MySQL基础原理
目录
一、MySQL架构
1、四层架构
2、MySQL运行机制
二、MySQL存储引擎
1、不同存储引擎对比
2、InnoDB存储结构
2.1 内存结构
2.2 磁盘结构
3、日志先行策略
3.1 核心思想
3.2 关键组件与流程
3.3 数据安全保证
3.3.1 崩溃恢复
3.3.2 持久性保障
一、MySQL架构
1、四层架构

1> 连接层
- 客户端连接器(Client Connectors):提供与MySQL服务器建立的支持。目前几乎支持所有主流的服务端编程技术。
2> 服务层
- 连接池(Connection Pool):管理客户端连接、认证及线程处理。
- 系统管理和控制工具( Management Services & Utilities ) :例如备份恢复、安全管理、集群管理等。
- SQL 接口( SQL Interface ):收客户端请求并返回结果,支持DML、DDL、存储过程 、视图、触发器等操作。
- 解析器( Parser ) :负责将请求的 SQL 解析生成一个 " 解析树 " 。然后根据一些 MySQL 规则进一步检查解析树是否合法。
- 查询优化器( Optimizer ) :当 “ 解析树 ” 通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互。
- 查询缓存( Query Cache,8.0+已移除):缓存SELECT语句及其结果集,以Key-Value形式存储。
核心引擎:
-
InnoDB:默认引擎,支持事务(ACID)、行锁、MVCC、外键,采用聚簇索引。
-
MyISAM:表锁、全文索引,适合读密集型场景(如
*.MYD/*.MYI文件)。 -
Memory:数据存于内存,适用于临时表。
4> 系统文件层
数据最终以文件形式存储在磁盘。主要包含日志文件,数据文件,配置文件,pid 文件,socket 文件等。
日志文件:
- 错误日志(Error log)
show variables like '%log_error%' //默认开启- 通用查询日志(General query log):记录一般查询语句
show variables like '%general%';- 二进制日志(binary log)
show variables like '%log_bin%'; //是否开启
show variables like '%binlog%'; //参数查看
show binary logs;//查看日志文件- 慢查询日志(Slow query log):记录所有执行时间超时的查询SQL,默认是10秒。
show variables like '%slow_query%'; //是否开启
show variables like '%long_query_time%'; //时长数据文件:
- db.opt 文件:记录这个库的默认使用的字符集和校验规则。
- frm 文件:存储与表相关的元数据(meta)信息,包括表结构的定义信息等,每一张表都会有一个frm 文件。
- MYD 文件:MyISAM 存储引擎专用,存放 MyISAM 表的数据(data),每一张表都会有一个.MYD 文件。
- MYI 文件: MyISAM 存储引擎专用,存放 MyISAM 表的索引相关信息,每一张 MyISAM 表对 应一个 .MYI 文件。
- ibd 文件和 IBDATA 文件:存放 InnoDB 的数据文件(包括索引)。 InnoDB 存储引擎有两种表空间方式:独享表空间和共享表空间。独享表空间使用 .ibd 文件来存放数据,且每一张InnoDB 表对应一个 .ibd 文件。共享表空间使用 .ibdata 文件,所有表共同使用一个(或多个,自行配置).ibdata 文件。
- ibdata1 文件:系统表空间数据文件,存储表元数据、 Undo 日志等 。
- ib_logfile0 、 ib_logfile1 文件: Redo log 日志文件。
配置文件:用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
pid 文件:pid 文件是 mysqld 应用程序在 Unix/Linux 环境下的一个进程文件,和许多其他 Unix/Linux 服务端程序一样,它存放着自己的进程 id。
socket 文件:socket 文件也是在 Unix/Linux 环境下才有的,用户在 Unix/Linux 环境下客户端连接可以不通过 TCP/IP 网络而直接使用 Unix Socket 来连接 MySQL。
2、MySQL运行机制
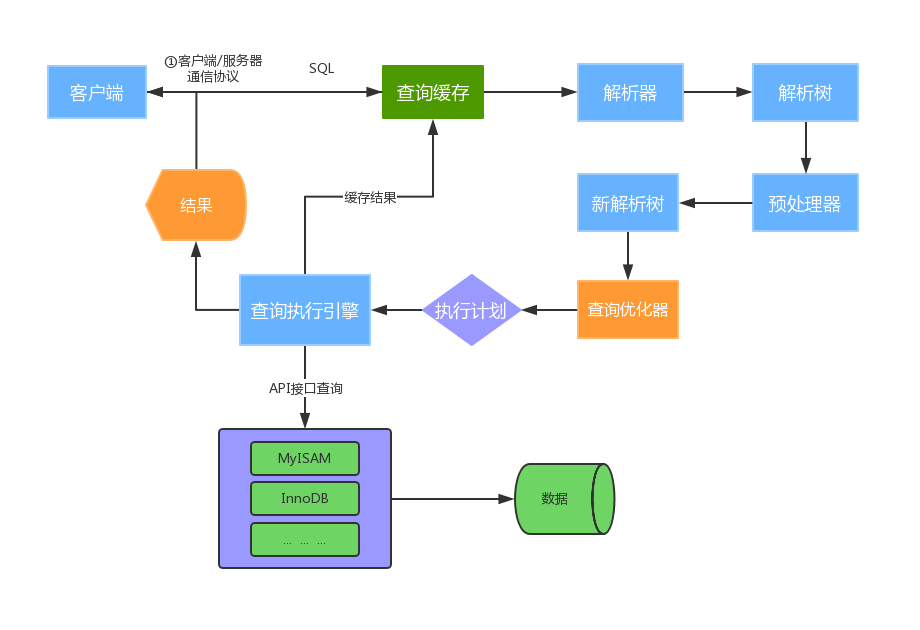
连接建立:客户端通过 TCP/IP 或 Socket 连接 MySQL 服务。
查询缓存:缓存命中直接返回,否则继续。
查询解析:解析 SQL 生成语法树,检查权限。
优化器决策:选择索引、JOIN 顺序,生成执行计划。
执行引擎调用:通过存储引擎读取数据(如全表扫描或索引查找)。
结果返回:将数据返回客户端,可能缓存结果(Query Cache)。
二、MySQL存储引擎
1、不同存储引擎对比
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务支持 | ✔️ | ❌ | ❌ |
| 锁粒度 | 行级锁 | 表级锁 | 表级锁 |
| 外键 | ✔️ | ❌ | ❌ |
| 崩溃恢复 | ✔️ | ❌(需手动修复) | ❌(数据丢失) |
| 存储介质 | 磁盘 | 磁盘 | 内存 |
| 索引类型 | 聚集索引(B+Tree) | 非聚集索引(B+Tree) | 哈希索引(默认) |
| 适用场景 | 高并发事务、OLTP | 读密集型、OLAP | 临时数据、缓存 |
2、InnoDB存储结构
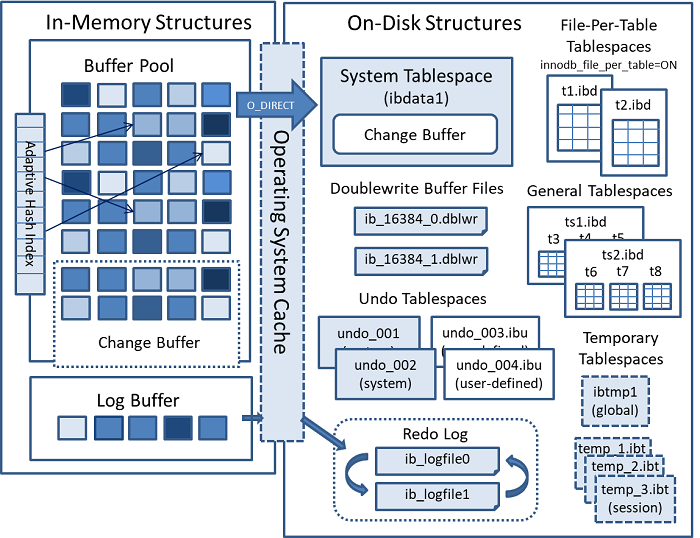
InnoDB架构分为内存结构与磁盘结构两部分,通过日志先行(Write-Ahead Logging, WAL)策略保证事务的持久性:
-
内存结构:包括缓冲池(Buffer Pool)、重做日志缓冲(Log Buffer)、变更缓冲(Change Buffer)、自适应哈希索引(Adaptive Hash Index)等,用于加速数据读写并减少磁盘IO138。
-
磁盘结构:包含表空间(Tablespace)、重做日志文件(Redo Log)、撤销日志(Undo Log)等,数据以页(16KB)为单位组织,并通过B+树索引管理
2.1 内存结构
1> 缓冲池(Buffer Pool)
核心作用:缓存数据页(Data Page)、索引页(Index Page)等,采用链表数据结构管理,减少磁盘IO。通常分配物理内存的60%-80%,
LRU优化:采用改进的LRU算法,将缓冲池分为New Sublist(5/8)和Old Sublist(3/8)加入元素时并不是从表头插入,而是从中间midpoint位置插入,如果数据很快被访问,那么page就会向new列表头部移动,如果数据没有被访问,会逐步向old尾部移动,等待淘汰。
配置参数:
show variables like '%innodb_page_size%'; //查看page页大小
show variables like '%innodb_old%'; //查看lru list中old列表参数
show variables like '%innodb_buffer%'; //查看buffer pool参数
//建议:将innodb_buffer_pool_size设置为总内存大小的60%-80%,
//innodb_buffer_pool_instances可以设置为多个,这样可以避免缓存争夺2> 变更缓冲(Change Buffer)
功能:针对非唯一辅助索引的插入、删除操作进行缓冲,合并多次修改为单次磁盘IO,减少随机写
限制:唯一索引无法使用,因需立即检查唯一性
3> 自适应哈希索引(AHI)
动态优化:用于优化对Buffer Pool数据查询,自动为高频访问的B+树索引页建立哈希索引,将查询复杂度从O(log n)降至O(1)
分区设计:默认分为8个分区,减少锁争用,提升并发
4> 重做日志缓冲(Log Buffer)
事务持久性:事务提交前先写Redo Log到Log Buffer,再根据innodb_flush_log_at_trx_commit配置刷盘。
innodb_flush_log_at_trx_commit:
=1(默认):事务提交时立即刷盘 Redo Log,保证持久性,但性能较低。
=0:每秒刷盘,可能丢失 1 秒内的提交数据。
=2:写入 OS 缓存,不强制刷盘,依赖操作系统刷盘策略(仍可能丢失数据)。
2.2 磁盘结构
1> 表空间(Tablespace)
-
系统表空间:存储元数据、Undo Log、Doublewrite Buffer等。
-
独立表空间(.ibd文件):每张表单独存储数据和索引,支持更灵活的备份与管理。
2> 数据页与B+树索引
-
页结构:每页16KB,包含文件头、页头、用户记录、空闲空间等,通过双向链表连接相邻页。
-
B+树索引:
-
聚集索引:数据按主键排序存储,叶子节点直接包含行数据。
-
辅助索引:叶子节点存储主键值,需回表查询
-
3> 日志与恢复
-
Redo Log:记录物理修改,用于崩溃恢复。采用循环写入模式,配合检查点(Checkpoint)机制减少恢复时间。
innodb_log_file_size和innodb_log_files_in_group:
控制 Redo Log 文件的大小和数量,需平衡写入性能与恢复时间。
-
Undo Log:记录事务前的数据版本,支持回滚与MVCC(多版本并发控制)。Undo Log 的修改也会被 Redo Log 记录,确保崩溃时能恢复 Undo Log。
-
Doublewrite Buffer:解决因部分页写入(Partial Page Write)导致的数据页损坏(如写入 16KB 页时崩溃,只写入了一半)。
工作原理:
脏页刷盘前,先写入双写缓冲区的连续磁盘区域。
再从双写缓冲区复制到数据文件的实际位置。
崩溃恢复时,若数据页损坏,可从双写缓冲区恢复完整页。
3、日志先行策略
InnoDB 的 Write-Ahead Logging (WAL,日志先行) 策略是其保证数据持久性和崩溃恢复能力的核心机制。通过 WAL,InnoDB 在数据修改写入磁盘之前,先记录相关操作的日志,确保即使在系统崩溃时,也能通过日志恢复数据的一致性。
3.1 核心思想
“先写日志,后写数据”
在修改数据页(如插入、更新、删除)时,InnoDB 不会立即将修改后的数据页写入磁盘,而是先将这些操作以日志的形式记录到 Redo Log(重做日志) 中。只有在 Redo Log 持久化到磁盘后,事务才被视为提交成功。
3.2 关键组件与流程
(1) Redo Log(重做日志)
-
物理日志:记录的是对数据页的物理修改(如“将表空间 X 的页 Y 偏移 Z 处的值从 A 改为 B”),而不是逻辑操作(如 SQL 语句)。
-
循环写入:Redo Log 由多个固定大小的文件组成(默认
ib_logfile0和ib_logfile1),以循环方式覆盖写入。 -
持久化保证:事务提交时,必须确保其对应的 Redo Log 写入磁盘(通过
fsync系统调用强制刷盘),之后事务才能返回成功。
(2) 数据页的写入
-
脏页(Dirty Page):被修改但尚未写入磁盘的数据页称为脏页。
-
异步刷盘:InnoDB 的后台线程(如
Page Cleaner)会定期将脏页刷新到磁盘,与事务提交解耦,避免频繁的随机 I/O。
(3) Checkpoint(检查点)
-
标记已持久化的位置:Checkpoint 记录了当前哪些 Redo Log 对应的修改已经刷入磁盘数据页。
-
减少恢复时间:崩溃恢复时,只需从 Checkpoint 对应的 Redo Log 位置开始重放,无需处理全部日志。
3.3 数据安全保证
3.3.1 崩溃恢复
-
场景:若事务提交后系统崩溃,但脏页尚未刷盘,此时磁盘上的数据可能不完整。
-
恢复过程:
-
重启时,InnoDB 通过 Redo Log 重放最后一次 Checkpoint 之后的所有日志。
-
将未刷盘的脏页修改重新应用到数据页,确保数据的一致性。
-
最后通过 Undo Log 回滚未提交的事务。
-
3.3.2 持久性保障
-
事务提交的原子性:事务提交时,Redo Log 必须落盘,确保即使后续脏页刷盘失败,仍能通过日志恢复数据。
-
避免部分写(Partial Write):数据页写入可能因崩溃中断,但 Redo Log 记录了完整操作,可修复损坏的页。