反向传播
如果你要用梯度下降算法来训练一个神经网络,应该怎么做?
假设网络有一堆的参数:。首先选择一个初始的参数
,计算
对损失函数的梯度,也就是计算神经网络里面的参数
对loss损失函数的导数,计算出后,更新参数
;再计算
对损失函数的梯度,再更新
,以此类推.......
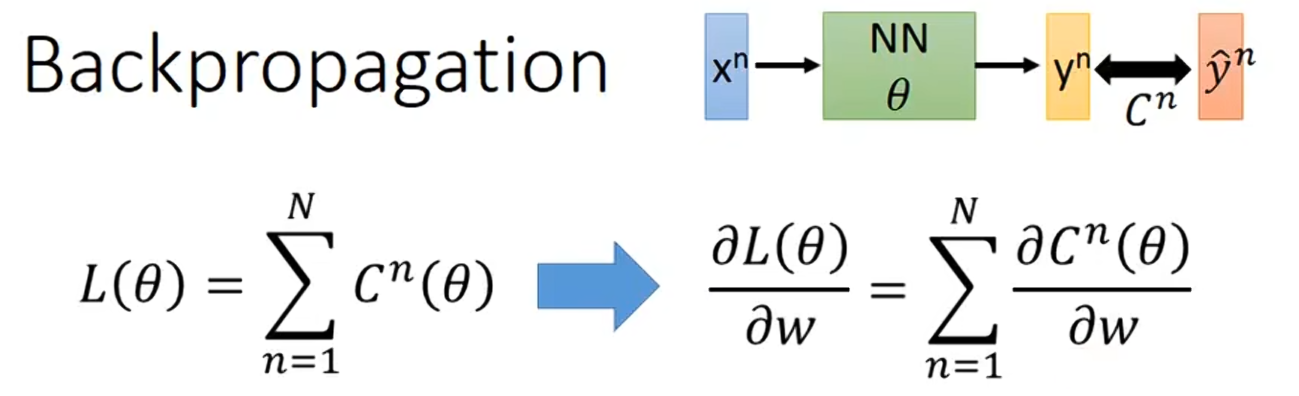
我们会定义一个loss损失函数,这个损失函数就是所有训练样本的预测值与真实值之间差值和,对损失函数进行梯度下降算法的公式如下:
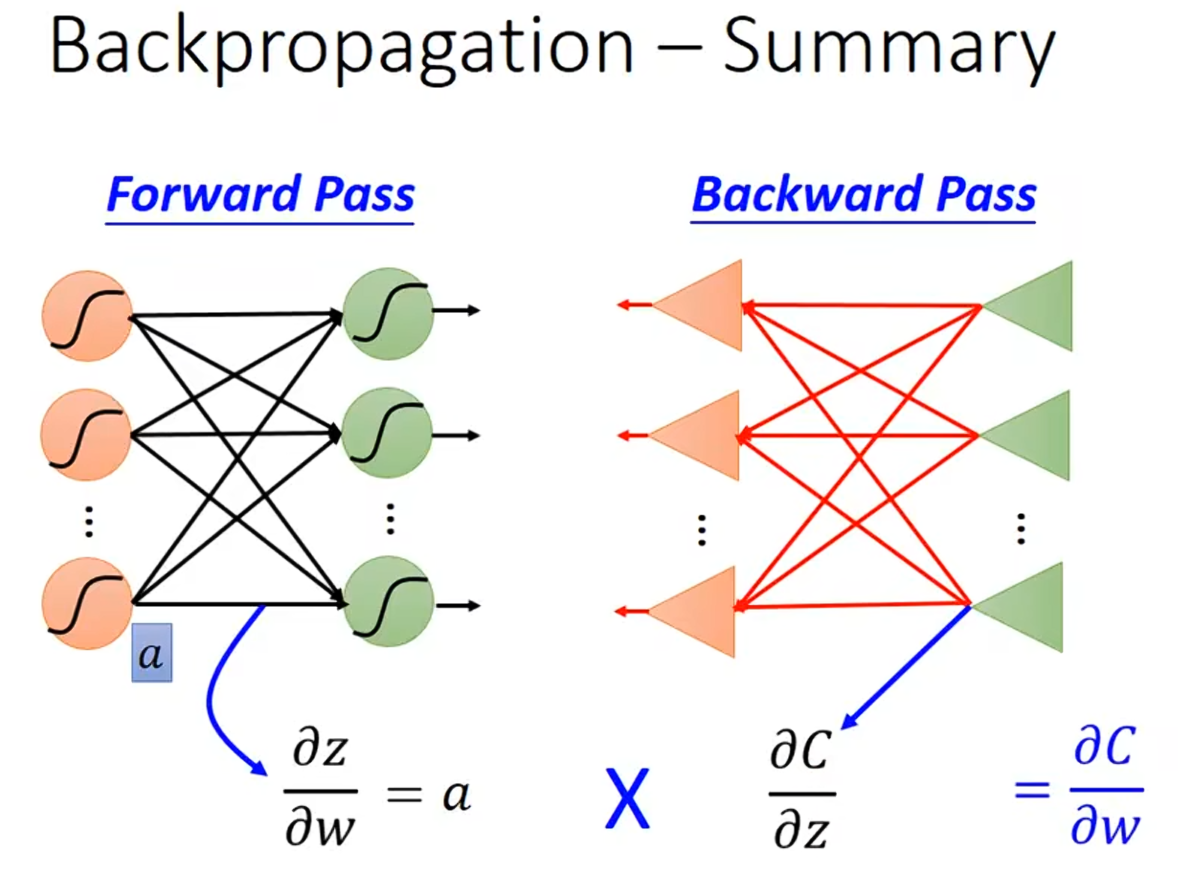
现在我们来看一下怎么对某一笔的样本计算梯度。
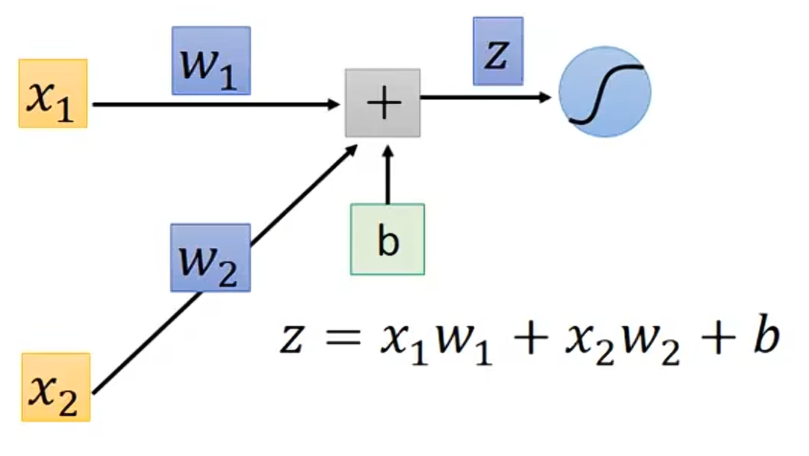
对于上述的神经元,先考虑计算某一个神经元的梯度:
通过前向过程计算可得,对于
。计算
是前向过程,计算
是反向过程。
我们先来看下怎么计算 。因为
,
,
。对于
就是看这个w前面接的是什么,那微分以后就是什么。
前面接的输入是
,所以求导后就是
;
前面接的输入是
,所以求导后就是
,就是这样的规律。
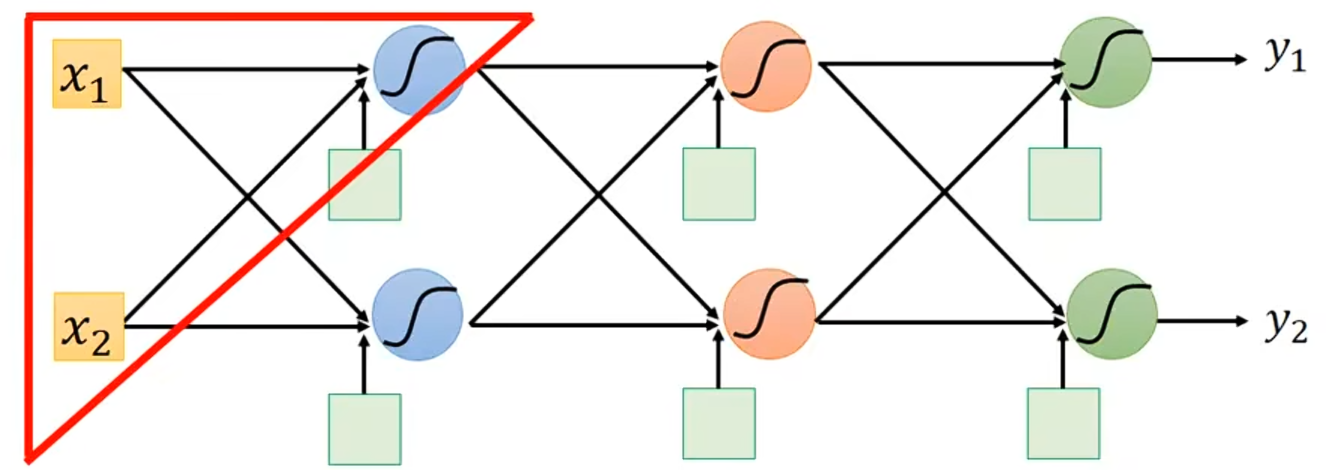
假如给你如下图的神经网络,它里面有一大堆的参数,计算里面的,这件事非常容易。
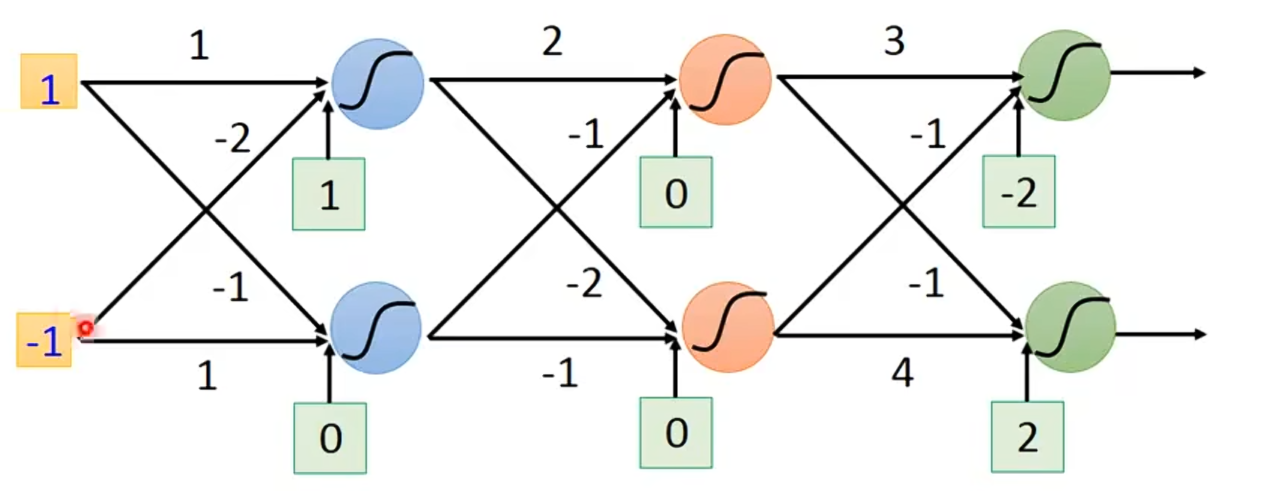
如果有人想问你: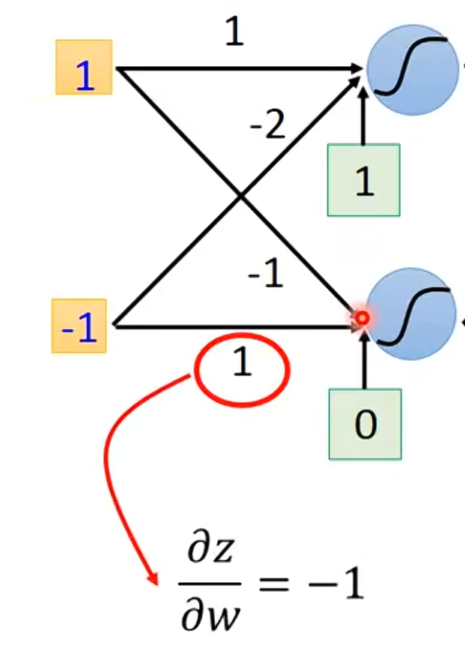 这个
这个是多少,你看这个w=1前面接的输入是-1,你可以瞬间告诉他
接下来,有人想问你: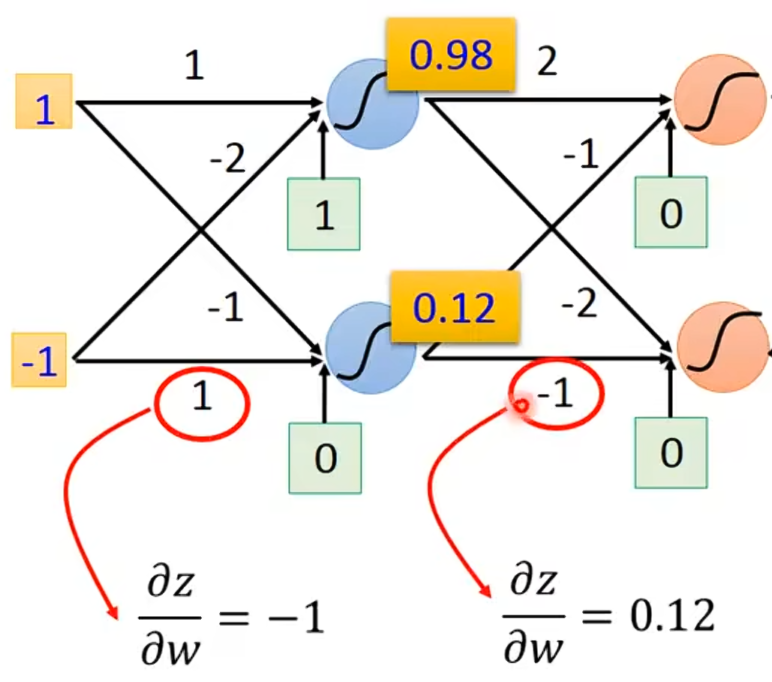 ,对于这个w=-1,
,对于这个w=-1,是多少,你可以很快告诉他
知道了怎么计算,我们现在来看看怎么计算
。计算
你会觉得很困难,因为z通过激活函数后得到一个输出。
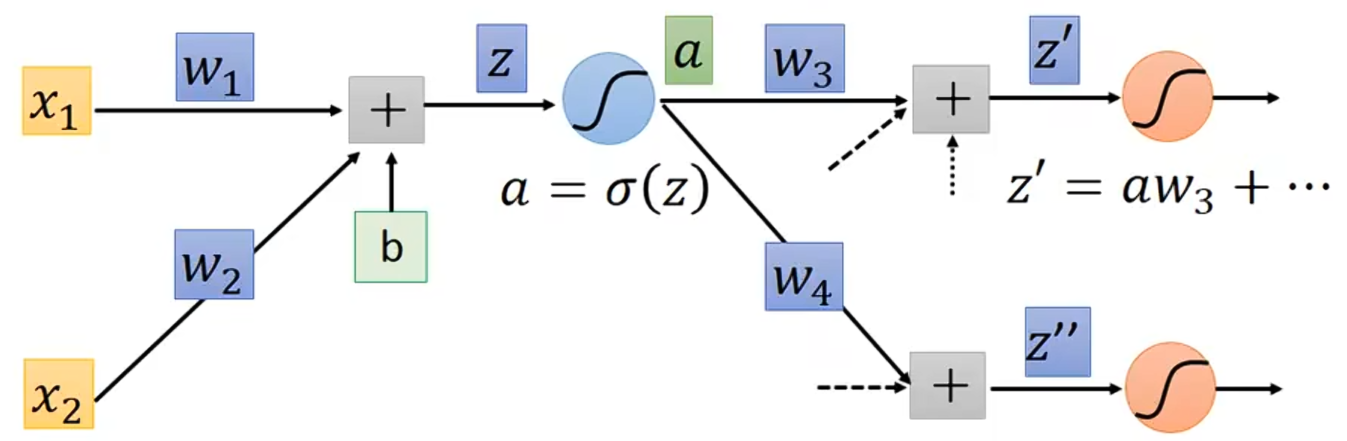
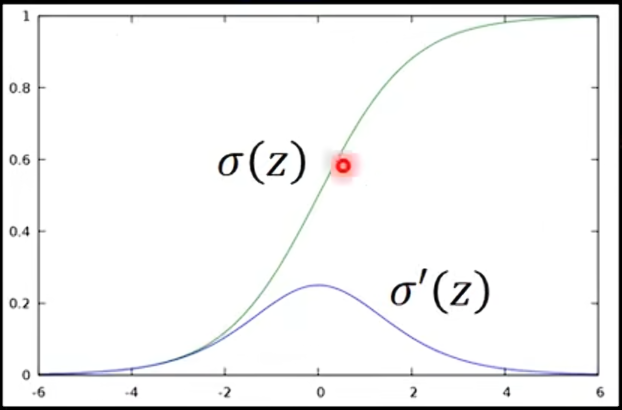
假设激活函数时sigmoid函数,z通过sigmoid函数后得到a。我们知道,
,
就是sigmoid函数的偏微分。sigmoid函数如下图绿色线所示,它的微分如蓝色线所示:
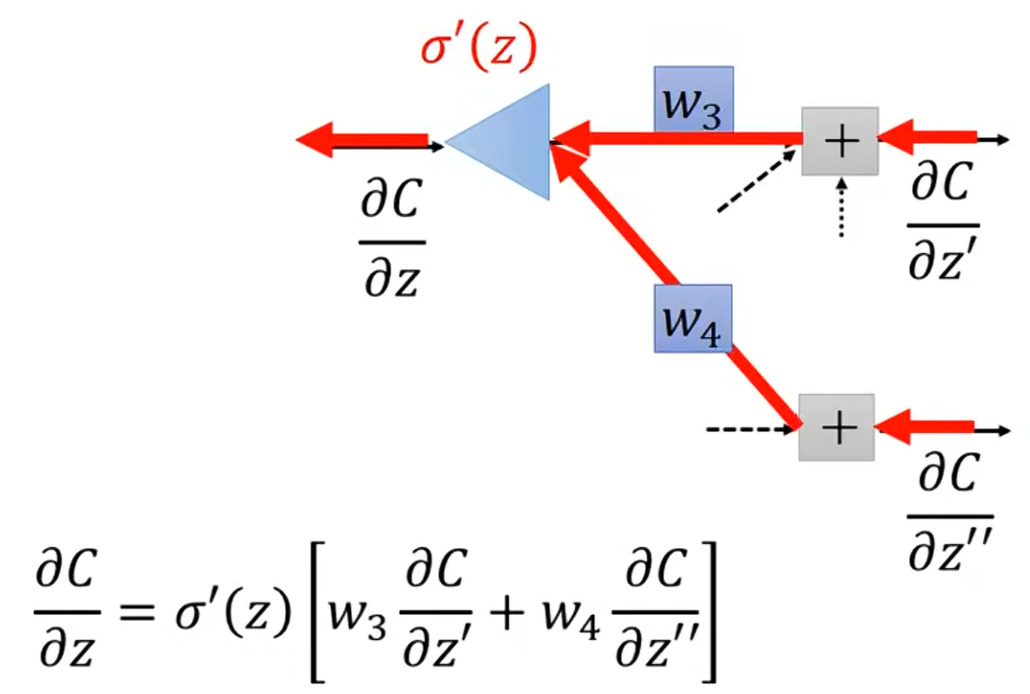
因为a会影响后面的,
会影响C;a会影响后面
,
会影响C。所以
。因为
,所以我们能很快知道
,
,但是我们又很难计算
和
,因为神经网络后面可能会又其他的运算,在此,我们先假设知道
和
这两项的值。 现在我们就可以计算
的值。
我们可以从另一个观点看待这个式子,如下图,其中是一个常数,因为z在计算前向过程的时候就被决定好了。
回到上一个问题,我们要怎么算和
呐?
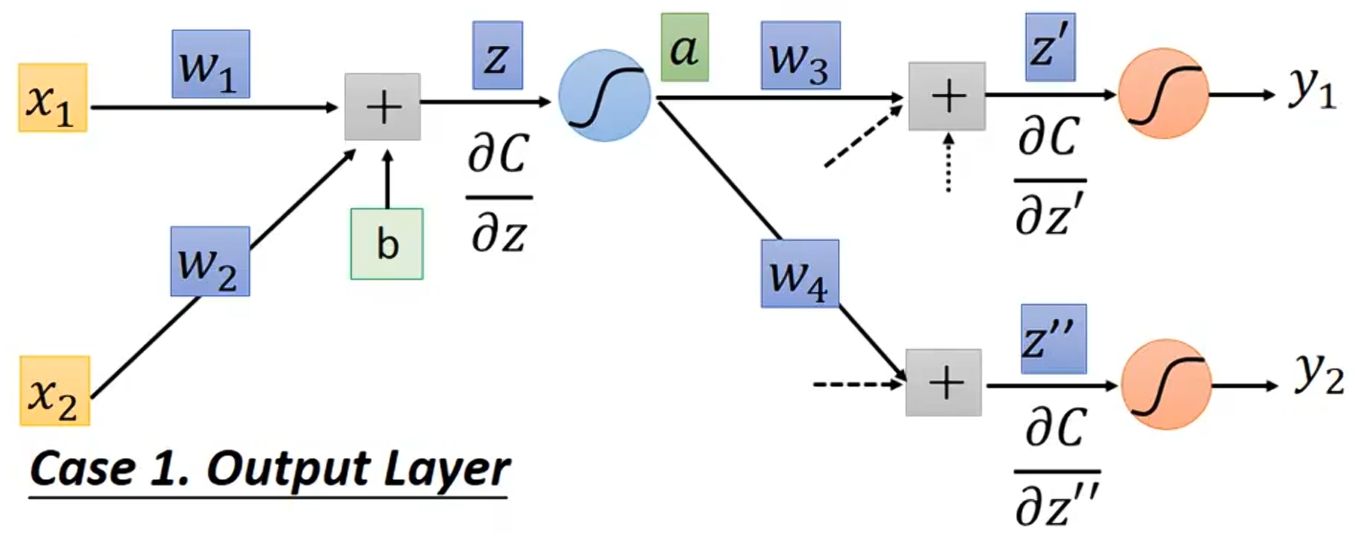
第一个例子是我们假设橘色的这两个神经元是输出层,所以可以计算出 ,
假设橘色的神经元并不是整个神经网络的输出,它后面还有其他的层,那应该怎么算呢?
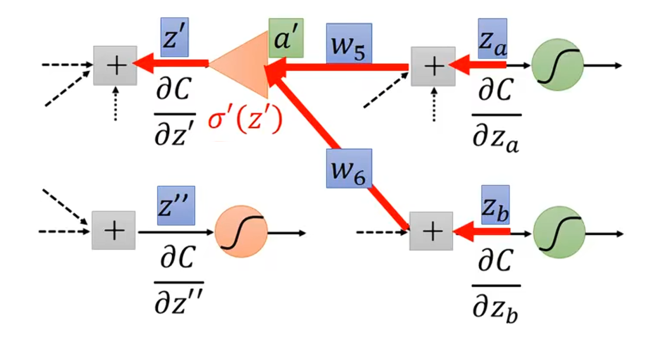
如果我们知道和
,我们就能计算出
,但我们现在无法计算出
和
,因为我们不知道后续的层是什么样的。我们可以再往下一层去看,如果绿色的神经元是输出层的话,计算
和
就不成问题。
实际上,我们是从输出层的开始计算的:
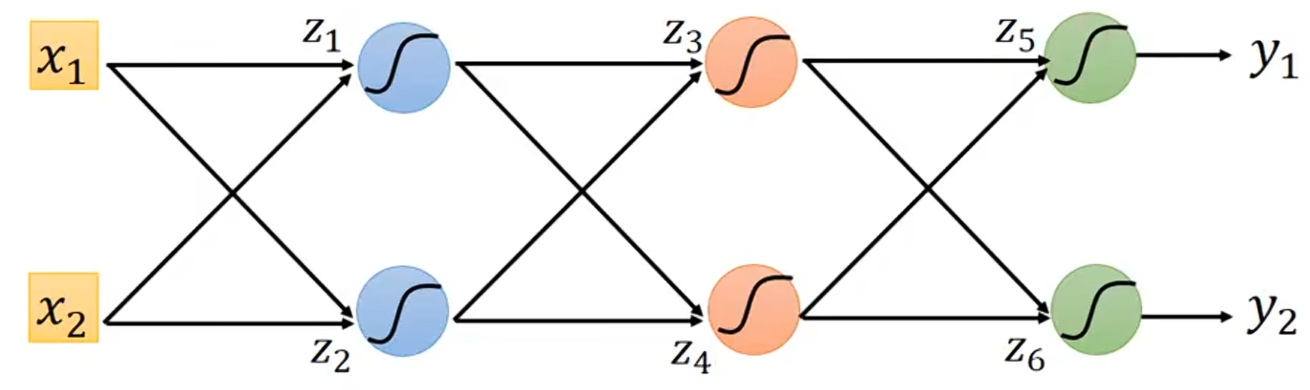
假设我们现在有6个神经元,现在我们要计算,如果先计算
和
,那就没有效率;如果先算
和
,就很有效率。
算出和
后,就可以算出
和
,然后算出
和
。
实际上,这个过程如下图所示: