CPU、GPU、内存、服务负载、数据库资源暂占用、数据库连接的概念关系详解
CPU是什么?内存是什么?CPU与内存有什么关系?k8s容器起的服务CPU使用量与内存使用量有什么关系?什么时候会用到CPU、内存?数据库的连接中,什么是服务端连接数和客户端连接数,它们有什么区别?服务端连接数设置的值可以跟客户端连接数不一样吗?服务数据库与服务CPU、内存有什么关系?k8s容器起的服务有什么资源?各种资源之间的关系是怎么样的?CPU和GPU的区别,服务会用到GPU吗?
一、CPU、内存及其关系
1. CPU是什么?
- **CPU(Central Processing Unit,中央处理器)**是计算机的核心组件,负责执行程序指令、处理数据和控制其他硬件设备。它通过指令周期(取指、解码、执行、写回)完成计算任务。
- 核心功能:逻辑运算、算术运算、流程控制。
- 特性:计算密集型任务(如加密解密、压缩解压)依赖CPU性能
- 指标:主频(GHz)、核心数、线程数(如4核8线程)
2. 内存是什么?
- **内存(Memory)**是计算机的临时存储设备,用于存放CPU正在处理或即将处理的程序和数据。其特点是读写速度快,但断电后数据丢失。
- 功能:临时存储运行中的程序和数据
- 特性:读写速度比磁盘快1000倍,断电数据丢失
- 指标:容量(GB)、频率(MHz)、时序(CL值)
3. CPU与内存的关系
- 协作模式:CPU从内存中读取指令和数据,处理完成后将结果写回内存。
- 性能依赖:
- 内存速度影响CPU效率(如内存延迟高会导致CPU“等待”)。
- CPU的缓存(Cache)设计减少了直接访问内存的次数,提升性能。
二、K8s容器服务的CPU与内存使用关系
1. 资源使用关系
- 独立性:CPU和内存是两种独立的资源类型,通常无直接数学关系。
- 间接关联:
- 高计算密集型任务(如加密、图像处理)可能同时消耗较多CPU和内存。
- 内存泄漏可能导致频繁GC(垃圾回收),间接增加CPU负载。
2. 何时会用到CPU和内存?
- CPU使用场景:
- 计算密集型操作(如算法运算、数据处理)。
- 多线程/进程并发执行。
- 内存使用场景:
- 程序加载到内存运行。
- 缓存数据(如数据库缓存、JVM堆内存)。
3. K8s资源管理
- 资源类型:CPU(可压缩资源)、内存(不可压缩资源)。
- 关键配置:
requests:预留资源(调度依据)。limits:资源使用上限(超限时CPU被限流,内存触发OOM Kill)。
- CPU瓶颈场景:高并发请求处理、视频转码、实时数据分析
- 内存瓶颈场景:大数据缓存、内存数据库(Redis)、全量日志分析
三、数据库连接中的服务端与客户端连接数
1. 服务端连接数
- 定义:数据库服务器允许的最大并发连接数(如MySQL的
max_connections参数)。 - 作用:保护数据库避免过载,防止资源耗尽。
2. 客户端连接数
- 定义:应用程序(客户端)向数据库发起的并发连接数(如连接池的
maxPoolSize)。 - 作用:控制客户端对数据库的请求压力。

3. 区别与配置
- 区别:
- 服务端是全局限制,客户端是局部限制。
- 客户端连接数总和可能超过服务端限制,导致连接失败。
- 配置建议:
- 客户端连接池大小应 ≤ 服务端
max_connections。 - 服务端需根据硬件资源(CPU、内存)调整连接数上限。
- 客户端连接池大小应 ≤ 服务端
四、服务数据库与CPU、内存的关系
1. 数据库对资源的需求
- CPU:处理查询、事务、索引计算。
- 内存:缓存数据(如InnoDB Buffer Pool)、临时表、连接会话。
2. K8s容器的资源类型
- 主要资源:
- CPU(单位:核或毫核,如
0.5或500m)。 - 内存(单位:GiB/MiB,如
2Gi)。
- CPU(单位:核或毫核,如
- 扩展资源:
- 临时存储(
ephemeral-storage)。 - GPU(需要特定驱动)。
- 自定义资源(如FPGA)。
- 临时存储(
3. 资源间的关系
- 互补性:CPU处理能力不足时,内存缓存可减少磁盘I/O,间接降低CPU负载。
- 竞争性:内存不足可能触发频繁磁盘交换(Swap),增加CPU负担。
- 示例场景:
- 高并发数据库服务:需平衡CPU(处理连接)和内存(缓存数据)。
五、总结
| 问题分类 | 核心要点 |
|---|---|
| CPU与内存 | CPU处理指令,内存提供临时存储;性能相互依赖(如内存速度影响CPU效率)。 |
| K8s资源关系 | CPU和内存独立但可能间接关联;需配置requests/limits避免资源争抢。 |
| 数据库连接数 | 服务端限制全局连接,客户端控制局部请求;需匹配避免超限。 |
| 服务资源与数据库 | 数据库依赖CPU处理查询、内存缓存数据;K8s需综合分配CPU/内存/存储资源。 |
实践建议:
- 监控K8s容器的CPU/内存使用率(如Prometheus + Grafana)。
- 数据库服务端连接数需结合硬件资源(如每个连接约占用2MB内存)。
- 客户端连接池配置需根据业务峰值动态调整(如HikariCP的
maximumPoolSize)。
CPU与GPU的区别及服务中GPU的应用
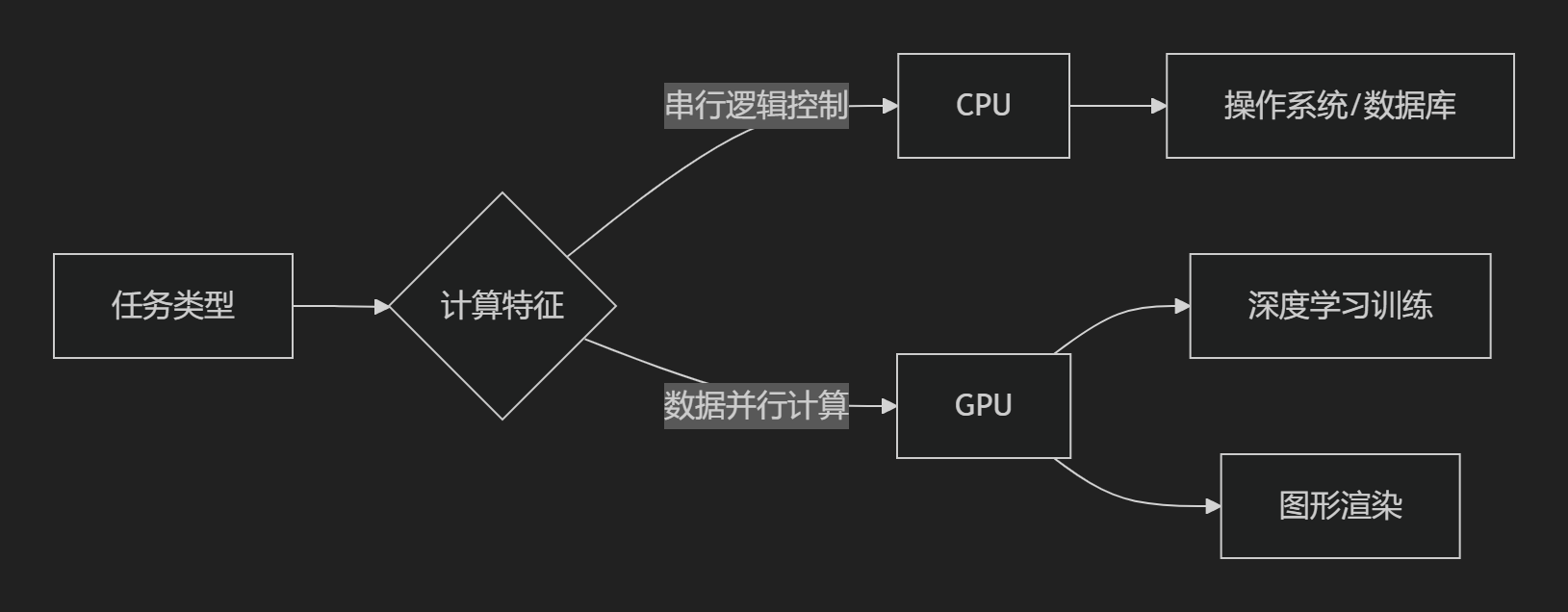
一、CPU与GPU的核心区别
| 特性 | CPU | GPU |
|---|---|---|
| 设计目标 | 通用计算(处理复杂逻辑、顺序任务) | 并行计算(处理大量简单重复任务) |
| 核心结构 | 少量高性能核心(如4-64核) | 数千个小型高效核心(如NVIDIA A100有6912 CUDA核心) |
| 适用场景 | 操作系统调度、业务逻辑、数据库事务 | 图形渲染、科学计算、深度学习、矩阵运算 |
| 延迟敏感度 | 低延迟(快速响应单任务) | 高吞吐(同时处理海量数据) |
| 能耗效率 | 高功耗/单线程性能 | 低功耗/大规模并行效率 |
| 典型负载 | 单线程程序、分支预测 | SIMD(单指令多数据流)、浮点运算 |
二、服务是否会用到GPU?
1. 需要GPU的场景
- 机器学习/深度学习
- 模型训练:如TensorFlow/PyTorch训练神经网络(GPU加速比CPU快10-100倍)。
- 推理服务:实时AI推理(如人脸识别、自然语言处理)。
- 图形与媒体处理
- 视频编码/解码:如FFmpeg硬件加速、直播推流。
- 3D渲染:游戏引擎、影视特效(如Blender Cycles)。
- 科学计算
- 分子动力学模拟:如GROMACS。
- 气象预测:大规模并行气候模型运算。
- 大数据分析
- 并行ETL:GPU加速数据清洗(如Apache Spark RAPIDS插件)。
2. 不需要GPU的场景
- 传统Web服务(如REST API、数据库CRUD)。
- 文件存储、消息队列(Kafka、RabbitMQ)。
- CPU密集型但非并行化任务(如单线程加密算法)。
三、服务使用GPU的典型架构
1. 本地部署
- 物理服务器:直接安装GPU卡(如NVIDIA Tesla系列),需配置驱动(CUDA/cuDNN)。
- 虚拟化:GPU虚拟化技术(如vGPU、MIG)分割物理GPU供多服务共享。
2. 云原生(Kubernetes)
- GPU资源声明:在Pod中指定GPU资源需求(如
nvidia.com/gpu: 1)。resources:limits:nvidia.com/gpu: 2 # 申请2块GPU - 设备插件:通过
k8s-device-plugin将GPU暴露给容器。 - 异构计算框架:Kubeflow用于管理GPU加速的机器学习流水线。
3. 无服务器(Serverless)
- 云服务商提供GPU实例(如AWS Lambda GPU支持)。
- 按需分配GPU资源,适合突发性AI推理任务。
四、GPU资源管理注意事项
-
成本与性能平衡
- GPU实例价格昂贵(如AWS p3.16xlarge约$24.48/小时),需按需使用。
- 混合部署:CPU处理轻量任务,GPU专注计算密集型任务。
-
资源隔离与共享
- 时间分片:多个任务排队使用同一GPU(可能引入延迟)。
- 空间分片:NVIDIA MIG技术将A100 GPU分割为7个独立实例。
-
监控与调优
- 工具:
nvidia-smi监控GPU利用率、显存占用。 - 显存优化:使用混合精度训练(FP16)、梯度累积减少显存需求。
- 工具:
五、总结
| 维度 | CPU | GPU | 服务是否需要GPU |
|---|---|---|---|
| 核心价值 | 通用性、低延迟 | 并行性、高吞吐 | 依赖业务场景(如AI/图形必选) |
| 部署成本 | 低(标准服务器) | 高(专用硬件+License) | 需评估ROI(训练任务通常必须) |
| 技术栈适配 | 所有服务默认依赖 | 需显式编程(CUDA/OpenCL) | 需框架支持(如PyTorch GPU版本) |
决策建议:
- 如果服务涉及矩阵运算、浮点计算、海量数据并行处理,优先考虑GPU。
- 在K8s中部署GPU服务时,需配置Device Plugin并设置资源配额,避免资源争抢。