π0: A Vision-Language-Action Flow Model for General Robot Control
TL;DR
- 2024 年 Physical Intelligence 发布的 VLA 模型 π0,基于 transformer + 流匹配(flow matching)架构,当前开源领域最强的 VLA 模型之一。
Paper name
π0: A Vision-Language-Action Flow Model for General Robot Control
Paper Reading Note
Paper URL:
- https://www.physicalintelligence.company/download/pi0.pdf
Project URL:
- https://www.physicalintelligence.company/blog/pi0
Introduction
背景
“一个人应该能换尿布、策划入侵、屠宰猪只、驾驶船只、设计建筑、写十四行诗、核对账目、砌墙、接骨、安慰垂死之人、服从命令、发号施令、协作、独立行动、解方程、分析新问题、铲粪、编程、做出美味饭菜、高效作战、英勇赴死。专业化,是昆虫的事。”
——罗伯特·海因莱因,《爱的时光足够长》
- 在多样性这一维度上,人类智能远远超越了机器智能:也就是在不同物理环境中解决多样任务的能力,能根据环境限制、语言指令以及突发扰动作出智能反应
- 然而,构建这样的通用机器人策略(即“机器人基础模型”)仍面临多项重大挑战:
- 规模要求高:要实现预训练带来的全部优势,研究必须在大规模下进行
- 模型架构合适:需开发能有效利用多源数据、同时能表达复杂交互行为的架构
- 训练策略关键:如在自然语言与视觉模型中,许多进展都依赖于预训练和后训练阶段的数据精细策划
本文方案
- 提出一个原型模型及其学习框架,称为 π₀(Pi-zero),展示如何应对上述三大瓶颈
- 规模
- 首先使用预训练视觉语言模型(VLM)训练视觉-语言-动作(VLA)模型,引入互联网上规模级的经验
- 跨具身训练(cross-embodiment training),将来自单臂、双臂、移动操作器等多种机器人平台的数据整合在一个模型中
- 模型架构
- 基于流匹配(flow matching,一种扩散模型变体)的动作分块(action chunking)架构,可支持高达 50 Hz 的控制频率
- 训练策略
- 预训练/后训练两阶段结构。先在多样大数据上预训练,再用高质量数据微调,从而达到所需的精细控制能力。
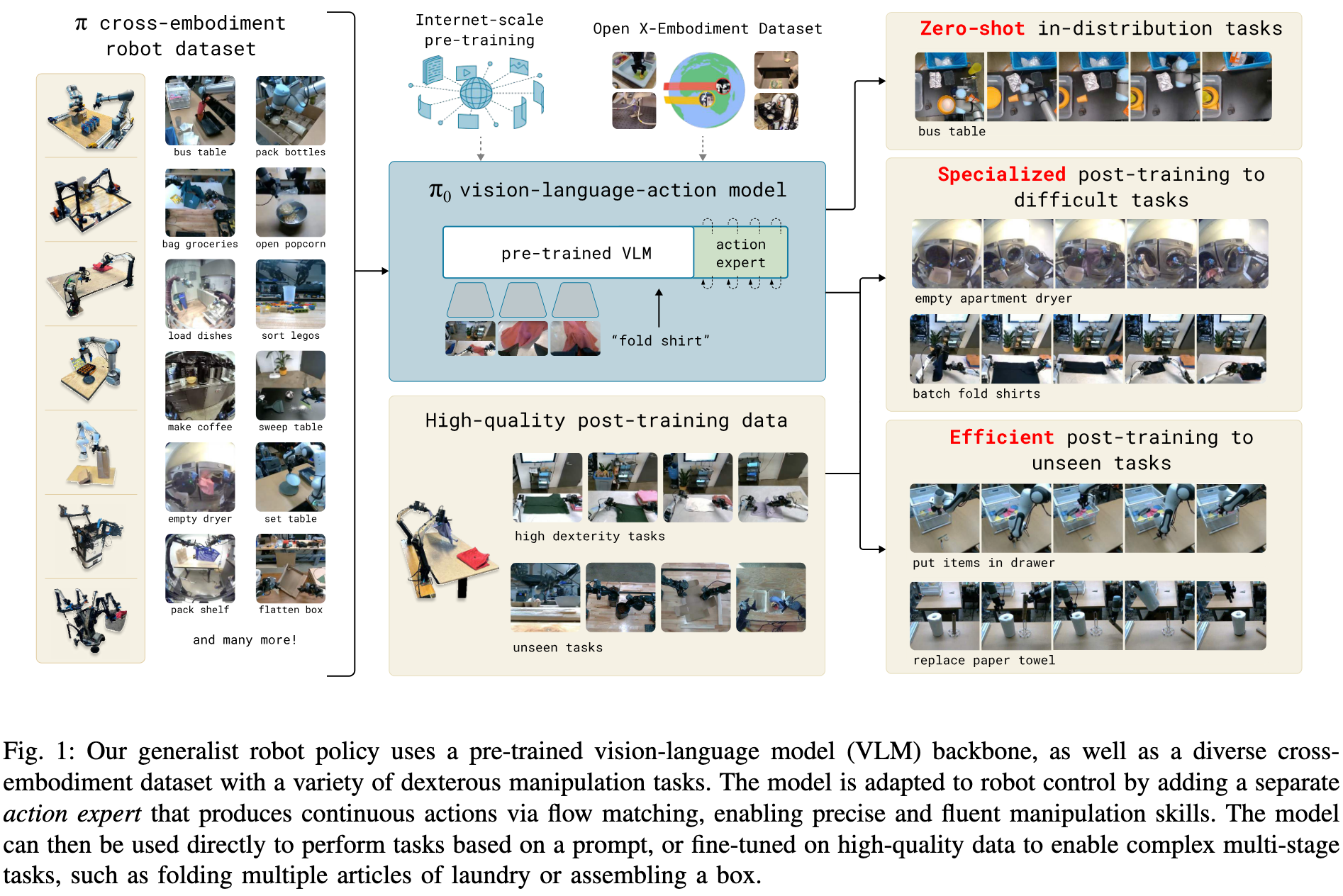
- 预训练/后训练两阶段结构。先在多样大数据上预训练,再用高质量数据微调,从而达到所需的精细控制能力。
- 规模
通过超过一万小时的机器人数据进行预训练,并在多个精细任务中进行微调,包括叠衣服(图2)、清理餐桌、放置餐具、装蛋、组装纸盒和打包购物物品。

Methods
网络架构
- π0 模型如图 3 所示,主要由语言模型的 Transformer 主干构成。
- 根据标准的后融合视觉语言模型(VLM)方案,图像编码器将机器人的图像观测嵌入到与语言标记相同的嵌入空间中。
- 进一步在此主干基础上增加了特定于机器人任务的输入与输出——即本体感知状态和机器人动作。π0 使用条件流匹配(Conditional Flow Matching)来建模动作的连续分布。流匹配使模型具有高精度和多模态建模能力,特别适合高频率的精细操作任务。
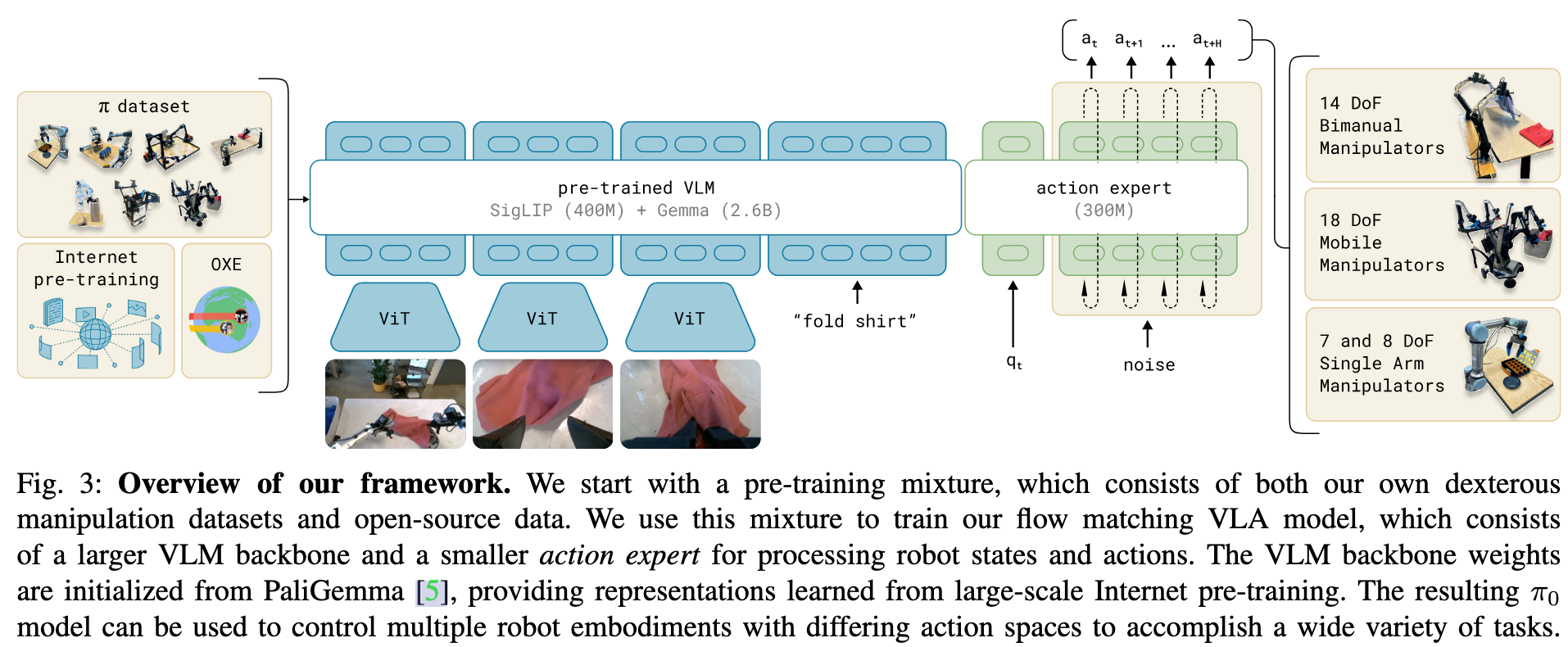
架构灵感来源于 Transfusion,该方法通过多个目标训练一个单一的 Transformer,利用流匹配损失监督连续输出的标记,使用交叉熵损失监督离散输出的标记。在此基础上,我们发现对机器人特定的动作与状态标记使用独立的一套权重会提升性能。这种设计类似于专家混合模型(Mixture of Experts)的两专家结构:第一专家处理图像和文本输入,第二专家处理与机器人相关的输入与输出。我们将第二组权重称为“动作专家”。
训练目标
形式上,我们要建模的数据分布为 p ( A t ∣ o t ) p(A_t | o_t) p(At∣ot),其中 A t = [ a t , a t + 1 , . . . , a t + H − 1 ] A_t = [a_t, a_{t+1}, ..., a_{t+H-1}] At=[at,at+1,...,at+H−1] 是未来动作的一个动作块(在我们的任务中,H = 50),而 o t o_t ot 是观测。观测包括多张RGB图像、一个语言指令和机器人的本体感知状态,即
o t = [ I t 1 , . . . , I t n , ℓ t , q t ] o_t = [I^1_t, ..., I^n_t, \ell_t, q_t] ot=[It1,...,Itn,ℓt,qt]
其中 I t i I^i_t Iti 是第 i i i 张图像(每个机器人有 2 或 3 张图像), ℓ t \ell_t ℓt 是语言标记序列, q t q_t qt 是关节角度向量。图像 I t i I^i_t Iti 和状态 q t q_t qt 经过对应的编码器,并通过线性投影映射到与语言标记相同的嵌入空间中。
对于动作块 A t A_t At 中的每个动作 a t ′ a'_t at′,我们都有一个对应的动作标记,通过“动作专家”进行处理。训练期间,这些动作标记通过条件流匹配损失进行监督:
L τ ( θ ) = E p ( A t ∣ o t ) , q ( A t τ ∣ A t ) ∥ v θ ( A t τ , o t ) − u ( A t τ ∣ A t ) ∥ 2 L_\tau (\theta) = \mathbb{E}_{p(A_t | o_t), q(A^\tau_t | A_t)} \left\| v_\theta (A^\tau_t, o_t) - u(A^\tau_t | A_t) \right\|^2 Lτ(θ)=Ep(At∣ot),q(Atτ∣At)∥vθ(Atτ,ot)−u(Atτ∣At)∥2
其中下标表示机器人时间步,上标表示流匹配时间步, τ ∈ [ 0 , 1 ] \tau \in [0, 1] τ∈[0,1]。
近期在高分辨率图像和视频合成中的研究表明,当与简单的线性高斯路径(或最优传输路径)联合使用时,流匹配可获得优异的经验性能。此概率路径形式为:
q ( A t τ ∣ A t ) = N ( τ A t , ( 1 − τ ) I ) q(A^\tau_t | A_t) = \mathcal{N}(\tau A_t, (1 - \tau)I) q(Atτ∣At)=N(τAt,(1−τ)I)
实际中,网络通过以下方式训练:采样随机噪声 ε ∼ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, I) ε∼N(0,I),计算“加噪动作”
A t τ = τ A t + ( 1 − τ ) ε A^\tau_t = \tau A_t + (1 - \tau) \varepsilon Atτ=τAt+(1−τ)ε
并训练网络输出 v θ ( A t τ , o t ) v_\theta (A^\tau_t, o_t) vθ(Atτ,ot) 来匹配去噪向量场
u ( A t τ ∣ A t ) = ε − A t u(A^\tau_t | A_t) = \varepsilon - A_t u(Atτ∣At)=ε−At
“动作专家”采用全双向注意力掩码,确保所有动作标记之间可以相互注意。在训练中,我们从一个偏向低值(即更嘈杂时间步)的 Beta 分布中采样 τ \tau τ。
推理
在推理阶段,我们通过将学习到的向量场从 τ = 0 \tau=0 τ=0 积分到 τ = 1 \tau=1 τ=1 来生成动作,起始为随机噪声 A t 0 ∼ N ( 0 , I ) A^0_t \sim \mathcal{N}(0, I) At0∼N(0,I)。我们使用前向欧拉积分规则:
A t τ + δ = A t τ + δ v θ ( A t τ , o t ) A^{\tau + \delta}_t = A^\tau_t + \delta v_\theta(A^\tau_t, o_t) Atτ+δ=Atτ+δvθ(Atτ,ot)
其中 δ \delta δ 是积分步长,我们实验中使用10个积分步(即 δ = 0.1 \delta = 0.1 δ=0.1)。值得注意的是,推理过程可高效实现——可缓存前缀 o t o_t ot 的注意力键和值,仅需在每个积分步重新计算与动作标记相关的后缀部分。
模型细节
虽然理论上该模型可从头训练或从任意 VLM 主干微调,实践中我们使用 PaliGemma 作为基础模型。PaliGemma 是一个开源的 30 亿参数的 VLM,在规模与性能之间实现了良好平衡。我们为“动作专家”额外添加了 3 亿参数(从头初始化),使总参数量达到 33 亿。
非VLM对照模型。 除了主模型外,我们还训练了一个未使用 VLM 初始化的类似对照模型,用于消融实验。我们称之为 π0-small,其参数量为 4.7 亿,未采用VLM初始化,并针对非 VLM 初始化情境在结构上做了一些小改动,帮助更好地在我们的数据上进行训练。该模型用于评估使用 VLM 初始化带来的收益。
数据收集与训练方案
-
预训练的目标是让模型接触到多样化的任务,从而习得通用的物理能力;而后训练的目标则是让模型能够熟练地完成具体的下游任务。预训练与后训练阶段所需的数据具有不同特点:
- 预训练数据集应覆盖尽可能多的任务,并且在每个任务内包含多种行为方式;
- 后训练数据集则应着重于高质量、流畅、连贯的策略表现,能够有效支持目标任务的执行。
-
图4中展示了预训练数据混合概况。
- 开源数据占预训练数据的 9.1%,包括 OXE、Bridge v2 和 DROID
- 我们自建的数据集占据 9.03 亿时间步
- 其中 1.06 亿步来自单臂机器人,
- 7.97 亿步来自双臂机器人。
- 总共包含 68 个任务,任务设计复杂。例如,“bussing”(收拾桌面)任务涉及将多种餐具、杯子和餐盘放入清理桶,同时将不同种类的垃圾丢入垃圾桶。

- 训练配置
- 动作向量 a t a_t at 和机器人配置向量 q t q_t qt 的维度固定为数据集中最大机器人维度(18 维),以容纳两个 6 自由度机械臂、两个夹爪、一个移动底座和一个升降躯干。
- 对低维度的机器人,我们进行零填充;
- 若图像数量少于3张,也对缺失图像位进行遮罩。
后训练(任务特化)
后训练阶段使用规模较小、与具体任务相关的数据集对模型进行微调,以便其专精于下游应用。不同任务对数据需求不同,从最简单任务仅需约 5小时数据,到复杂任务可能需要 100小时或以上。
语言与高层策略
对于如“清理桌面”这类需要语义推理和策略规划的复杂任务,我们引入高层策略(high-level policy)对任务进行分解(如将“清理桌面”分解为“捡起餐巾纸”“扔进垃圾桶”等子任务)。由于模型本身支持语言输入,我们可以使用高层VLM模型进行语义推理,其方法类似于 SayCan 等LLM/VLM规划系统。
机器人系统
- 精细操作数据集包含 7 种机器人配置,涵盖 68 个任务

| 机器人类型 | 配置描述 |
|---|---|
| UR5e | 单臂,7自由度,带夹爪。配有一个腕部摄像头和一个肩部摄像头(共2张图像)。配置与动作空间维度为7。 |
| Bimanual UR5e | 两个UR5e机械臂,三张图像,配置与动作空间为14维。 |
| Franka | 单臂,8维配置与动作空间,配有2张图像。 |
| Bimanual Trossen | 2个6自由度的Trossen ViperX机械臂,ALOHA架构,配有两个腕部摄像头和一个底部摄像头,14维配置与动作空间。 |
| Bimanual ARX & AgileX | 2个6自由度机械臂(ARX或AgileX),三张图像,14维空间。因运动学相似归为同一类。 |
| Mobile Trossen & ARX | Mobile ALOHA平台,2个6自由度机械臂(ARX或Trossen ViperX),配移动底座(增加2维动作),总共14维配置 + 16维动作。3张图像。 |
| Mobile Fibocom | 2个6自由度ARX机械臂,带全向移动底座,底座增加3个自由度(2平移 + 1旋转),总共14维配置 + 17维动作。 |
数据集比例中看起来是 Bimanual ARX 占了大头
Experiments
基础模型测试(开箱即用)
- 与以下模型对比:
- OpenVLA:7B参数,训练于OXE。
- Octo:93M参数,基于扩散模型生成动作。
- π0-small:未进行VLM初始化的小模型。
- π0 parity:使用与baseline相同训练步数的π0版本(160k步)。
- OpenVLA-UR5e:仅在UR5e任务上精调过的版本。

- 图7显示,即使是 parity 版本的 π0 也显著优于所有 baseline,完整训练的 π0 则有压倒性优势。OpenVLA 因不支持动作块(action chunk)而效果不佳;Octo 表现稍好但表示能力有限

跟随语言指令
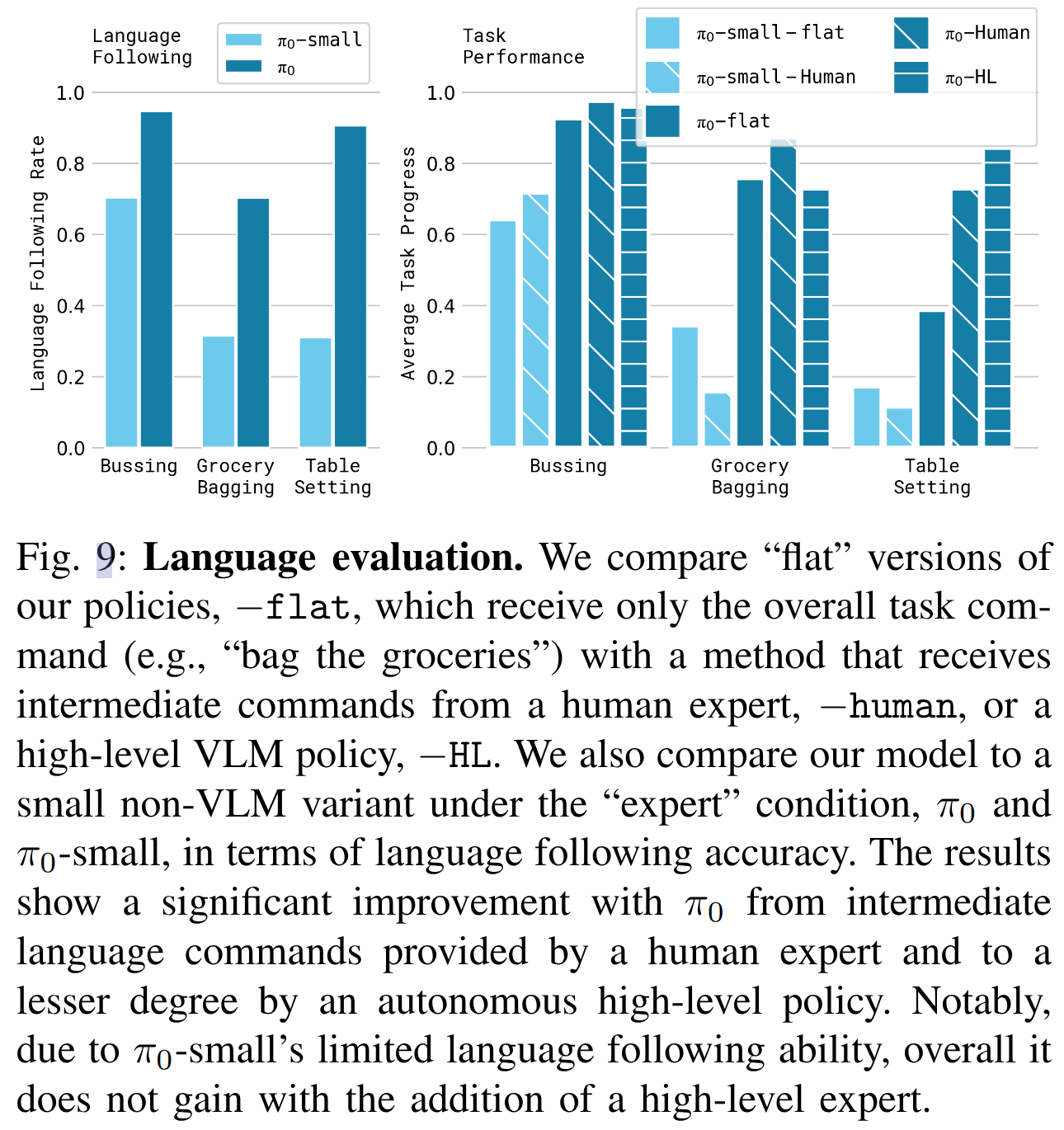
评估 π0 与 π0-small 在语言指令下的跟随能力,任务包括:
- 清理桌面
- 摆放餐具
- 杂货打包

我们设置三种提示条件:
- flat:只给出整体任务指令
- human:中间步骤由人工专家提供(如“拿起餐巾纸并扔进垃圾桶”)
- HL:由高层 VLM 策略生成中间语言指令
结果如图9所示:π0 明显优于 π0-small,特别是在 human 和 HL 条件下。说明 VLM 预训练显著增强了语言理解与自主任务执行能力。
学习全新精细操作任务
| 任务名称 | 描述 | 难度 |
|---|---|---|
| 叠碗(UR5e) | 叠放不同尺寸碗 | 易 |
| 叠毛巾 | 与叠T恤相似 | 易 |
| 放保鲜盒进微波炉 | 包含新对象“微波炉” | 中 |
| 更换纸巾卷 | 无预训练相似经验 | 难 |
| 抽屉收纳(Franka) | 打开/关闭抽屉并整理物品 | 难 |
比较以下方法:
- π0(预训练+精调)
- π0 从头训练
- OpenVLA
- Octo
- ACT 与 Diffusion Policy(专为小数据精细操作任务设计)
结果如图11:π0 在所有任务上整体表现最佳,尤其在预训练任务相似的场景中效果显著。对于如“保鲜盒微波炉”这类任务,π0在仅1小时训练下即可大幅优于其他方法。
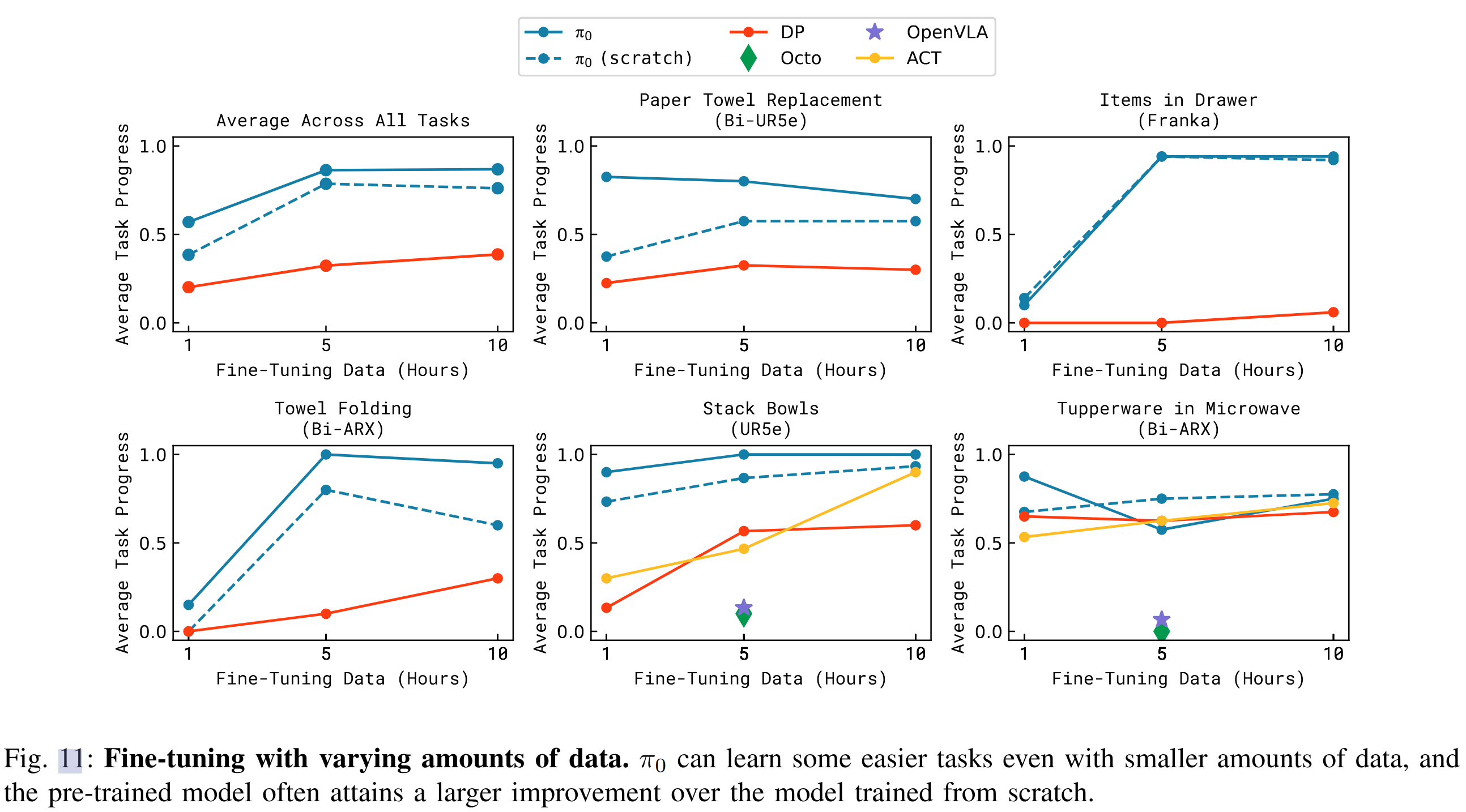
- 微调还是能带来很大提升
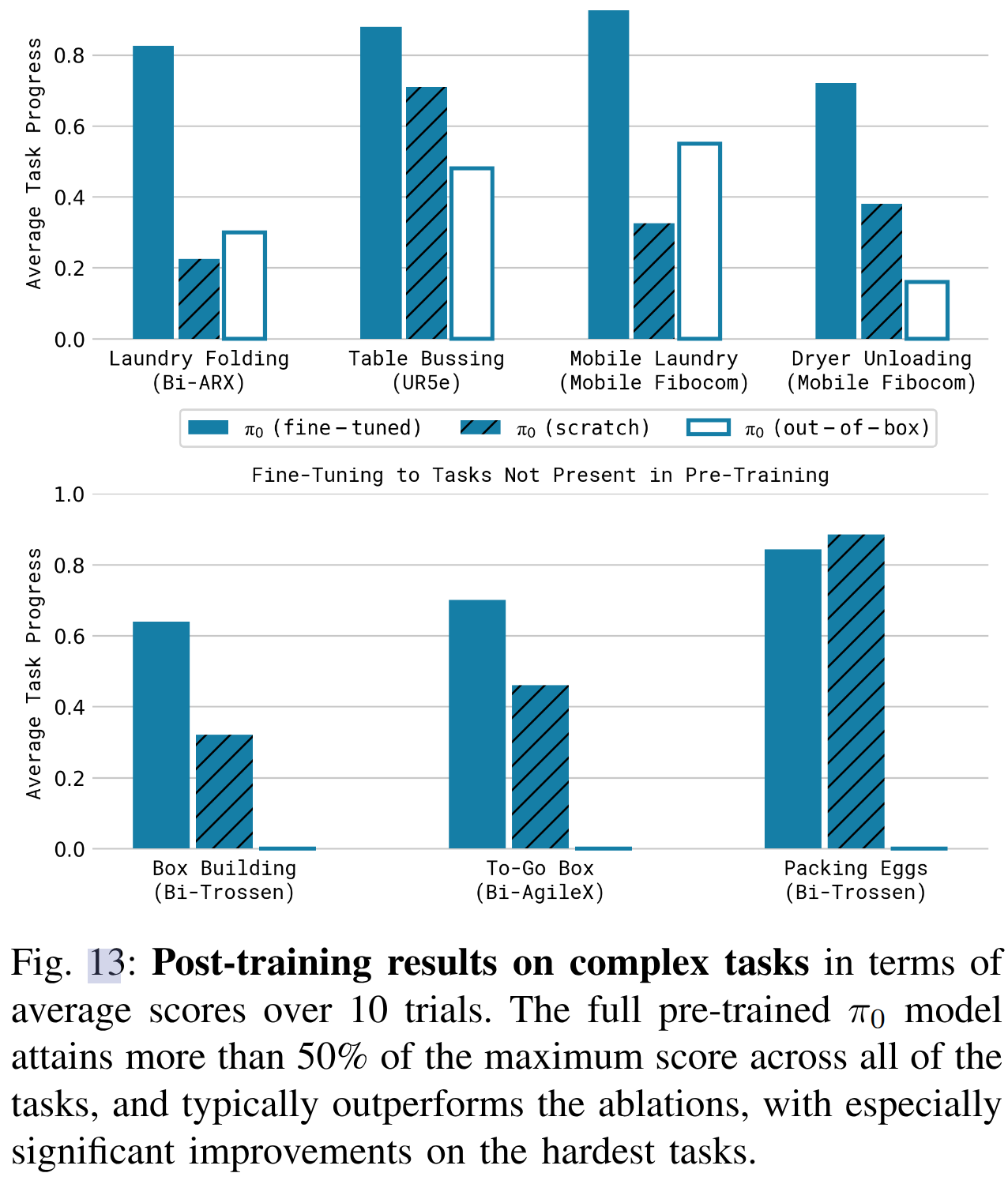
Conclusion
- 提出了 π0 的训练框架,通过海量预训练和精调,可执行多阶段、需要策略与精细操作的任务。其关键特点包括:
- 结合 Internet 规模的 VLM 预训练与流匹配方法表达高频动作块;
- 使用超过 1 万小时数据、涵盖 7 种机器人配置与 68 个任务;
- 精调覆盖 20 多个任务,超越多种现有方法;
- 类似 LLM 的训练流程,预训练提供知识,精调对齐模型策略。