【C语言指针超详解(六)】--sizeof和strlen的对比,数组和指针笔试题解析,指针运算笔试题解析
目录
一.sizeof和strlen
1.1--sizeof
1.2--strlen
1.3--sizeof和strlen的对比
二.数组和指针笔试题解析
2.1--一维数组
2.2--字符数组
2.2.1--代码1:
2.2.2--代码2:
2.2.3--代码3:
2.2.4--代码4 :
2.2.5--代码5:
2.2.6--代码6:
2.3--二维数组
部分注意点总结:
三.指针运算笔试题解析
3.1--题目1:
3.2--题目2:
3.3--题目3:
3.4--题目4:
3.5--题目5:
3.6--题目6:
3.7--题目7:

🔥个人主页:@草莓熊Lotso的个人主页
🎬作者简介:C++研发方向学习者
📖个人专栏:《C语言》
⭐️人生格言:生活是默默的坚持,毅力是永久的享受。
一.sizeof和strlen
1.1--sizeof
-- sizeof 计算变量所占内存空间大小的,单位是字节,如果操作数是类型的话,计算的是使用类型创建的变量所占内存空间的大小。
sizeof 只关注占用内存空间的大小,不在乎内存中存放什么数据;sizeof中表达式不计算
比如:
#include<stdio.h>
int main()
{int a = 10;printf("%d\n", sizeof(a));//4printf("%d\n", sizeof (a+3.14));//8//sizeof中表达式不计算//3.14是double类型,a是int类型//a要进行算术转换为double类型,所有最后结果还是double类型printf("%d\n", sizeof(int));//4return 0;
}1.2--strlen
--strlen是C语言库函数,功能是求字符串长度。函数原型如下:
1 size_t strlen ( const char * str );
统计的是从strlen函数的参数str这个地址开始向后,\0之前字符串中字符的个数。
strlen函数会一直向后找\0字符,直到找到为止,所以可能存在越界查找。
#include <stdio.h>
#include<string.h>
int main()
{char arr1[3] = { 'a', 'b', 'c' };char arr2[] = "abc";//字符串后隐藏了一个\0;printf("%d\n", strlen(arr1));//随机值printf("%d\n", strlen(arr2));//3printf("%d\n", sizeof(arr1));//3printf("%d\n", sizeof(arr2));//4return 0;
}arr1中没有\0所有strlen是找不到\0的,可能会越界访问,产生随机值。sizeof中直接放数组名算的是整个数组的大小
1.3--sizeof和strlen的对比
| 对比项目 | sizeof | strlen |
|---|---|---|
| 类型 | 操作符 | 库函数(要包含头文件string.h) |
| 作用 | 计算变量或类型所占内存 空间大小,单位是字节 | 计算字符串中\0 之前字符的个数 |
| 参数类型 | 可以是各种类型数据类型 ,变量,表达式等 | 必须是const char*l类型 ,且字符要以\0结尾 |
| 是否关注\0 | 计算内存大小时,将\0所占空间 | 遇到\0停止计算, 不将\0计入字符串长度 |
| 编译/运行时计算 | 在编译阶段就可确定结果 所以sizeof中表达式不计算 | 在程序运行时才能计算出结果 |
| 举例 | char arr[] = "abc"; sizeof(arr)结果为4,包括\0的空间 | char arr[] = "abc"; strlen(arr)结果为3,不包括\0 |
二.数组和指针笔试题解析
--在分析题目前再回顾下数组名的意义:
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表示首元素的地址。
补充说明一下:sizeof里面如果是地址,不是4就是8,看在多少位机器下。再就是大家可以自己去画图理解下面的题目更直观
2.1--一维数组
--注意看注释
#include<stdio.h>
int main()
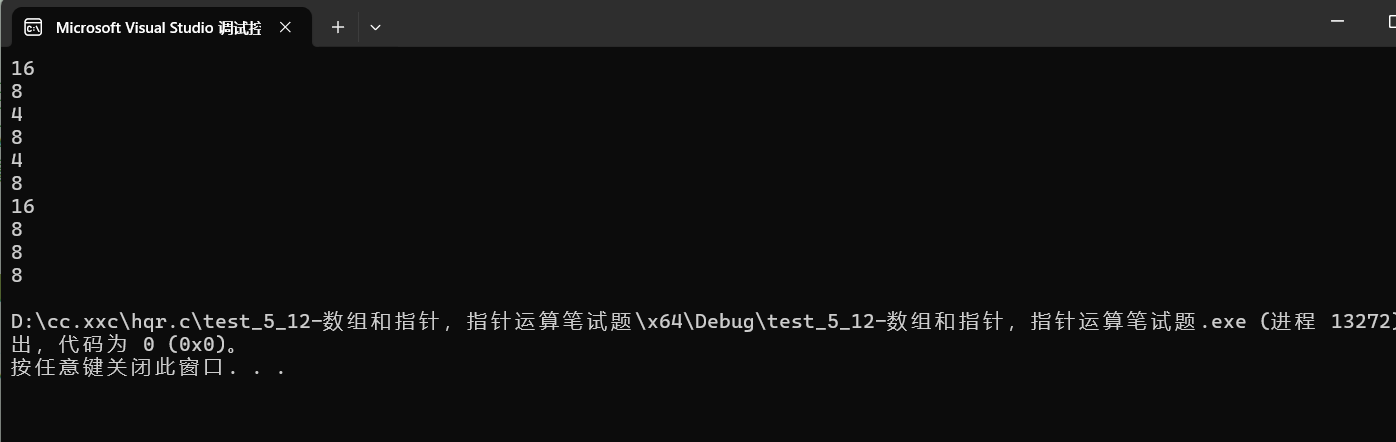
{int a[] = { 1,2,3,4 };printf("%zu\n", sizeof(a));//16//a是数组名,且单独存放在sizeof中,所以算的是整个数组的大小printf("%zu\n", sizeof(a + 0));// 4/8(看在多少位机器下)//a是数组名,且不单独存放在sizeof中,所以是数组首元素的地址,加0还是数组首元素的地址//只要是地址,就是4/8printf("%zu\n", sizeof(*a));//4//这里a是数组名,是数组首元素地址(原因不再说了),*a则是数组首元素,int类型,所以是4printf("%zu\n", sizeof(a + 1));// 4/8//这里a是数组首元素地址,a+1是数组第二个元素的地址,所以还是4/8printf("%zu\n", sizeof(a[1]));//4//数组中第二个元素,int类型,所以是4printf("%zu\n", sizeof(&a));// 4/8//&a是取出整个数组的地址,但还是地址,所以还是4/8//&a的特殊性主要体现在加减整数printf("%zu\n", sizeof(*&a));//16// *&a==a,a是数组名,且在sizeof中,所以算的整个数组大小printf("%zu\n", sizeof(&a + 1));// 4/8//&a是数组的地址,&a+1是跳过整个数组后的地址,是地址就是4/8个字节printf("%zu\n", sizeof(&a[0]));//4/8//&a[0]是数组首元素的地址,所以还是4/8printf("%zu\n", sizeof(&a[0] + 1));// 4/8//&a[0]+1就是第二个元素的地址,是地址就还是4/8
}
2.2--字符数组
--注意看注释
2.2.1--代码1:
#include<stdio.h>
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%zu\n", sizeof(arr));//6//arr是数组名,且放在sizeof中,所以是算整个数组大小,且是char,所以为6printf("%zu\n", sizeof(arr + 0));// 4/8//数组名arr在这里是数组首元素地址,是地址就是4/8printf("%zu\n", sizeof(*arr));// 1//数组名arr在这里是数组首元素地址,所以*arr就是数组首元素,char类型,为1printf("%zu\n", sizeof(arr[1]));// 1//arr[1]是数组第二个元素,char类型.为1printf("%zu\n", sizeof(&arr));// 4/8//&arr是数组地址,是地址就是4/8printf("%zu\n", sizeof(&arr + 1));// 4/8//&arr是数组地址。&arr+1是跳过一整个数组的地址,是地址就是4/8printf("%zu\n", sizeof(&arr[0] + 1));// 4/8//&arr[0]+1是数组第二个元素的地址,是地址就是4/8
}
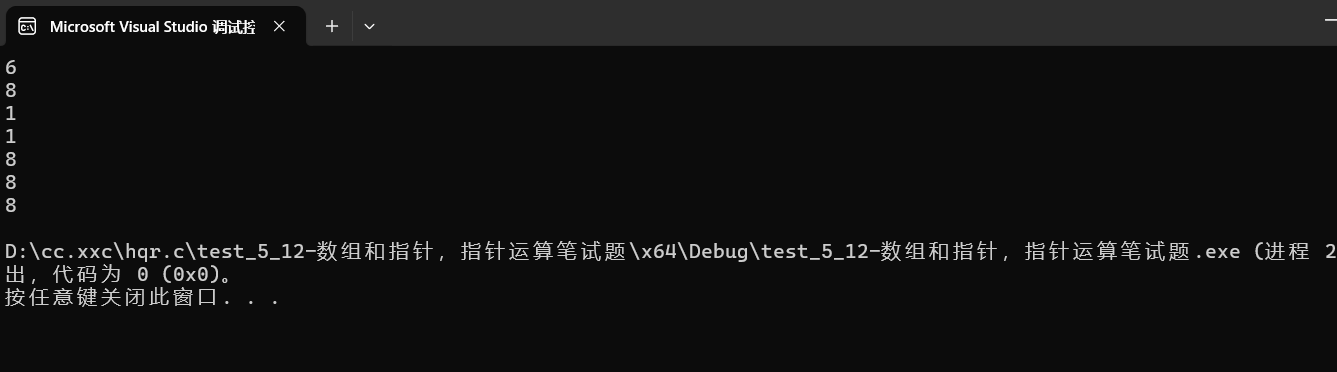
2.2.2--代码2:
#include<stdio.h>
#include<string.h>
int main()
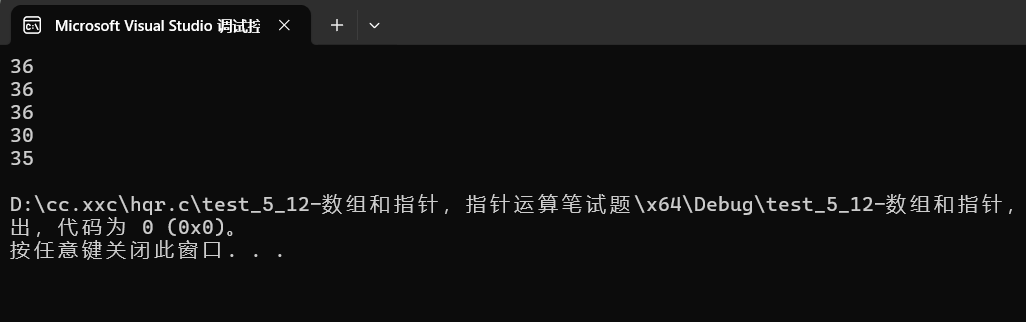
{char arr[] = { 'a','b','c','d','e','f' };printf("%zu\n", strlen(arr));//随机值//数组名arr在这里是数组首元素地址,从这开始往后数,直到\0为止,但是找不到\0//所以会越界,产生随机值printf("%zu\n", strlen(arr + 0));//随机值//和上一句代码理由差不多,因为arr+0还是数组首元素地址//printf("%zu\n", strlen(*arr));//err,崩溃//arr在这里是数组首元素地址,*arr是数组首元素,也就是a,a-97//这里给到strlen的不是地址,[strlen(const char* p)]类型不符合,所以会编译错误//printf("%zu\n", strlen(arr[1]));//err,崩溃//arr[1]是数组第二个元素,后续缘由和上面相同printf("%zu\n", strlen(&arr));//随机值//&arr是数组的地址,但还是从首元素开始的,找\0,但是找不到,会越界printf("%zu\n", strlen(&arr + 1));//随机值//&arr是数组的地址,&arr+1是跳过一整个数组后的地址,但还是找不到\0//这里也会是随机值,不过和前面的不同,和第一,第二个的差6printf("%zu\n", strlen(&arr[0] + 1));//随机值//&arr[0]+1是数组第二个元素的地址,从这往后面找,但还是和前面情况相同,所以是随机值,但也是不同的//和第一,第二个的差1
}
2.2.3--代码3:
#include<stdio.h>
int main()
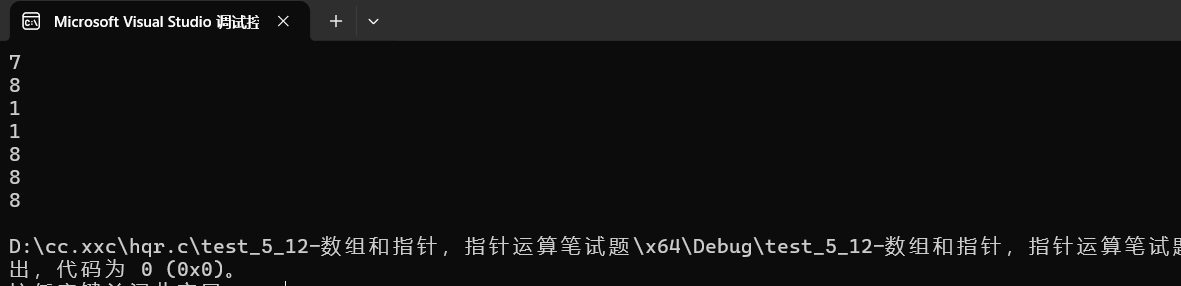
{char arr[] = "abcdef";//字符串里隐藏了个\0,所以其实是7个元素printf("%zu\n", sizeof(arr));//7//数组名arr直接放在sizeof中,算的是整个数组的大小,所以是7printf("%zu\n", sizeof(arr + 0));// 4/8//这里的数组名arr是数组的首元素地址,arr+0还是数组首元素的地址//是地址就是4/8printf("%zu\n", sizeof(*arr));//1//这里的数组名arr是数组的首元素地址,*arr是数组首元素,char类型,所以是1printf("%zu\n", sizeof(arr[1]));//1//arr[1]是数组第二个元素,char类型,所以是1printf("%zu\n", sizeof(&arr));// 4/8//&arr是数组的地址,是地址就是4/8printf("%zu\n", sizeof(&arr + 1));// 4/8//&arr是数组的地址,&arr+1是跳过一整个数组后的地址,是地址就是4/8printf("%zu\n", sizeof(&arr[0] + 1));// 4/8//&arr[0]+1是第二个元素的地址,是地址就是4/8
}
2.2.4--代码4 :
#include<stdio.h>
#include<string.h>
int main()
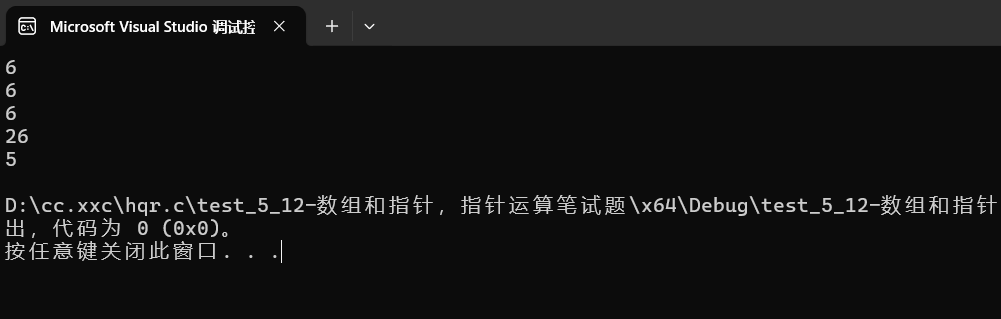
{char arr[] = "abcdef";//字符串里隐藏了个\0,所以其实是7个元素printf("%zu\n", strlen(arr));//6//这里的数组名arr是数组首元素的地址,从这开始往后找,直到\0;printf("%zu\n", strlen(arr + 0));//6//这里的数组名arr是数组首元素地址,arr+0还是,所以和上面的缘由一样//printf("%zu\n", strlen(*arr));//err,崩溃//*arr是数组首元素,这里给到strlen的不是地址// [strlen(const char* p)]类型不符合,所以会编译错误//printf("%zu\n", strlen(arr[1]));//err,崩溃//arr[1]是数组的第二个元素,理由和上面相同printf("%zu\n", strlen(&arr));//6//&arr是数组的地址,但还是从首元素开始的,直到\0printf("%zu\n", strlen(&arr + 1));//随机值//&arr是数组的地址,& arr + 1是跳过一整个数组后的地址,但就找不到\0了//会越界,产生随机值printf("%zu\n", strlen(&arr[0] + 1));//5//&arr[0]+1是第二个数组的地址,从这里开始,直到\0
}
2.2.5--代码5:
#include<stdio.h>
int main()
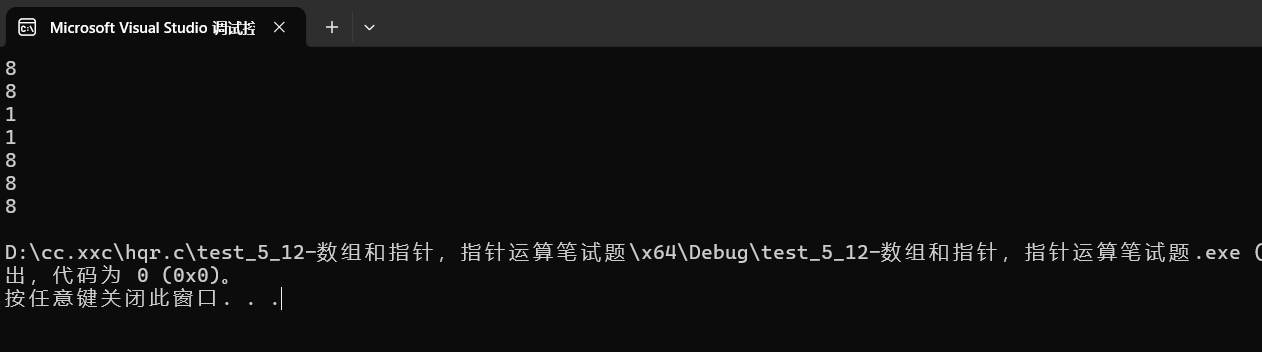
{char* p = "abcdef";//这里p存放的是首字符a的地址printf("%zu\n", sizeof(p));// 4/8//p存放的a的地址,是地址就是4/8printf("%zu\n", sizeof(p + 1));// 4/8//p+1(指针+1)还是地址,是b的地址,是地址就是4/8printf("%zu\n", sizeof(*p));// 1//p里存放的是a的地址,*p就是a,char类型,所以是1printf("%zu\n", sizeof(p[0]));// 1//p[0]=*(p+0)=*p=a,char类型,所以是1printf("%zu\n", sizeof(&p));// 4/8//&p是指针变量p的地址,是地址就是4/8printf("%zu\n", sizeof(&p + 1));//4/8//&p+1本质上也还是个地址,是地址就是4/8printf("%zu\n", sizeof(&p[0] + 1));// 4/8//&p[0]+1是第二个元素也就是b的地址,是地址就是4/8
}
2.2.6--代码6:
#include<stdio.h>
#include<string.h>
int main()
{char* p = "abcdef";//这里p存放的是首字符a的地址printf("%zu\n", strlen(p));//6//p里存放的是首字符a的地址,从这里开始找到\0为止printf("%zu\n", strlen(p + 1));//5//p+1是第二个字符b的地址,从这里开始也是找到\0为止//printf("%zu\n", strlen(*p));//err,崩溃// *p=a,这不是一个地址,和sizeof的参数类型不符合//printf("%zu\n", strlen(p[0]));//err,崩溃//p[0]=*(p+0)=*p=a,所以和上面一样printf("%zu\n", strlen(&p));//随机值//&p是指针变量p的地址,在这是找不到\0的,所以会是随机值printf("%zu\n", strlen(&p + 1));//随机值//&p+1是&p向后访问之后的地址,也是找不到\0的,但是随机值和上面不同printf("%zu\n", strlen(&p[0] + 1));//5//&p[0]+1就是从第二个元素也就是b的地址,从这里开始往后直到\0}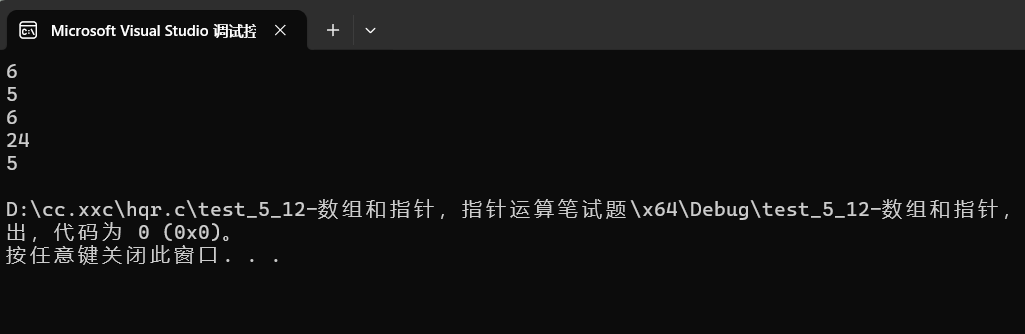
2.3--二维数组
--注意看注释
#include<stdio.h>
int main()
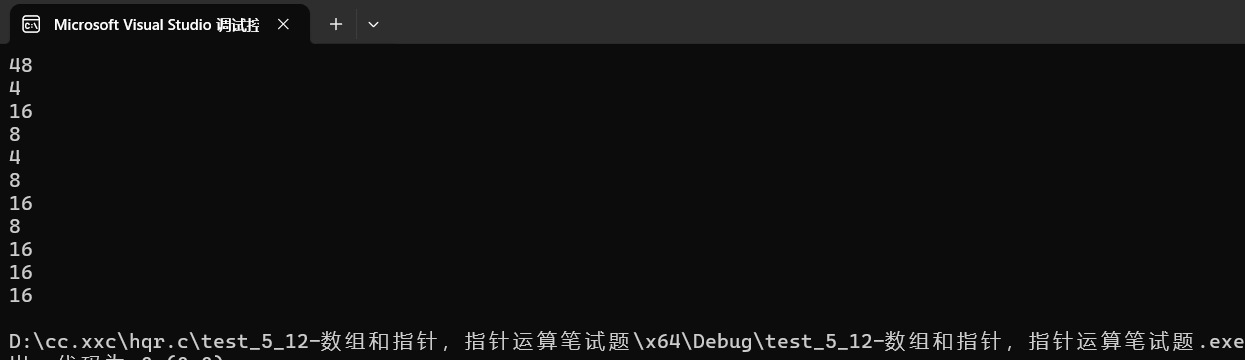
{int a[3][4] = { 0 };printf("%zu\n", sizeof(a));// 48//a是二维数组数组名,直接放在了sizeof中,计算的整个二维数组大小,12*4printf("%zu\n", sizeof(a[0][0]));//4//二维数组第一行第一个元素,int类型的printf("%zu\n", sizeof(a[0]));//16//a[0]是二维数组第一行一维数组的数组名,数组名直接放在sizeof中//算的是这一行一维数组的大小,4*4=16printf("%zu\n", sizeof(a[0] + 1));// 4/8//a[0]是二维数组第一行一维数组的数组名,在这里就是一维数组首元素的地址//a[0]+1是第一行一维数组第二个元素的地址,是地址就是4/8printf("%zu\n", sizeof(*(a[0] + 1)));// 4//a[0]+1是第一行一维数组第二个元素的地址,*(a[0] + 1)就是第二个元素,int类型printf("%zu\n", sizeof(a + 1));//4/8//a在这里是二维数组的首元素的地址,也就是第一行一维数组的地址,a+1则是第二行一维数组的地址//是地址就是4/8printf("%zu\n", sizeof(*(a + 1)));// 16//a + 1是第二行一维数组的地址,*(a + 1)则是第二行一维数组中的元素,4个,4*4=16printf("%zu\n", sizeof(&a[0] + 1));// 4/8//&a[0]是第一行一维数组的地址,&a[0]+1是跳过一整个数组之后的地址//其实也就是第二行一维数组的地址,是地址就是4/8printf("%zu\n", sizeof(*(&a[0] + 1)));//16//&a[0] + 1是第二行一维数组的地址,所以*(&a[0] + 1)是第二行所有元素,一共4个,4*4=16printf("%zu\n", sizeof(*a));//16//a是二维数组数组名,在这里就是二维数组的首元素的地址,也就是第一行一维数组的地址//*a则是第一行一维数组的所有元素,4个,4*4=16printf("%zu\n", sizeof(a[3]));//16//--sizeof中的表达式在编译时就已经确定结果了,所有后面不会计算了//sizeof在计算变量,数组大小时,是通过类型来推导的,不会真实去访问内存空间的//所以a[3]没有也不会发生越界访问,它的类型就是int(*)[4],那最后就是16
}
部分注意点总结:
- 判断存放的数据类型,是什么数组或者是字符指针变量存储字符串这种,它们各自有不同的特点
- 再注意数组名是否是那两种特殊情况,不是的话就是数组首元素地址。
- 注意如果sizeof里面是地址就是4/8,strlen要注意是否越界和参数类型是否匹配
- 最好可以画图理解
三.指针运算笔试题解析
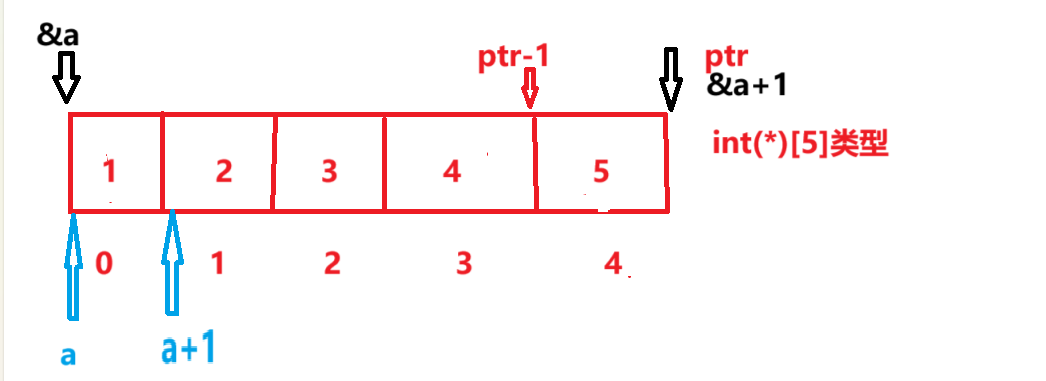
3.1--题目1:
#include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int* ptr = (int*)(&a + 1);printf("%d,%d", *(a + 1), *(ptr - 1));return 0;
}
//程序的结果是什么?
//2 5题解:
- &a是数组地址,+1跳过一整个数组到图示位置,将这样的地址存放在ptr中,类型不符合,所有将(&a+1)强制类型转换为(int*)类型。
- a是数组名,在这里是数组首元素地址,a+1是数组第二个元素的地址,*(a+1)则是第二个元素,也就是2
- ptr刚开始在图示&a+1处,减1到图中所示位置,*(ptr-1)则是此地址处的元素也就是5
- 所以程序的结果是:2 5
3.2--题目2:
#include<stdio.h>
struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}
//在X86环境下
//假设结构体的大小是20个字节
//程序输出的结果是啥?
//00100014
//00100001
//00100004题解:(注意是在X86环境下)
- 先将地址0x100000强制类型转换为(struct Test*)类型存放在p中
- 第一个printf里面p里存放的地址是(struct Test*)类型,假设结构体的大小是20个字节,+1就跳过20个字节,20转换成16进制就是0x000014,加起来后是0x100014
- 第二个printf里面将p强制类型转换为(unsigned long)类型,那+1就是直接+1,1转换为16进制就是0x000001,加起来后就是0x100001
- 第三个printf里面将p强制类型转换为(unsigned int*)类型,+1就是跳过4个字节,4转换为16进制就是0x000004,加起来后就是0x100004
- 所以最后程序的输出结果是:00100014 00100001 00100004 (每个结果间是会换行的)
3.3--题目3:
#include <stdio.h>
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int* p;p = a[0];printf("%d", p[0]);return 0;
}
//程序输出的结果是啥?
//1题解:
- 这里要注意数组里的几个元素用的是()而不是{},所以其实是逗号表达式,则int a[3][2] = {1,3,5};
- p=a[0]则是数组首元素地址,在二维数组中就是第一行一维数组的数组名
- p[0]等价于a[0][0]也就是第一行一维数组的首元素
- 所以程序的输出结果是 1
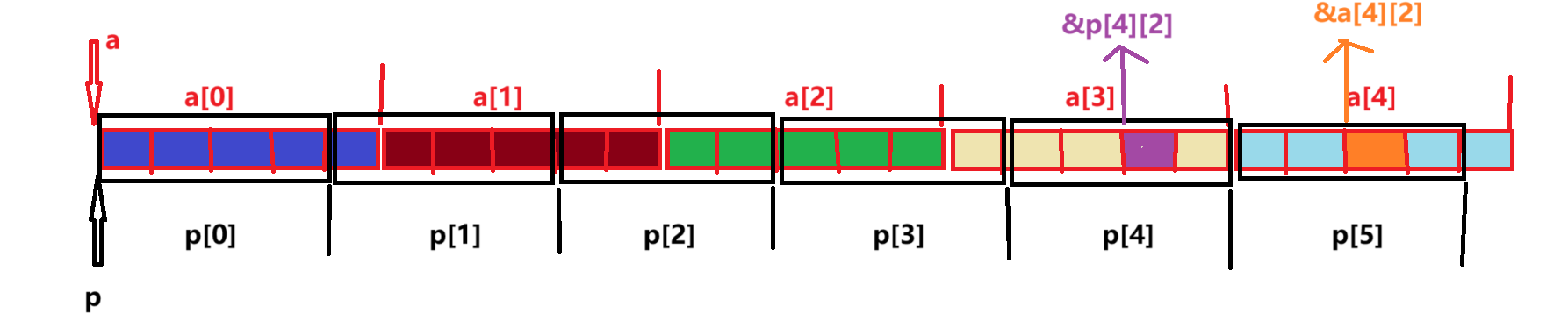
3.4--题目4:
#include <stdio.h>
int main()
{int a[5][5];int(*p)[4];p = a;printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}//假设环境是x86环境,程序输出的结果是啥?
//FFFFFFFC,-4题解:(注意是在X86环境下)
- 根据代码,可以得出p中一行4个元素,再如图中划分出来p和a
- 根据图示找到&p[4][2]和&a[4][2]的位置
- 地址减地址(指针减指针)的绝对值是它们之间的元素个数,但这里没有绝对值,且明显&a[4][2]靠后,所以&p[4][2] - &a[4][2]小于0,故是-4
- 根剧printf中的占位符要求,%p需要按16进制打印地址(它认为内存中的补码就是地址),所以先将-4转换成二进制补码形式,再转换为16进制也就是FFFFFFFC,而%d则是按10进制打印,直接就是-4.
- 所以程序输出的结果是:FFFFFFFC -4
3.5--题目5:
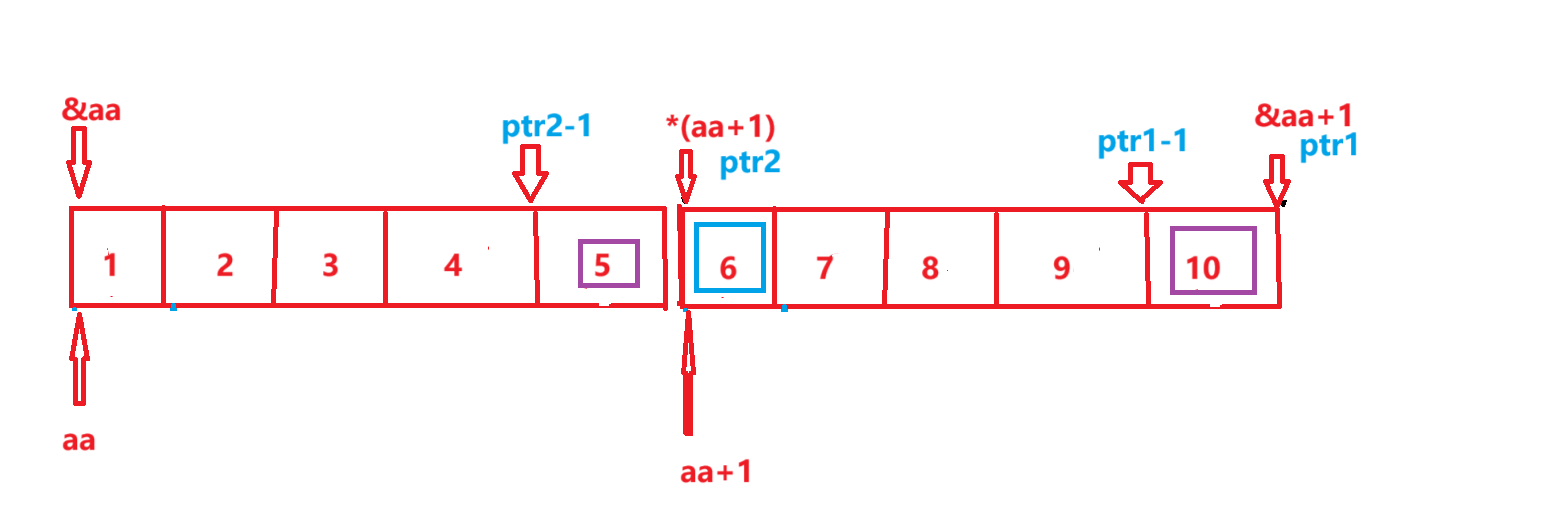
#include <stdio.h>
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* ptr1 = (int*)(&aa + 1);int* ptr2 = (int*)(*(aa + 1));printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}
//程序输出的结果是啥?
//10 5题解:
- 分别将&aa + 1和*(aa + 1)强制类型转换为(int*)类型存放在ptr1和ptr2中
- &aa是整个二维数组地址,aa是数组名这里是数组首元素地址也就是第一行一维数组地址
- 都+1了,跳过的距离不一样,移动到图中所示位置,且*(aa+1)=aa[1]最后也就是第二行一维数组首元素地址
- *(ptr1 - 1), *(ptr2 - 1),如图所示位置,解引用分别求出来这个地址处的元素
- 所以程序的输出结果是:10 5
3.6--题目6:
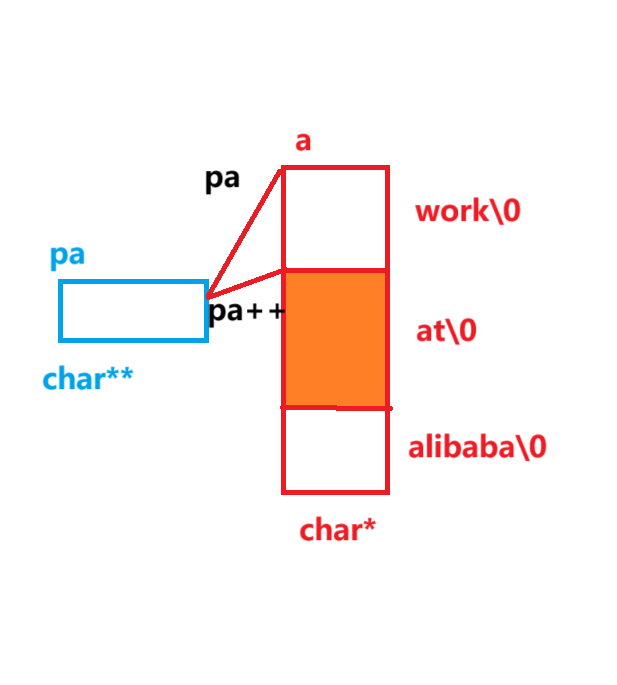
#include <stdio.h>
int main()
{char* a[] = { "work","at","alibaba" };char** pa = a;pa++;printf("%s\n", *pa);return 0;
}
//程序输出的结果是啥?
// at题解:
- 根据代码,可以得知pa存放的是数组a首元素的地址,pa++则得到了数组a第二个元素的地址,即at所在的地址,如图中所示
- *pa得到了字符串at,直接将它打印出来
- 所以程序的输出结果是:at
3.7--题目7:
#include <stdio.h>
int main()
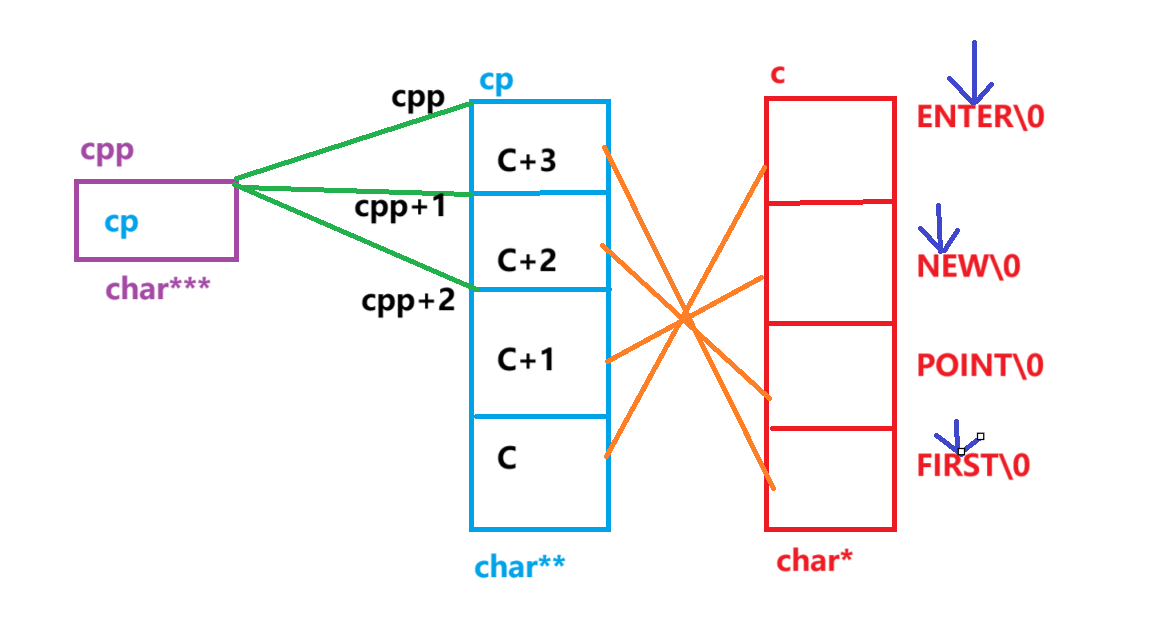
{char* c[] = { "ENTER","NEW","POINT","FIRST" };char** cp[] = { c + 3,c + 2,c + 1,c };char*** cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *-- * ++cpp + 3);printf("%s\n", *cpp[-2] + 3);printf("%s\n", cpp[-1][-1] + 1);return 0;
}
//程序输出的结果是啥?
//POINT
//ER
//ST
//EW题解:
- 根据题目初始化条件画出下图,明确指向关系等
- 第一个printf:先++cpp,让cpp来到了图示cpp+1的位置,也就是拿到了c+2的地址,再解引用(*++cpp),得到了c+2所指向的POINT的地址,再次解引用,拿到了POINT,将它打印出来
- 第二个printf中:因为第一次printf中已经++cpp一次了,所以现在刚开始在图示cpp+1的位置,再次++cpp,来到了cpp+2的位置,也就是拿到了c+1的地址,解引用拿到c+1所指向的NEW的地址 ,然后 --,拿到了ENTER的地址,再解引用一次,拿到ENTER,最后+3,来到ENTER中的第二个E,所以打印出ER
- 第三个printf中:因为前两次的++cpp,现在它在图示cpp+2的位置上,这时的cpp[-2]等价于*(cpp-2),指向的是图示cpp的位置 ,其意义是拿到了c+3的地址后解引用得到了FIRST的地址,再继续解引用一次拿到了FIRST,最后+3来到FIRST中的S,所以打印出ST
- 第四个printf中:将cpp[-1][-1]等价于 *(*(cpp-1)-1) ,还是因为两次++cpp,刚开始在图示cpp+2的位置上,先解析*(*(cpp-1)-1),cpp-1拿到了c+2的地址,解引用得到c+2所指向的POINT的地址 再-1得到NEW的地址,解引用后拿到NEW,解析完*(*(cpp-1)-1)也就是cpp[-1][-1],再+1,来到NEW中的E,所以打印出EW
- 所以程序的输出结果是:POINT ER ST EW (每个结果间是会换行的)
往期回顾:
【C语言指针超详解(一)】--指针变量和地址,指针变量类型的意义,指针运算
【C语言指针超详解(二)】--const修饰指针变量,野指针的辩析,assert断言,指针的使用和传址调用
【C语言指针超详解(三)】--数组名的理解,一维数组传参的本质,冒泡排序,二级指针,指针数组
【C语言指针超详解(四)】--字符指针变量,数组指针变量,二维数组传参的本质,函数指针变量,函数指针数组,转移表
【C语言指针超详解(五)】--回调函数,qsort函数的理解和使用,qsort函数的模拟实现
结语:本篇文章就到此结束了,继前面几篇文章后,在此篇文章中给大家分享了sizeof和strlen的知识点,还有指针和数组以及指针变量笔试题,这篇也是指针的最后一篇了,后续会继续分析其它内容,如果文章对你有帮助的话,欢迎评论,点赞,收藏加关注,感谢大家的支持。