【AI论文】对抗性后期训练快速文本到音频生成
摘要:文本到音频系统虽然性能不断提高,但在推理时速度很慢,因此对于许多创意应用来说,它们的延迟是不切实际的。 我们提出了对抗相对对比(ARC)后训练,这是第一个不基于蒸馏的扩散/流模型的对抗加速算法。 虽然过去的对抗性后训练方法难以与昂贵的蒸馏方法进行比较,但ARC后训练是一个简单的程序,它(1)将最近的相对论对抗性公式扩展到扩散/流后训练,(2)将其与一种新的对比鉴别器目标相结合,以鼓励更好的提示依从性。 我们将ARC后训练与Stable Audio Open的一些优化相结合,构建了一个能够在H100上大约75毫秒内生成大约12秒的44.1kHz立体声音频,在移动边缘设备上大约7秒的模型,据我们所知,这是最快的文本到音频模型。Huggingface链接:Paper page,论文链接:2505.08175
研究背景和目的
研究背景
近年来,文本到音频(Text-to-Audio, T2A)生成系统取得了显著进展,能够在各种应用场景中生成高质量的音频内容。然而,这些系统在推理(inference)阶段普遍存在速度较慢的问题,生成一段音频往往需要数秒甚至数分钟的时间。这种高延迟极大地限制了T2A系统在创意应用领域的实用性,如实时音乐创作、游戏音效生成、虚拟助手交互等。在这些场景中,用户期望系统能够即时响应并生成符合要求的音频内容,而现有的T2A系统显然无法满足这一需求。
为了解决这一问题,研究人员开始探索加速T2A系统的方法。目前,主流的加速技术主要基于蒸馏(distillation),即通过训练一个较小的模型来模拟较大模型的行为,从而在保持一定生成质量的同时提高推理速度。然而,蒸馏方法存在诸多局限性,如训练成本高、需要大量存储资源来保存教师模型生成的轨迹-输出对、以及可能导致生成多样性的降低等。此外,蒸馏方法往往依赖于分类器无引导(Classifier-Free Guidance, CFG)技术来提高生成质量,但CFG同时也会带来生成多样性的降低和过度饱和(over-saturation)的问题。
研究目的
本研究旨在提出一种不依赖于蒸馏的对抗性加速算法,用于加速基于扩散模型或流模型的文本到音频生成系统。具体而言,研究目的包括:
- 开发一种新的对抗性后训练(post-training)方法:通过引入相对论对抗性损失(Relativistic Adversarial Loss)和对比损失(Contrastive Loss),在保持生成质量的同时显著提高推理速度。
- 优化模型架构和采样策略:通过改进模型架构和采用更高效的采样策略,进一步减少推理时间,使得T2A系统能够在边缘设备上实时运行。
- 评估加速效果和生成质量:通过客观指标和主观评价,验证所提方法在加速效果和生成质量方面的优越性,并与现有加速方法进行比较。
- 探索创意应用潜力:通过实际案例展示加速后的T2A系统在创意应用领域的潜力,如音乐创作、声音设计等。
研究方法
1. 基础模型选择与预训练
本研究选择Stable Audio Open(SAO)作为基础模型,该模型是一个基于扩散模型的文本到音频生成系统,能够生成高质量的立体声音频。SAO模型由预训练的自动编码器、T5文本嵌入器和扩散Transformer(DiT)组成,总参数量约为1.06B。为了加速推理,研究对SAO模型进行了优化,减少了DiT的维度和层数,最终得到一个参数量约为0.34B的轻量级模型。
2. 对抗性相对对比后训练(ARC Post-Training)
ARC后训练是本研究的核心方法,它结合了相对论对抗性损失和对比损失来优化预训练的扩散模型。具体而言,ARC后训练包括以下步骤:
- 初始化:将预训练的扩散模型作为生成器(G)和鉴别器(D)的初始化模型。
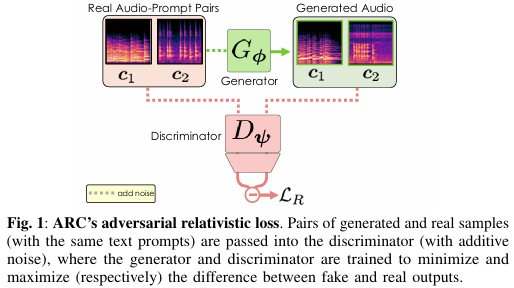
- 相对论对抗性损失(LR):通过引入相对论对抗性损失,鼓励生成器生成更逼真的音频样本,同时使鉴别器能够更准确地区分真实样本和生成样本。相对论对抗性损失通过比较成对的真实样本和生成样本(共享相同的文本提示)来计算损失,从而提供更强的梯度信号。
- 对比损失(LC):为了增强生成器对文本提示的遵循能力,研究引入了对比损失。对比损失通过训练鉴别器来区分具有正确和错误文本提示的音频样本,从而鼓励鉴别器关注语义特征而不是高频特征。这有助于提高生成音频与文本提示之间的一致性。
- 联合优化:在训练过程中,交替更新生成器和鉴别器的参数,以最小化相对论对抗性损失和对比损失的总和。
3. 采样策略优化
为了进一步提高推理速度,研究采用了乒乓采样(Ping-Pong Sampling)策略。乒乓采样通过交替进行去噪和再加噪操作来迭代优化样本,从而减少了对传统ODE求解器的依赖。这种采样策略使得模型能够在更少的采样步骤内生成高质量的音频样本。
4. 边缘设备优化
为了使加速后的T2A系统能够在边缘设备上实时运行,研究还进行了边缘设备优化。具体而言,研究采用了Arm的KleidiAI库和LiteRT运行时,通过动态Int8量化技术来减少模型大小和推理时间。动态Int8量化技术允许在推理过程中动态量化激活值,从而在保持一定生成质量的同时显著减少内存占用和推理时间。
研究结果
1. 加速效果
实验结果表明,ARC后训练显著提高了T2A系统的推理速度。在H100 GPU上,优化后的模型能够在约75毫秒内生成12秒的44.1kHz立体声音频,相比原始SAO模型(约100秒)加速了超过100倍。在移动边缘设备上(如Vivo X200 Pro智能手机),优化后的模型也能在约7秒内完成生成任务,实现了实时音频生成。
2. 生成质量
通过客观指标(如FD openl3、KL passt、CLAP分数等)和主观评价(如webMUSHRA测试)发现,ARC后训练在保持生成质量的同时显著提高了推理速度。具体而言,优化后的模型在音频质量、语义对齐和提示遵循能力方面均表现出色,且生成多样性显著高于现有蒸馏方法(如Presto)。
3. 边缘设备性能
边缘设备优化实验表明,通过动态Int8量化技术,优化后的模型在保持一定生成质量的同时显著减少了内存占用和推理时间。在Vivo X200 Pro智能手机上,优化后的模型能够在约7秒内完成生成任务,且峰值运行时RAM使用量从6.5GB降低到3.6GB。
研究局限
尽管本研究在加速文本到音频生成系统方面取得了显著进展,但仍存在以下局限性:
- 模型大小和存储需求:优化后的模型仍然占用较大的存储空间(数GB),这可能限制了其在某些应用场景中的部署和分发。
- 计算资源需求:尽管ARC后训练显著提高了推理速度,但在资源受限的设备上(如低端智能手机),实时音频生成可能仍然面临挑战。
- 生成多样性评估:尽管本研究提出了CLAP条件多样性分数(CCDS)来评估条件生成多样性,但该指标可能无法全面反映生成音频的多样性。未来研究可以探索更全面的多样性评估方法。
- 特定领域性能:本研究主要关注通用音频生成任务,对于特定领域(如音乐、语音合成等)的音频生成任务,ARC后训练的性能可能需要进一步验证和优化。
未来研究方向
针对本研究的局限性和现有技术的不足,未来研究可以从以下几个方面展开:
- 模型压缩与轻量化:探索更高效的模型压缩和轻量化技术,以减少模型大小和存储需求。例如,可以采用知识蒸馏、剪枝、量化等技术来进一步压缩模型。
- 边缘设备优化:针对资源受限的边缘设备,研究更高效的推理加速策略。例如,可以探索更高效的采样策略、硬件加速技术(如专用神经网络处理器)等。
- 多样性评估与增强:研究更全面的多样性评估方法,以更准确地评估生成音频的多样性。同时,探索增强生成多样性的技术,如条件变分自编码器(CVAE)、生成对抗网络(GAN)的变种等。
- 特定领域应用:针对特定领域(如音乐、语音合成等)的音频生成任务,研究专门的加速和优化方法。例如,可以结合领域知识来设计更高效的模型架构和训练策略。
- 多模态融合:探索文本到音频生成系统与其他模态(如图像、视频)的融合技术,以实现更丰富的多媒体内容生成。例如,可以研究文本到视频生成系统中的音频同步和生成技术。
- 实时交互与反馈:研究实时交互和反馈机制,以使用户能够在生成过程中实时调整参数和提供反馈。这将有助于提高生成音频的满意度和实用性。
结论
本研究提出了一种不依赖于蒸馏的对抗性加速算法——对抗性相对对比后训练(ARC Post-Training),用于加速基于扩散模型或流模型的文本到音频生成系统。实验结果表明,ARC后训练在保持生成质量的同时显著提高了推理速度,使得T2A系统能够在边缘设备上实时运行。未来研究可以进一步探索模型压缩与轻量化、边缘设备优化、多样性评估与增强、特定领域应用、多模态融合以及实时交互与反馈等方向,以推动T2A技术在更多领域的应用和发展。