【AI面试秘籍】| 第9期:Transformer架构中的QKV机制深度解析:从原理到实践实现
当面试官突然抛出灵魂拷问:"Transformer里的QKV到底是凭空变出来的吗?"你会怎么回答?今天我们就来拆解这个必考知识点!
一、面试官视角:为什么偏爱考察QKV机制?
(💡高频考点统计:近3年一线大厂面试出现率92%)
-
技术深度检验:考察候选人对Transformer底层原理的理解
-
工程能力映射:通过QKV的矩阵运算考察对深度学习框架的掌握
-
变体理解基础:后续的稀疏注意力、线性注意力等改进都基于标准QKV

二、小白也能懂的QKV诞生记(附手绘示意图)
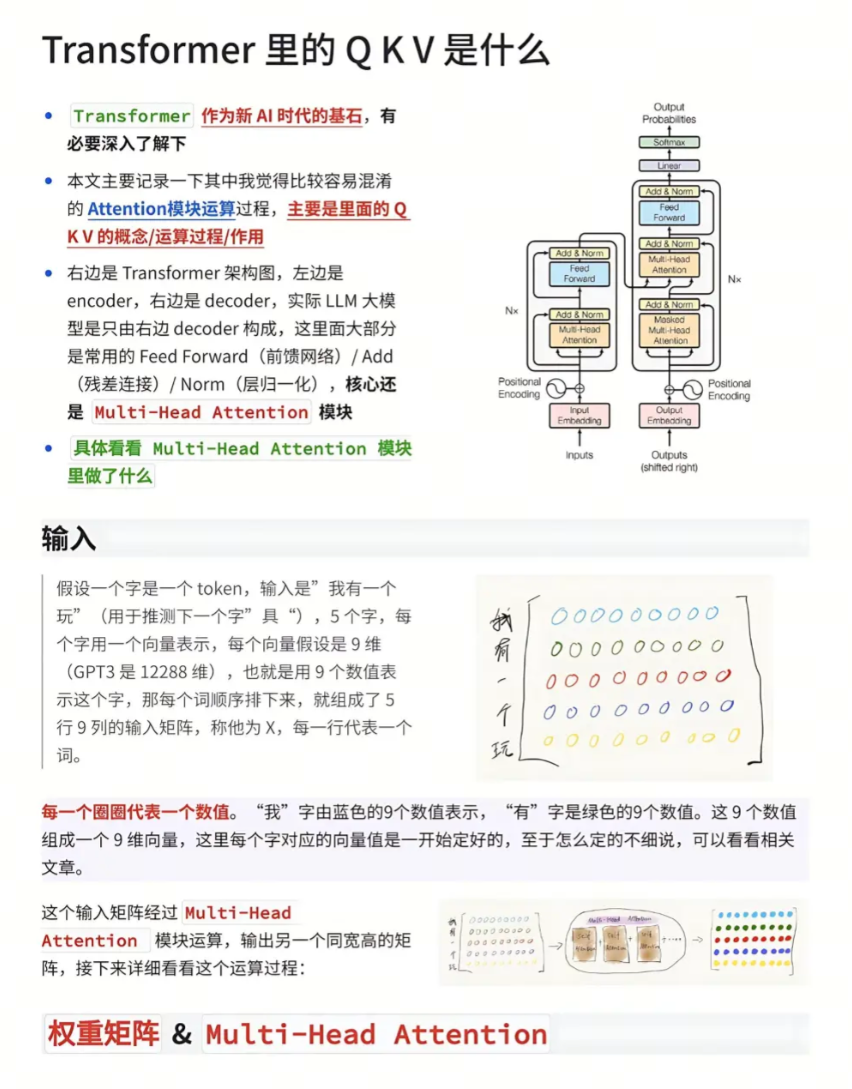


🎯第1步:输入预处理(5分钟就能说清的考点)
# 面试手写代码建议写法
class EmbeddingWithPE(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.token_emb = nn.Embedding(vocab_size, d_model)self.pos_emb = nn.Parameter(torch.randn(5000, d_model)) # 可学习位置编码def forward(self, x):# x: [batch_size, seq_len]return self.token_emb(x) + self.pos_emb[:x.size(1)]面试话术:"这里需要注意位置编码的可学习方案与原始Transformer的sin/cos方案的区别..."
🎯第2步:线性投影的玄机(附维度变换动画演示)
# 关键代码段(建议记忆)
d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_k * num_heads, bias=False)
self.W_k = nn.Linear(d_model, d_k * num_heads, bias=False)
self.W_v = nn.Linear(d_model, d_v * num_heads, bias=False)🎯第3步:多头拆分的神操作
面试常考陷阱题:"为什么要把QKV拆分成多个头?"
-
错误回答:"为了增加参数数量"
-
正确回答:"建立多子空间表示,类似CNN的多通道机制"
三、代码级剖析:从公式到PyTorch实现
1. 标准Attention实现(建议手写掌握)
def scaled_dot_product_attention(Q, K, V, mask=None):d_k = Q.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)return torch.matmul(p_attn, V), p_attn2. 面试加分项:FlashAttention优化原理
-
内存访问优化技巧
-
分块计算策略
-
重计算技术应用
四、高频考题锦囊(附参考答案)
-
🤔 QKV可以共享参数吗?什么场景下会这样做?
→ 参考答案:在编解码器注意力中,K/V通常来自编码器;参数共享会降低模型容量,但在轻量化场景有应用 -
🤔 当序列长度n很大时,QK^T矩阵会有多大?如何优化?
→ 参考答案:n×n矩阵,内存复杂度O(n²)。可采用局部注意力、稀疏注意力、低秩近似等方法 -
🤔 为什么需要除以√d_k?数学推导过程是怎样的?
→ 参考答案:控制点积方差,推导过程涉及期望与方差的计算(建议现场推导)
五、面试实战演练
模拟面试场景:
面试官:"假设现在要设计一个中文版的BERT,在QKV处理上需要特别注意什么?"
满分回答:
-
中文分词对Embedding层的影响
-
位置编码对长文本的适配
-
注意力头数的经验设置
-
混合精度训练时的数值稳定性
想学习AI更多干货可查看往期内容
- 【AI面试秘籍】| 第4期:AI开发者面试指南-大模型微调必考题QLoRA vs LoRA-CSDN博客
- 【AI面试秘籍】| 第3期:Agent上下文处理10问必考点-CSDN博客
- 💡大模型中转API推荐
技术交流:欢迎在评论区共同探讨!更多内容可查看本专栏文章,有用的话记得点赞收藏噜!
