YOLOv8在单目向下多车辆目标检测中的应用
大家读完觉得我有帮助记得关注!!!
摘要
自动驾驶技术正逐步改变传统的汽车驾驶方式,标志着现代交通运输的一个重要里程碑。目标检测是自主系统的基石,在提高驾驶安全性、实现自主功能、提高交通效率和促进有效的应急响应方面发挥着至关重要的作用。然而,目前的环境感知雷达、道路感知摄像头和车辆传感器网络等技术面临着显著的挑战,包括高成本、易受天气和光照条件影响以及分辨率有限。为了解决这些限制,本文提出了一种基于YOLOv8的改进型自主目标检测网络。通过将结构重参数化技术、双向金字塔结构网络模型和一种新型检测流程集成到YOLOv8框架中,所提出的方法实现了对多尺度、小型和远程物体的高效和精确检测。实验结果表明,增强后的模型能够有效地检测大型和小型物体,检测精度达到65%,显示出相对于传统方法的显著进步。这种改进的模型在实际应用中具有巨大的潜力,非常适合自动驾驶竞赛,如中国大学生无人驾驶方程式大赛(FSAC),尤其擅长涉及单目标和小物体检测的场景。
关键词:YOLOv8;自主;安全;目标检测;多尺度;FSAC
1. 绪论
自动驾驶技术已经快速发展,具有提高安全性、交通效率、舒适性和环境友好性等优点[1][2]。它可以减少疲劳和注意力分散等人为错误,提高安全性,优化驾驶路径,缓解拥堵,并使乘客能够专注于其他活动[3]。然而,实现道路目标的高精度检测仍然是一个关键挑战[4]。
目标检测对于自动驾驶至关重要,直接影响安全性、自主性、交通效率和用户体验[5]。它使车辆能够识别和跟踪行人、车辆和障碍物,确保及时采取行动以避免碰撞并提高安全性。准确的检测支持自主决策、遵守交通规则以及无缝融入交通流,从而减少拥堵和出行时间。在紧急情况下,它有助于车辆迅速应对危险,保护乘客和行人。对于自动驾驶赛车,目标检测对于推进无人驾驶技术并在无人驾驶方程式赛车中实现完全自主至关重要。
目前的自动驾驶检测技术[6],包括雷达、摄像头[7]和车载传感器网络[8],面临着成本高、易受天气影响和分辨率限制等挑战。雷达的精度在恶劣天气和反射表面会降低,而摄像头虽然能有效地检测道路标志和车道线,但在光线不足以及雨或雾等天气条件下会受到影响[9]。车载传感器网络提供全面的环境感知,但涉及复杂的数据处理[10]。
2. YOLOV8改进了模型的框架结构
原始的YOLOv8模型在处理多尺度、小目标和远距离目标检测时,面临着适应性有限、特征提取不足以及信息流不畅等挑战。
本文通过结合结构重参数化、双向金字塔结构和新的检测流程,增强了基于YOLOv8的自主目标检测网络。这些改进旨在实现对多尺度、小型和远距离物体的高效和高精度检测。
结构重参数化技术优化了网络结构,增强了其对多尺度和小目标检测的适用性,且不牺牲精度。这种调整改进了对不同尺寸目标的检测。双向金字塔结构处理多尺度特征信息,更有效地捕捉空间和语义细节,这有助于检测远处和小目标。此外,新的检测流程结构优化了信息流,通过特征融合和信息传递等模块,提高了检查效率和准确性。图1展示了改进后的YOLOv8模型的框架,改进的详细解释如下。
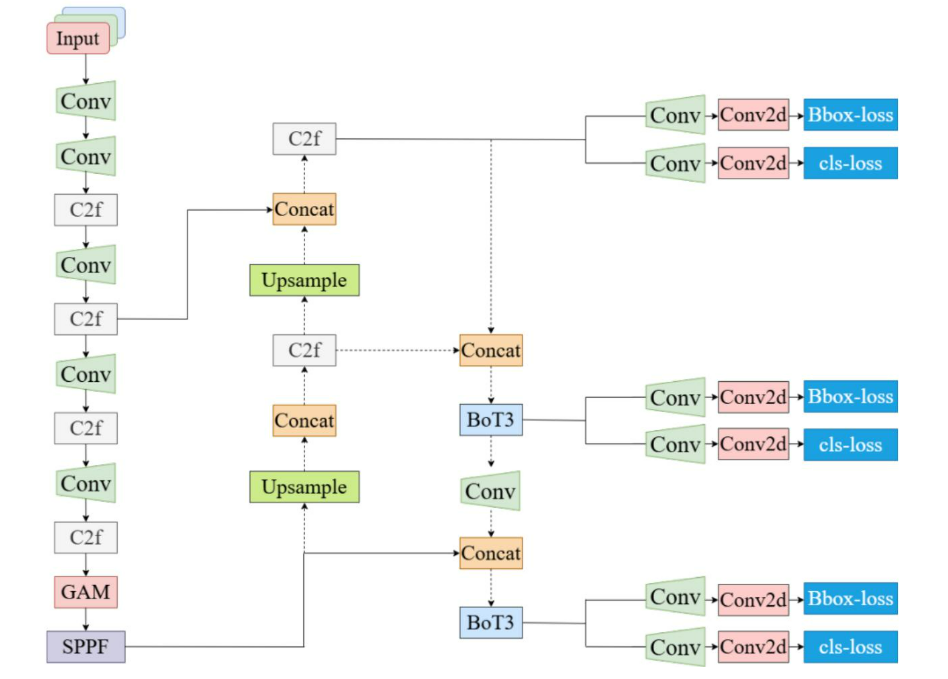
图 1:改进的 YOLOv8 模型结构。
2.1. 主干网络介绍
DBB(不同分支块)模型通过集成关注图像不同尺度、语义或方面的分支,增强了骨干网络的特征提取能力。通过使用这些分支块扩充原始骨干网络,该网络有效地捕获了多尺度和多语义信息,从而显著提高了对远处和小目标的检测能力。
在自动驾驶中,车辆必须迅速检测和识别障碍物和交通标志,包括远处和小型物体,如交通标志、车辆和行人。由于其尺寸和距离,这些物体可能显得模糊或细微,需要准确的检测和识别。通过结合不同的分支块模型,网络可以有效地整合多尺度和语义信息,从而增强其对图像内容的理解。
本文结合了多个DBB模块,以增强用于检测远处和小尺寸物体的骨干网络。为了补充改进后的骨干网络,结构重参数化技术被集成到C2f-DBB模块中,从而提高了检测速度和准确性,如图2所示。
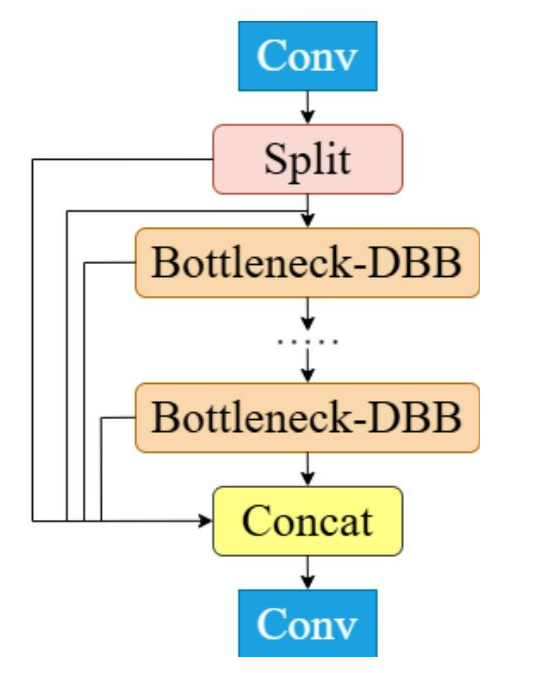
图2:将结构重参数化技术引入C2F-DBB模块。
2.2. 颈部结构引入双向金字塔结构网络模型
YOLOv8的颈部结构将来自骨干网络的特征图转换为优化的对象检测表示,执行融合、压缩、增强和调整,以提高网络性能和效率。
原始YOLOv8网络作为颈部结构使用的路径聚合特征金字塔网络(PAFPN)的一个主要局限性在于其单向性,这可能导致特征提取不完整。这限制了多尺度和语义特征的有效整合和利用,可能影响目标检测性能。
为了解决这一局限性,本文将双向金字塔网络模型引入颈部结构,保持与原始YOLOv8模型相似的传输模式,如图3所示。与单向金字塔结构相比,双向设计提供了更强的特征整合和灵活性,能够更全面地捕获信息,并提高自主目标检测的性能和准确性。
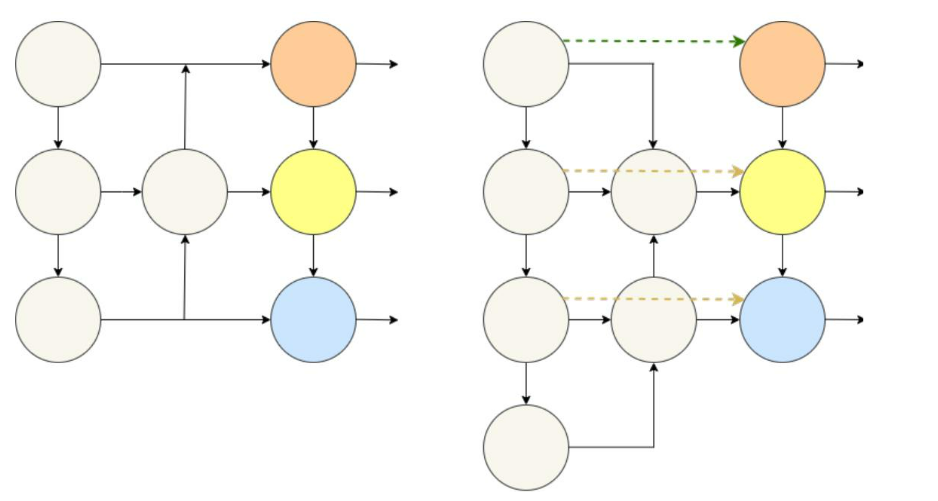
图 3:路径聚合特征金字塔网络与双向金字塔结构网络模型的比较。
2.3. 引入了一种新的检查管道结构模型
YOLOv8的颈部结构将来自骨干网络的特征图转换为针对目标检测优化的表示,结合了特征融合、压缩、增强和调整,以提高性能和效率。然而,原始YOLOv8的路径聚合特征金字塔网络(PAFPN)存在单向性问题,限制了多尺度和语义特征的整合和利用,这会影响检测性能。为了解决这个问题,引入了一个双向金字塔网络模型,如图3所示。与单向结构相比,双向设计增强了特征整合和灵活性,能够更全面地捕获信息,并提高检测性能和准确性。
图4:新型检测流水线结构模型的结构示意图。
3. 实验结果与讨论
3.1 实验条件设置
本文中使用的图像分辨率为1280。该模型使用SGD优化器训练了100轮,批处理大小为16,内存为64GB。
本文利用SODA-D和VisDrone数据集进行评估。SODA-D(无人机航拍图像中的小目标检测)专注于检测无人机航拍图像中的小目标,提供多种类别,为小目标检测研究提供丰富的数据。VisDrone是一个用于无人机视频分析和目标检测的大规模数据集,包含来自全球多个城市的航拍镜头,涵盖各种场景和环境条件。其挑战,如遮挡、部分可见性和小尺寸目标,需要算法具有高鲁棒性和高性能。这两个数据集都非常适合解决FSAC竞赛场景中的小目标检测需求。
3.2. 参数评估
为了证明所提出的改进模型的可靠性,基于YOLOv8模型,对SODAD和VisDrone数据集的评估参数进行了比较,其中YOLOv8模型采用了各种模块改进。这些比较的结果分别在表1和表2中给出。
本研究中的评估参数包括精确率 (P)、召回率 (R)、mAP@0.5、GFLOPS、Params 和 FPS。这些指标共同为缺陷检测算法提供了全面的评估,涵盖了准确性和效率。
表1:基于SODA-D数据库的模型参数比较

表1:基于VISDRONE数据库的模型参数比较

如表所示,改进后的模型对较大和较小目标的检测精度均达到65%,这归功于YOLOv8的增强。图5和图6展示了在相同条件下,改进前后YOLOv8模型的PR曲线。改进后的模型总体mAP@0.5比原始模型高约7%,最大mAP值为0.716,显著超过了未改进的结构。这些结果表明,对YOLOv8模型的提出的改进极大地提高了检测精度,突显了这项工作的重要性。
3.3. 实验可视化
本文将提出的模型与基于YOLOv8技术的基线方法进行了比较。使用了来自SODA-D数据库的实验图像,展示了原始图像、提出的模型和基线方法的结果,如图7所示。改进后的模型表现出更高的检测精度和更精确的物体定位。

图 7:本文的模型与基线方法进行了比较。
4. 结论
自主技术正在迅速发展,其中目标检测在确保驾驶安全、自主性、交通效率和应急响应方面发挥着关键作用。传统检测技术面临着成本高、易受天气影响和分辨率低等局限性。本文提出了一种改进的基于YOLOv8的自主目标检测网络,结合了结构重参数化、双向金字塔结构和新的检测流程,以实现对多尺度、小型和远距离物体的有效和精确检测。实验结果表明,对于较大和较小的物体,检测精度为65.2%,突出了模型的有效性。所提出的方法在实际应用和自主竞赛中具有应用前景,例如中国大学生无人驾驶方程式大赛(FSAC),尤其是在单目标和小目标检测场景中。