一文理解扩散模型(生成式AI模型)(2)
第二期内容主要是扩散模型的架构,其中包括用于扩散模型的U-Net架构和用于扩散模型的transformer架构。(transformer架构非常重要)
扩散模型需要训练一个神经网络来学习加噪数据的分数函数,或者学习加在数据上的噪声(这对应上文所展示的扩散模型的两种训练范式,详情请见一文理解扩散模型(生成式AI模型)(1)-CSDN博客)。并且因为分数函数是对输入数据的似然函数的导数,所以其维度和输入数据的维度相同;同理,对输入数据的每一个维度都加入独立的标准高斯噪声,所以神经网络预测的噪声的维度与输入数据相同。
用于扩散模型的U-Net
用于扩散模型的U-Net架构通常用于图像生成的任务。(下面都简写为U-Net架构)U-Net架构是一种典型的编码-解码结构,满足输出和输入的分辨率相同的条件,主要由3部分组成:下采样,上采样和跳连(skip connection)。
编码器利用卷积层和池化层进行逐级下采样(下采样的过程中分辨率逐级减少,类似于放大的过程),数据的通道数在卷积的作用下逐渐增大,从而可以学习图片的的高级语义信息。
解码器利用反卷积进行逐级下采样(进行与编码器相反的操作)。在这个过程中输入原始图像中的空间信息与图像中的边缘信息会逐渐恢复。最终,低分辨率的特征图最终会被映射为与原数据维度相同的像素级结果图。
为了弥补编码阶段下采样所丢失的信息,在编码器与解码器之间利用跳连来融合两个过程中对应位置上的特征图,使解码器在进行上采样时能融合不同层次的特征信息,进而恢复和完善原始数据中的细节信息。
以下为U-Net架构图(因为解码部分的操作与编码部分相反,所以省略了解码部分)
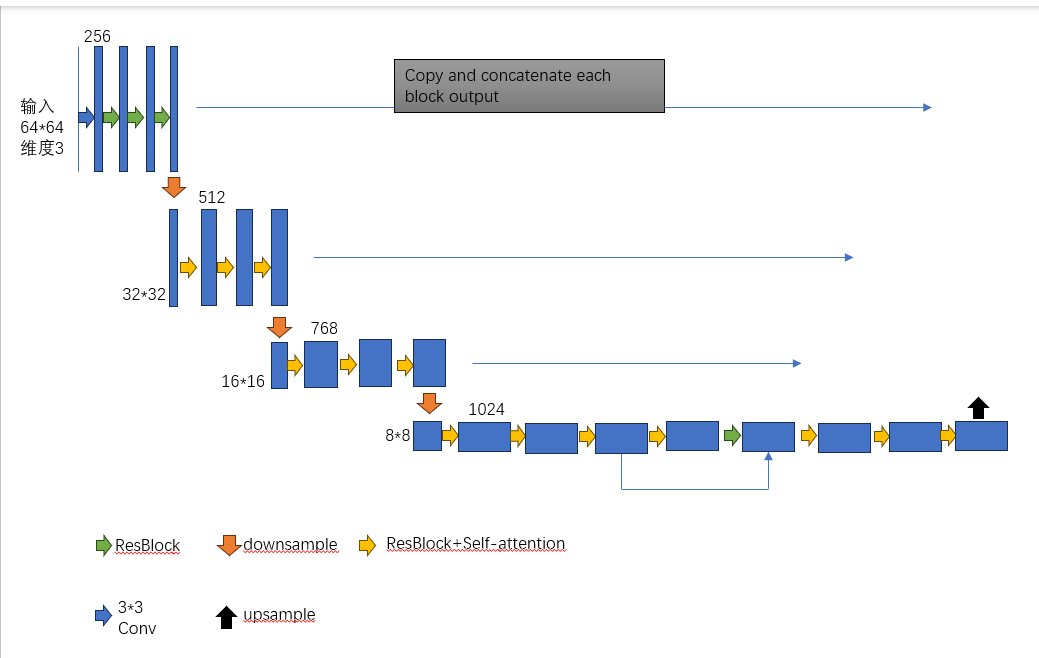
其中ResBlock为残差模块,Self-attention为自注意力机制,3*3 Conv为进行3*3的卷积操作,downsample为下采样,upsample为上采样
该结构在第t步去噪过程中,接受去噪对象和时间嵌入,输出去噪结果。由于去噪过程是依赖于时间t的,所以残差模块在抽取特征时,也将时间嵌入
考虑进来。
Transformer
目前U-Net是扩散模型的主流结构,但Transformer架构也有非常不错的效果。这里仅对Transformer作一些总体介绍,更多细节留在新的栏目中来展现。
Transformer主要由自注意力机制和前馈神经网络组成。在自注意力机制中,输入序列中的每个元素都会与其他元素进行相互作用,从而形成一个新的特征向量。这种机制允许模型对输入序列进行非常灵活的处理,能够捕捉输入序列中的长依赖关系,且因为它的并行性使得速度大大提升。前馈神经网络也有非常大的作用,该模块由几层全连接层组成,使用激活函数ReLU对中间层进行激活,并且增加了非线性关系,从而能更好地进行数据建模。
更多关于Transformer的总体概述和自注意力机制运作模式和细节将在新的栏目中更新,敬请期待!