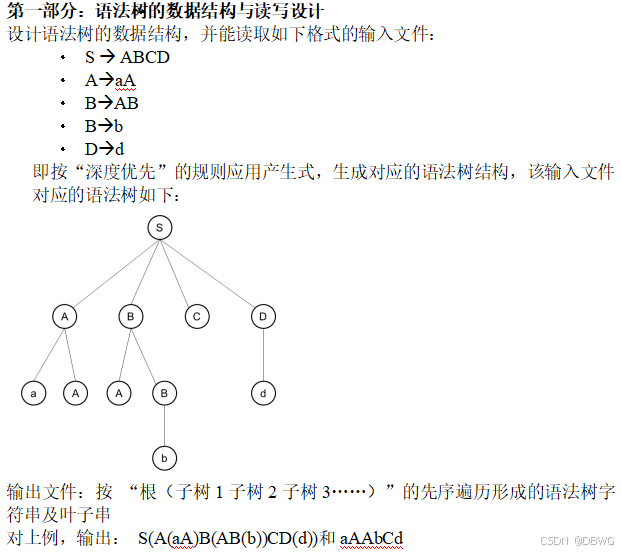
SZU 编译原理

总结自 深圳大学《编译原理》课程所学相关知识。
文章目录
- 文法
- 语法分析
- 自顶向下的语法分析
- 递归下降分析
- LL(1) 预测分析法
- FIRST 集合
- FOLLOW 集合
文法
乔姆斯基形式语言理论:
表达能力:0型文法 > 1型文法 > 2型文法 > 3型文法。
- 0 型文法(短语结构文法)
- 定义:
产生式规则为 α → β,其中 α 是至少包含一个非终结符的符号串,β 是任意符号串(终结符和非终结符的混合)。 - 特点:
限制最少,表达能力最强,能描述所有递归可枚举语言。
允许 “全局” 替换(不局限于单个非终结符),例如 AB → CD。 - 自动机:由图灵机识别。
- 应用:理论计算模型,几乎不用于实际编程。
- 定义:
- 1 型文法(上下文有关文法)
- 定义:
产生式规则为 αAβ → αγβ,其中 A 是非终结符,α, β, γ 是任意符号串,且 γ ≠ ε。
直观理解:只有当非终结符 A 出现在上下文 α 和 β 之间时,才能被替换为 γ。
等价形式:|α| ≤ |β|(产生式右部长度不小于左部,除了 S → ε,其中 S 是开始符号且不出现在其他产生式右部)。 - 特点:
表达能力仅次于 0 型文法,能描述上下文有关语言。
例如:a^n b^n c^n(n 个 a、n 个 b、n 个 c 的串)可用 1 型文法描述,但无法用 2 型文法描述。 - 自动机:由线性界限自动机识别。
- 应用:自然语言处理(理论模型),实际中较少使用。
- 定义:
- 2 型文法(上下文无关文法)
- 定义:
产生式规则为 A → β,其中 A 是非终结符,β 是任意符号串(终结符和非终结符的混合)。
直观理解:非终结符 A 可被替换为 β,无需考虑 A 出现的上下文。 - 特点:
表达能力强,能描述程序设计语言的语法(如表达式、语句结构)。
例如:算术表达式文法、括号匹配问题均属于 2 型文法。 - 自动机:由下推自动机(带栈的有限状态机)识别。
- 应用:编译器的语法分析阶段(如递归下降分析、LR 分析)。
- 定义:
- 3 型文法(正则文法)
- 定义:
产生式规则分为两类:
右线性文法:A → aB 或 A → a(右部符号串以终结符开头,后跟非终结符或空)。
左线性文法:A → Ba 或 A → a(右部符号串以非终结符开头,前跟终结符或空)。 - 特点:
表达能力最弱,只能描述线性结构(如标识符、关键字、数值常量)。
与正则表达式等价,可转换为有限状态自动机。 - 自动机:由有限状态自动机识别。
- 应用:编译器的词法分析阶段(用于识别单词符号)。
- 定义:
语法分析
Syntax Analysis
判断源代码是否符合语言的语法规则,符合可构建语法树/抽象语法树(AST),为后续的语义分析、优化和代码生成提供基础。
- 输入:
词法分析器输出的单词符号序列(Token流)
(如:int a = b + 1; 对应的 token 序列为:[int, id(a), '=', id(b), '+', num(1), ';']) - 输出:
源程序对应的语法树(parse tree)或抽象语法树(AST)
语法分析的两大类方法:
- 自顶向下分析(Top-Down Parsing):从文法的开始符号出发,尝试推导输入串。
- 常见算法:递归下降分析、LL(1)分析
- 自底向上分析(Bottom-Up Parsing):从输入符号出发,逐步归约还原为文法的开始符号。
- 常见算法:LR(0)、SLR(1)、LALR(1)、LR(1)
| 算法 | 全称/关键含义 | 分析方向 | 向前看符号数 | 分析能力/特点 | 适用场景 |
|---|---|---|---|---|---|
| 递归下降分析 | 每个非终结符对应一个递归函数,通过函数调用模拟推导过程 | 自顶向下 | 通常 1(LL(1)) | 实现简单直观,适合手工编写分析器,但需消除左递归和提取左公因子。 | 简单 LL(1) 文法 |
| LL(1) | Left-to-right, Leftmost derivation, 1 lookahead symbol | 自顶向下 | 1 | 预测分析,根据当前非终结符和下一个输入符号选择产生式,需构造 FIRST 和 FOLLOW 集。 | 无左递归、无左公因子的简单文法 |
| LR(0) | Left-to-right, Rightmost derivation in reverse, 0 lookahead | 自底向上 | 0 | 仅根据当前状态决定动作,能力弱,可能存在移进-归约冲突。 | 教学示例,极简单文法 |
| SLR(1) | Simplified LR(1), 使用 FOLLOW 集解决冲突 | 自底向上 | 1 | 在 LR(0) 基础上,通过向前看 1 个符号(FOLLOW 集)解决冲突,实现较简单。 | 中等复杂度文法 |
| LALR(1) | Look-Ahead LR(1), 合并同心项目集 | 自底向上 | 1 | 通过合并 LR(1) 的同心项目集减少状态数,能力接近 LR(1),是实际编译器常用的方法(如 Yacc、Bison)。 | 大多数程序设计语言的文法 |
| LR(1) | Left-to-right, Rightmost derivation in reverse, 1 lookahead | 自底向上 | 1 | 能力最强,每个状态包含精确的向前看符号,但状态数多,实现复杂。 | 复杂文法,理论研究 |
自顶向下的语法分析
递归下降分析
Recursive Descent Parsing
递归下降分析 是一种自顶向下的语法分析方法,为文法中每个非终结符编写一个递归函数来尝试匹配输入的语句。
例题:
第二部分:基于递归下降分析法的简单算术表达式语法分析
选用课本的简单算术表达式的文法,设计基于递归下降分析法的程序,对输入的简单算术表达式,分析并按第一部分的输出格式,输出其对应的语法树(若存在)。
例如,如果输入文件是形如 i+i*i 的字符串,那么输出文件内容是:E(T(F(i)T')E'(+T(F(i)T'(*F(i)T'))E'))
解:
假设用的是如下简化文法(符合 LL(1))
E → T E' // 维护加法
E' → + T E' | ε
T → F T' // 维护乘法
T' → * F T' | ε
F → ( E ) | i【用于算术表达式的上下文无关文法(CFG)】
原始的算术表达式文法(如 E → E + T | T)存在左递归,会导致递归下降分析器陷入无限循环。
这个文法通过引入 E' 和 T' 消除了左递归。
T 项 (T的产生式维护了右边的一个可为空的乘积)
E' 处理右递归,这里维护 ’ + ’
T' 处理右递归,维护 ’ * ’
每个产生式写一个函数:调用谁就打印谁
void E(); // 处理 E → T E'
void E_(); // 处理 E' → + T E' | ε
void T(); // 处理 T → F T'
void T_(); // 处理 T' → * F T' | ε
void F(); // 处理 F → ( E ) | i
匹配流程:
1. 开始于 E
2. E → T E':T → F T'F → i → F(i)T' 当前输入是 +,不匹配 *,进入 ε → T'E' → + T E'匹配 + → +T → F T'F → i → F(i)T' → * F T'匹配 *F → i → F(i)T' → εE' → ε
LL(1) 预测分析法
L: 从左到右扫描输入串(Left-to-right)
L: 产生最左推导(Leftmost derivation)
1: 使用 1 个符号向前看(lookahead)
核心思想:使用一个 预测分析表(Parsing Table) 来决定根据当前的栈顶非终结符和当前输入符号应该使用哪个产生式。
第三部分: 基于LL(1)预测分析法的简单算术表达式语法分析
与第二部分相同,但采用LL(1)预测分析法进行分析程序的设计。注意:需要把LL(1)分析表设计为一个可配置(可初始化)的参数
仍是这个文法:
E → T E'
E' → + T E' | ε
T → F T'
T' → * F T' | ε
F → ( E ) | i
我们先构造 FIRST 和 FOLLOW 集合,再得出分析表。
FIRST 集合
FIRST(X) 是:从 X 推导出的所有串中能出现在最前面的终结符集合(或 ε)
FIRST(E) = FIRST(T) = FIRST(F) = { i, ( }
FIRST(E') = { +, ε }
FIRST(T') = { *, ε }
FIRST(F) = { i, ( }
FOLLOW 集合
FOLLOW(A) 是:在某些推导中,非终结符 A 后面可能出现的终结符集合
(如果 S 是开始符号,#(输入结束标志)属于 FOLLOW(S))
若某个产生式是 B → α A β:将 FIRST(β)(去除 ε)加入 FOLLOW(A) // A 后的第一个给 A若 β 可推出 ε,则将 FOLLOW(B) 也加入 FOLLOW(A) // A 后的β是空的,那A后和B后是一样的
FOLLOW(E) = { ), # }
FOLLOW(E') = { ), # }
FOLLOW(T) = { +, ), # }
FOLLOW(T') = { +, ), # }
FOLLOW(F) = { *, +, ), # }
构造方式:
假设某个产生式 A → α:对于所有 a ∈ FIRST(α)(a ≠ ε),在表中 M[A][a] = α如果 ε ∈ FIRST(α),那么对于 b ∈ FOLLOW(A),令 M[A][b] = ε
构建的LL(1) 预测分析表:(行:非终结符,列:终结符)
| 非终结符 | i | + | * | ( | ) | #(终止符) |
|---|---|---|---|---|---|---|
| E | T E’ | T E’ | ||||
| E’ | + T E’ | ε | ε | |||
| T | F T’ | F T’ | ||||
| T’ | ε | * F T’ | ε | ε | ||
| F | F(i) | ( E ) |
初始化分析表:
map<string, map<string, string>> parsingTable;parsingTable["E"]["i"] = "T E'";
parsingTable["E"]["("] = "T E'";
parsingTable["E'"]["+"] = "+ T E'";
parsingTable["E'"][")"] = "ε";
parsingTable["E'"]["#"] = "ε";
...