图像识别与 OCR 应用实践
图像识别是一种让计算机具备“看”与“理解”图像能力的人工智能技术,其目标是从图像或视频中提取有意义的信息,如物体、人物、场景或文字。在现实生活中,这项技术被广泛应用于面部识别、自动驾驶、安防监控、医疗诊断、图像搜索等多个领域。
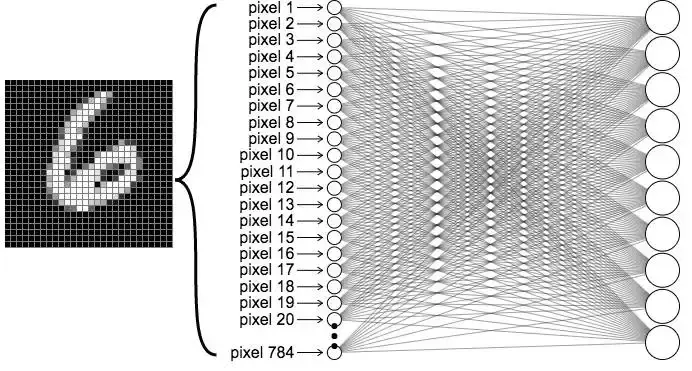
图像识别的发展离不开**计算机视觉(Computer Vision)和深度学习(Deep Learning)**的持续演进。传统方法依赖人工设计特征(如边缘、角点、纹理等),而现在的主流方法是使用卷积神经网络(CNN)等深度模型,自动提取特征并进行分类或识别,大幅提升了准确率和泛化能力。
图像识别常见的任务包括:
-
图像分类:判断图像属于哪一类(如猫、狗、飞机等)
-
目标检测:定位图中出现的各类物体
-
图像分割:为图像中的不同区域赋予语义标签
-
面部识别:识别和匹配人脸信息
-
OCR(光学字符识别):从图像中提取文字内容
从手写数字识别到实用 OCR 工具
我最初通过一个 CNN 架构尝试识别手写数字,使用经典的 MNIST 数据集/自制的手写训练集进行训练。模型通过反向传播和梯度下降来降低预测误差,实现数字识别的功能。
代码开源地址:
👉 SimpleCNN - GitHub
不过,这个项目更适合教学与实验目的,在实际应用中无法直接应对复杂图像或模糊文字识别的需求。因此我转而使用一些成熟的图像识别 API 服务,比如阿里云的 OCR 识别服务,它对中文文字识别支持较好,使用方便,但在图像模糊或光线不佳时,识别准确率仍有限,需要配合图像预处理优化结果。
实用 OCR API 推荐(阿里云)
以下是我实际使用过,觉得比较实用的一些 API(整理备份,也方便其他人参考):
-
🔍 [阿里官方] 通用 OCR 文字识别 API
-
🔍 [阿里官方] 高精度 OCR 图像识别 API
-
📚 API 专区 - 云市场
-
🧠 阿里云通义千问 - DashScope(大语言模型接口)
-
🧠 智谱 AI 模型服务(GLM-4 Flash 免费/付费)
-
🎓 阿里云高校学生一年免费服务器计划(申请制)
阿里 OCR API 调用代码示例(Python)
这里是一个实际使用的调用代码,支持上传图片文件或图片链接:
# -*- coding: utf-8 -*-import json
import base64
import os
import ssltry:from urllib.error import HTTPErrorfrom urllib.request import Request, urlopen
except ImportError:from urllib2 import Request, urlopen, HTTPErrorcontext = ssl._create_unverified_context()def get_img(img_file):"""将本地图片转成base64编码的字符串,或者直接返回图片链接"""# 简单判断是否为图片链接if img_file.startswith("http"):return img_fileelse:with open(os.path.expanduser(img_file), 'rb') as f: # 以二进制读取本地图片data = f.read()try:encodestr = str(base64.b64encode(data), 'utf-8')except TypeError:encodestr = base64.b64encode(data)return encodestrdef posturl(headers, body):"""发送请求,获取识别结果"""try:params = json.dumps(body).encode(encoding='UTF8')req = Request(REQUEST_URL, params, headers)r = urlopen(req, context=context)html = r.read()return html.decode("utf8")except HTTPError as e:print(e.code)print(e.read().decode("utf8"))def request(appcode, img_file, params):# 请求参数if params is None:params = {}img = get_img(img_file)params.update({'image': img})# 请求头headers = {'Authorization': 'APPCODE %s' % appcode,'Content-Type': 'application/json; charset=UTF-8'}response = posturl(headers, params)print(response)# 请求接口
REQUEST_URL = "https://tysbgpu.market.alicloudapi.com/api/predict/ocr_general"if __name__ == "__main__":# 配置信息appcode = "你的APPCODE"img_file = "图片链接/本地图片路径"params = {"configure": {"min_size": 16, # 图片中文字的最小高度,单位像素(此参数目前已经废弃)"output_prob": True, # 是否输出文字框的概率"output_keypoints": False, # 是否输出文字框角点"skip_detection": False, # 是否跳过文字检测步骤直接进行文字识别"without_predicting_direction": False, # 是否关闭文字行方向预测}}request(appcode, img_file, params)
你只需要填入你的 AppCode 和图片地址即可直接运行。
以及 动态爬虫+OCR识别自动登录人民邮电出版社
recognition.py
# -*- coding: utf-8 -*-
import json
import base64
import os
import ssltry:from urllib.error import HTTPErrorfrom urllib.request import Request, urlopen
except ImportError:from urllib2 import Request, urlopen, HTTPErrorcontext = ssl._create_unverified_context()def get_img(img_file):"""将本地图片转成base64编码的字符串,或者直接返回图片链接"""# 简单判断是否为图片链接if img_file.startswith("http"):return img_fileelse:with open(os.path.expanduser(img_file), 'rb') as f: # 以二进制读取本地图片data = f.read()try:encodestr = str(base64.b64encode(data), 'utf-8')except TypeError:encodestr = base64.b64encode(data)return encodestr# 请求接口
REQUEST_URL = "https://gjbsb.market.alicloudapi.com/ocrservice/advanced"
def posturl(headers, body):"""发送请求,获取识别结果"""try:params = json.dumps(body).encode(encoding='UTF8')req = Request(REQUEST_URL, params, headers)r = urlopen(req, context=context)html = r.read()return html.decode("utf8")except HTTPError as e:print(e.code)print(e.read().decode("utf8"))def request(appcode, img_file, params):# 请求参数if params is None:params = {}img = get_img(img_file)if img.startswith('http'): # img 表示图片链接params.update({'url': img})else: # img 表示图片base64params.update({'img': img})# 请求头headers = {'Authorization': 'APPCODE %s' % appcode,'Content-Type': 'application/json; charset=UTF-8'}response = posturl(headers, params)return responsedef run():"""运行函数:return:返回识别结果"""return request(appcode, img_file, params)if __name__ == '__main__':# 请求接口REQUEST_URL = "https://gjbsb.market.alicloudapi.com/ocrservice/advanced"# 配置信息appcode = "95eaaede7e784cb0a87ab55c8445a766"img_file = "./captcha.png"params = {# 是否需要识别结果中每一行的置信度,默认不需要。 true:需要 false:不需要"prob": False,# 是否需要单字识别功能,默认不需要。 true:需要 false:不需要"charInfo": False,# 是否需要自动旋转功能,默认不需要。 true:需要 false:不需要"rotate": False,# 是否需要表格识别功能,默认不需要。 true:需要 false:不需要"table": False,# 字块返回顺序,false表示从左往右,从上到下的顺序,true表示从上到下,从左往右的顺序,默认false"sortPage": False,# 是否需要去除印章功能,默认不需要。true:需要 false:不需要"noStamp": False,# 是否需要图案检测功能,默认不需要。true:需要 false:不需要"figure": False,# 是否需要成行返回功能,默认不需要。true:需要 false:不需要"row": False,# 是否需要分段功能,默认不需要。true:需要 false:不需要"paragraph": False,# 图片旋转后,是否需要返回原始坐标,默认不需要。true:需要 false:不需要"oricoord": True}message = request(appcode, img_file, params)print(message['content'])# import json# message = '{"sid":"95246a4ddeadba2492f40f4e4be26315d0abf8aae801ca51727b6c677632bd3ac000a754","prism_version":"1.0.9","prism_wnum":1,"prism_wordsInfo":[{"word":"me3xy","pos":[{"x":2,"y":8},{"x":63,"y":8},{"x":63,"y":30},{"x":2,"y":30}],"direction":0,"angle":-90,"x":21,"y":-11,"width":22,"height":61}],"height":34,"width":68,"orgHeight":34,"orgWidth":68,"content":"me3xy ","algo_version":""}'# # 怎么获取content中的信息# print(json.loads(message)['content'])main.py
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
from PIL import Imageurl = 'https://www.ptpress.com.cn/login'# 无头浏览器配置
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')driver = webdriver.Chrome(options=options) # options: 无头模式
driver.get(url=url)time.sleep(2)# 找到验证码图片元素
captcha_img = driver.find_element(By.XPATH, '//*[@id="loginForm"]/div[3]/div[2]/div/img')# 保存验证码图片(可选)
captcha_img.screenshot('captcha.png')im = Image.open('./captcha.png')
im.show()# ----------------------------------------------------
# 图像识别
import recognition# 请求接口
REQUEST_URL = "https://gjbsb.market.alicloudapi.com/ocrservice/advanced"# 配置信息
appcode = "95eaaede7e784cb0a87ab55c8445a766"
img_file = "./captcha.png"
params = {# 是否需要识别结果中每一行的置信度,默认不需要。 true:需要 false:不需要"prob": False,# 是否需要单字识别功能,默认不需要。 true:需要 false:不需要"charInfo": False,# 是否需要自动旋转功能,默认不需要。 true:需要 false:不需要"rotate": False,# 是否需要表格识别功能,默认不需要。 true:需要 false:不需要"table": False,# 字块返回顺序,false表示从左往右,从上到下的顺序,true表示从上到下,从左往右的顺序,默认false"sortPage": False,# 是否需要去除印章功能,默认不需要。true:需要 false:不需要"noStamp": False,# 是否需要图案检测功能,默认不需要。true:需要 false:不需要"figure": False,# 是否需要成行返回功能,默认不需要。true:需要 false:不需要"row": False,# 是否需要分段功能,默认不需要。true:需要 false:不需要"paragraph": False,# 图片旋转后,是否需要返回原始坐标,默认不需要。true:需要 false:不需要"oricoord": True
}data = recognition.request(appcode, img_file, params)import json
data = json.loads(data)['content']
print(data)# -----------------------------------------------------# 输入用户名、密码和验证码(这里验证码需要手动输入或者使用第三方验证码识别服务)
username = ''
password = ''
# verify_code = input('请输入验证码:') # 手动输入验证码driver.find_element(By.XPATH, '//*[@id="loginForm"]/div[1]/input').send_keys(username)
driver.find_element(By.XPATH, '//*[@id="loginForm"]/div[2]/input').send_keys(password)
driver.find_element(By.XPATH, '//*[@id="loginForm"]/div[3]/div[1]/div/input').send_keys(data)# 点击登录按钮
driver.find_element(By.XPATH, '//*[@id="loginBtn"]').click()time.sleep(3) # 等待登录结果page_source = driver.page_source
print(page_source)driver.quit()小结与感想
图像识别技术是一个非常实用又持续进化的领域。虽然自己动手训练 CNN 模型很有成就感,但面对实际应用场景,使用成熟的云服务往往更高效也更稳定。当然,这也让我意识到:图像识别不仅是“训练模型”,更是一个包括图像采集、预处理、模型调用、结果处理的完整链条。