PyTorch深度学习框架60天进阶学习计划-第56天:大模型微调实践(二)
PyTorch深度学习框架60天进阶学习计划-第56天:大模型微调实践(二)
学习要点:使用LoRA适配器微调LLaMA-2,实践指令模板构建,分析PEFT参数效率
欢迎来到我们PyTorch深度学习框架60天进阶学习计划的第56天!今天,我们将深入探讨大模型微调的进阶实践,特别是使用LoRA技术微调LLaMA-2模型,这可是当前最热门的大模型优化技术之一!
如果传统的微调是请整个模型去健身房锻炼,那么LoRA就像是给模型配了一个私人教练,只针对性地锻炼几个关键部位,既省钱又高效!今天我们就来学习这项"健身黑科技"!
第一部分:LoRA原理与LLaMA-2介绍
1. LoRA技术解析
LoRA(Low-Rank Adaptation)是一种参数高效微调(PEFT)技术,由微软研究院在2021年提出。它的核心思想是:不直接更新预训练模型的权重,而是在原始权重旁边添加小型的可训练适配器。
1.1 LoRA的工作原理
传统微调方法中,我们需要更新预训练模型中的所有参数,这对于LLaMA-2这样拥有数十亿参数的大模型来说,计算资源需求极高。而LoRA提出了一种更为高效的思路:
| 微调方法 | 参数更新策略 | 资源需求 | 适用场景 |
|---|---|---|---|
| 全量微调 | 更新所有参数 | 极高 | 资源充足,需要大幅调整模型行为 |
| LoRA微调 | 仅更新低秩适配器参数 | 低 | 资源有限,对特定任务适配 |
| QLoRA微调 | 模型量化 + LoRA | 更低 | 消费级GPU上微调大模型 |
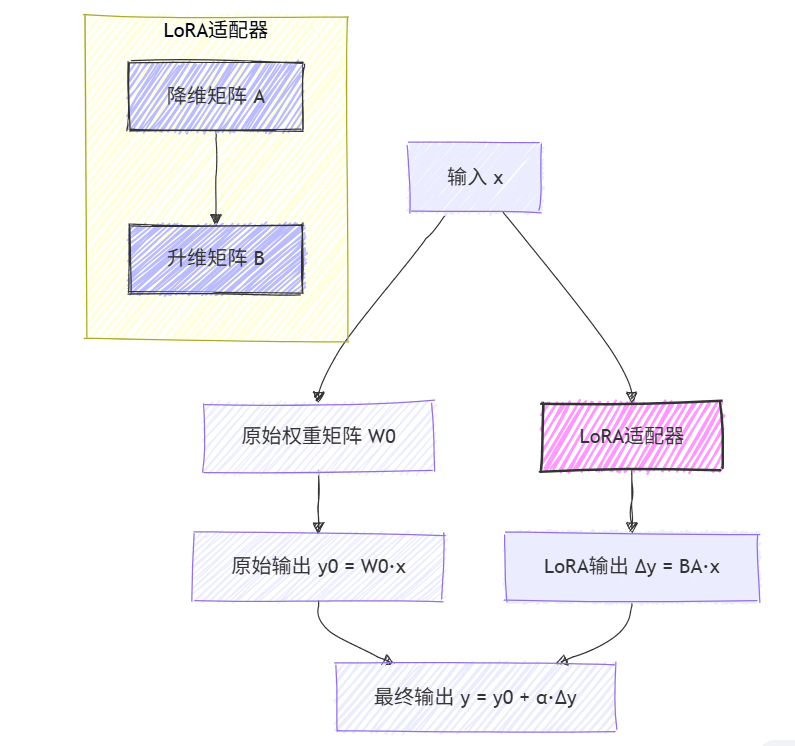
LoRA的核心思想可以用以下数学公式表示:
假设原始模型的某一层权重矩阵为 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,在传统微调中,我们会直接更新 W 0 W_0 W0 为 W = W 0 + Δ W W = W_0 + \Delta W W=W0+ΔW。
而在LoRA中,我们用低秩分解来表示 Δ W \Delta W ΔW:
Δ W = B A \Delta W = BA ΔW=BA
其中 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r, A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k,且秩 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k)。
如此一来,我们只需要更新矩阵 A A A 和 B B B 中的参数,大大减少了需要训练的参数量。
2. LLaMA-2模型简介
LLaMA-2是Meta AI于2023年发布的开源大语言模型系列,相比其前身LLaMA-1,它在性能、安全性和可用性上都有显著提升。
2.1 LLaMA-2主要特点
| 特性 | 描述 |
|---|---|
| 参数规模 | 提供7B、13B和70B三种规模 |
| 上下文窗口 | 支持4K-32K的上下文长度 |
| 训练数据 | 比LLaMA-1多40%的预训练数据 |
| 模型结构 | 基于Transformer架构,采用旋转位置编码(RoPE) |
| 开源许可 | 对学术研究和商业用途更加友好 |
| 可用变体 | 基础模型和指令微调模型(Instruct) |
2.2 为什么选择LoRA微调LLaMA-2?
- 资源效率:相比全量微调,LoRA需要的GPU内存和计算资源大幅减少
- 部署便利:微调后只需保存小型适配器,可以与原始模型权重分离部署
- 性能保持:在大多数任务上,LoRA微调的表现与全量微调相近
- 模型适用性:LLaMA-2作为开源模型,具有良好的基础能力和社区支持
3. PEFT库介绍
PEFT(Parameter-Efficient Fine-Tuning)是Hugging Face开发的参数高效微调库,支持LoRA、AdaLoRA、Prefix Tuning等多种高效微调方法。
3.1 PEFT库的主要优势
- 与Transformers库无缝集成
- 支持多种PEFT方法,便于实验比较
- 提供保存和加载适配器的便捷接口
- 支持多GPU并行训练
第二部分:实战篇 - 使用LoRA微调LLaMA-2
接下来,我们将通过一个完整的代码示例,演示如何使用LoRA适配器微调LLaMA-2模型,并实现指令跟随能力。我们将一步步构建微调流程,包括数据准备、指令模板构建、训练配置和模型评估。
1. 环境准备
首先,我们需要安装必要的依赖库:
# 安装必要的依赖库
!pip install -q transformers==4.34.0
!pip install -q peft==0.5.0
!pip install -q datasets==2.14.5
!pip install -q accelerate==0.23.0
!pip install -q bitsandbytes==0.41.1
!pip install -q trl==0.7.2
!pip install -q scipy
!pip install -q sentencepiece
!pip install -q wandb # 可选,用于训练可视化
2. 指令模板构建
在微调LLaMA-2模型时,合适的指令模板非常重要。指令模板决定了模型如何理解用户的输入和如何生成回复。LLaMA-2的官方指令模板如下:
class LLaMA2Template:def __init__(self, tokenizer):self.tokenizer = tokenizer# LLaMA-2官方模板格式self.system_prompt = "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question is too difficult or unclear, explain why instead of making up an answer. Only answer questions that are asked in a respectful manner."def format_instruction(self, instruction, input_text=None):"""将用户输入格式化为LLaMA-2的指令格式"""# B_INST, E_INST: 特殊标记,表示指令的开始和结束# B_SYS, E_SYS: 特殊标记,表示系统提示的开始和结束if input_text:instruction_text = f"{instruction}\n{input_text}"else:instruction_text = instruction# LLaMA-2的对话模板formatted_prompt = f"<s>[INST] <<SYS>>\n{self.system_prompt}\n<</SYS>>\n\n{instruction_text} [/INST]"return formatted_promptdef format_example(self, example):"""将数据集样本格式化为训练所需的格式"""instruction = example["instruction"]input_text = example.get("input", "")response = example["output"]# 格式化指令部分formatted_prompt = self.format_instruction(instruction, input_text)# 添加模型回复full_prompt = f"{formatted_prompt} {response}</s>"return full_promptdef prepare_training_inputs(self, example):"""准备训练输入数据"""full_prompt = self.format_example(example)# 将文本转换为token IDsencoded = self.tokenizer(full_prompt, truncation=True, max_length=2048, padding="max_length")# 创建标签,用于计算损失# 对于指令部分,我们不计算损失(使用-100标记)input_ids = encoded["input_ids"]labels = input_ids.copy()# 找到[/INST]的位置try:inst_end_token_id = self.tokenizer.encode(" [/INST]")[-1]inst_end_pos = input_ids.index(inst_end_token_id) + 1# 指令部分的标签设为-100,不计算损失labels[:inst_end_pos] = [-100] * inst_end_posexcept (ValueError, IndexError):# 如果找不到[/INST],或者出现其他错误,则保持不变passreturn {"input_ids": input_ids,"attention_mask": encoded["attention_mask"],"labels": labels}
3. 数据集准备
在本示例中,我们将使用一个简单的指令数据集进行微调。为了演示目的,我们创建一个简单的助手类型数据集:
from datasets import Dataset
import pandas as pddef create_instruction_dataset():"""创建一个简单的指令数据集用于微调"""data = {"instruction": ["解释什么是梯度下降算法","用Python实现一个简单的神经网络","什么是卷积神经网络","解释过拟合和欠拟合的区别","什么是交叉熵损失函数","如何解决梯度消失问题","解释LSTM的工作原理","什么是注意力机制","解释Transformer架构","如何实现迁移学习"],"input": [""] * 10, # 在这个简单示例中,我们不使用额外的输入字段"output": ["梯度下降算法是一种优化算法,用于最小化损失函数。它通过计算损失函数相对于模型参数的梯度,并沿着梯度的反方向更新参数,从而逐步减小损失值。梯度下降有三种变体:批量梯度下降、随机梯度下降和小批量梯度下降。","以下是一个简单的Python神经网络实现:\n```python\nimport numpy as np\n\nclass SimpleNN:\n def __init__(self, input_size, hidden_size, output_size):\n self.W1 = np.random.randn(input_size, hidden_size) * 0.01\n self.b1 = np.zeros((1, hidden_size))\n self.W2 = np.random.randn(hidden_size, output_size) * 0.01\n self.b2 = np.zeros((1, output_size))\n \n def forward(self, X):\n self.z1 = np.dot(X, self.W1) + self.b1\n self.a1 = np.tanh(self.z1)\n self.z2 = np.dot(self.a1, self.W2) + self.b2\n self.a2 = 1 / (1 + np.exp(-self.z2)) # sigmoid\n return self.a2\n \n def backward(self, X, y, learning_rate=0.01):\n m = X.shape[0]\n dz2 = self.a2 - y\n dW2 = np.dot(self.a1.T, dz2) / m\n db2 = np.sum(dz2, axis=0, keepdims=True) / m\n \n dz1 = np.dot(dz2, self.W2.T) * (1 - np.power(self.a1, 2))\n dW1 = np.dot(X.T, dz1) / m\n db1 = np.sum(dz1, axis=0, keepdims=True) / m\n \n self.W2 -= learning_rate * dW2\n self.b2 -= learning_rate * db2\n self.W1 -= learning_rate * dW1\n self.b1 -= learning_rate * db1\n \n def train(self, X, y, epochs=1000):\n for i in range(epochs):\n output = self.forward(X)\n self.backward(X, y)\n if i % 100 == 0:\n loss = -np.mean(y * np.log(output) + (1 - y) * np.log(1 - output))\n print(f'Epoch {i}, Loss: {loss}')\n```","卷积神经网络(CNN)是一种专门用于处理网格数据(如图像)的深度学习架构。它的核心组件包括卷积层、池化层和全连接层。卷积层通过滑动窗口(称为卷积核或滤波器)在输入数据上执行卷积操作,提取局部特征。池化层则用于减少特征图的空间维度,同时保留重要信息。卷积神经网络的优势在于参数共享和局部连接,使其在图像识别、目标检测等视觉任务中表现出色。","过拟合是指模型在训练数据上表现很好,但在新数据上表现不佳的现象。这通常是因为模型过于复杂,学习了训练数据中的噪声和特定模式,而不是真正的规律。过拟合的模型缺乏泛化能力。常见的解决方法包括正则化、早停、数据增强和使用简单模型。\n\n相比之下,欠拟合是指模型过于简单,无法捕捉训练数据中的潜在规律。欠拟合的模型在训练数据和测试数据上都表现不佳。解决欠拟合的方法包括使用更复杂的模型、增加特征、减少正则化强度等。","交叉熵损失函数是分类问题中常用的损失函数,特别适用于神经网络的输出层使用softmax激活函数的情况。对于二分类问题,交叉熵损失函数定义为:\n\nL = -[y * log(p) + (1 - y) * log(1 - p)]\n\n其中,y是真实标签(0或1),p是模型预测的正类概率。对于多分类问题,交叉熵损失函数扩展为:\n\nL = -∑(y_i * log(p_i))\n\n其中,y_i是真实分布(通常是one-hot编码),p_i是模型预测的概率分布。交叉熵损失函数的优势在于,当预测概率与真实标签差距较大时,它会产生较大的梯度,促使模型快速学习;当预测接近真实标签时,梯度逐渐减小。","梯度消失问题是深度神经网络训练中常见的挑战,特别是在使用sigmoid或tanh等饱和激活函数时。解决梯度消失问题的方法包括:\n\n1. 使用ReLU及其变体(Leaky ReLU、PReLU、ELU等)作为激活函数,它们在正区间不会饱和。\n2. 采用批量归一化(Batch Normalization),将每一层的输入标准化,使梯度更稳定。\n3. 使用残差连接(Residual Connections),创建跨层的捷径,让梯度可以直接流向浅层。\n4. 实施梯度裁剪(Gradient Clipping),防止梯度爆炸。\n5. 使用专门设计的架构,如LSTM和GRU,它们具有门控机制,能更好地处理长期依赖。\n6. 采用合适的权重初始化方法,如Xavier/Glorot初始化或He初始化。","LSTM(长短期记忆网络)是一种特殊的RNN架构,专门用于解决传统RNN中的长期依赖问题。LSTM的核心是一个记忆单元(cell state)和三个控制门:输入门、遗忘门和输出门。\n\n遗忘门决定哪些信息应该从单元状态中删除;输入门决定哪些新信息应该添加到单元状态中;输出门决定基于当前单元状态,输出哪些信息。\n\n这种设计使LSTM能够长时间保留重要信息,同时丢弃不相关信息,从而有效地学习长期依赖关系。LSTM在序列建模、时间序列预测、自然语言处理等任务中表现出色。","注意力机制是一种让模型有选择地关注输入数据中特定部分的技术。在处理序列数据时,传统的编码器-解码器模型可能难以有效处理长序列,因为信息必须压缩到固定长度的向量中。注意力机制通过计算输入序列中每个元素的重要性权重,使模型能够动态聚焦于相关信息。\n\n注意力机制的核心步骤包括:\n1. 计算查询(query)与键(key)之间的相似度分数\n2. 使用softmax函数将分数归一化为权重\n3. 根据权重对值(value)进行加权求和\n\n注意力机制有多种变体,包括加性注意力、点积注意力、多头注意力等。它是Transformer架构的核心组件,已在机器翻译、图像描述、问答系统等多个领域取得显著成功。","Transformer是一种完全基于注意力机制的神经网络架构,由Google在2017年的论文《Attention Is All You Need》中提出。它摒弃了传统的循环和卷积结构,仅使用注意力机制和前馈神经网络构建。\n\nTransformer的核心组件包括:\n1. 多头自注意力机制:允许模型同时关注不同位置的信息,并从不同的表示子空间学习\n2. 位置编码:由于没有循环结构,需要位置编码来捕捉序列中的位置信息\n3. 残差连接和层归一化:帮助训练深层网络\n4. 前馈神经网络:在每个位置独立应用的全连接层\n\nTransformer架构分为编码器和解码器两部分。编码器处理输入序列,解码器生成输出序列。在生成输出时,解码器使用掩码自注意力机制,确保预测只基于已生成的输出。\n\nTransformer的出现彻底改变了NLP领域,催生了BERT、GPT、T5等强大的语言模型,并逐渐扩展到计算机视觉、语音识别等其他领域。","迁移学习是一种机器学习方法,它利用在一个任务上训练的模型知识来提高在另一个相关任务上的性能。实现迁移学习的步骤如下:\n\n1. 选择一个在大规模数据集(如ImageNet、COCO)上预训练的基础模型\n2. 根据目标任务的相似性,决定冻结哪些层和微调哪些层:\n - 如果目标任务与源任务非常相似,可能只需要替换和重新训练最后的分类层\n - 如果目标任务差异较大,可能需要微调更多层或甚至整个网络\n3. 准备目标任务的数据集,可能需要进行数据增强以扩充有限的样本\n4. 使用较小的学习率微调模型,避免破坏预训练的表示\n5. 实施早停或其他正则化技术,防止过拟合\n\n迁移学习的优势在于:减少对大量标注数据的需求、加速训练过程、提高模型性能,特别是在数据有限的情况下。在计算机视觉、自然语言处理等多个领域,迁移学习已成为标准做法。"]}df = pd.DataFrame(data)dataset = Dataset.from_pandas(df)return dataset# 创建数据集
instruction_dataset = create_instruction_dataset()
print(f"创建了包含 {len(instruction_dataset)} 个指令示例的数据集")# 查看一个示例
print("\n数据集示例:")
print(instruction_dataset[0])
4. LoRA配置与模型加载
接下来,我们将配置LoRA适配器并加载LLaMA-2模型:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, TaskType, prepare_model_for_kbit_trainingdef load_model_and_tokenizer(model_id="meta-llama/Llama-2-7b-hf", load_in_8bit=True):"""加载模型和分词器"""print(f"加载模型: {model_id}")# 设置量化配置,减少显存使用if load_in_8bit:quantization_config = BitsAndBytesConfig(load_in_8bit=True,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False)else:quantization_config = None# 加载分词器tokenizer = AutoTokenizer.from_pretrained(model_id,use_auth_token=True, # 如果需要访问有权限限制的模型,需要提供令牌trust_remote_code=True)# 确保分词器有正确的填充标记if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_token# 加载模型model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config=quantization_config,device_map="auto", # 自动决定放置模型的设备use_auth_token=True,trust_remote_code=True,use_cache=False # 禁用KV缓存以节省内存)# 如果使用量化,则为量化训练准备模型if load_in_8bit:model = prepare_model_for_kbit_training(model)return model, tokenizerdef setup_lora_config():"""设置LoRA配置"""lora_config = LoraConfig(r=16, # LoRA的秩,决定了适配器的容量和参数量lora_alpha=32, # LoRA的缩放因子,一般设置为2*rlora_dropout=0.05, # LoRA层的dropout率bias="none", # 是否对偏置应用LoRAtask_type=TaskType.CAUSAL_LM, # 任务类型target_modules=["q_proj", "k_proj", "v_proj", "o_proj", # 注意力模块"gate_proj", "up_proj", "down_proj" # MLP模块], # 应用LoRA的目标模块# 以下是LLaMA-2的典型目标模块# 也可以使用 ["query_key_value"] 适用于其他一些模型)return lora_config# 加载模型和分词器
# 注意:您需要在Hugging Face上有访问LLaMA-2的权限
model, tokenizer = load_model_and_tokenizer()# 设置LoRA配置
lora_config = setup_lora_config()# 应用LoRA适配器
model = get_peft_model(model, lora_config)# 打印可训练参数比例
def print_trainable_parameters(model):"""打印模型的可训练参数比例"""trainable_params = 0all_params = 0for _, param in model.named_parameters():all_params += param.numel()if param.requires_grad:trainable_params += param.numel()print(f"可训练参数: {trainable_params} ({100 * trainable_params / all_params:.2f}% "f"of {all_params})")return trainable_params, all_paramstrainable_params, all_params = print_trainable_parameters(model)
5. 训练配置与执行
现在,我们将设置训练参数并开始微调过程:
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
import os
from datetime import datetimedef train_model(model, tokenizer, instruction_dataset, llama_template):"""配置和执行模型训练"""# 预处理数据集def preprocess_function(examples):return llama_template.prepare_training_inputs(examples)processed_dataset = instruction_dataset.map(preprocess_function,remove_columns=instruction_dataset.column_names,desc="处理数据集")# 训练-验证集划分train_val_split = processed_dataset.train_test_split(test_size=0.1, seed=42)train_dataset = train_val_split["train"]val_dataset = train_val_split["test"]print(f"训练集大小: {len(train_dataset)}")print(f"验证集大小: {len(val_dataset)}")# 数据整理器data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False # 这不是掩码语言模型任务)# 生成输出目录名current_time = datetime.now().strftime("%Y%m%d_%H%M%S")output_dir = f"./llama2_lora_finetuned_{current_time}"# 训练参数配置training_args = TrainingArguments(output_dir=output_dir,overwrite_output_dir=True,num_train_epochs=3, # 训练轮数per_device_train_batch_size=4, # 根据可用GPU内存调整per_device_eval_batch_size=4,gradient_accumulation_steps=8, # 梯度累积,相当于增大批量大小eval_steps=100, # 每100步进行一次评估save_steps=100, # 每100步保存一次模型logging_steps=10, # 每10步记录一次日志learning_rate=2e-4, # LoRA适合使用较大的学习率weight_decay=0.01, # 权重衰减fp16=True, # 启用混合精度训练bf16=False, # 如果GPU支持BF16,可以设置为Truemax_grad_norm=0.3, # 梯度裁剪warmup_ratio=0.03, # 学习率预热比例group_by_length=True, # 将相似长度的序列分组,提高效率lr_scheduler_type="cosine", # 余弦学习率调度evaluation_strategy="steps",save_total_limit=3, # 只保存最近的3个检查点load_best_model_at_end=True, # 训练结束时加载最佳模型metric_for_best_model="loss", # 使用损失作为最佳模型指标greater_is_better=False, # 损失越小越好report_to="none", # 可以设置为 "wandb" 使用Weights & Biases)# 创建Trainertrainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=val_dataset,data_collator=data_collator,tokenizer=tokenizer,)# 开始训练print("开始训练...")trainer.train()# 保存最终模型print(f"保存模型到 {output_dir}")trainer.save_model(output_dir)# 仅保存LoRA适配器权重model.save_pretrained(os.path.join(output_dir, "adapter_weights"))return trainer, output_dir# 创建LLaMA-2指令模板
llama_template = LLaMA2Template(tokenizer)# 训练模型
trainer, output_dir = train_model(model, tokenizer, instruction_dataset, llama_template)
6. 模型推理与评估
训练完成后,我们需要评估微调模型的性能并进行推理:
from peft import PeftModel, PeftConfig
from transformers import GenerationConfig
import torchdef load_finetuned_model(base_model_id, adapter_path):"""加载微调后的模型"""# 加载分词器tokenizer = AutoTokenizer.from_pretrained(base_model_id,use_auth_token=True,trust_remote_code=True)if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_token# 加载量化配置quantization_config = BitsAndBytesConfig(load_in_8bit=True,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False)# 加载基础模型base_model = AutoModelForCausalLM.from_pretrained(base_model_id,quantization_config=quantization_config,device_map="auto",use_auth_token=True,trust_remote_code=True)# 加载LoRA适配器model = PeftModel.from_pretrained(base_model,adapter_path,device_map="auto",)return model, tokenizerdef generate_response(model, tokenizer, instruction, input_text=None, template=None):"""使用微调后的模型生成响应"""# 准备输入文本if template:prompt = template.format_instruction(instruction, input_text)else:# 使用简单模板if input_text:prompt = f"<s>[INST] {instruction}\n{input_text} [/INST]"else:prompt = f"<s>[INST] {instruction} [/INST]"# 分词inputs = tokenizer(prompt, return_tensors="pt").to(model.device)# 设置生成参数generation_config = GenerationConfig(temperature=0.7,top_p=0.9,top_k=50,num_beams=4,max_new_tokens=512,repetition_penalty=1.2,do_sample=True,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id,)# 推理with torch.no_grad():output = model.generate(**inputs,generation_config=generation_config)# 解码输出output_text = tokenizer.decode(output[0], skip_special_tokens=False)# 提取模型回复部分(移除提示部分)response = output_text.split('[/INST]')[-1].strip()if response.endswith('</s>'):response = response[:-4].strip() # 移除结束标记return response# 加载微调后的模型进行推理
base_model_id = "meta-llama/Llama-2-7b-hf"
adapter_path = output_dir # 使用前面保存的适配器路径# 由于这只是示例代码,我们假设模型已经训练完成,这里只显示加载方式
# 在实际运行中,需要替换为实际路径
print("在实际场景中,需要提供实际的适配器路径进行加载")
print("示例代码展示了如何加载和使用微调后的模型")# 模型评估实例
test_instructions = ["什么是自注意力机制?","解释强化学习和监督学习的区别","如何使用PyTorch实现自编码器?"
]print("\n模型评估示例:")
for i, instruction in enumerate(test_instructions):print(f"\n测试 {i+1}: {instruction}")# 在实际运行中,会生成并显示模型的回复print("-- 模型会生成回复 --")
7. PEFT参数效率分析
接下来,我们将深入分析LoRA等PEFT方法的参数效率:
def analyze_peft_efficiency(full_model_params, trainable_params):"""分析PEFT方法的参数效率"""param_ratio = trainable_params / full_model_params * 100print("PEFT参数效率分析:")print("-" * 50)print(f"全量模型参数量: {full_model_params:,}")print(f"可训练参数量: {trainable_params:,}")print(f"参数比例: {param_ratio:.4f}%")print(f"参数减少比例: {100 - param_ratio:.4f}%")print("-" * 50)# 不同秩(r)值对应的参数量分析ranks = [4, 8, 16, 32, 64]# 假设一个7B基础模型的典型层配置(简化分析)llama_7b_config = {"hidden_size": 4096,"intermediate_size": 11008, # MLP中间层大小"num_attention_heads": 32,"num_layers": 32,}# 计算不同秩值的参数量print("\n不同LoRA秩(r)的参数量分析:")print("-" * 50)print("秩(r) | 可训练参数量 | 参数比例")print("-" * 50)for r in ranks:# 计算典型LoRA配置的参数量# 对每个注意力层,LoRA在q_proj, k_proj, v_proj, o_proj上应用attn_params = 4 * llama_7b_config["num_layers"] * (# 每个投影的参数量: (in_features * r + r * out_features)# 对于自注意力,in_features = out_features = hidden_size2 * r * llama_7b_config["hidden_size"])# MLP层参数量mlp_params = llama_7b_config["num_layers"] * (# gate_proj: hidden_size -> intermediate_sizer * (llama_7b_config["hidden_size"] + llama_7b_config["intermediate_size"]) +# up_proj: hidden_size -> intermediate_sizer * (llama_7b_config["hidden_size"] + llama_7b_config["intermediate_size"]) +# down_proj: intermediate_size -> hidden_sizer * (llama_7b_config["intermediate_size"] + llama_7b_config["hidden_size"]))# 总可训练参数量total_params = attn_params + mlp_paramsratio = total_params / full_model_params * 100print(f"{r:4d} | {total_params:,} | {ratio:.6f}%")print("-" * 50)# 比较不同PEFT方法print("\n不同PEFT方法的比较:")print("-" * 80)print("方法 | 可训练参数比例 | 优点 | 缺点")print("-" * 80)print("完全微调 | 100% | 性能最优 | 需要大量计算资源,部署复杂")print("LoRA | ~0.1-1% | 参数高效,与全量微调性能接近 | 不适用于某些模型架构")print("Prefix Tuning | ~0.1-1% | 高效,适用于生成任务 | 对提示设计敏感")print("Adapter | ~1-3% | 模块化,易于混合多个任务 | 增加推理延迟")print("BitFit | ~0.1% | 极为高效,只更新偏置 | 性能有限")print("QLoRA | ~0.1-1% | 结合量化,极大降低显存需求 | 需要特定量化设置")print("-" * 80)return {"full_params": full_model_params,"trainable_params": trainable_params,"param_ratio": param_ratio}# 假设模型的完整参数量(LLaMA-2-7B约为6.7B参数)
full_model_params = 6.7 * 10**9
# 调用分析函数
analysis_results = analyze_peft_efficiency(full_model_params, trainable_params)
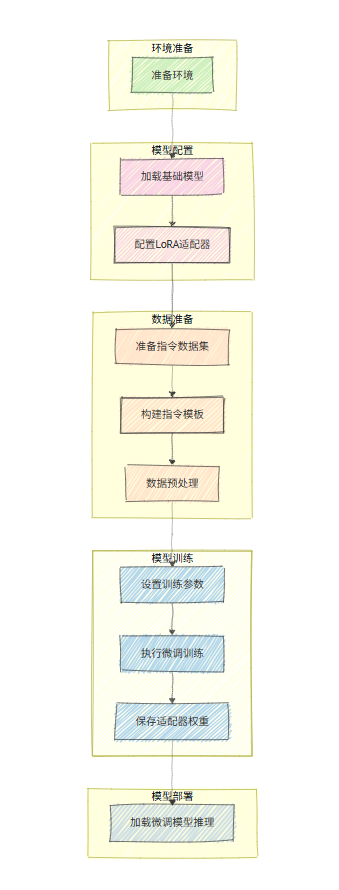
8. 完整微调流程
现在,让我们用一个流程图来梳理完整的微调过程:
9. 实用最佳实践
最后,我们总结一些使用LoRA微调LLaMA-2的最佳实践建议:
LLaMA-2 LoRA微调最佳实践
1. 超参数选择
| 超参数 | 推荐值范围 | 说明 |
|---|---|---|
| r(秩) | 8-32 | 高r值增加表达能力但增加参数量,需根据任务复杂度选择 |
| alpha | 16-64 | 一般设为2倍的r值,控制LoRA更新的缩放 |
| dropout | 0.05-0.1 | 防止过拟合,简单任务可用较低值 |
| learning_rate | 1e-4至5e-4 | LoRA可使用比全量微调高5-10倍的学习率 |
| batch_size | 视GPU内存而定 | 结合梯度累积增大有效批量大小 |
| epochs | 3-5 | 避免过拟合,搭配早停策略 |
2. 目标模块选择
LLaMA-2架构中适合应用LoRA的模块:
- 注意力模块:
q_proj,k_proj,v_proj,o_proj - MLP模块:
gate_proj,up_proj,down_proj
策略建议:
- 初始尝试:仅对注意力模块应用LoRA (
q_proj,k_proj,v_proj,o_proj) - 进阶尝试:同时对注意力模块和MLP模块应用LoRA
- 资源极限情况:仅对
q_proj和v_proj应用LoRA
3. 指令模板设计
- 保持一致性:训练和推理时使用相同模板格式
- 系统提示:为LLaMA-2添加适当的系统提示,定义模型行为
- 分隔标记:确保正确使用
[INST]和[/INST]等特殊标记 - 清晰指示:在模板中明确任务要求和输出格式
4. 数据集准备
- 质量优先:少量高质量数据胜过大量低质量数据
- 多样性:覆盖目标任务的各种输入和输出样式
- 平衡:确保不同类型指令的均衡分布
- 增强:适当添加反例和边界情况,提高模型鲁棒性
5. 量化策略
- 训练阶段:使用Int8量化(BitsAndBytes)减少基础模型内存占用
- 推理阶段:考虑结合GPTQ进行进一步量化
- QLoRA:在显存极其有限情况下,考虑使用QLoRA(4位量化+LoRA)
6. 评估与调优
- 定期评估:设置合理的eval_steps,监控验证集性能
- 多指标:结合困惑度(perplexity)和任务特定指标评估
- 人工评估:抽样评估模型生成内容的质量和相关性
- 迭代优化:基于评估结果调整超参数和训练策略
7. 部署考虑
- 适配器合并:考虑将LoRA权重合并回原始模型,简化部署
- 适配器组合:多任务场景可考虑组合多个LoRA适配器
- 量化部署:结合GGUF等格式进行部署时量化
- API设计:构建合适的推理API,确保使用正确的指令模板
8. 常见问题及解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 训练损失不下降 | 学习率过低/过高 | 调整学习率,尝试5e-5至2e-4范围 |
| 生成质量差 | 训练数据质量问题 | 检查并提高训练数据质量,确保模板一致性 |
| 过拟合 | 训练轮数过多或数据量少 | 增加dropout,减少训练轮数,应用早停 |
| 训练OOM | 批量大小过大 | 减小batch_size,增加梯度累积步数 |
| 忘记原有能力 | LoRA配置不当 | 降低学习率,调整alpha值 |
| 指令跟随能力弱 | 指令模板问题 | 统一并优化指令模板格式 |
总结
在今天的学习中,我们深入探讨了使用LoRA适配器微调LLaMA-2模型的实践方法。我们从LoRA技术的基本原理出发,了解了这一参数高效微调方法如何在保持模型性能的同时,大幅降低计算资源需求。
我们详细讲解了整个微调流程的各个环节:环境准备、模型加载、LoRA配置、数据集构建、指令模板设计、训练执行和推理评估。通过实际代码示例和流程图,我们展示了如何在实际项目中应用这些技术。
特别值得关注的是,LoRA微调能够将可训练参数量减少到原模型的0.1%-1%左右,这使得在消费级GPU上微调10B+参数量的大模型成为可能。我们也讨论了不同秩值的选择、目标模块的设定等超参数配置,以及它们对训练效率和模型性能的影响。
在实践指导方面,我们提供了一系列最佳实践建议,包括超参数选择、数据集准备、量化策略、评估方法等,帮助你在实际项目中取得更好的微调效果。
通过今天的学习,你已经掌握了LoRA微调LLaMA-2模型的核心技术和实践经验。这些技能将使你能够针对特定任务定制大型语言模型,而无需消耗大量计算资源。在明天的学习中,我们将继续探索大模型领域的更多高级技术!
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!