使用IDEA开发Spark Maven应用程序【超详细教程】
一、创建项目
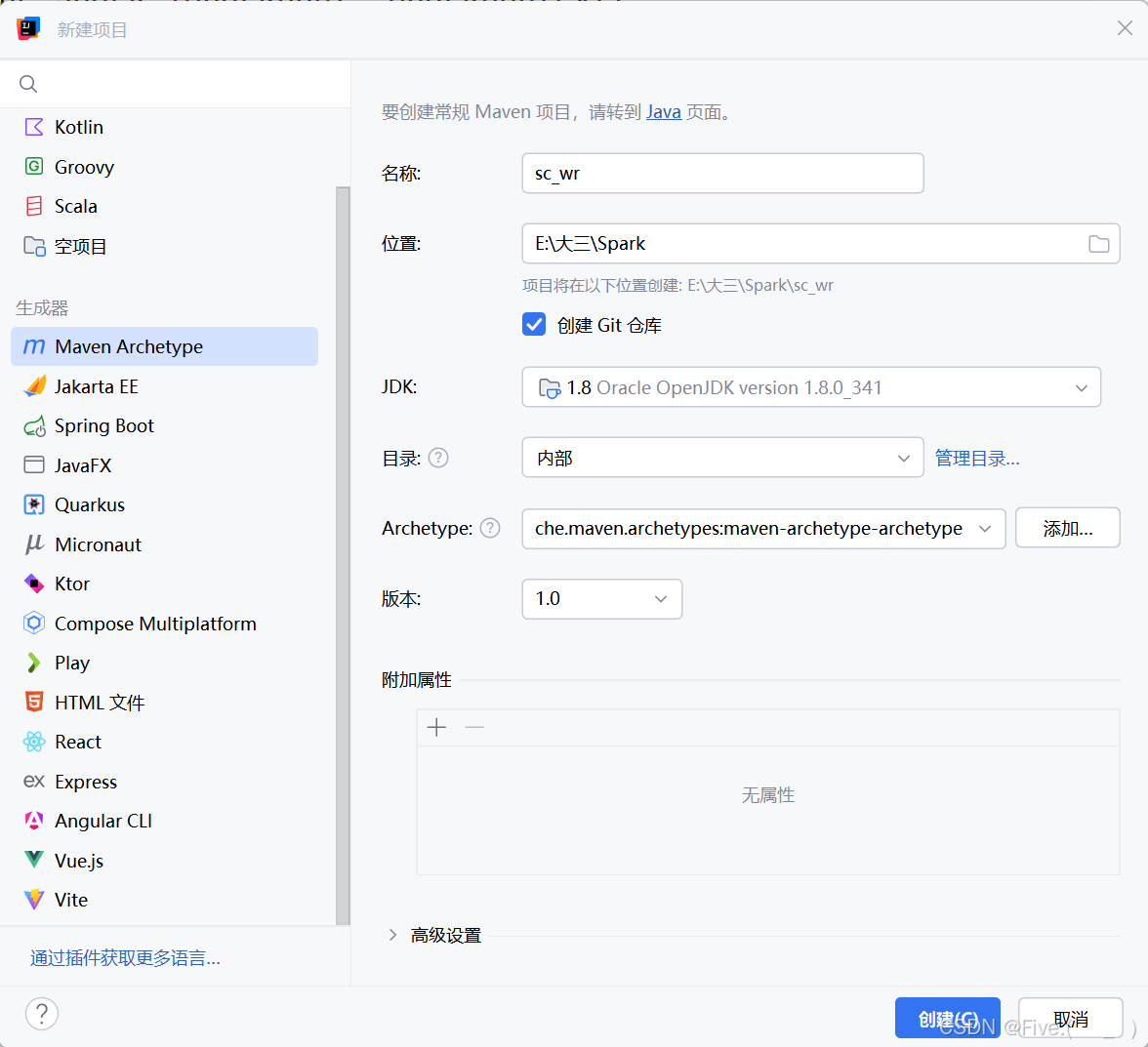
创建maven项目
二、修改pom.xml文件
创建好项目后,在pom.xml中改为:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>sc01</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.8</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.11</artifactId><version>2.4.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib-local_2.11</artifactId><version>2.4.0</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>4.5.3</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>
</project>
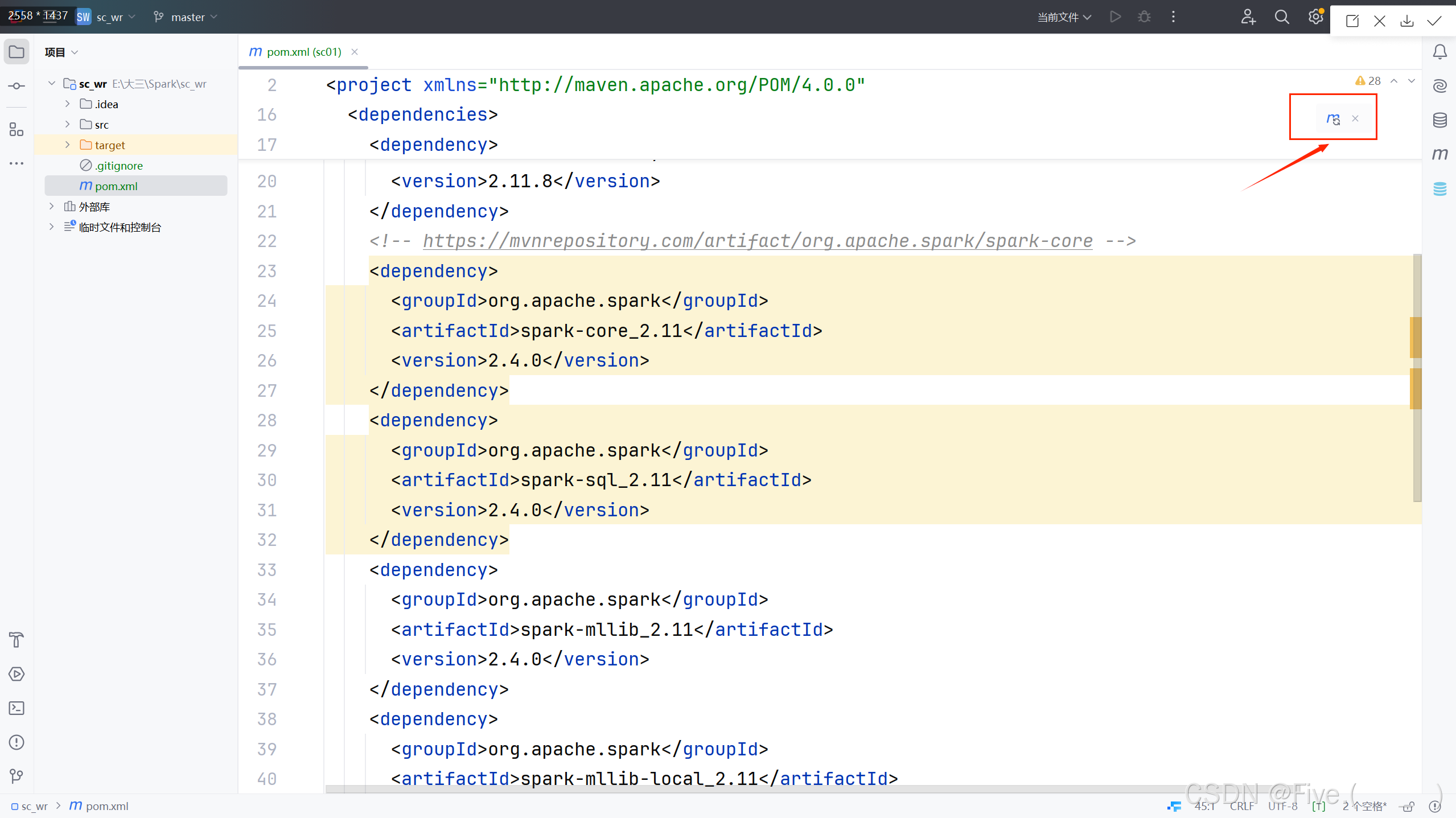
然后点击一下右上角的刷新按钮
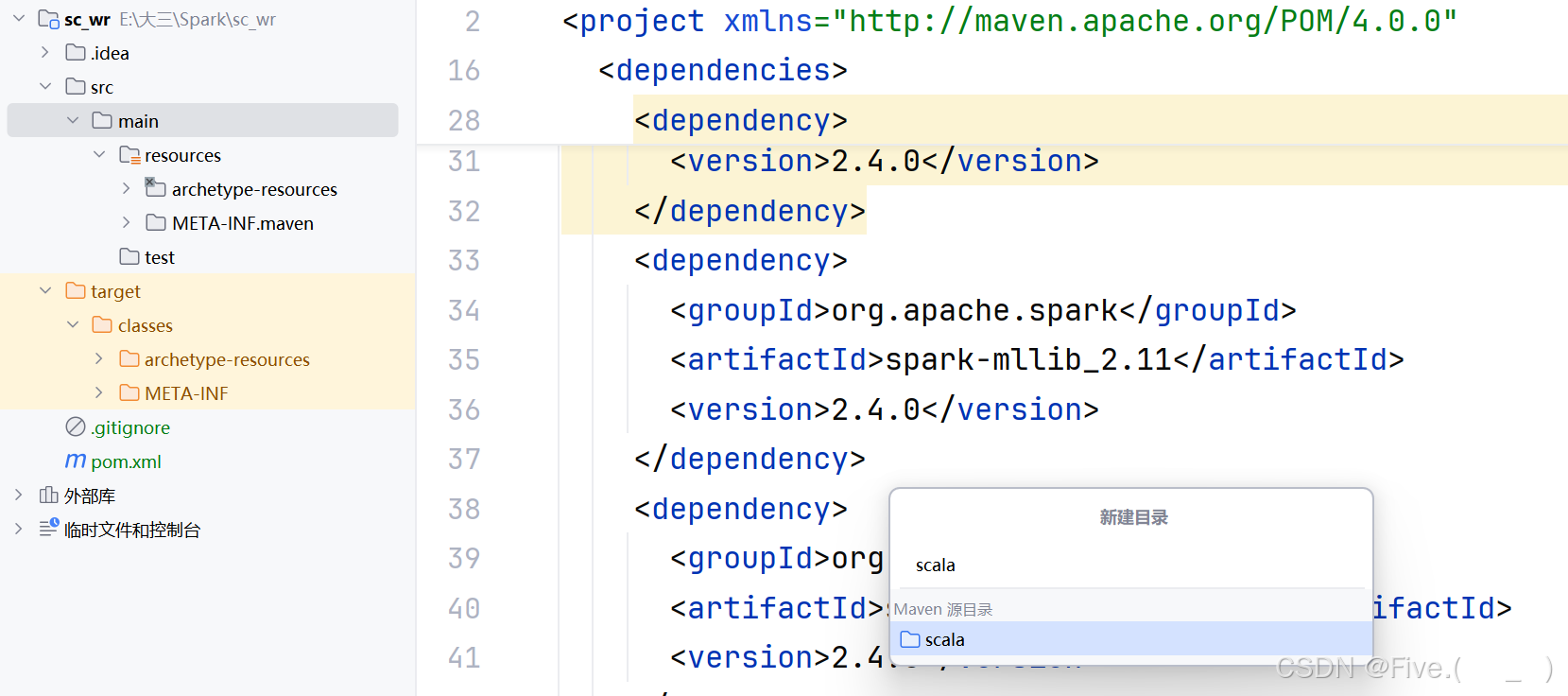
项目src/main/下创建scala目录
再在src下创建test/scala
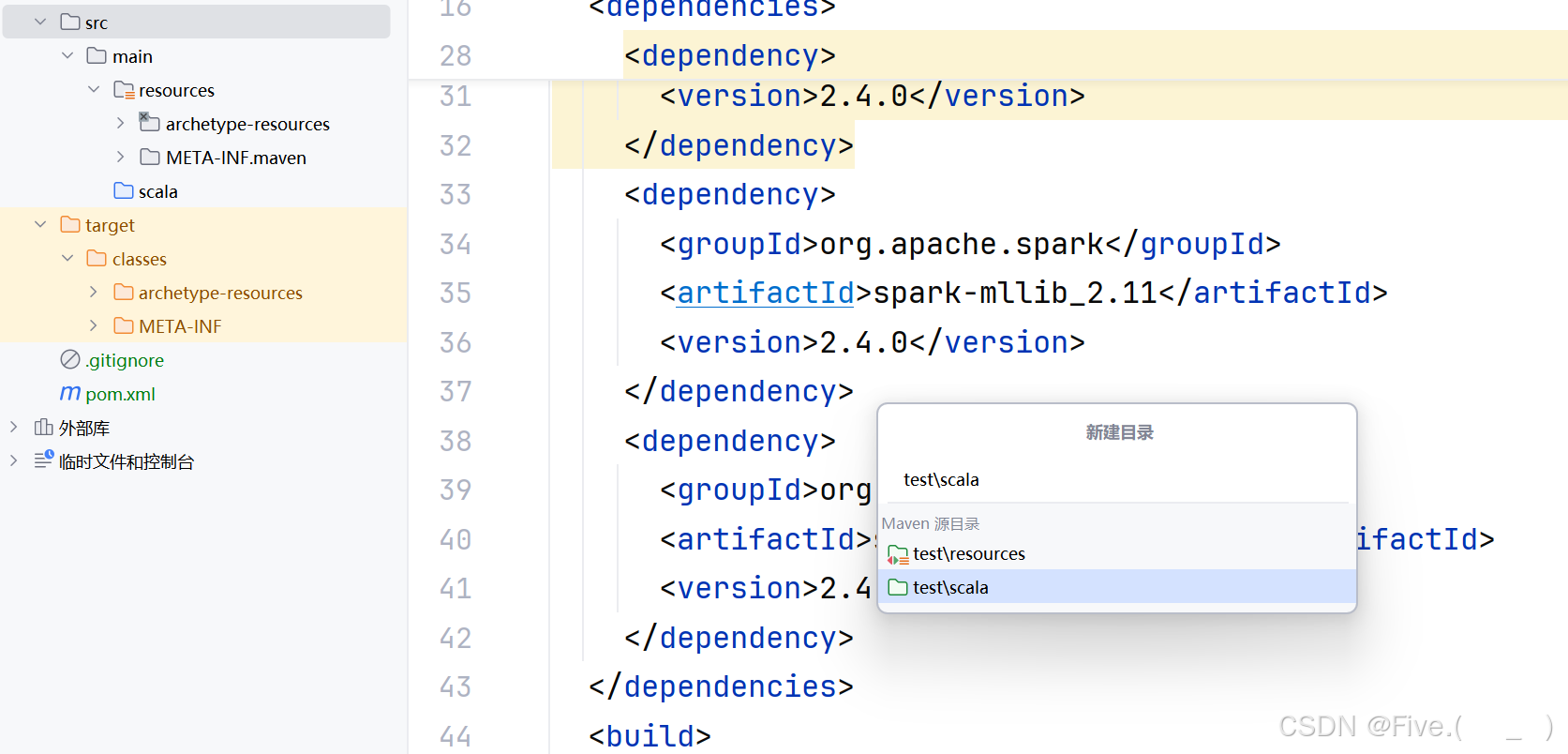
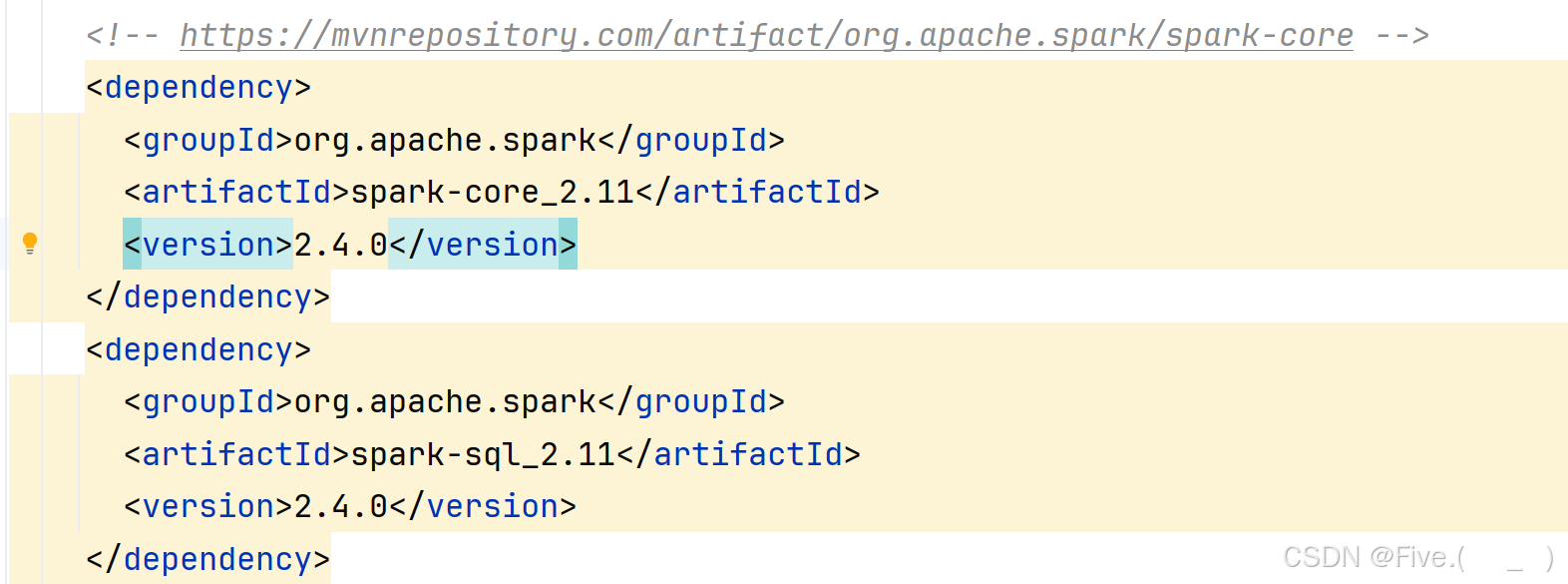
依赖已在maven中添加,如图,官网跳转【Maven】
三、构建项目结构
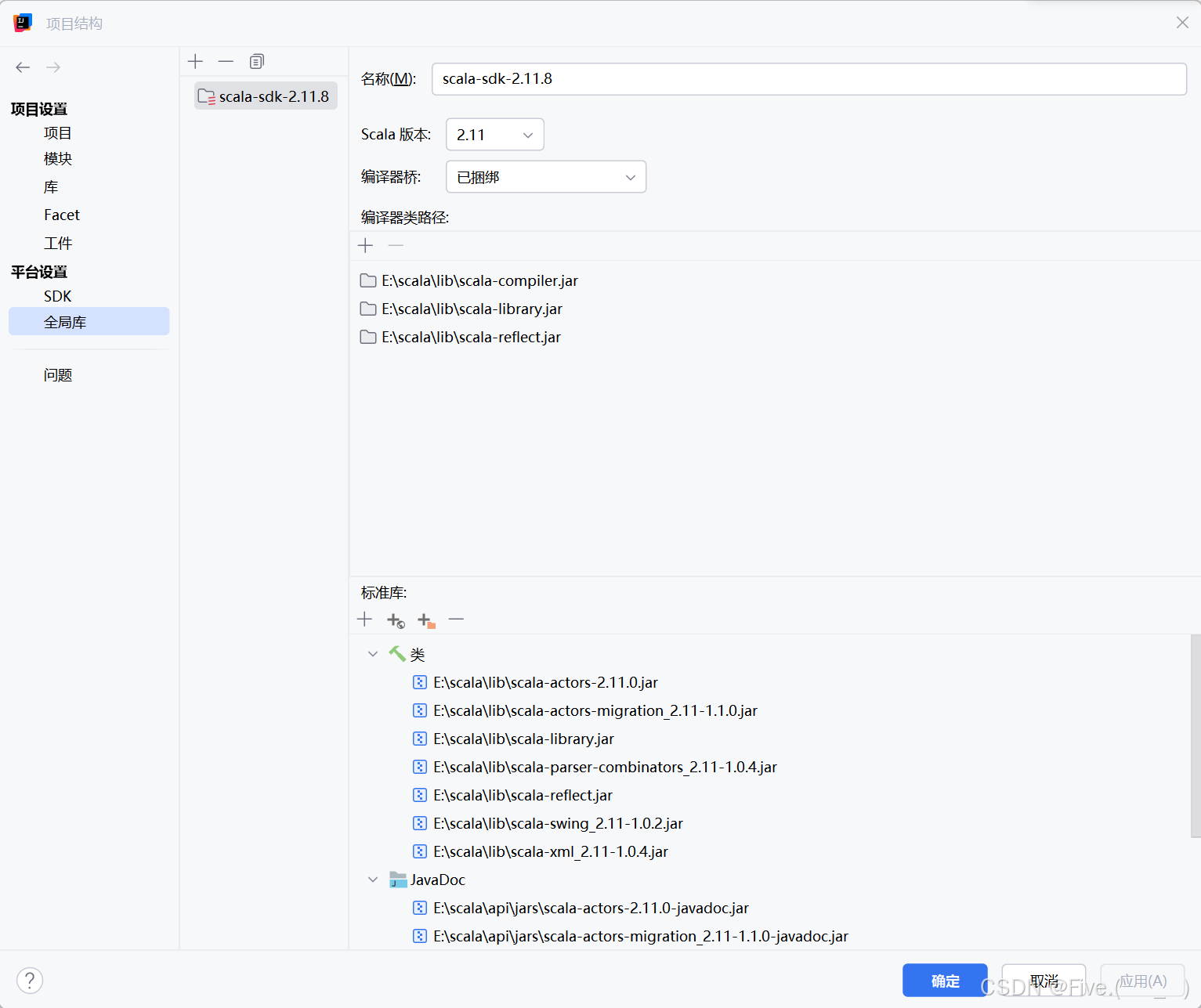
在 文件/项目结构下找到全局库【Global Libraries]
删除后【最开始应该是空空的啥也没有】,重新添加一遍scala-sdk就可以创建scala-class
确定使用的scala-sdk-2.11.8
点击"应用”,即可完成
再右键src/main/scala下新建Scala类\文件,选择Object文件,写好文件名称
我这里创建wordcount程序
import org.apache.spark.{SparkConf, SparkContext}
object mywordcound {def main(args: Array[String]): Unit = {val con = new SparkConf().setMaster("local").setAppName("WordCount")val sc = new SparkContext(con)sc.textFile("E:/abc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)}
}点击运行,运行结果如图: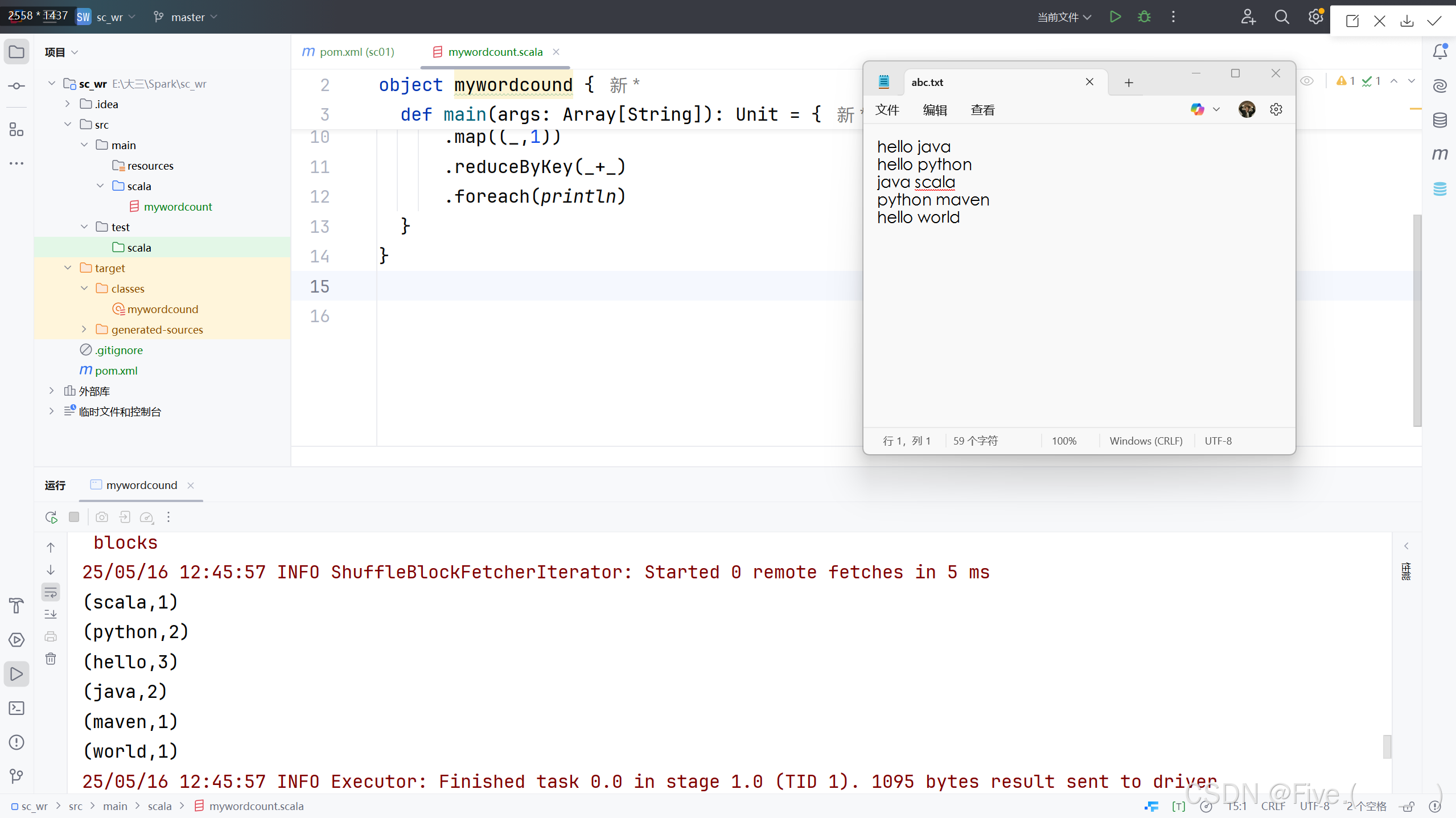
四、消除多余日志信息
若只想要结果没有那么多INFO日志信息,可在src/main/resources/下创建log4j.properties文件,内容填写:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n# Set the default spark-shell log level to ERROR. When running the spark-shell,the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR五、重点报错问题
在运行时会出现报错:Could not locate executable null\bin\winutils.exe in the Hadoop binaries
报错解决办法
(1)下载winutils.exe
(2)在windows创建指定目录
(3)将winutils.exe放进新建好的bin下
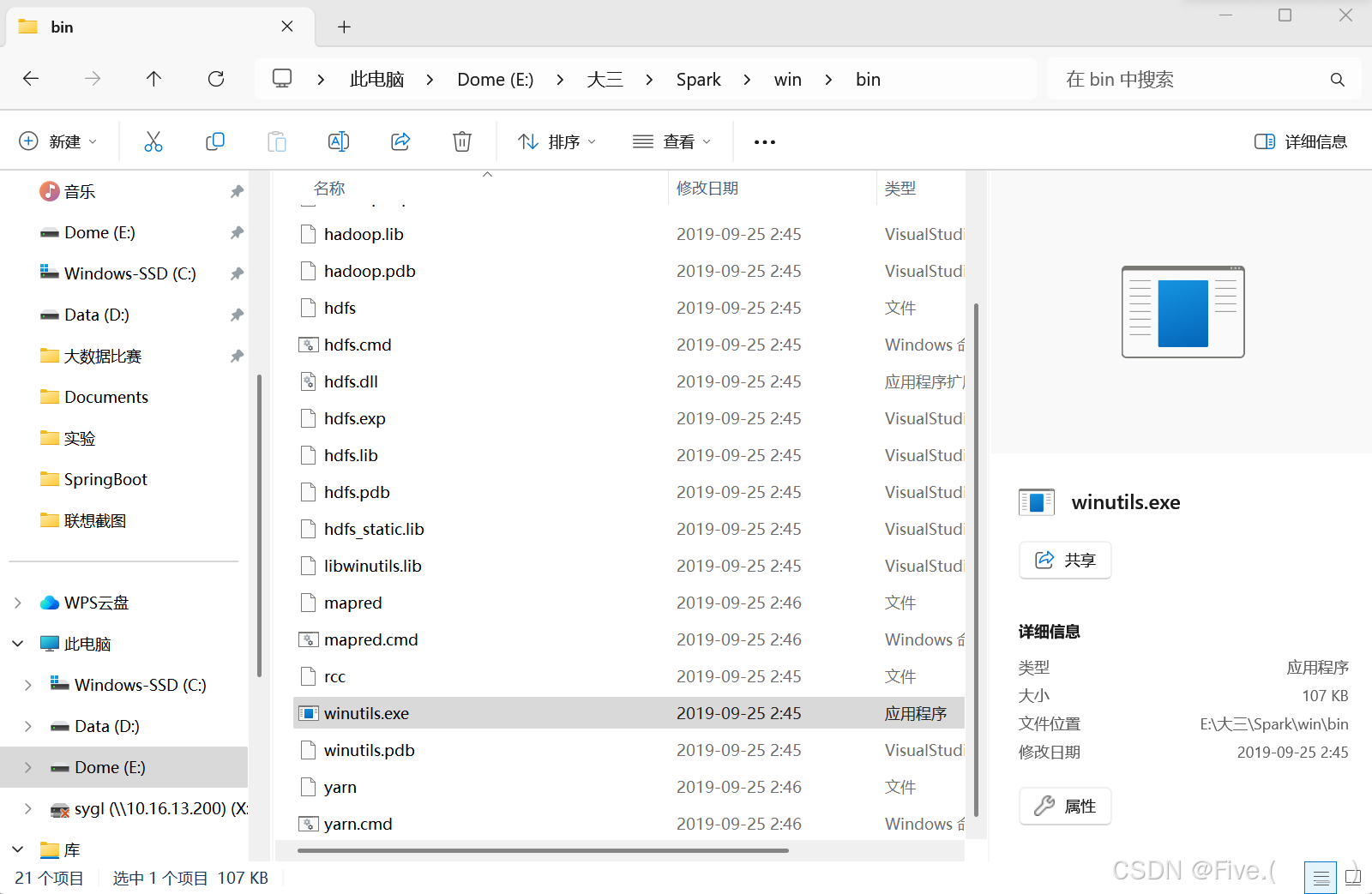
再在设置--系统--系统信息--高级系统设置中
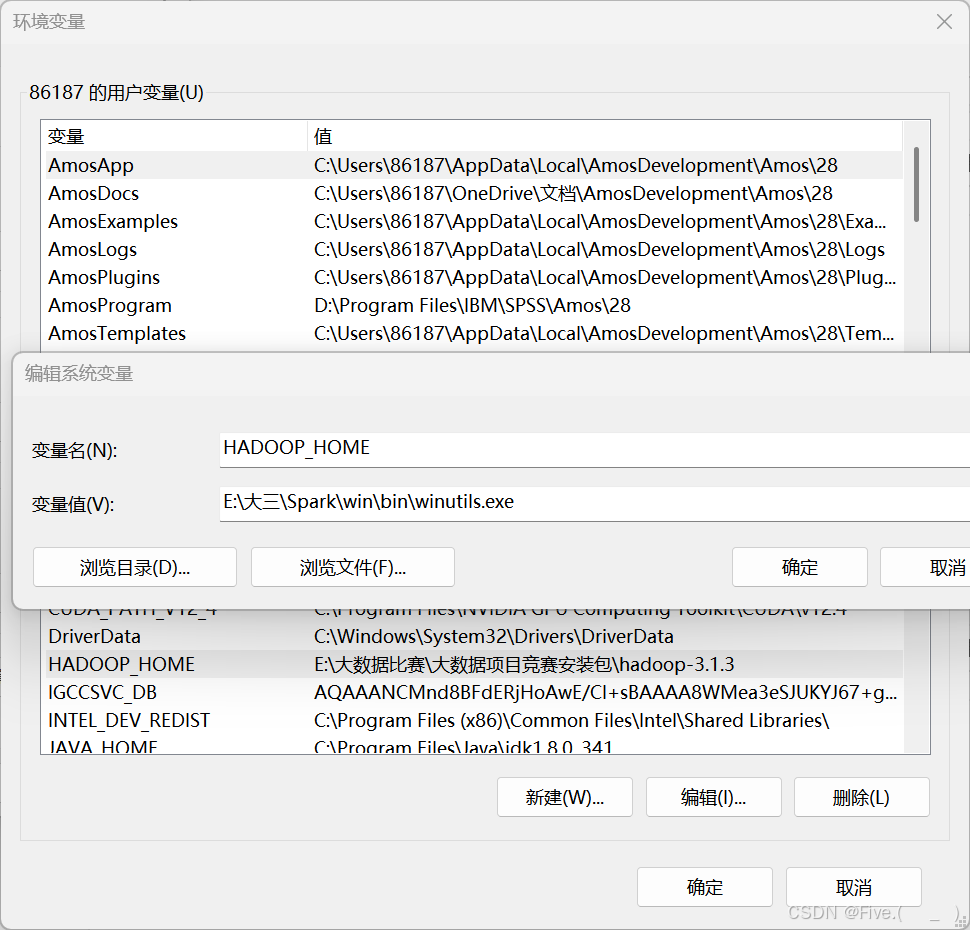
配置hadoop环境变量
HADOOP_HOME 及对应的winutils.exe文件位置前的bin的上一个文件夹即可!
不是E:\大三\Spark\win\bin ! 而是 E:\大三\Spark\win 即可!

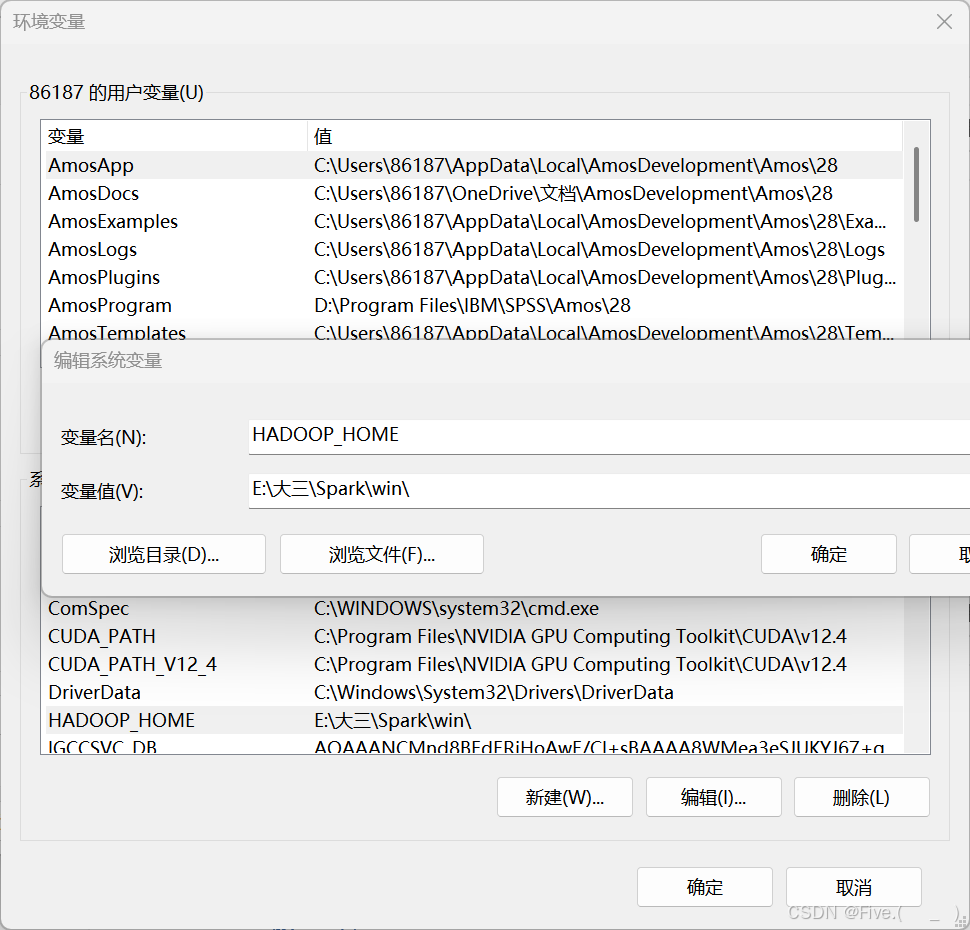
再在path变量中添加
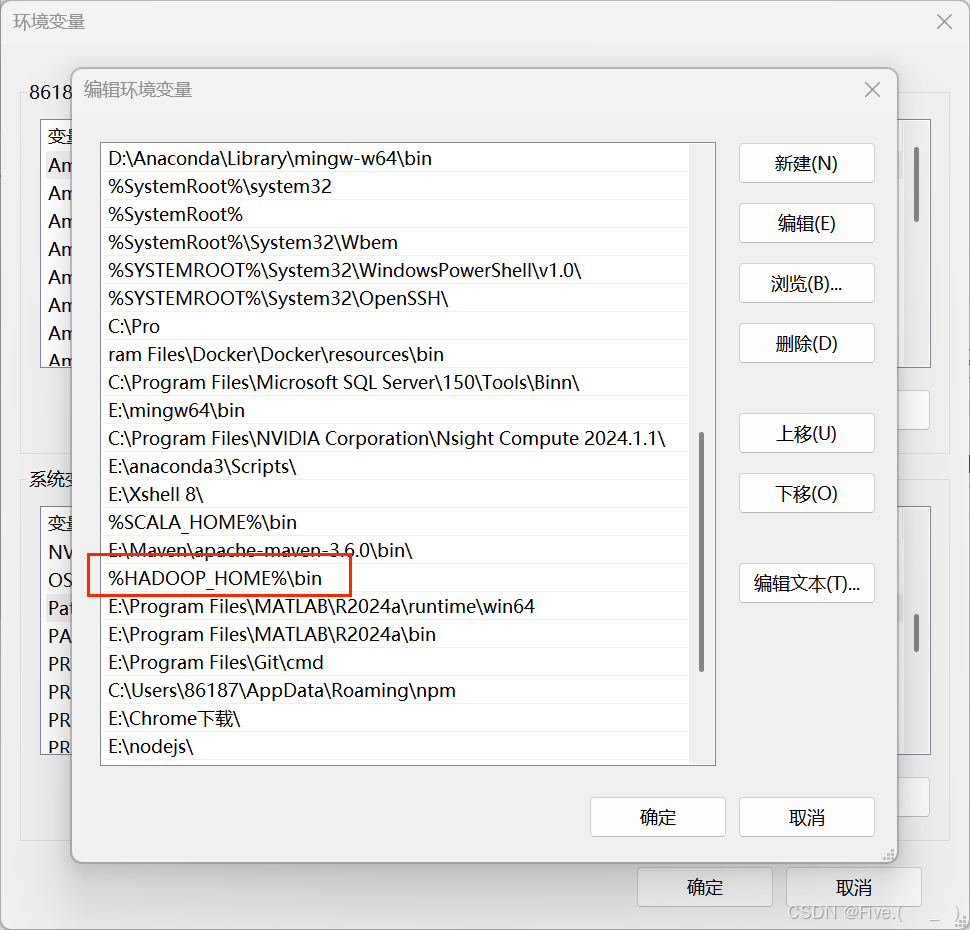
最后重启idea程序-->完美解决
重新运行程序:
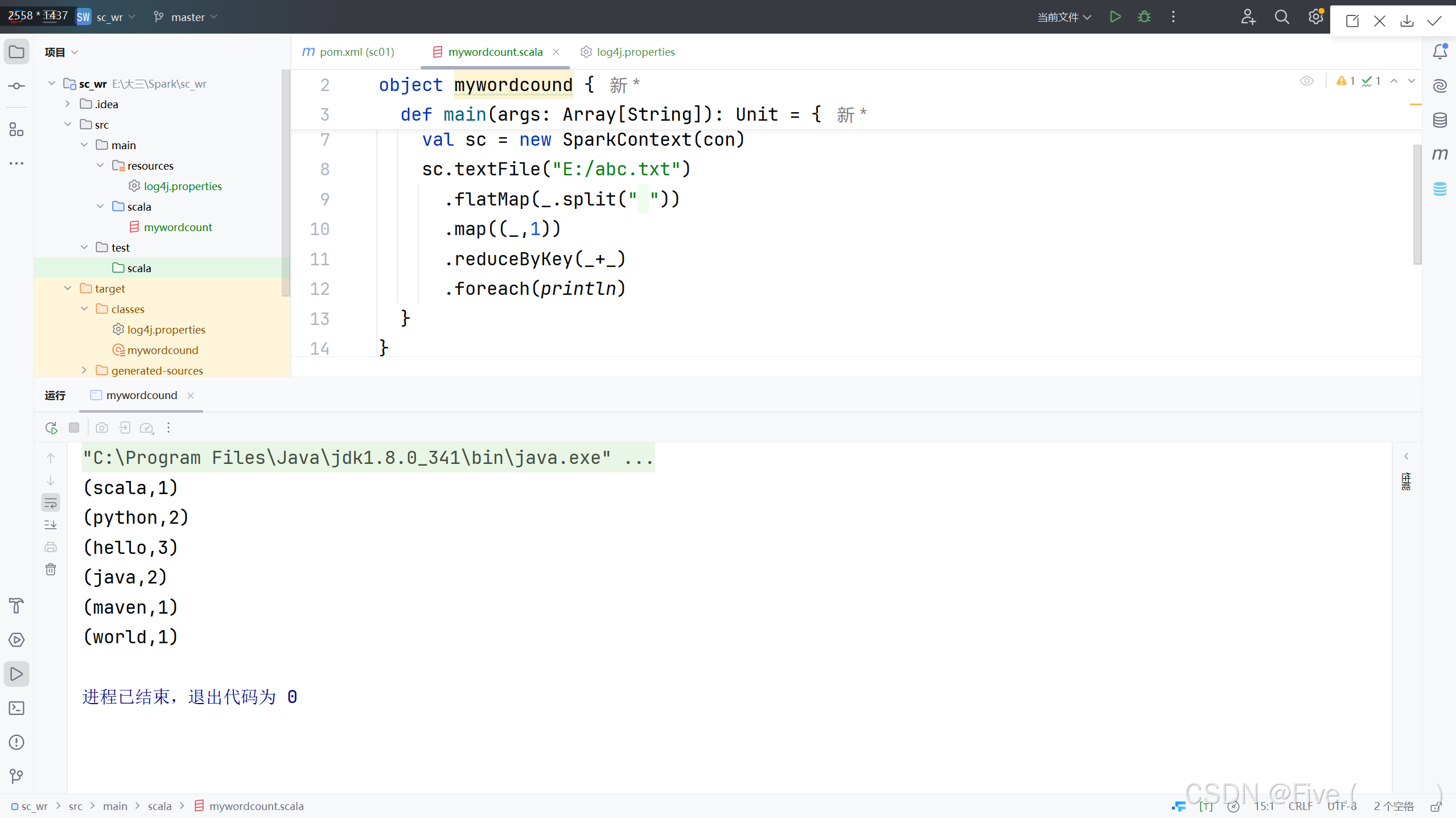
成功成功!