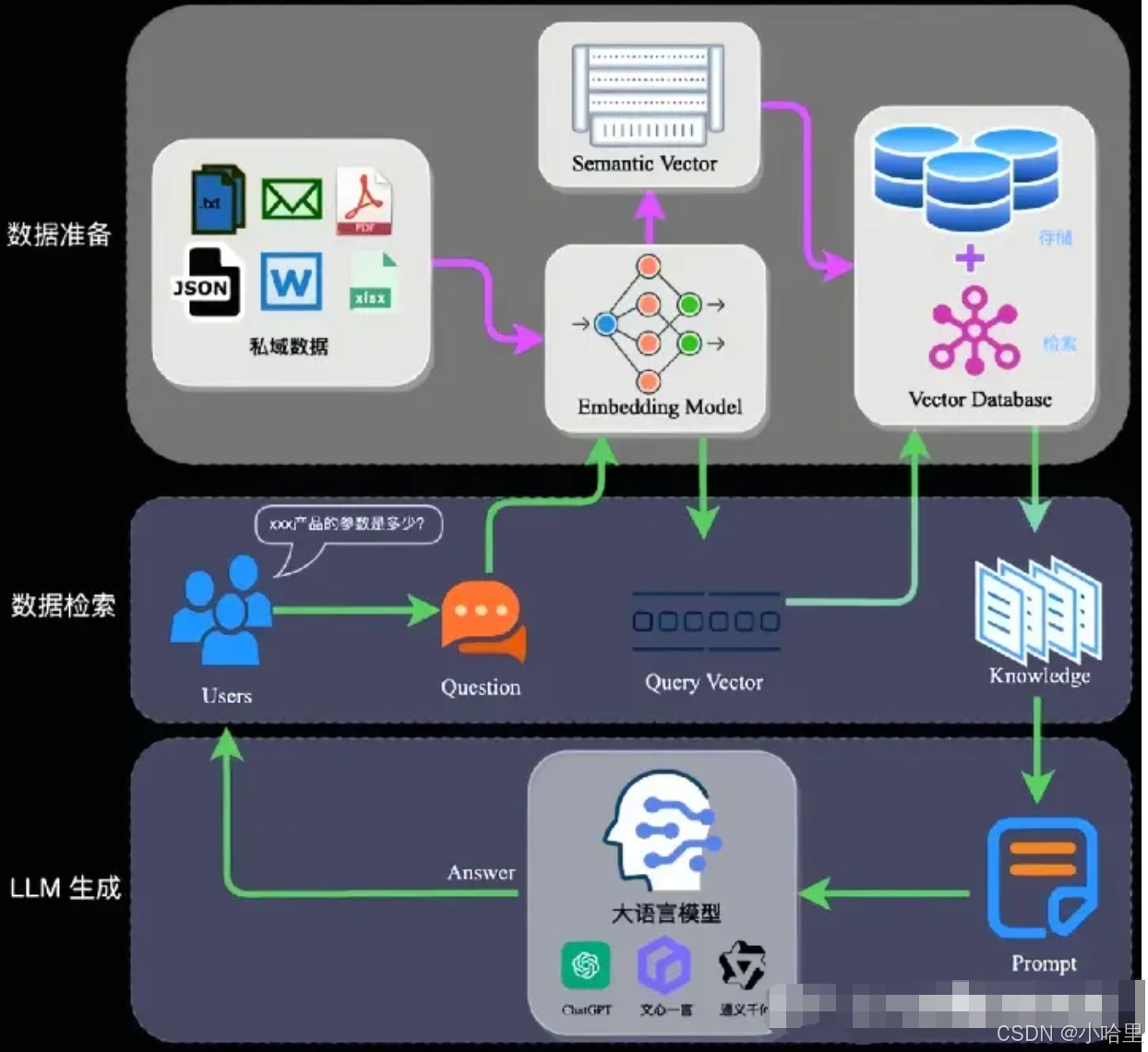
开源框架与解决方案
- 1、LangChain-108k + FAISS
适用场景:轻量级RAG,本地部署。 - 2、LlamaIndex-42k(专用RAG框架)
特点:优化长文档索引、支持多种数据源(PDF/网页/API)。 - 3、Haystack-20k(工业级Pipeline)
特点:模块化设计,支持复杂检索逻辑(过滤、重排序)。 - 4、商业解决方案(非开源)
Pinecone:托管向量数据库,低延迟检索
Weaviate:开源/云版,支持多模态检索
Google Vertex AI:集成Gemini模型+RAG工作流
Azure Cognitive Search:企业级全文检索+AI扩展
# 例子:LangChain-108k
# 基于LangChain + OpenAI的完整流程
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import pinecone# 初始化Pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="us-west1-gcp")
index_name = "company-knowledge-base"# 从本地文档构建索引
# 加载文档,分块,构建向量数据库
# loader = TextLoader("example.txt")
# documents = loader.load()
documents = load_and_split_documents() # 自定义文档加载函数
embeddings = OpenAIEmbeddings()
vector_db = Pinecone.from_documents(documents, embeddings, index_name=index_name)# 检索问答链
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(model="gpt-4"),chain_type="stuff",retriever=vector_db.as_retriever(search_kwargs={"k": 3}),return_source_documents=True
)# 提问
result = qa_chain("XXX是怎样的?")
print("答案:", result["result"])
print("来源:", result["source_documents"])# 更多优化# 1.重排序(Re-Rank):使用交叉编码器(如cross-encoder/ms-marco-MiniLM-L-6-v2)对检索结果排序。
from sentence_transformers import CrossEncoder
encoder = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
scores = encoder.predict([(query, doc.text) for doc in retrieved_docs]) # 假设retrieved_docs是初步检索结果
reranked_docs = [doc for _, doc in sorted(zip(scores, retrieved_docs), reverse=True)]# 2.生成优化
# 提示工程:明确上下文角色(如“基于以下文档回答:...”)。
# 上下文压缩:用LangChain的ContextualCompressionRetriever过滤无关内容。# 3.评估指标
# 检索质量:Recall@K、Hit Rate。
# 生成质量:Faithfulness(事实一致性)、Answer Relevance(相关性)
# 工具推荐:RAGAS (自动化评估库)参考资料:1, 2, 3
3、AI Agent MCP
Agent MCP 是落地范式,通过多智能体实现复杂场景自动化。原理是提供工具调用接口给到AI。
MCP介绍
- 核心原理
多智能体协作:多个Agent(如规划、工具调用、验证Agent)分工合作,通过任务分解、反馈循环完成复杂目标。
记忆与规划:利用LLM的推理能力制定计划,并通过短期/长期记忆(如向量数据库)保存状态。 - 应用场景
自动化工作流:如AutoGPT自动写代码+调试+部署。
复杂决策:供应链优化中协调采购、物流、库存Agent。
仿真环境:游戏NPC群体协作(如《AI小镇》项目)。 - 技术组件
工具调用(Tool Use):调用API、数据库等外部工具。
反思机制(Reflection):通过失败案例自我改进策略。 - 挑战
任务分解的可靠性、长程规划的稳定性(避免无限循环)。
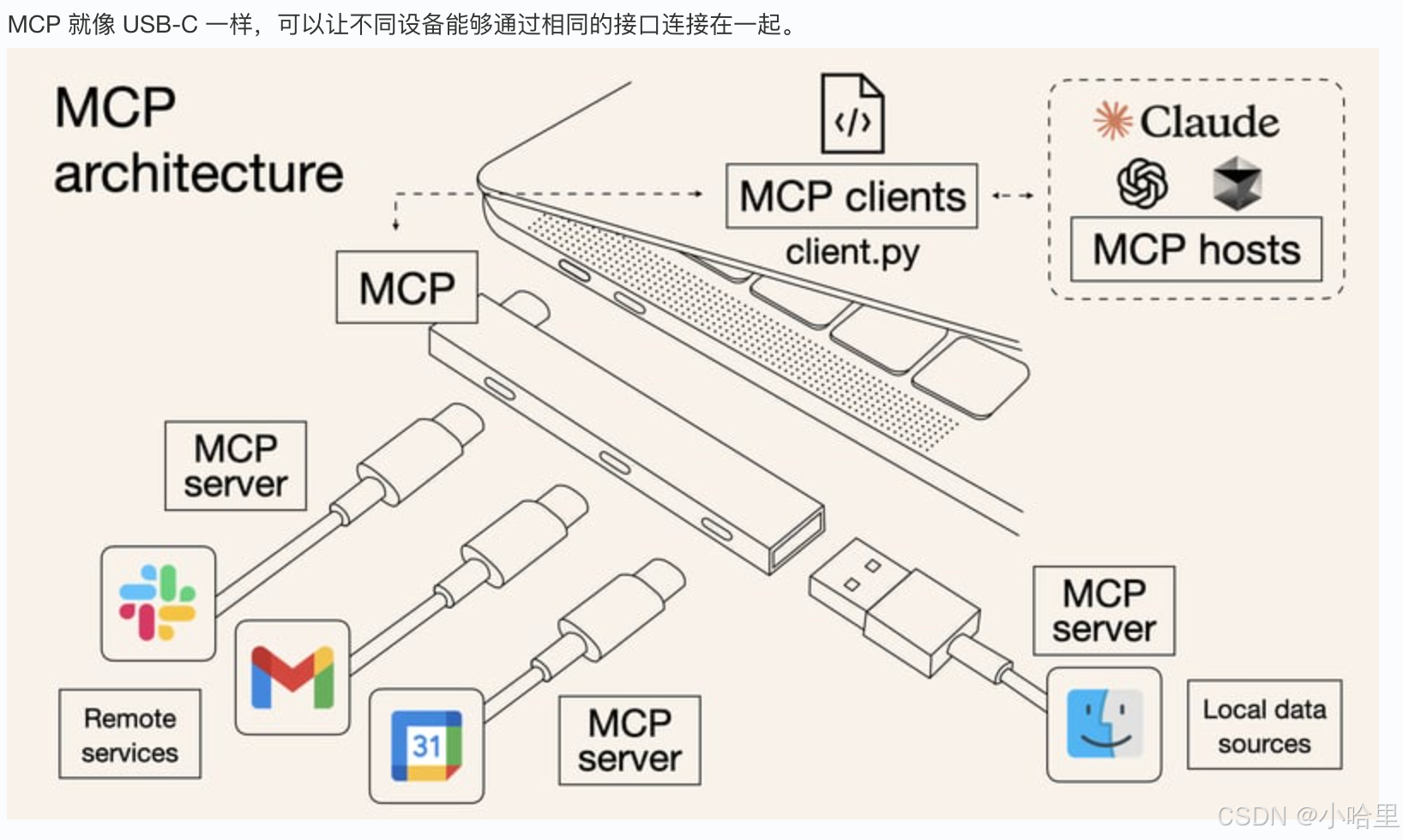
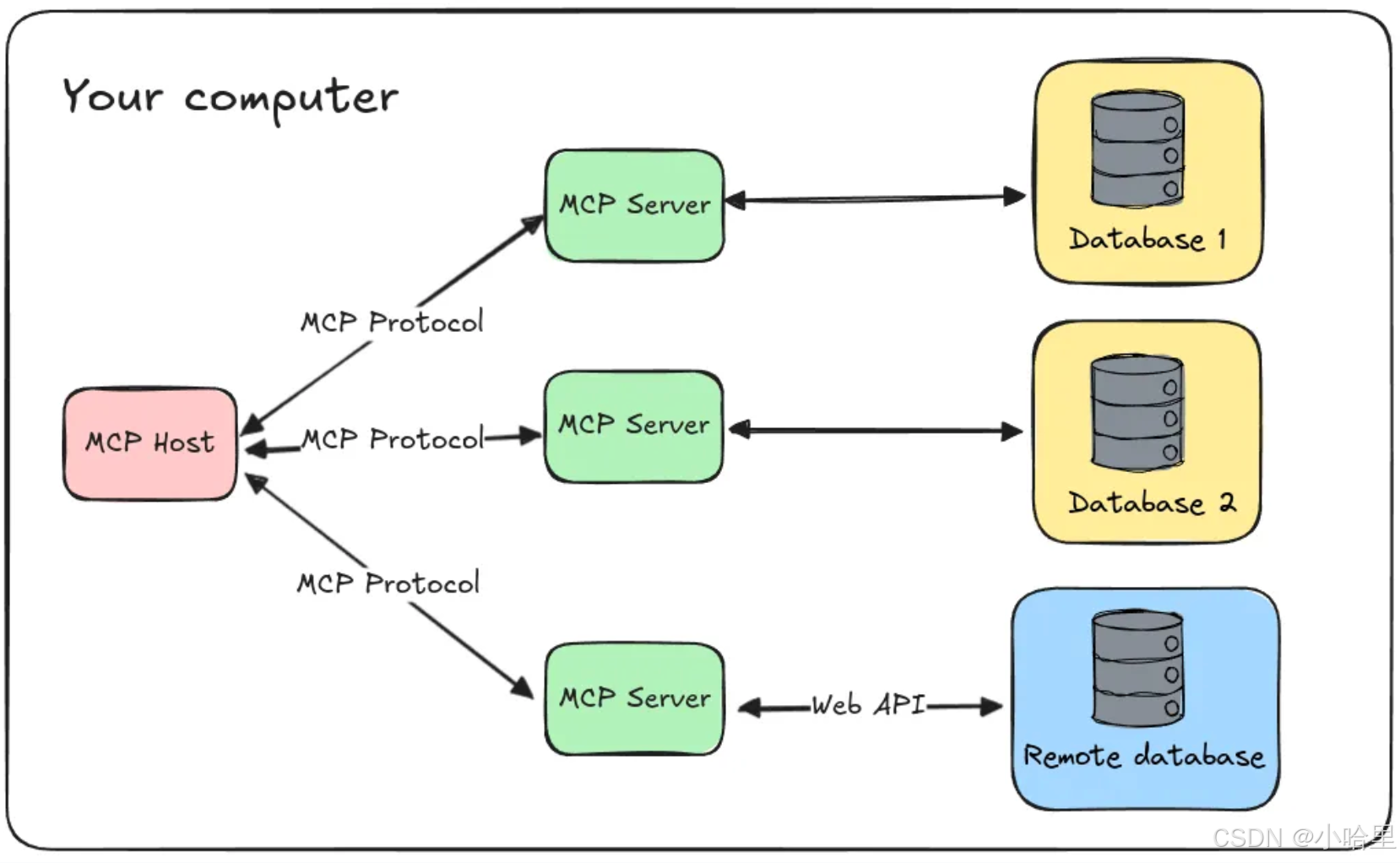
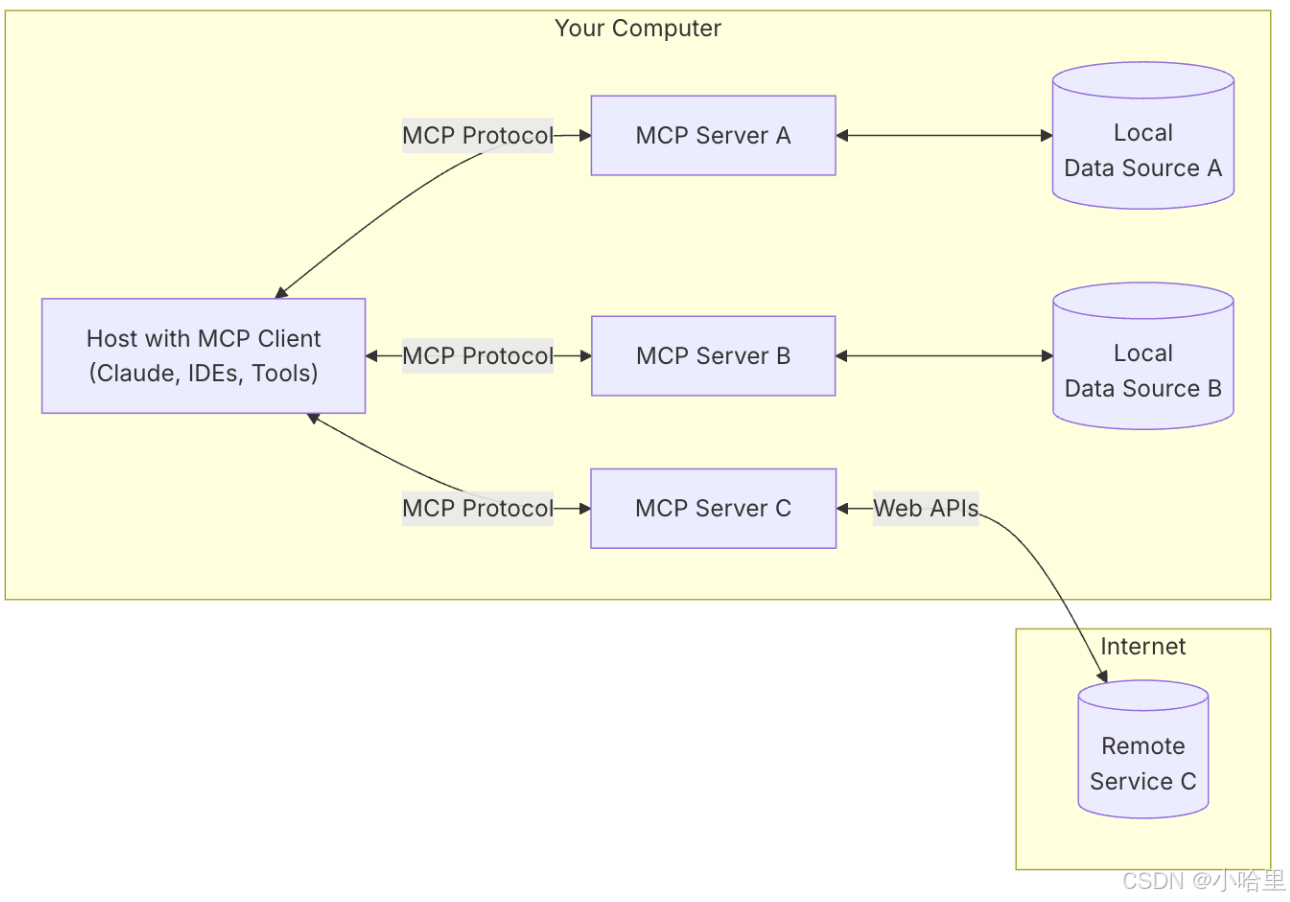
MCP协议的说明
-
MCP目前还没有一个广泛认可的通信协议或官方项目 1。
协议的开放性最重要的,封闭的协议没有未来。类似Anthropic MCP的技术,现在开源社区、标准化组织也都有探索。
Anthropic MCP是否能够成为最终的标准,谁都判断不了,但是未来肯定有这样的一个标准协议,能够让智能体相互通信,连接成一个智能体网络。
所以现在谁都想,成为智能体互联网时代的 HTTP。 -
一般的认为,MCP由 Anthropic 2024 年 11 月 首次提出并开源,通过定义标准化接口,允许大语言模型以一致的方式与各类外部系统互动,包括数据库、API和企业内部工具等。
-
MCP的内部协议,自主设计模式。
可以参考经典协议(如 MQTT、gRPC,HTTP,TCP等) -
AutoGPT 和 LangChain 是 AI 应用层框架。
解决模型调用、提示工程、记忆管理等,基于现有协议(如通过 HTTP 调用 OpenAI API 或 gRPC 调用 TensorFlow Serving)其核心是 AI 工作流,而非协议本身(当然也有开源对应的协议,并且在这基础上实现了更多的工具和功能),可类比http/rpc框架学习。 -
AutoGPT 和 LangChain 和 AnthropicMCP 没有直接联系。
AutoGPT/LangChain 是工具层,而 MCP 是模型层的优化技术。
在技术实现或设计理念上可能存在间接的相似性或互补性。

MCP开发框架
- autoGPT-175k, AgentGPT-35k-web版,(自主任务分解+工具调用)
框架特点:单Agent自主规划任务,调用工具链(如搜索、代码执行等)。
适用场景:自动化流程(如数据分析、报告生成)。
from langchain.agents import Tool
from langchain.agents import AgentExecutor
from langchain.agents import initialize_agent
from langchain.llms import OpenAI# 定义工具(如搜索、计算器)
def search(query):return "检索结果: " + querytools = [Tool(name="Search", func=search, description="用于搜索信息"),
]# 初始化Agent
llm = OpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)# 执行任务
agent.run("找出2023年诺贝尔物理学奖得主,并总结他们的贡献。")
- LangChain-108k(多Agent编排 + 记忆管理)
框架特点:支持多Agent协作,集成工具调用、记忆(ConversationBufferMemory)和外部知识库(RAG)。
核心模块:
Agent:任务执行单元。
Memory:保存对话历史。
Tools:外部API/函数调用。
from langchain.agents import AgentType, initialize_agent
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI# 定义多个工具
def get_weather(city):return f"{city}天气晴朗,25°C"tools = [Tool(name="Weather", func=get_weather, description="查询城市天气"),
]# 初始化记忆和Agent
memory = ConversationBufferMemory(memory_key="chat_history")
llm = OpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, memory=memory,verbose=True
)# 执行多轮任务
agent.run("北京天气如何?") # Agent调用Weather工具
agent.run("上海呢?") # 记忆保留上一轮上下文
MCP开发实践指南
- 1、开发流程
任务分解:将复杂目标拆解为子任务(如“数据分析→可视化→报告生成”)
Agent角色设计:为每个子任务分配Agent(如“数据清洗Agent”、“绘图Agent”)
工具集成:为Agent添加API调用、代码执行等能力
记忆管理:通过ConversationBufferMemory或向量数据库保存上下文。
调试优化:监控Agent决策路径,调整提示词(Prompt)或工具链。 - 2、关键挑战与解决
任务循环:Agent可能陷入无限分解。
方案:设置最大递归深度或超时机制。
工具可靠性:API调用失败。
方案:添加重试逻辑和fallback响应。
上下文过长:记忆超出模型token限制。
方案:使用摘要(Summarization)或向量检索关键信息。 - 3、进阶方向
动态Agent创建:根据任务需求实时生成新Agent(如MetaGPT的“演员模型”)
强化学习优化:通过RLHF调整Agent协作策略(如OpenAI的“过程监督”)
分布式Agent系统:跨设备部署Agent(如云端规划Agent+本地执行Agent)
参考资料:1 mcp项目, 2 mcp协议, 3 , 4, 5, 6